Maize or corn (Zea mays L.), a plant species particularly generous in its production potential and in its wide diversity of uses, is fundamental for the development of a modern and efficient agriculture. Globally, maize ranks third in area and first in production, ahead of wheat and rice [5]. Due to the large areas corn occupies, but especially to its yielding performance, maize is a major source of food for the world’s population. In addition to its nutritional importance for humans, corn is also basic food for animal feed and valuable raw material for industrial processing. The importance of corn for human health results from the fact that it is a food rich in nutrients [6–8], especially energy of 355 kcal per 100 g flour with 15% moisture, compared to 352 kcal for wheat flour, 348 kcal for rye flour, and 346 kcal for hulled barley [9]. As food, maize also has some shortcomings, of which that we note the low amount of some essential amino acids was noteds, such as lysine and tryptophan [10,11]. Maize is also a valuable raw material for industry, extracting oil, starch, alcohol, glucose, and other products such as syrup, pectin, dextrin, plastics, lactic acid, acetic acid, acetone, dyes, and synthetic rubber from its grains. Paper, cardboard, and nitrocellulose can be made from corn stalks [9]. Every part of the maize plant has economic worth, including the grain, leaves, stalk, tassel, and cob, which can be used to make a variety of food and non-food goods [11]. Maize breeding research has traditionally concentrated on enhancing productive potential in newly created maize varieties because this criterion ensures a crop’s economic efficiency [8]. Nowadays, genomics tools are essential for a precise, fast, and efficient breeding of crops especially in the context of climate challenges, but also may in the future represent a way to accelerate the processes of de novo domestication of the species.
1. Evolution of Maize: From Domestication to Precise Breeding
Over time, there have been many hypotheses about the exact origin of maize and its domestication process
[1][18]. Considered to be originating from the high mountains of Mexico for a long time, the newest molecular analyses suggest that the origin of species is the Central Balsas River Valley from southwestern Mexico. It also seems that maize domestication was not a long time process with multiple steps but rather a very rapid one
[2][21] from its wild ancestor, a subspecies of teosinte known as
Zea mays ssp.
parviglumis [3][4][22,23]. Following the archeological researches carried out in Balsas River Valley, the archaeologists Piperno and Ranere highlight the fact that maize was present in the area about 8700 years ago, during the early Holocene
[3][4][5][22,23,24], when the first agriculture practices were organized in small groups which were moving their shelters seasonally and carrying out a subsistence activity. From Mexico, maize spread over the Americas. Christopher Columbus brought the first seeds of maize to Europe, and in 1525 the first fields were planted in Spain
[6][25].
The most widespread method of genetic improvement since the domestication of plants was mass selection, where the best ear of the healthiest plant is selected to be sown in the next year
[7][26]. Even if the method perfected over the years from a simple mass selection to an ear-to-row selection, it was not very efficient for traits with low heritability like yield
[7][26]. The selection method involves the choice of individuals for breeding based on how they differ in the desired characteristics, which are usually observable or measurable traits. In one of the world’s longest studies, the breeders from the Illinois Agricultural Experiment Station began selecting maize kernels for high oil content as early as 1896. Maize breeders have regularly selected to change the oil composition for nearly a century. The shift in oil concentration after 100 generations was significant: from a base of about 5%, the high oil-producing line currently has about 20% oil
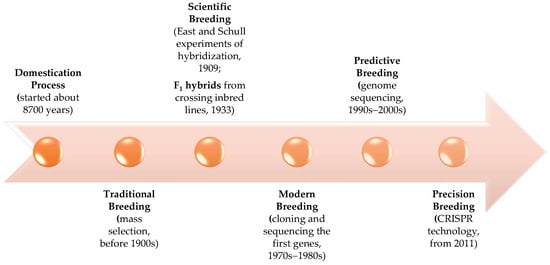
[6][25]. The evolution of maize breeding over time is synthetized in
Figure 1.
Figure 1.
Maize breeding stages: from plant domestication to precise improvement.
The first attempts to direct pollen from one plant to another began in 1867, when H.S. Bidwell introduced maize detasseling as a pollination control measure in his breeding program. In 1878–1881, the professor W.J. Beal from Michigan State Agricultural College proposed crossing maize varieties to grow the production of commercial cultivars. W.A. Kellerman and W.T. Swingle conducted the first segregation counts on maize ears in 1891, for the starchy gene. In 1893, during the World’s Colombian Exposition in Chicago, R. and J. Reid’s “Yellow Dent Maize” won the golden prize as “the world’s most beautiful corn.” Reid’s maize became a very important parent of modern hybrid maize
[6][25]. A revolutionary step in maize breeding began with the discovery of ‘hybrid vigor’ or heterosis in 1909, simultaneously by E.M. East at Harvard University in collaboration with the Connecticut Agricultural Experiment Station
[8][27] and G.H. Schull at the Carnegie Institution Station at Cold Spring Harbor
[8][9][27,28]. This was the first step toward the maize scientific breeding. It took until 1933 for the first hybrid maize created by crossing inbred lines to be introduced.
The modern breeding of corn started in the 1970s–1980s with the first regenerated plant from a cell culture and sequencing the first maize genes. In 1975, in vitro selection of maize found callus cultures resistant to fungal plant pathogen
Helminthosporium maydis T-toxin
[10][29]. Molecular markers were first used in 1980s–1990s in maize breeding and the first transgenic maize cultivar,
Bacillus thuringiensis (
Bt) hybrid, was marketed in 1996
[11][12][30,31]. Later, more transgenic hybrids with insect resistance, herbicide tolerance, high lysine content, and drought-resistance were commercialized
[12][31]. Predictive breeding started with the decreasing costs of genome sequencing in the late 1990s to early 2000s
[9][28], today being known as genomic prediction or genomic selection
[13][14][32,33]. Genome editing by CRISPR technology represents the beginning of the precision plant breeding
[15][34]. The first CRISPR-edited crop that was submitted to the US regulatory system in 2016 was Pioneer high amylopectin maize from DuPont
[16][35].
New plant breeding techniques based on gene editing, cisgenesis, and epigenetic approaches
[17][36] will hold an essential role in the developing of new plants cultivars, allowing for more precise, predictable and quick breeding works
[18][37]. All of these new plant development strategies, however, would not be conceivable without the help of bioinformatics hardware and software.
2. Bioinformatics: The Fundamental Tool Underlying Modern Methods of Breeding
Knowledge that helps us to deeply understand the biological data through methods and software tools is bioinformatics (BI). A link between biology and computer science
[19][38], BI plays an essential role in modern methods of plant breeding. The baggage of tools that bioinformatics provides facilitates the understanding of the biological and genetic processes that underlie the selection process. As Pauline Hogeweg, one of the promoters of BI states, the term was used for the first time by her and Ben Hesper, in the beginning of 1970s and defining “the study of informatics processes in biotic systems”
[20][21][39,40]. Over the past years, advanced research in the field of biology, genetics, but also artificial intelligence, has led to the reconfiguration and development of the meaning of BI
[19][21][22][38,40,41]. At present, evolutionary biology goes ‘hand-in-hand’ with bioinformatics, due to the fact that the first provides the scientific data and the second manages and analyzes them
[23][42].
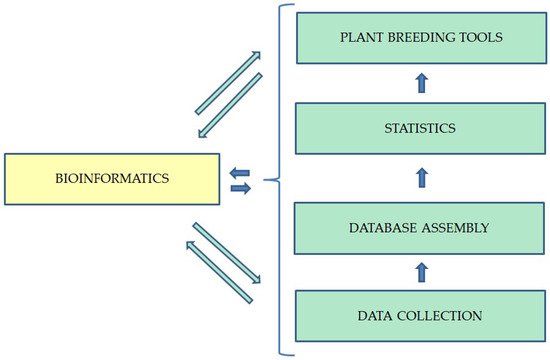
Major goals of BI can be stated in the analysis, reconstruction, discovery, assembly, comparison, classification, simulation, modeling, and prediction using biological data
[19][38]. In order to be able to organize the multitude of existing data and to be able to process them, the data are collected and organized systematically in databases. The process of BI implication in plant breeding is shown in
Figure 2. Most BI databases contain nucleic acid and protein sequences. Those are a key factor in understanding and developing the applied sciences
[24][43], such as plant breeding, especially in the cases of the species that are rich in phenotypic and genetic diversity, such as maize.
Figure 2.
Operation process of bioinformatics in plant breeding.
Having available the entire genome of a species opens the way to advanced research, because it can be used to create better crops, with a higher quality or more resistant to biotic and abiotic stress. Knowing exactly how closely related are the plants is the base for choosing the right genitors to produce crops with desirable traits. BI databases help researchers study and understand better functions and expression of genes especially under different stress conditions so that they can identify, analyze, and test the right plants for their purpose. Through its essence, BI is not only a provider of information but also leads to new experiments. By constantly updating databases, scientists will have new data in a timely manner that they can use for further and more advanced research.
3. Marker-Assisted Selection
Plant breeding for crop improvement that uses direct phenotypic selection is labor-intensive, expensive, and time-consuming. Target gene expression, their unique biological or environmental state, and the trait’s heredity all influence this selection. For quantitative traits that are regularly under selection process, phenotypic selection is less effective
[25][26][27][72,73,74].
Marker-assisted selection (MAS), also known as marker-aided selection, is an indirect selection method in which a trait of interest is chosen based on a marker (morphological, biochemical, or DNA/RNA variation)
[6][25]. In MAS, a marker is close to a gene that controls the trait, so the presence of the marker indicates the presence of a desired allele
[28][75]. Molecular marker technology, automated equipment, and new statistical tools to analyze data are all aiding the breeders to be ready to face the growing food demand. MAS is now widely applied and proven to be an effective breeding technique
[29][76]. Genotypic markers are used to help phenotypic selections. MAS is cheaper to use in crops for traits with simple inheritance
[28][75] but also can be applied to quantitative traits controlled by many genes with small effects, such as yield, stress tolerance, and resistance to pests
[28][30][75,77], even if using the method
in th
ereinis case is more complicated
[31][78]. It is primarily utilized by plant breeders in their breeding programs to find desired dominant or recessive alleles throughout generations as well as to help identify the best genotypes from segregating generations
[32][79]. Reliable markers, a high-quality DNA extraction procedure, genetic maps, knowledge of marker-trait associations, quick and efficient data processing, and the availability of high-throughput marker detection equipment are all prerequisites for an effective MAS program
[25][72].
Marker-assisted backcross (MABC) is a particular case of MAS where backcrossing strategy is assisted by molecular markers to speed up recurrent parent selection and genome recovery
[33][80]. Conventional backcrossing is a method that has been widely used for transferring oligogenic traits from donor parents to recurrent parents by recovering the whole genome of recurrent parents except for the trait of interest after 6–7 generations of backcrossing
[34][81]. By transferring genes of interest or quantitative trait loci (QTLs) from donor parent, the MABC technique has been widely utilized to remove undesired features such as insect and disease susceptibility, anti-nutritional factors, and other undesirable traits from high yielding popular varieties
[30][77]. The close connection of markers with genes or QTLs is the foundation of MABC
[25][72].
Maize was one of the first important crop species for which a comprehensive molecular marker map was developed
[35][82]. First molecular markers used were restriction fragment length polymorphism (RFLPs)
[30][77]. Following that, random amplified polymorphic DNA markers (RAPDs) evolved as a result of the development of polymerase chain reaction (PCR) technology
[36][83]. Because of their limitations, simple sequence repeats (SSRs) or microsatellite markers began to be increasingly used
[37][84]. The amplified fragment length polymorphism (AFLP) uses PCR to preferentially amplify DNA fragments
[37][84]. Single-nucleotide polymorphisms (SNPs) identify single base pair changes and are used more recently
[38][85]. SSRs and SNPs appears to be most common markers used to identify different levels of genetic diversity
[39][40][86,87].
4. Genomic Selection
The new technology with perhaps the greatest potential to improve breeding efficiency for quantitative traits is genomic selection (GS). GS was first successfully used in animals
[41][99], and then it also spread in the case of crops
[42][100]. GS requires genotyping thousands of individuals with thousands of markers; it became more popular in breeding programs due to advancement in genotyping technology. By GS, breeders obtain the complete genetic profile of an individual, and the data are used to identify individuals that have superior breeding value
[43][101]. Marker and phenotypic data are co-analyzed to develop a model that predicts which genomes produce the best breeding value meaning they produce superior progeny
[44][102]. Those individuals are intermated to produce progeny that are genotyped and the best are selected using GS models, and intermated again to start a new cycle
[45][46][103,104]. The goal is to assemble the best genome as quickly as possible
[42][43][100,101]. GS can predict the yield value of individual plants quickly and cheaply, thereby reducing the duration and cost of a breeding cycle
[47][105]. Apart from yield GS has the potential to improve complex traits with low heritability
[48][49][50][106,107,108] as well as simple traits with higher heritability
[51][52][109,110].
The application of GS in plant breeding could be limited by genotyping costs and circumstances where GS can be efficiently applied in a breeding program
[53][111]. Limitations of GS arise from the size and diversity of the training population and the heritability of the traits to be predicted
[54][112]. Statistical difficulties of GS are related to the high amplitude of marker data, where the number of markers is much larger than the number of observations
[55][113].
There is a close relation between GS and phenotypic selection (PS). Both utilize cycles of selection and phenotypic data from multiple parent populations which are selected based on estimation of the value of their whole genome. Depending on the crop, a single cycle of GS can be completed in a few months instead of years with PS, which requires reliable phenotypes to estimate breeding values. Thus, gain-per-year can be greatly increased, making GS a promising technology to meet the pressing need to improve it
[56][57][114,115].
In maize breeding the advantage of GS over PS consists of reducing costs and saving time. In terms of cost reduction, the breeder can testcross 50% of all available lines, evaluating them in first-stage multi-locational trials and can then use the phenotypic data to predict the remaining 50% by GS. Selecting lines directly for stage II instead of going through stage I (used in PS) significantly reduces the cost of testcross formation and evaluation at each stage of multi-location trials. The GS time efficacy in maize breeding could come from the second cycle of selection, which uses the training population from the previous cycle to predict the new doubled haploid lines, therefore eliminating testcross formation and first-stage multi-location evaluation trials. Based on this, the best lines could go directly to the second stage of multi-location evaluations
[53][111].
For instance, Beyenne et al. (2021) used GS in maize to predict the breeding value for the new created double haploid lines for further testing. Using rAmpSeq markers, his team evaluated as test crosses 3068 inbred lines of tropical maize in well-watered and water-stress environments
[58][116]. GS was also used in predicting the performance of maize hybrids under different genetic designs: Griffing’s methods, North Carolina Design II, partial diallel, and test crossing
[14][59][60][33,117,118]. Using GS, inbreds with high combining ability, either general or specific, are revealed
[51][109]. Genomic estimation of breeding value can help to identify inbred lines of maize with favorable disease resistance
[61][119]. GS models can include multiple levels of the biological hierarchy of an agronomic trait based on the available omics data (genomics, transcriptomics, proteomics, epigenomics, and metabolomics) in maize
[14][61][33,119].
5. Breeding by Design
Approaches made on genomics and breeding technologies facilitate the development of breeding by design (BD) where the allelic variation of the genes with agronomic importance can be controlled
[62][120] so the breeder can design new in silico superior genotypes
[63][121] (
Figure 3). Due to the accuracy of this process, the breeder can ignore the selection by phenotyping and evaluate only the superior varieties for field performance
[63][121]. The BD technique involves three stages: mapping loci that are influencing all agronomical relevant traits; assessing the allelic variation at those loci; and breeding by design using desirable alleles of different loci
[63][64][121,122]. Thus, the BD approaches the possibility to predict the result of a set of crosses based on molecular marker information. This method has been mentioned in the development of higher-quality maize cultivars. The most effective use of the BD method, on the other hand, will come from incorporating the most powerful genomic tools into the breeding process, which will allow the improvement of predictions
[65][123].
Figure 3.
A simplified approach of design in silico.
6. Genome Sequencing
- Genome Sequencing
Genome sequencing (GSq) implies the determination of the order of DNA nucleotides in the genome of an organism [66][123]. Using this technique, scientists try to localize the genes and understand how a certain gene develops and influences the entire organism. In addition to the genes, GSq can help to a better understanding of the parts of genome outside the genes that control how genes are turned on or off [66][123]. Due to its complex genetics, maize is mostly used as a model plant for genetics analyses [67][68][124,125] and has become one of the first species considered for GSq [69][126]. It is estimated that maize genome is almost 80% of the human genome size and contains approximately 59,000 genes [70][127]. First sequencing attempts on maize were started during the early 2000s with The Sequencing the Maize Genome Project (STMG) [71][72][128,129] and The Consortium for Maize Genomics (CMG) [72][73][129,130]. A full-scale program was launched in 2005 by the National Science Foundation [72][129], to sequence the cultivar B73, one of the most used maize inbred lines for the production of the high-yielding commercial hybrids [74][75][131,132]. Three years later, the first draft sequence for maize genome was published [76][133]. According to a multi-genome investigation carried out in 2021, new variation in gene content, genome organization, and methylation was discovered in maize [77][134]. Genome prediction combined with crops modeling can lead to significant gains in maize breeding [32].
7. New Plant-Breeding Techniques
- New Plant-Breeding Techniques
The start of the precision breeding was represented by the first actions of editing the plant genome [34]. Genome editing (GE) is the newest approach of modifying certain genes to improve the expression of interest traits. This technique can increase the genetic gain of the plants and also accelerate the breeding process at the same time [78][137]. GE modifications are precise, and the resulting changes are minor [79][138]. The GE experiments with high chances of success are the ones in which the target traits are determined by a single gene. The needed tools for GE are provided by the Novel Genomics Techniques (NGTs)/New Plant-Breeding Techniques (NBTs) [80][139]. GE instruments are based on DNA modification with the purpose of changing the traits of the plant [81][82][140,141]. Genome editing through NTBs implies using one the following methods: CRISPR/Cas, Zinc finger nuclease or TALENs [83][84][85][86][87][88][142–147], oligonucleotide-directed mutagenesis [89][90][91][148–150], epigenetic methods [92][93][94][151–153], cisgenesis [95][96][97][154–156], intragenesis [96][98][99][155,157,158], or grafting an unmodified plant with a transgenic one [100][101][102][159–161]. Using these types of tools combined with the classical breeding methods could remodel the maize breeding science [103][186] by speeding the entire process with shortening the generation time [104][73].