Object detection is a common application within the computer vision area. Its tasks include the classic challenges of object localization and classification. As a consequence, object detection is a challenging task. Furthermore, this technique is crucial for maritime applications since situational awareness can bring various benefits to surveillance systems. The Convoliterature presents various models to improve utional neural network (CNNs) have been added as part of research on ship detection because of their extraordinary ability to extract and represent visual features. For example, in automatic target recognition and tracking capabilities that can be applinavigation systems, the role of CNNs is to interpret the visual data collected by the cameras. Thus, the detection information is added to and leverage maritime surveillancethe data from different sensors, allowing the data fusion processing systems to have enough information for decision-making.
- maritime surveillance
- classification
- localization
- detection
- artificial intelligence
- neural networks
1. Introduction
2. Image Acquisition
During image capture, several types of sensors can be used. However, the focus of this work is on the use of optical sensors, be they remote, installed on satellites or aircraft, or those that observe from a side view, such as those installed in inshore or offshore scenarios, such as on other ships or fixed constructions on land, usually near the coast. Optical images can still be divided into visible and infrared (IR) spectra, and the range of both is very similar, from the order of meters to at most a few kilometers. The main differences between optical sensors are related to sensitivity to the environment and the quality and quantity of visual information generated by the sensor [7]. Comparing the sensitivity to illumination, both sensor types have problems working outside their respective designations, i.e., while the visible light sensor performs poorly for nighttime applications, the IR sensor presents high saturation in images captured during the day. In addition, the visible light sensor is less robust to the effects of light reflection on ships caused by water dynamics. However, the visual data generated are more detailed when compared to the quality and quantity of elements captured by a visible sensor [7]. Thus, this sensor can lead to the training of detectors with higher reliability. Optical remote sensing images suffer from weather conditions, such as rain, waves, fog, and clouds, which causes the need, in some cases, for preprocessing of the image to improve the image quality that will be analyzed.3. Preprocessing Techniques
The preprocessing step can be used to improve the quality of images by introducing techniques that allow obtaining a dataset with better quality images through the attenuation of interference caused by elements of the environment, such as extreme brightness and contrast, in addition to the quality of the camera lenses used in the capture process [10][8]. Among the various techniques that can be used in preprocessing, it is possible to mention super-resolution techniques [11,12][9][10] and deblur [13,14][11][12]. The main benefit of improving images before they are used in location, classification, or detection models is usually the improvement of accuracy achieved only by increasing the quality of the dataset [15][13]. An example of detection enhancement can be seen in Figure 21.
3.1. SRCNN
The SRCNN model is based on an CNN architecture, trained to learn an end-to-end mapping between low and high-resolution images for the super-resolution (SR) problem. It was one of the first architectures that applied the concept of deep learning in the super-resolution task, achieving one of the best results for this task in 2015. When the authors proposed the use of CNNs, the most common was to use the traditional sparse-coding-based SR methods [18][16]. The model is divided into three stages; the first is responsible for performing the extraction and representation of low-quality images within the network. The second step is the application of a nonlinear mapping, where the layers of CNN extract as much information about the image. The last step is to rebuild the image at a higher resolution than the image applied to the template entry [18][16].3.2. SRResNet
The model SRResNet was developed with an architecture based on residual network (ResNet), but with modifications in the optimization of the MSE loss function to achieve high upscaling factors, 4×, as quoted in [22][20]. With this optimization, the model was consolidated in 2017 as the new state-of-the-art, and its performance was evaluated by peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM), two metrics widely used in image quality assessment [26][24]. Another proposal by the authors of [22][20] was to change the MSE loss function using model resources visual geometry group (VGG). With this, the authors compared the optimized version of the MSE with the version modified to use the VGG loss metrics. The result was that the model improved the visual metric mean opinion score (MOS) but had lower performance on the metrics of PSNR and SSIM [22][20].3.3. SRGAN
The model SRGAN is trained through a generative architecture based on the ResNet. This architecture generates images with super-resolution and has its loss analyzed through a second structure with a discriminative function, which only acts during training. The commission’s proposal SRGAN is to use a new resource-based loss function of the model VGG, which, when combined with the discriminating network, helps to detect the difference between the image generated about the reference image. According to metric-based tests MOS [27][25], which evaluates the perceptual quality of an empirically obtained image through a visual classification scale, the trained model achieves results close to the state of the art in the literature [22][20].3.4. EDSR
The model EDSR, as well as the other SR models already presented, also has its architecture based on ResNet. These models have characteristics similar to SRResNet. However, unnecessary modules are removed from the architecture to optimize the model. Among these changes, one can mention the residual blocks, which have removed the batch normalization (BN). This causes the model to be simplified and memory usage to be reduced [20][18]. Just as SRResNet achieves 4× upscaling factors, the EDSR model is also capable. In the work [20][18], the authors trained the model for upscaling of 2×, 3×, and 4×. In addition to achieving model time optimization and simplifying the architecture, the authors also had superior results compared to other networks that were tested, such as SRCNN, SRResNet, and MDSR.3.5. MDSR
The model MDSR was proposed by the same author who developed the EDSR model such that their architectures are described in [20][18]. The MDSR network has a certain increase in complexity compared to EDSR because it uses extra blocks with different scales at the beginning of the architecture. Removing the BN layers, as suggested in [20][18], is also adopted in this model [20][18]. Unlike EDSR, which reconstructs only a super-resolution image scale on the MDSR network, an initial upscaling is applied that operates with parallel image processing structures of different sizes. This allows for reducing various problems caused by variations in image scale. Both models, EDSR and MDSR, were proposed in the NTIRE 2017 Super-Resolution Challenge [28][26], taking first and second place, respectively. With this, the authors claimed that they managed simultaneously to achieve the state of the art in the topic of super-resolution and simultaneously transformed the architecture ResNet into a more compact model.3.6. ESRGAN
In three respects, the model ESRGAN is an improved version of the network SRGAN. The first was the replacement of residual blocks by residual-in-residual dense block (RRDB) to facilitate training, followed by the exchange of layers of BN by residual scaling and smaller initialization, as suggested in [20][18] because it allows the training of a more profound architecture. The second difference was the replacement of a GAN joint for a relativistic average GAN (RaGAN); instead of judging whether an image is true or false, this generative network can identify which image is more realistic. Finally, the perceptual loss was improved using VGG features before and after activation as in the SRGAN. This last change makes the model provide sharper edges and visually more satisfying results [23][21]. With the modifications made, the model reached the state of the art in 2018, presenting the best results of perceptual quality, with first place in the challenge perceptual image restoration and manipulation—super resolution (PIRM-SR) [17][15]. The test evaluated several models under the quality of visual perception metrics, PSNR and SSIM. From the evaluation of the performance of the models in this challenge, it was possible to notice that the increasing values of PSNR and SSIM were not always accompanied by an increase in perceptual quality. In many cases, this resulted in increasingly blurred and unnatural outputs, which gives more meaning to the previously cited results of [22][20].3.7. RankSRGAN
The RankSRGAN model is based on the GANs architecture but adopts a siamese architecture to learn perceptual metrics and rank images according to the quality score found during its training. This model combines different SR algorithms to improve perceptual metrics by combining other models [24][22]. To train the ranker, the authors used three templates, SRResNet, SRGAN, and ESRGAN. With their combination, RankSRGAN was able to optimize the natural image quality evaluator (NIQE) parameter [29][27], a visual metric that measures the naturalness of the image in the scene. With this, the model achieved superior performance to the individual models used when applied to the dataset of the PIRM-SR Challenge 2018 [24][22].3.8. DBPN
The DBPN model is an improved version of the SRCNN network, but instead of using predefined upsampling, it uses interleaved upsampling and downsampling layers. Unlike other methods that build the SR image feed-forwardly, ouresearchers' proposed networks focus on directly increasing SR resources by using multiple stages of ascending and descending sampling that feeds error predictions into each depth. The values of the error feedback of the steps of increase and scale reduction were used to guide the network to obtain a better result. The model performed similarly to the state-of-the-art performance in 2018. In addition, the network was trained with 8× magnification, higher than that used in the creation of SRResNet [19][17] and EDSR [20][18]. Unlike super-resolution techniques, deblurring techniques were developed to remove noise and blur present in the image, which hinders the visualization of the image. When noisy images are treated before being inserted into detection and classification systems, the system performance can increase considerably [30][28]. Some of the techniques that can be applied to the deblur task are deblur generative adversarial network (DeblurGAN), DeblurGAN-V2, and deblurring and shape recovery of fast moving objects (DeFMO).3.9. DeblurGAN
The DeblurGAN template is composed of a GAN architecture, and its purpose is to remove blur in images. The model features an architecture of CNN, composed of residual blocks (ResBlocks) consisting of a convolution layer, instance normalization layer, and ReLU activation [31][29]. The authors of DeblurGAN validated their results by applying the you only look once (YOLO) model to perform the detection and classification of objects in images with blur and images processed by the deblur model. There is a gain in accuracy in the YOLO results when inserted images are improved by the DeblurGAN model, proving that it significantly contributes to image quality and consequently to the performance of subsequent processing systems [31][29].3.10. DeblurGAN-V2
The DeblurGAN-V2 model is based on the construction of the original model DeblurGAN but with some modifications to improve the [32][30] network. Among them, the generative model in DeblurGAN-V2 integrates the technique feature pyramid network (FPN). This technique was initially developed for object detection purposes [33][31]. Still, in the case of the DeblurGAN-V2 model, the authors used FPN for the construction of a noisy image [32][30]. In addition to integrating the FPN technique, the new version allows the selection of different backbones. Each of the different backbones is designed to improve some of the performance parameters. For example, with the Inception-ResNetV2 architecture, you obtain a next-generation blur. In contrast, with the mobile network-depthwise separable convolution (MobileNet-DSC) architecture, you obtain an increase in processing speed, some 10 to 100 times faster than the top competitors in 2019 [32][30].3.11. DeFMO
Motion blur is one of the existing blur types, and it is caused by the rapid movement of objects when captured by cameras or by the quick scroll of the camera to capture still objects, recording photos or videos, with blur [34][32]. Thus, DeFMO is designed to act on this type of blur. The proposed network is a novel based on a ’self-supervised’ loss function that improves the model’s accuracy when applied to images with motion blur. By presenting a good generalization capability, this model can be applied to different areas in computer vision, such as the improvement of security cameras, microscopes, and photos with high noise levels [35][33]. This model is the first fully neural FMOs deblurring that fills the gap between deblurring, 3D modeling, and FMO subframe tracking for trajectory analysis.4. Processing Techniques
Most previously proposed models for image processing, that is, location, classification, or detection of ships, have focused on using handcrafted resources applied to image processing. These models are built with the expert knowledge of designers. Within the scope of handcraft features models, it is possible to point out several works that employ different techniques, such as Gabor filter in [36][34], for automatic target detection, discrete cosine transform (DCT) in [37][35] for maritime surveillance on non-stationary surface platforms, as well as Haar–Cascade [38][36], scale-invariant feature transform (SIFT) [39][37], local binary pattern (LBP) [40][38], support vector machine (SVM) [41][39], and histograms of oriented gradients (HOG) [42][40] for the remote sensing of ships. As a result, the extracted features reflect the limited aspects of the problem, generating a low response accuracy of the models and a low generalization. Thus, deep learning in the computer vision research community, such as CNNs proved to be more suitable for developing and training resource extractors [43][41]. The techniques based on CNN dominate the most recent works, as shown in Table 1, which details the evolution of the works over the years, pointing out aspects such as the type of image used, applications, and techniques involved in each of the works. They won great strength after winning the ImageNet challenge in 2012 and have been achieving excellent results in several image processing tasks for obtaining visual information [44][42]. Another point that collaborates with this type of network is the evolution of the sizes of the available datasets, given that CNNs usually require a large number of training samples. With this, the use of detection models based on CNNs has accelerated even more because, according to [45][43], a good object detector should improve when given more training data. Within these networks, there is a subclass, the region-based convolutional neural network (R-CNNs), whose working principle is based on a selective search for object detection, generating region proposals, as shown in Figure 32. Work related to this type of technique began with the R-CNN, proposed by Ross Girshick [46][44]. Since then, other variations have been proposed, such as fast R-CNN [45][43], faster R-CNN [47][45], mask R-CNN [48][46], single-shot detector (SSD) [49][47], YOLO [50][48], YOLOv2/9000 [51][49], YOLOv3 [52][50], YOLOv4 [52][50], and YOLOv5 [52][50]. These models have some modifications in their topologies to increase their speed and prediction performances or even to add a new function, as is the case of segmentation in mask R-CNN.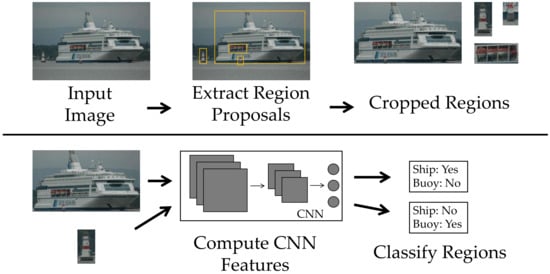
4.1. R-CNN
It emerged with the task of localizing objects through a CNN that could have high detection capability even with a small amount of annotated samples for its training. It is basically divided into three modules. The first is responsible for generating several region proposals without a specific category, by a method called selective search (SS) [53][51]. The second is an CNN, which extracts a fixed number of features for each of the proposals. Finally, the third module is based on a linear SVMs trained specifically for each possible class. With this, this network can not only locate the object, but also inform which of the possible classes it belongs to. This classification is performed through a score generated by the [46][44] classifiers.4.2. Fast R-CNN
Fast R-CNN introduces single-stage training with an update of all layers and avoids disk storage for feature caching [45][43]. Regarding the detection task, it has the advantage of achieving higher mean average precision (mAP) compared to its standard version. In this model, the linear SVMs used in R-CNN is replaced by a softmax classifier. Using the same training algorithm and hyperparameters used in R-CNN, they train a new SVM to be the classifier for fast R-CNN and justify the use of softmax by achieving a slight advantage in mAP over it [45][43].4.3. Faster R-CNN
This model uses the region proposal network (RPN), which comprises CNNs capable of providing region proposals to fast R-CNN, informing at the same time the object boundaries and the scores of each proposed region. RPN calculates proposal regions much faster and more efficiently compared to SS. Moreover, it brings another advantage by sharing convolutional layers between the proposal generation network and the classification network, optimizing the network training [47][45].4.4. Mask R-CNN
It follows the same principle as faster R-CNN but has a second output in the model for segmenting objects [48][46]. The pixel-by-pixel object segmentation is performed through the superposition of an outline, applied by this second output. This overlay mask is applied to each region of interest (RoI) and is based on the fully connected neural network (FCNN) model [54][52]. 4.5. SSD Compared to previous methods that take two stages, SSD is a more straightforward method because it encapsulates all computations in a single deep neural net, eliminating the need to generate object proposals in multiple stages. This increases the speed of the system and facilitates training by providing a unified structure for training and inference. It scores bounding boxes and adjusts to best match the shape of the object and uses boxes of different proportions to handle objects of different sizes [49][47].4.6. YOLO
Like SSD, this is also a single-stage detector, which can have its optimized performance within its unified detection model. In this method, object detection is performed as a regression task for bounding boxes, which, at the same time, provides the object locations with their respective classes. The primary source of error in this network is in the incorrect location of small objects [50][48].| Image View | Approaches | ||||
|---|---|---|---|---|---|
| Papers | Side View | Remote | Localization | Classification | Techniques/Models |
| 2017 [55][53] | - | x | x | - | FusionNet |
| 2017 [56][54] | x | - | - | x | VGG16 |
| 2018 [57][55] | x | - | x | - | Faster R-CNN+ResNet |
| 2018 [58][56] | - | x | x | - | ResNet-50 |
| 2018 [59][57] | - | x | x | - | SNN |
| 2018 [60][58] | - | x | x | x | Faster R-CNN+Inception-ResNet |
| 2018 [61][59] | - | x | x | - | RetinaNet |
| 2018 [62][60] | - | x | x | x | R-CNN |
| 2018 [63][61] | - | x | x | - | R-CNN |
| 2019 [64][62] | - | x | - | x | VGG19 |
| 2019 [65][63] | - | x | - | x | VGG16 |
| 2019 [66][64] | x | - | - | x | Skip-ENet |
| 2019 [67][65] | - | x | x | x | Cascade R-CNN+B2RB |
| 2019 [68][66] | - | x | - | x | ResNet-34 |
| 2019 [69][67] | x | - | x | - | YOLOv3 |
| 2019 [70][68] | - | x | x | x | VGG16 |
| 2019 [71][69] | x | - | x | - | Faster R-CNN |
| 2020 [72][70] | - | x | x | x | SSS-Net |
| 2020 [73][71] | - | x | x | x | YOLOv3 |
| 2020 [74][72] | - | x | x | x | CNN |
| 2020 [75][73] | x | - | x | - | CNN Segmentation |
| 2020 [76][74] | - | x | x | - | YOLO |
| 2020 [77][75] | - | x | x | x | ResNet-50+RNP |
| 2020 [78][76] | x | - | - | x | CNN |
| 2020 [79][77] | x | - | x | x | YOLOv4 |
| 2020 [80][78] | - | x | x | - | YOLOv3 |
| 2020 [81][79] | - | x | - | x | VGG16 |
| 2020 [82][80] | x | - | x | - | Mask R-CNN+YOLOv1 |
| 2021 [83][81] | - | x | x | x | Mask RPN+DenseNet |
| 2021 [84][82] | - | x | x | - | VGG16 |
| 2021 [85][83] | x | - | x | x | SSD MobileNetV2 |
| 2021 [86][84] | x | - | x | x | YOLOv3 |
| 2021 [87][85] | x | - | x | - | Faster R-CNN |
| 2021 [88][86] | x | - | x | - | R-CNN |
| 2021 [89][87] | x | - | x | x | BLS |
| 2021 [90][88] | x | - | x | - | YOLOv5 |
| 2021 [3] | x | - | x | x | MobileNet+YOLOv4 |
| 2021 [91][89] | - | x | x | x | Cascade R-CNN |
| 2021 [92][90] | x | - | x | x | YOLOv3 |
| 2021 [93][91] | - | x | x | x | YOLOv3 |
| 2021 [94][92] | x | - | x | x | YOLOv3 |
| 2021 [95][93] | - | x | x | x | YOLOv4 |
| 2021 [96][94] | x | - | x | x | ResNet-152 |
| 2021 [97][95] | - | x | x | - | Faster R-CNN |
| 2022 [92][90] | x | - | x | x | YOLOv4 |
| 2022 [98][96] | - | x | x | - | YOLOv3 |
| 2022 [99][97] | x | - | x | x | MobileNetV2+YOLOv4 |
| 2022 [100][98] | - | x | x | x | YOLOv5 |
References
- Park, J.; Cho, Y.; Yoo, B.; Kim, J. Autonomous collision avoidance for unmanned surface ships using onboard monocular vision. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–6.
- Dumitriu, A.; Miceli, G.E.; Schito, S.; Vertuani, D.; Ceccheto, P.; Placco, L.; Callegaro, G.; Marazzato, L.; Accattino, F.; Bettio, A.; et al. OCEANS-18: Monitoring undetected vessels in high risk maritime areas. In Proceedings of the 2018 5th IEEE International Workshop on Metrology for AeroSpace (MetroAeroSpace), Rome, Italy, 20–22 June 2018; pp. 669–674.
- Yue, T.; Yang, Y.; Niu, J.M. A Light-weight Ship Detection and Recognition Method Based on YOLOv4. In Proceedings of the 2021 4th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Changsha, China, 26–28 March 2021; pp. 661–670.
- Liu, H.; Xu, X.; Chen, X.; Li, C.; Wang, M. Real-Time Ship Tracking under Challenges of Scale Variation and Different Visibility Weather Conditions. J. Mar. Sci. Eng. 2022, 10, 444.
- Shan, Y.; Zhou, X.; Liu, S.; Zhang, Y.; Huang, K. SiamFPN: A Deep Learning Method for Accurate and Real-Time Maritime Ship Tracking. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 315–325.
- Duan, Y.; Li, Z.; Tao, X.; Li, Q.; Hu, S.; Lu, J. EEG-Based Maritime Object Detection for IoT-Driven Surveillance Systems in Smart Ocean. IEEE Internet Things J. 2020, 7, 9678–9687.
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing From Electro-Optical Sensors for Object Detection and Tracking in a Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016.
- Talab, M.A.; Awang, S.; Najim, S.A.d.M. Super-Low Resolution Face Recognition using Integrated Efficient Sub-Pixel Convolutional Neural Network (ESPCN) and Convolutional Neural Network (CNN). In Proceedings of the 2019 IEEE International Conference on Automatic Control and Intelligent Systems (I2CACIS), Selangor, Malaysia, 29 June 2019; pp. 331–335.
- Robey, A.; Ganapati, V. Optimal physical preprocessing for example-based super-resolution. Opt. Express 2018, 26, 31333.
- Yang, Z.; Shi, P.; Pan, D. A Survey of Super-Resolution Based on Deep Learning. In Proceedings of the 2020 International Conference on Culture-oriented Science Technology (ICCST), Beijing, China, 30–31 October 2020; pp. 514–518.
- Xie, J.; Xu, L.; Chen, E. Image Denoising and Inpainting with Deep Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, NV, USA, 3–6 December 2012; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; Volume 25.
- Sada, M.; Goyani, M. Image Deblurring Techniques—A Detail Review. In Proceedings of the National Conference on Advanced Research Trends in Information and Computing Technologies (NCARTICT-2018), Ahmedabad, Gujarat, India, 20 January 2018; pp. 176–188.
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Data Preprocessing for Supervised Learning. Int. J. Comput. Sci. 2006, 1, 111–117.
- Yang, W.; Zhang, X.; Tian, Y.; Wang, W.; Xue, J.H.; Liao, Q. Deep Learning for Single Image Super-Resolution: A Brief Review. IEEE Trans. Multimed. 2019, 21, 3106–3121.
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM challenge on perceptual image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018.
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307.
- Zabalza, M.; Bernardini, A. Super-Resolution of Sentinel-2 Images Using a Spectral Attention Mechanism. Remote Sens. 2022, 14, 2890.
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144.
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep Back-ProjectiNetworks for Single Image Super-Resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4323–4337.
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114.
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018.
- Zhang, W.; Liu, Y.; Dong, C.; Qiao, Y. Ranksrgan: Generative adversarial networks with ranker for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3096–3105.
- Chen, W.; Liu, C.; Yan, Y.; Jin, L.; Sun, X.; Peng, X. Guided Dual Networks for Single Image Super-Resolution. IEEE Access 2020, 8, 93608–93620.
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444.
- Ieremeiev, O.; Lukin, V.; Okarma, K.; Egiazarian, K. Full-reference quality metric based on neural network to assess the visual quality of remote sensing images. Remote Sens. 2020, 12, 2349.
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. NTIRE 2017 Challenge on Single Image Super-Resolution: Methods and Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017.
- Xu, N.; Ma, D.; Ren, G.; Huang, Y. BM-IQE: An image quality evaluator with block-matching for both real-life scenes and remote sensing scenes. Sensors 2020, 20, 3472.
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep image deblurring: A survey. Int. J. Comput. Vis. 2022, 1–28.
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 2018 IEEE/CVF International Conference on Computer Vision (ICCV), Salt Lake City, UT, USA, 18–23 December 2018; pp. 8183–8192.
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8877–8886.
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944.
- Rozumnyi, D.; Oswald, M.R.; Ferrari, V.; Matas, J.; Pollefeys, M. DeFMO: Deblurring and Shape Recovery of Fast Moving Objects. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021.
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777.
- Rahmani, N.; Behrad, A. Automatic marine targets detection using features based on Local Gabor Binary Pattern Histogram Sequence. In Proceedings of the 2011 1st International eConference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 13–14 October 2011; pp. 195–201.
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean. Eng. 2017, 141, 53–63.
- Mutalikdesai, A.; Baskaran, G.; Jadhav, B.; Biyani, M.; Prasad, J.R. Machine learning approach for ship detection using remotely sensed images. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 1064–1068.
- Shuai, T.; Sun, K.; Shi, B.; Chen, J. A ship target automatic recognition method for sub-meter remote sensing images. In Proceedings of the 2016 4th International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Guangzhou, China, 4–6 July 2016; pp. 153–156.
- Yang, F.; Xu, Q.; Li, B. Ship Detection From Optical Satellite Images Based on Saliency Segmentation and Structure-LBP Feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606.
- Song, Z.; Sui, H.; Hua, L. How to Quickly Find the Object of Interest in Large Scale Remote Sensing Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4843–4845.
- Li, W.; Fu, K.; Sun, H.; Sun, X.; Guo, Z.; Yan, M.; Zheng, X. Integrated Localization and Recognition for Inshore Ships in Large Scene Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 936–940.
- Thombre, S.; Zhao, Z.; Ramm-Schmidt, H.; Vallet García, J.M.; Malkamäki, T.; Nikolskiy, S.; Hammarberg, T.; Nuortie, H.; Bhuiyan, M.Z.H.; Särkkä, S.; et al. Sensors and AI Techniques for Situational Awareness in Autonomous Ships: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 64–83.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252.
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448.
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149.
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988.
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision – ECCV 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788.
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525.
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for Autonomous Landing Spot Detection in Faulty UAVs. Sensors 2022, 22, 464.
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Cheng, D.; Meng, G.; Xiang, S.; Pan, C. FusionNet: Edge Aware Deep Convolutional Networks for Semantic Segmentation of Remote Sensing Harbor Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 5769–5783.
- Kumar, A.S.; Sherly, E. A convolutional neural network for visual object recognition in marine sector. In Proceedings of the 2017 2nd International Conference for Convergence in Technology (I2CT), Mumbai, India, 7–9 April 2017; pp. 304–307.
- Fu, H.; Li, Y.; Wang, Y.; Han, L. Maritime Target Detection Method Based on Deep Learning. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation (ICMA), Changchun, China, 5–8 August 2018; pp. 878–883.
- Li, M.; Guo, W.; Zhang, Z.; Yu, W.; Zhang, T. Rotated Region Based Fully Convolutional Network for Ship Detection. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 673–676.
- Liu, Y.; Cai, K.; Zhang, M.h.; Zheng, F.b. Target detection in remote sensing image based on saliency computation of spiking neural network. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 2865–2868.
- Voinov, S.; Krause, D.; Schwarz, E. Towards Automated Vessel Detection and Type Recognition from VHR Optical Satellite Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 4823–4826.
- Wang, Y.; Li, W.; Li, X.; Sun, X. Ship Detection by Modified RetinaNet. In Proceedings of the 2018 10th IAPR Workshop on Pattern Recognition in Remote Sensing (PRRS), Beijing, China, 19–20 August 2018; pp. 1–5.
- Zhang, Y.; You, Y.; Wang, R.; Liu, F.; Liu, J. Nearshore vessel detection based on Scene-mask R-CNN in remote sensing image. In Proceedings of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22–24 August 2018; pp. 76–80.
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection With Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749.
- Hui, Z.; Na, C.; ZhenYu, L. Combining a Deep Convolutional Neural Network with Transfer Learning for Ship Classification. In Proceedings of the 2019 12th International Conference on Intelligent Computation Technology and Automation (ICICTA), Xiangtan, China, 26–27 October 2019; pp. 16–19.
- Jiang, B.; Li, X.; Yin, L.; Yue, W.; Wang, S. Object Recognition in Remote Sensing Images Using Combined Deep Features. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 606–610.
- Kim, H.; Koo, J.; Kim, D.; Park, B.; Jo, Y.; Myung, H.; Lee, D. Vision-Based Real-Time Obstacle Segmentation Algorithm for Autonomous Surface Vehicle. IEEE Access 2019, 7, 179420–179428.
- Sun, J.; Zou, H.; Deng, Z.; Cao, X.; Li, M.; Ma, Q. Multiclass Oriented Ship Localization and Recognition In High Resolution Remote Sensing Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1288–1291.
- Ward, C.M.; Harguess, J.; Hilton, C. Ship Classification from Overhead Imagery using Synthetic Data and Domain Adaptation. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–5.
- Zheng, R.; Zhou, Q.; Wang, C. Inland River Ship Auxiliary Collision Avoidance System. In Proceedings of the 2019 18th International Symposium on Distributed Computing and Applications for Business Engineering and Science (DCABES), Wuhan, China, 8–10 November 2019; pp. 56–59.
- Zong-ling, L.; Lu-yuan, W.; Ji-yang, Y.; Bo-wen, C.; Liang, H.; Shuai, J.; Zhen, L.; Jian-feng, Y. Remote Sensing Ship Target Detection and Recognition System Based on Machine Learning. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1272–1275.
- Zou, J.; Yuan, W.; Yu, M. Maritime Target Detection Of Intelligent Ship Based On Faster R-CNN. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 4113–4117.
- Huang, Z.; Sun, S.; Li, R. Fast Single-Shot Ship Instance Segmentation Based on Polar Template Mask in Remote Sensing Images. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1236–1239.
- Chen, Y.; Yang, S.; Suo, Y.; Chen, W. Research on Recognition of Marine Ships under Complex Conditions. In Proceedings of the 2020 Chinese Automation Congress (CAC), Guangzhou, China, 27–30 August 2020; pp. 5748–5753.
- Jin, L.; Liu, G. A Convolutional Neural Network for Ship Targets Detection and Recognition in Remote Sensing Images. In Proceedings of the 2020 IEEE 9th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 11–13 December 2020; Volume 9, pp. 139–143.
- Kelm, A.P.; Zölzer, U. Walk the Lines: Object Contour Tracing CNN for Contour Completion of Ships. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3993–4000.
- Li, X.; Cai, K. Method research on ship detection in remote sensing image based on YOLO algorithm. In Proceedings of the 2020 International Conference on Information Science, Parallel and Distributed Systems (ISPDS), Xi’an, China, 14–16 August 2020; pp. 104–108.
- Li, J.; Tian, J.; Gao, P.; Li, L. Ship Detection and Fine-Grained Recognition in Large-Format Remote Sensing Images Based on Convolutional Neural Network. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 2859–2862.
- Syah, A.; Wulandari, M.; Gunawan, D. Fishing and Military Ship Recognition using Parameters of Convolutional Neural Network. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 286–290.
- Wang, Y.; Wang, L.; Jiang, Y.; Li, T. Detection of Self-Build Data Set Based on YOLOv4 Network. In Proceedings of the 2020 IEEE 3rd International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 27–29 September 2020; pp. 640–642.
- Yulin, T.; Jin, S.; Bian, G.; Zhang, Y. Shipwreck Target Recognition in Side-Scan Sonar Images by Improved YOLOv3 Model Based on Transfer Learning. IEEE Access 2020, 8, 173450–173460.
- Zhang, X.; Lv, Y.; Yao, L.; Xiong, W.; Fu, C. A New Benchmark and an Attribute-Guided Multilevel Feature Representation Network for Fine-Grained Ship Classification in Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1271–1285.
- Zhao, D.; Li, X. Ocean ship detection and recognition algorithm based on aerial image. In Proceedings of the 2020 Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2020; pp. 218–222.
- Han, Y.; Yang, X.; Pu, T.; Peng, Z. Fine-Grained Recognition for Oriented Ship Against Complex Scenes in Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18.
- Gong, P.; Zheng, K.; Jiang, Y.; Liu, J. Water Surface Object Detection Based on Neural Style Learning Algorithm. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8539–8543.
- Boyer, A.; Abiemona, R.; Bolic, M.; Petriu, E. Vessel Identification using Convolutional Neural Network-based Hardware Accelerators. In Proceedings of the 2021 IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications (CIVEMSA), Virtual, 18–20 June 2021; pp. 1–6.
- Chang, L.; Chen, Y.T.; Hung, M.H.; Wang, J.H.; Chang, Y.L. YOLOv3 Based Ship Detection in Visible and Infrared Images. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3549–3552.
- Zhou, J.; Jiang, P.; Zou, A.; Chen, X.; Hu, W. Ship Target Detection Algorithm Based on Improved YOLOv5. J. Mar. Sci. Eng. 2021, 9, 908.
- Sali, S.M.; Manisha, N.L.; King, G.; Vidya Mol, K. A Review on Object Detection Algorithms for Ship Detection. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; Volume 1, pp. 1–5.
- Su, H.; Zuo, Y.; Li, T. Ship detection in navigation based on broad learning system. In Proceedings of the 2021 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Chengdu, China, 18–20 June 2021; pp. 318–322.
- Ting, L.; Baijun, Z.; Yongsheng, Z.; Shun, Y. Ship Detection Algorithm based on Improved YOLO V5. In Proceedings of the 2021 6th International Conference on Automation, Control and Robotics Engineering (CACRE), Dalian, China, 15–17 July 2021; pp. 483–487.
- Zhang, C.; Xiong, B.; Kuang, G. Ship Detection and Recognition in Optical Remote Sensing Images Based on Scale Enhancement Rotating Cascade R-CNN Networks. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3545–3548.
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection From Visual Image. IEEE Access 2021, 9, 16692–16706.
- Chen, L.; Shi, W.; Deng, D. Improved YOLOv3 Based on Attention Mechanism for Fast and Accurate Ship Detection in Optical Remote Sensing Images. Remote Sens. 2021, 13, 660.
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean. Eng. 2021, 235, 109435.
- Hu, J.; Zhi, X.; Shi, T.; Zhang, W.; Cui, Y.; Zhao, S. PAG-YOLO: A Portable Attention-Guided YOLO Network for Small Ship Detection. Remote Sens. 2021, 13, 3059.
- Leonidas, L.A.; Jie, Y. Ship Classification Based on Improved Convolutional Neural Network Architecture for Intelligent Transport Systems. Information 2021, 12, 302.
- Dong, Y.; Chen, F.; Han, S.; Liu, H. Ship Object Detection of Remote Sensing Image Based on Visual Attention. Remote Sens. 2021, 13, 3192.
- Su, N.; Huang, Z.; Yan, Y.; Zhao, C.; Zhou, S. Detect Larger at Once: Large-Area Remote-Sensing Image Arbitrary-Oriented Ship Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5.
- Xie, P.; Tao, R.; Luo, X.; Shi, Y. YOLOv4-MobileNetV2-DW-LCARM: A Real-Time Ship Detection Network. In Proceedings of the Knowledge Management in Organisations, Hagen, Germany, 11–14 July 2022; Uden, L., Ting, I.H., Feldmann, B., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 281–293.
- Li, L.; Jiang, L.; Zhang, J.; Wang, S.; Chen, F. A Complete YOLO-Based Ship Detection Method for Thermal Infrared Remote Sensing Images under Complex Backgrounds. Remote Sens. 2022, 14, 1534.