Deep learning approaches to the detection of visual data instances that markedly digress from regular sequences have been mostly focusing on outdoor video-surveillance scenarios, mainly regarding abnormal behaviour and suspicious or abandoned object detection. However, with the increasing importance of public and shared transportation for urban mobility, it becomes imperative to provide autonomous intelligent systems capable of detecting abnormal behaviour that threatens passenger safety. In-vehicle monitoring becomes particularly relevant for Shared Autonomous Vehicles, which do not have a driver responsible for assuring the well-being and safety of passengers; such vehicles must be accompanied by reliable autonomous in-vehicle surveillance systems.
- anomaly detection
- deep learning
- computer vision
- anomaly locality
- in-vehicle monitoring
1. Introduction
2. Deep Anomaly Detection
2.1. Evaluation Metrics
In the literature on anomaly detection [7][8], a prominent evaluation metric is the Receiver Operation Characteristic (ROC), which is obtained by gradually changing the threshold of the regularity score. The regularity score is used to judge whether the input frame is normal or abnormal by manually defining a threshold. The optimal value of this parameter is relevant, since a higher threshold leads to a higher false negative rate, while a lower one leads to a higher false negative rate. Then, the Area Under the Curve (AUC) is cumulated to a scalar for performance evaluation with a higher value indicating better performance. To achieve a more detailed understanding of a certain model, precision, recall, true positive, and false alarm should also be considered. Although these metrics are not as popular as Frame AUC, their inclusion provides interesting indicators to estimate the potential success of a real-world application of a certain model (e.g., knowing if it is prone to false alarms).2.2. Semi-Supervised Strategies
Generally, semi-supervised methods for anomaly detection in the literature fall in the category of One-Class Classification (OCC). In practice, it is quite frequent that normal events have a good representation, as they represent the majority of the captured sequences, whilst abnormal cases are rare, and the abnormal class is ill-defined. In these cases, the abnormality is detected based on the information learnt from the normal class only. One-Class Classification is present in reconstruction-based and prediction-based semi-supervised methods that employ the same basic principle; both try to generate the entirety or patches of a frame, evaluating their similarity to the ground truth. These models are trained on normality and assume that it is not possible to properly reconstruct an abnormal event that has never been learnt. Hence, a frame that greatly differs from the captured one is likely to represent abnormal or unexpected events. The main difference between both types of semi-supervised methods regards temporal information, as illustrated in Figure 1. On the one hand, reconstruction-based methods try to reconstruct the current frame, using previous and present information. On the other hand, prediction-based methods use the previous frames to compute a prediction of the following one. Recently, semi-supervised strategies have been increasingly focusing on video frame prediction due to its potential applications in unsupervised video representation learning. However, existing methods of this type deliver suboptimal results, especially when compared to newer methods that use weakly supervised techniques, due to their insufficient modelling of temporal information. Moreover, they suffer from inefficient training for implementing adversarial techniques or additional losses [9]. The lack of prior knowledge of abnormality is usually a cause of overfitting of the training data, not enabling a proper way to distinguish abnormal from normal events [10].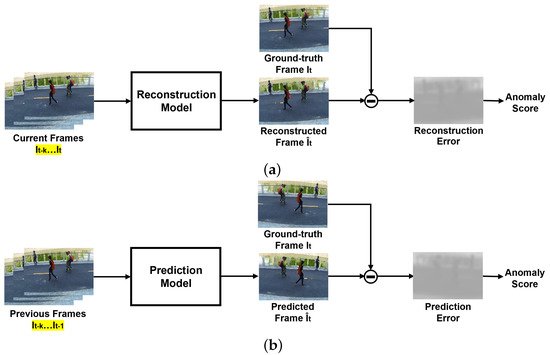
2.2.1. Reconstruction-Based Methods
2.2.2. Prediction-Based Methods
As far as prediction-based approaches are concerned, these aim to predict future frames based on an input consisting of previous frames. This method was introduced by Liu et al.[3] and assumes that normal events are predictable, while abnormal ones are not. Future Frame Prediction[3] proposed strategies to impose consistency on the generated images by applying intensity and gradient constraints. The former assures the similarity of all pixels in the RGB space, and the latter sharpens the generated images.Georgescu et al.[17] proposed some alterations to frame prediction, innovating by learning the discrimination of moving objects, which is referred to as the arrow of time. Essentially, it considered both classification and detection information, producing large prediction discrepancies when anomalies occur. This approach was inspired by the object-centric perspective of Ionescu et al.[18], which employed an object detector on each frame, applying a convolutional autoencoder to learn deep unsupervised representations for a one-versus-rest classification.
The main drawbacks of semi-supervised approaches are the lack of consideration for the diversity of normal patterns and the ability of deep learning techniques to correctly recreate abnormal video frames based on already abnormal inputs. To this end, Park et al.[19] proposed a memory module that updates items in the memory while assuring that these represent prototypical patterns of normal data. Similarly, Cai et al.[20] attempted to assure appearance and motion consistency through modality memory pools. Two separate pools were created to store this information: one comprising appearance features and the other consisting of the motion features, guaranteeing a robust feature representation of normality
2.3. Weakly Supervised Strategies
Weakly supervised video anomaly detection strategies are amongst the best-performing approaches for this task. At the expense of an additional low-intensity annotation effort, a better anomaly classification accuracy can be achieved. Essentially, weakly supervised approaches can be subdivided into two classes, encoder-agnostic and encoder-based methods. Encoder-agnostic methods[21][22][23] leveraged task agnostic features of videos extracted from a vanilla feature encoder (e.g., I3D[24]) to estimate the anomaly scores of each frame. In these methods, only the classifier was trained. On the other hand, encoder-based methods[25][26] trained both the feature encoder and classifier simultaneously. Weakly supervised strategies are considered to be a feasible method due to their competitive performance. Sultani et al.[21] introduced the use of video-level labels in the tasks of anomaly detection in videos by presenting UCF-Crime, which is a large-scale video dataset for training and testing weakly supervised anomaly detection approaches. Along with this strategy, Sultani et al.[21] proposed a deep Multiple Instance Learning (MIL) ranking framework to detect anomalies, as illustrated in Figure 2. In essence, MIL takes a video as a bag and clips the video as separate instances. The bag generated from an abnormal instance is called a positive bag, and it must contain at least one abnormal snippet. The negative bag, generated from normal videos, contains no abnormal snippets. The instance-level anomaly scores are learnt through the bag-level labels.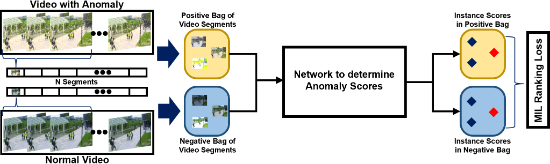
Several papers followed the MIL framework, suggesting improvements to the method. The inner-bag score gap regularisation was introduced by Zhang et al.[22] to increase the gap between the lowest and highest scores in a positive bag and reduce it in a negative one. Wan et al.[23] proposed a dynamic MIL-loss and centre-guided regularisation; the former enlarged the interclass dispersion, and the latter reduced the intraclass distance of normal snippets. Additionally, Zhu et al.[25], in an encoder-based approach, suggested an attention-based MIL model capable of encoding motion-aware features by using an autoencoder based on optical flow.
Zhong et al.[26] denoted that in the methods that used MIL, if the model incorrectly predicted anomalous instances in the positive bag, the error would propagate to subsequent instance selection. To tackle this problem, Zhong et al.[26] reformulated the task as a binary classification under a noisy label problem and suggested the use of a Graph Convolution Neural (GCN) network to correct low-confidence anomaly scores, replacing them with high-confidence ones. Even though this work achieved better accuracy in the identification of anomalies when compared to MIL-based approaches, training both a GCN and MIL is computationally expensive and may cause unstable performance due to unconstrained latent space.
2.4. Fully Supervised Strategies
The exploration of fully supervised anomaly detection remains limited by the high cost of collecting large-scale data or generating sufficiently broad artificial dataset solutions. However, semi-supervised and weakly supervised methods, despite their recent improvements, have not fully addressed their limitations, such as background bias. Liu et al.[27] conducted a series of experiments to validate the existence of a background-bias phenomenon, i.e., the tendency for deep neural networks to learn the background information rather than the anomaly pattern. To tackle this, a portion of UCF-Crime[21] was re-annotated with temporal and spatial labels, the latter being represented by bounding boxes. This new information was used to feed an end-to-end framework with a designed region loss, explicitly guiding the model to focus on the anomalous region.A similar approach was implemented by Landi et al.[28], focusing on spatiotemporal tubes instead of the entirety of video segments containing full frames. UCFCrime2Local, an enriched subsection of 100 burglary and assault sequences from UCF-Crime[21], was presented as a separate dataset for anomaly detection with bounding box supervision in its train and test set. The proposed model was able to provide spatiotemporal proposals for unseen surveillance videos leveraging only video-level labels, enlarging the anomaly dataset without additional human labelling.
3. Publicly Available Datasets
3.1. Real-World Datasets
3.1.1. Pedestrians and Crowds
The most widely used video anomaly detection dataset is the UCSD pedestrian dataset[7]. It was captured by a stationary video camera, focusing on two pedestrian walkways. This dataset contains two separate subsets: Ped1 and Ped2. The former is composed of 34 training videos and 36 testing videos, whilst the latter consists of 16 training video clips and 12 testing ones. The abnormal behaviours are connected to the presence of vehicles such as cars and bikers, as illustrated by Figure 3a,b. The CUHK Avenue dataset[8] is very common in benchmarks, and it was also acquired using a stationary video camera in the CUHK campus avenue. It has 16 training video samples and 21 test video samples. The abnormal behaviour represented in the scenes is connected to human actions, showing people walking on the grass, and throwing objects in the background. However, both datasets possess severe limitations regarding their single-scene representation, lack of abnormality diversity, and amount of sequences.It is desirable to learn an anomaly detection model capable of performing well under multiple scenes and viewing angles. To address these drawbacks, ShanghaiTech[4] was developed, taking advantage of multiple surveillance cameras with different view angles installed at different spots, to capture real events at a university campus. ShanghaiTech has challenging light conditions and camera angles, as Figures 3c,d exemplify. It contains 130 abnormal events and annotations for pixel-level ground truth of abnormal events.

Figure 3. Abnormal frames extracted from widely used datasets for training and benchmarking video anomaly tasks. (a) Two bikers amongst the pedestrians in Ped1[7] dataset. (b) Car and biker in a pedestrian walkway in Ped2[7] dataset. (c) A normal frame from ShanghaiTech dataset[4]. (d) Two people fighting in ShanghaiTech dataset[4].
3.1.2. Real-World Anomalies
Motivated by the limitations of previous datasets, UCF-Crime[21] was developed as a new large-scale dataset to evaluate video anomaly detection. It is composed of 1900 untrimmed videos of real-world surveillance footage, extracted from the internet, with an average length of 4 min each. It includes 13 types of anomalous events with a high impact on public safety, such as abuse, burglary, shoplifting and shooting, displayed in Figure 4a,b. UCF-Crime contains annotated bounding boxes of anomalous regions in one image per 16 frames of each abnormal video. A considerable amount of available data was essential for the development of weakly supervised strategies.XD-Violence[29] was originally released to develop a large-scale and multi-scene dataset for violence detection and classification. Furthermore, it contains audio-visual signals, allowing for the research on multi-modal solutions for this problem. XD-Violence consists of 4754 weak-labelled untrimmed videos with audio, which were collected from both films and YouTube. This dataset embraces a variety of scenarios and anomalies, for instance, rioting, and explosions, as shown in Figure 4c,d.

Figure 4. Comparison between normal and abnormal frames extracted from real-world anomalies datasets. (a) Frame from a normal activity extracted from UCF-Crime[21]. (b) Abnormal frame from UCF-Crime[21], showing a shooting. (c) Frame from a normal activity in XD-Violence[29]. (d) Abnormal frame from XD-Violence[29], representing an explosion.
3.1.3. Traffic
Most datasets that involve traffic consist of dashcam videos or surveillance videos to support the development of systems capable of anticipating traffic accidents. However, the scope of this paper concerns anomaly detection of human-related behaviours. The Street Scene dataset[30] consists of 46 training video sequences and 35 testing video sequences taken from a static camera looking down on a scene of a two-lane street with bike lanes and pedestrian sidewalks. All of the footage is composed of daytime sequences, and it does not contain staged anomalies. The testing sequences have a total of 205 anomalous events consisting of 17 different anomaly types, such as jaywalking, cars outside their lane, and loitering. Although weather conditions are similar in every sequence, the dataset is challenging due to the variety of simultaneous activities occurring, moving background (e.g., trees moving with the wind) and changing shadows.3.2. Synthetic Alternatives
UBnormal[31] is a novel supervised open-set benchmark composed of multiple virtual scenes for video anomaly detection. The artificial generation of the scenes of this dataset using Cinema4D is essential to provide pixel-level annotations for abnormal events in the training set, allowing for the use of fully supervised methods for video anomaly detection. The dataset consists of 29 virtual scenes with 660 anomalies and nine different types of abnormal behaviour. The videos were generated at 30 FPS and are composed of photorealistic frames as far as both background and actors are concerned. Normal and abnormal frames of some scenes are illustrated in Figure 5a,b, respectively. Additionally, the work of Acsintoae et al.[31] introduces an interesting concept of expanding real-world datasets. The translation of simulated objects from UBnormal to Avenue[8] or ShanghaiTech[4] was proposed using a CycleGAN[32], producing enhanced results when used to train state-of-the-art methods. Similar hybrid strategies could be studied as a solution to the lack of available public datasets for anomaly detection inside vehicles.SVIRO-Uncertainty[33] is a high-quality synthetic dataset that is not directly related to the task of anomaly detection. Nonetheless, it has the potential to be adapted to study a subset of this problem: the detection of abandoned or dangerous objects. The original goal of this dataset was to train models capable of classifying the object that is occupying each position. SVIRO-Uncertainty is made up of sequences of the rear bench of a vehicle, in which each of the three seats might contain a passenger or an object, as displayed in Figure 5c,d. The dataset is quite large, containing two separate training sets, 4384 scenes with adult passengers only and 3515 using adults, child seats and infant seats.

4. Challenges and Opportunities for In-Vehicle Monitoring
Choosing the best model for a new use case such as anomaly detection inside of a vehicle is not straightforward. The typical scenario of the publicly available datasets does not faithfully represent the new environment in which anomalies must be detected; therefore, their use does not produce an authentic benchmark of the proposed methods. Most of these sequences were captured with stationary video cameras that were recording static backgrounds. Although cameras inside vehicles are also stationary, windows on a moving vehicle produce a partially moving background on the recorded sequence. The distance between the cameras and the subjects is much smaller inside a vehicle, increasing the effect of geometric distortions on the captured information. Additionally, headlights of other vehicles, public illumination and occlusions of sunlight produce more frequent illumination perturbations in the scene than those found on datasets that focus on a pedestrian walkway, for instance. The behaviour of the available models in such scenes is uncertain, as these did not have to specifically build and test tools for such problems.
Anomaly detection in confined spaces, such as the interior of vehicles, is an interesting new application scenario for deep anomaly detection methods. However, as the work of Augusto et al.[5] demonstrates, the development of solutions for this use case is still fully dependent on the availability of private datasets. However, the relevance of objects was not considered in this work, whether for representing a danger to the passengers or simply as an object that was left behind by one of them. The latter is of significant importance in the suggested shared autonomous vehicle scenario.
Creating new datasets or expanding existing ones appears to be an immediate need for considering new use applications for anomaly detection. The former is a complex and costly task that implies allocating resources for staging and recording the desired interactions. Hence, an attractive option relies on synthetic data that could be generated for direct use or to augment available data. The work of Acsintoae et al.[31] is referred to as an interesting approach to the translation of simulated objects to real-world datasets. Similar hybrid strategies could be employed to circumvent the lack of data for in-vehicle monitoring applications. Furthermore, such strategies could pre-emptively add some artificial variety to the available video sequences. The work of Capozzi et al.[34] has linked the lack of actor independence with the underperformance of the trained models, as a bias is developed linking certain actors to certain actions, instead of learning the pattern of the action.
A common issue with the proposed deep anomaly detection techniques was noted by Pang et al.[10] Most anomaly detection studies focus on detection performance only, ignoring the capability of illustrating the identified anomalies. Although it would be relevant to classify the abnormal behaviour that was detected, the detection could represent a novel anomaly. Hence, it is crucial to at least provide spatial cues that demonstrate the specific data portion that is anomalous. These cues might prove useful as a tool for interpreting such complex models and identifying scenarios in which they could be missing.
References
- B. Ravi Kiran; Dilip Mathew Thomas; Ranjith Parakkal; An Overview of Deep Learning Based Methods for Unsupervised and Semi-Supervised Anomaly Detection in Videos. Journal of Imaging 2018, 4, 36, 10.3390/jimaging4020036.
- Dan Xu; Yan Yan; Elisa Ricci; Nicu Sebe; Detecting anomalous events in videos by learning deep representations of appearance and motion. Computer Vision and Image Understanding 2017, 156, 117-127, 10.1016/j.cviu.2016.10.010.
- Wen Liu; Weixin Luo; Dongze Lian; Shenghua Gao; Future Frame Prediction for Anomaly Detection - A New Baseline. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, 1, 6536-6545, 10.1109/cvpr.2018.00684.
- Weixin Luo; Wen Liu; Shenghua Gao; A Revisit of Sparse Coding Based Anomaly Detection in Stacked RNN Framework. 2017 IEEE International Conference on Computer Vision (ICCV) 2017, 1, 341-349, 10.1109/iccv.2017.45.
- Pedro Augusto; Jaime S. Cardoso; Joaquim Fonseca; Automotive Interior Sensing - Towards a Synergetic Approach between Anomaly Detection and Action Recognition Strategies. 2020 IEEE 4th International Conference on Image Processing, Applications and Systems (IPAS) 2020, 1, 162-167, 10.1109/ipas50080.2020.9334942.
- David Gunning; Mark Stefik; Jaesik Choi; Timothy Miller; Simone Stumpf; Guang-Zhong Yang; XAI—Explainable artificial intelligence. Science Robotics 2019, 4, 1-3, 10.1126/scirobotics.aay7120.
- Vijay Mahadevan; Weixin Li; Viral Bhalodia; Nuno Vasconcelos; Anomaly detection in crowded scenes. 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2010, 1, 1975-1981, 10.1109/cvpr.2010.5539872.
- Cewu Lu; Jianping Shi; Jiaya Jia; Abnormal Event Detection at 150 FPS in MATLAB. 2013 IEEE International Conference on Computer Vision 2013, 1, 2720-2727, 10.1109/iccv.2013.338.
- Xuanzhao Wang; ZhengPing Che; Bo Jiang; Ning Xiao; Ke Yang; Jian Tang; Jieping Ye; Jingyu Wang; Qi Qi; Robust Unsupervised Video Anomaly Detection by Multipath Frame Prediction. IEEE Transactions on Neural Networks and Learning Systems 2021, 33, 2301-2312, 10.1109/tnnls.2021.3083152.
- Guansong Pang; Chunhua Shen; Longbing Cao; Anton Van Den Hengel; Deep Learning for Anomaly Detection: A Review. ACM Computing Surveys 2021, 54, 1-38, https://doi.org/10.1145/3439950.
- Dan Xu; Elisa Ricci; Yan Yan; Jingkuan Song; Nicu Sebe; Learning Deep Representations of Appearance and Motion for Anomalous Event Detection. Procedings of the British Machine Vision Conference 2015 2015, 1, 8.1-8.12, 10.5244/c.29.8.
- Mahmudul Hasan; Jonghyun Choi; Jan Neumann; Amit K. Roy-Chowdhury; Larry S. Davis; Learning Temporal Regularity in Video Sequences. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, 1, 733-742, 10.1109/cvpr.2016.86.
- Weixin Luo; Wen Liu; Shenghua Gao; Remembering history with convolutional LSTM for anomaly detection. 2017 IEEE International Conference on Multimedia and Expo (ICME) 2017, 1, 439-444, 10.1109/icme.2017.8019325.
- Ranzato, M.; Szlam, A.; Bruna, J.; Mathieu, M.; Collobert, R.; Chopra, S.; Video (language) modeling: a baseline for generative models of natural videos. arXiv preprint 2014, 1, 1-15.
- Wisdom, S.; Powers, T.; Pitton, J.; Atlas, L.; Interpretable recurrent neural networks using sequential sparse recovery. arXiv 2016, 1, 1-8, https://doi.org/10.48550/arXiv.1611.07252.
- Dong Gong; Lingqiao Liu; Vuong Le; Budhaditya Saha; Moussa Reda Mansour; Svetha Venkatesh; Anton Van Den Hengel; Memorizing Normality to Detect Anomaly: Memory-Augmented Deep Autoencoder for Unsupervised Anomaly Detection. 2019 IEEE/CVF International Conference on Computer Vision (ICCV) 2019, 1, 1705-1714, 10.1109/iccv.2019.00179.
- Mariana-Iuliana Georgescu; Antonio Barbalau; Radu Tudor Ionescu; Fahad Shahbaz Khan; Marius Popescu; Mubarak Shah; Anomaly Detection in Video via Self-Supervised and Multi-Task Learning. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2021, 1, 12737-12747, 10.1109/cvpr46437.2021.01255.
- Radu Tudor Ionescu; Fahad Shahbaz Khan; Mariana-Iuliana Georgescu; Ling Shao; Object-Centric Auto-Encoders and Dummy Anomalies for Abnormal Event Detection in Video. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2019, 1, 7834-7843, 10.1109/cvpr.2019.00803.
- Hyunjong Park; Jongyoun Noh; Bumsub Ham; Learning Memory-Guided Normality for Anomaly Detection. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2020, 1, 14360-14369, 10.1109/cvpr42600.2020.01438.
- Ruichu Cai; Hao Zhang; Wen Liu; Shenghua Gao; Zhifeng Hao; Appearance-Motion Memory Consistency Network for Video Anomaly Detection. Proceedings of the AAAI Conference on Artificial Intelligence 2021, 35, 938-946, 10.1609/aaai.v35i2.16177.
- Waqas Sultani; Chen Chen; Mubarak Shah; Real-World Anomaly Detection in Surveillance Videos. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2018, 1, 6479-6488, 10.1109/cvpr.2018.00678.
- Jiangong Zhang; LaiYun Qing; Jun Miao; Temporal Convolutional Network with Complementary Inner Bag Loss for Weakly Supervised Anomaly Detection. 2019 IEEE International Conference on Image Processing (ICIP) 2019, 1, 4030-4034, 10.1109/icip.2019.8803657.
- Boyang Wan; Yuming Fang; Xue Xia; Jiajie Mei; Weakly Supervised Video Anomaly Detection via Center-Guided Discriminative Learning. 2020 IEEE International Conference on Multimedia and Expo (ICME) 2020, 1, 1-6, 10.1109/icme46284.2020.9102722.
- Joao Carreira; Andrew Zisserman; Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2017, 1, 4724-4733, 10.1109/cvpr.2017.502.
- Yi Zhu; Shawn Newsam; Motion-Aware Feature for Improved Video Anomaly Detection. arXiv 2019, arXiv:1907.10211, 1-12.
- Jia-Xing Zhong; Nannan Li; Weijie Kong; Shan Liu; Thomas H. Li; Ge Li; Graph Convolutional Label Noise Cleaner: Train a Plug-And-Play Action Classifier for Anomaly Detection. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2019, 1, 1237-1246, 10.1109/cvpr.2019.00133.
- Kun Liu; Huadong Ma; Exploring Background-bias for Anomaly Detection in Surveillance Videos. Proceedings of the 27th ACM International Conference on Multimedia 2019, 1, 1490-1499, 10.1145/3343031.3350998.
- Federico Landi; Cees G. M. Snoek; Rita Cucchiara; Anomaly Locality in Video Surveillance. arXiv 2019, arXiv:1901.10364, 1-5, https://doi.org/10.48550/arXiv.1901.10364.
- Peng Wu; Jing Liu; Yujia Shi; Yujia Sun; Fangtao Shao; Zhaoyang Wu; Zhiwei Yang; Not only Look, But Also Listen: Learning Multimodal Violence Detection Under Weak Supervision. Proceedings of the European Conference on Computer Vision 2020, 1, 322-339, 10.1007/978-3-030-58577-8_20.
- Bharathkumar Ramachandra; Michael J. Jones; Street Scene: A new dataset and evaluation protocol for video anomaly detection. 2020 IEEE Winter Conference on Applications of Computer Vision (WACV) 2020, 1, 2558-2567, 10.1109/wacv45572.2020.9093457.
- Andra Acsintoae; Andrei Florescu; Mariana-Iuliana Georgescu; Tudor Mare; Paul Sumedrea; Radu Tudor Ionescu; Fahad Shahbaz Khan; Mubarak Shah; UBnormal: New Benchmark for Supervised Open-Set Video Anomaly Detection. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, 1, 20111-20121, 10.1109/cvpr52688.2022.01951.
- Jun-Yan Zhu; Taesung Park; Phillip Isola; Alexei A. Efros; Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. 2017 IEEE International Conference on Computer Vision (ICCV) 2017, 1, 2242-2251, 10.1109/iccv.2017.244.
- Steve Dias Da Cruz; Bertram Taetz; Thomas Stifter; Didier Stricker; Autoencoder Attractors for Uncertainty Estimation. arXiv e-prints 2022, 1, 1-8, https://doi.org/10.48550/arXiv.2204.00382.
- Leonardo Capozzi; Vitor Barbosa; Carolina Pinto; Joao Ribeiro Pinto; Americo Pereira; Pedro M. Carvalho; Jaime S. Cardoso; Towards vehicle occupant-invariant models for activity characterisation. IEEE Access 2022, PP, 1-1, 10.1109/access.2022.3210973.