Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Vivi Li and Version 1 by Rahul Gomes.
Coronavirus disease (COVID-19) has had a significant impact on global health since the start of the pandemic in 2019. As of June 2022, over 539 million cases have been confirmed worldwide with over 6.3 million deaths as a result. Artificial Intelligence (AI) solutions such as machine learning and deep learning have played a major part in this pandemic for the diagnosis and treatment of COVID-19.
- COVID-19 prognosis
- deep learning
- machine learning
- CT scan
- X-rays
1. Introduction
COVID-19 is a viral infectious disease caused by SARS-CoV-2 that affects the respiratory system of infected persons and can range from mild to severe symptoms. The spread of the disease is predominantly through small aerosol particles that are expelled when coughing, sneezing, breathing, or talking. Comorbidities such as cardiovascular disease, diabetes, chronic respiratory disease, or cancer can increase the chances of developing serious illness or medical complications [1]. COVID-19 is primarily diagnosed using reverse transcription polymerase chain reaction (RT-PCR) tests which includes specific detection of the sequences for the nucleocapsid, envelope, spike, and RNA-dependent RNA polymerase proteins of the virus [1]. These tests have high specificity, but their sensitivity rates could be as low as 60–70% [2]. The use of artificial intelligence (AI) in this area has made significant contributions in this regard to identify, forecast, and treat COVID-19. There are several forms of medical data ranging from text to images in the form of X-rays or CT scans. Text data can include patient health and several factors being recorded in the hospital after COVID-19 diagnosis. Radiation information can be used to diagnose COVID-19 and also study the progression of this disease. Machine Learning algorithms are equipped with the potential to detect hidden trends and aid a clinician in the decision-making process which can save countless lives and utilize hospital resources in an optimal way. However, to train such accurate models, machine learning algorithms need access to huge datasets.
The use of machine learning models as diagnostic and prognostic tools helps to increase both accuracy and speed while ensuring desired patient outcomes. Prior to COVID-19, researchers and clinicians have had tremendous success in using machine learning to identify and classify chest radiographs for multiple applications including the diagnosis of pneumonia [3,4][3][4]. Machine learning algorithms like Naïve Bayes, K-nearest neighbor and Support Vector Machines(SVM) were all optimized with the best features. Machine learning has also been applied to predict symptomatic intracranial hemorrhaging from brain CTs and clinical variables in patients suffering from acute ischemic stroke [5]. Results were used to determine whether to administer intravenous thrombolysis (tPA) which can result in the dissolution of the blood clot or can lead to complications from intracranial hemorrhaging. Machine learning also finds application in the identification of liver tumor boundaries in CT imaging [6]. Machine learning techniques like AdaBoost allowed a model to learn diverse intensity distributions of the tumor regions and then use those results for developing a detection algorithm. Machine learning also finds applications in fields such as urinary bladder cancer staging in CT urography [7]. Various automated segmentation techniques can detect bladder lesions and then extract both texture and morphological features for classification.
2. Machine Architectures Used in COVID-19 Diagnosis
Machine learning refers to the process of using data for generating a model followed by using that model to make predictions. The most commonly used Maximum Likelihood Classification involves the calculation of the probability that a given feature belongs to a specific class label [10,11][8][9]. Datasets used for training contains pre-selected feature values that correspond to these classes which in ouresearchers' case could be either ‘normal’ or ‘COVID-19’. Classification is done by determining two values for the classes, the mean and the covariance which is then used in a normal distribution for probability estimation. Each record/data point will be assigned a probability for every class and the highest probability class is selected for the data point. For COVID-19 diagnosis, the commonly used machine learning models identified included random forests, and support vector machines (SVM).
2.1. Machine Learning Models
Random Forests are an ensemble learning method of machine learning that performs classification, regression, and other tasks through the use of decision trees. For the Kth tree, a random vector is generated that is independent of the past vectors but with the same distribution. From this random vector and the training set, a tree is grown, resulting in a classifier. Thus, a random forest classifier consists of a large collection of tree-structured classifiers and each tree casts a vote for the most popular class [12][10]. The resiliency of this system allows for the addition of more trees to not induce over-fitting. Random forests converge towards a limited generalization error value as the number of trees increases. The accuracy of this method is dependent on the strength of the tree classifiers along with the correlation between them. SVM is a supervised learning method in machine learning that is used for classification, regression, and outlier detection. Classification can be either binary or multi-class depending on the dataset. The dataset can be described as p-dimensional vectors which can be separated by a p—1-dimensional hyperplane called a linear classifier. A hyperplane is a subspace whose dimension is one less than that of its ambient space. The optimal hyperplane is the linear decision function with the maximum margins between the vectors of the two classes that are being classified [13][11]. Figure 21 shows how hyperplanes are used to separate class labels. These vectors that are on the margin can be described as support vectors. To create this separation between the two, these data are transformed into a higher dimensional space that makes classification easier.
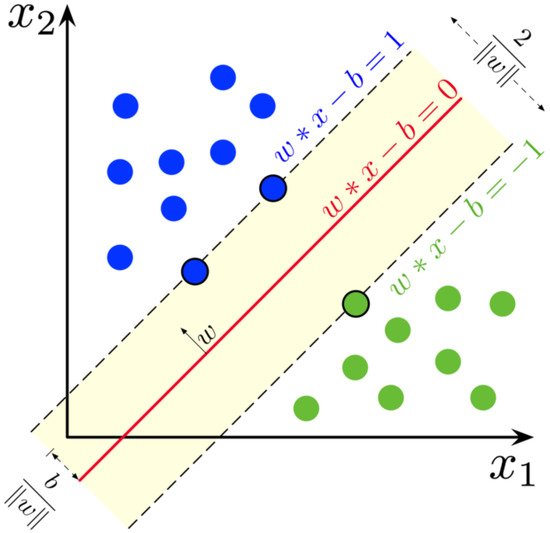
Figure 21. Support vectors on yellow area, are used to create boundaries also known as hyperplanes. The SVM in the figure is using a linear kernel denoted by the straight line equation. Image distributed under a CC BY-SA 4.0 license.
2.2. Deep Neural Networks
A deep neural network (DNN) is a type of machine learning which uses multiple consecutive hidden layers between the input and output. These hidden layers are used to extract and process the information received, making weighted calculations. When a deep neural network is trained, the weights are adjusted automatically to more closely match labels on manually identified data. The image of a DNN is shown in Figure 32. Here the hidden layers are represented by blue, while yellow represents input and orange represents output.
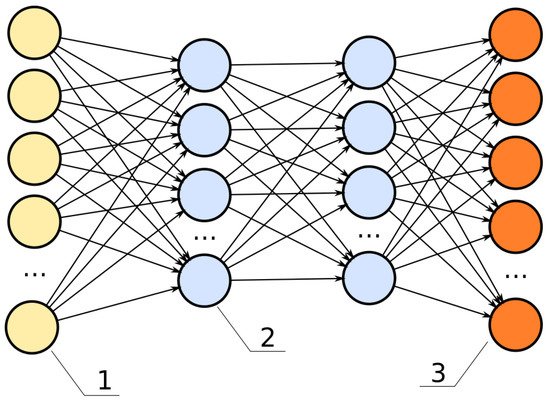
Figure 32. The structure of DNN model. Image distributed under a CC BY-SA 4.0 license. Number one represents input layer followed by two which are the hidden layers and finally three which is the output layer.
2.3. Convolutional Neural Networks
Convolutional neural networks, or CNNs, are deep learning algorithms useful for image processing. A CNN is overall a black box technique, where the input and output are the only parts wresearchers can observe. The internal workings of a CNN can be understood in theory, but weresearchers cannot easily discover the internal workings of a trained CNN. This can be a setback, as weresearchers do not truly know what part of an image the model considers when making the classification. However, high accuracy on a large variety of testing images serves as proof that a model is performing well. Segmentation networks are slightly superior to classification networks in this regard, as the output image shows what the model is seeing. To extract features from an image, the CNN utilizes kernels. These kernels scan over every pixel of the image (for a stride of one), and a kernel size larger than 2×2 will consider a matrix including three neighboring pixels. A larger kernel size considers more surrounding pixels. For a kernel size of 3×3, it also views the eight surrounding pixels. A kernel utilizes a weighted matrix to interpret the pixel and send it to the feature map. Each convolution outputs a full feature map from the input image. The size of this feature map can change based on the stride used—a stride of one will not change the image size, but a stride of two will halve the size of the image. Stride refers to how far the kernel moves, so a stride greater than one will skip half of the pixels to create the feature map. This is used for downsampling, and it is useful for increasing the computational efficiency of the model. CNNs use multiple layers of convolutions in order to pick up on different levels of features. Earlier layers pick up low-level features, such as lines or curves in the image. Later (or deeper) layers begin to pick up on the high-level features of the image, which are specific details in the image. For example, one low-level feature of a face would be the curve of the forehead. A higher level feature could be the eyes or something equally specific to the image. Besides being used to primarily process images, CNNs have also found a wide variety of applications in other domains like bioinformatics and cybersecurity among others. In cybersecurity research such as [14][12], the authors present how features can be represented in a matrix format for malware detection applications using CNN. Authors in [15][13] report the applicability of using CNNs for DNA sequence interpretation. CNNs have also been applied for named entity recognition of biomedical text [16][14].
The input of a CNN—whether the task is classification or segmentation—is an image. When a CNN model is created, the input shape is specified, and cannot be changed without retraining an entirely new model. If the model is designed to take an input image of shape 256 × 256, an image of shape 128 × 128 must be resized. Preprocessing includes a step in which the images are resized to fit the determined input shape.
The output of CNN defines the differences between model tasks. A classification model, such as ResNet or MobileNet, will provide a prediction of which class the entire image belongs to. This comes as a probability for each class—for two classes, there will be two numbers, each between 0 and 1. A simple binary classification task decides which of the two classes the image belongs to. For COVID-19 detection, these models are often used to classify images as either positive or negative. Segmentation models, on the other hand, will predict the class of every separate pixel of an image. This generates the predicted mask.
2.3.1. UNet
The UNet model [17][15] architecture shown in Figure 43 is a 2D convolutional neural network that was designed to give precise segmentation given fewer training images. The model is also noted for being very efficient, generating a segmentation of a 256×256 image in a matter of seconds. This architecture follows a contracting path, followed by an expansive path. The diagram of this architecture forms a U-shape, hence the name UNet. The contracting path (left) uses a traditional CNN shape to extract the information while reducing the size of the image. The model uses blocks that contain two 3×3 convolutional layers, a ReLU function, and then a 2×2 Max Pooling layer. The Max Pooling layer uses a stride of 2, which performs downsampling. After each block, the number of feature channels is doubled. The left and right paths of the UNet architecture match such that after each downsample, a cropped version of the feature map is passed on to the respective block during upsampling. The expansive path (right) consists of the mentioned upsampling of the feature map, a 2×2 convolution, a concatenation with the downsample’s respective feature map, two 3×3 convolutions, and finally a ReLU. The 2×2 convolution serves to halve the number of feature channels on the map.
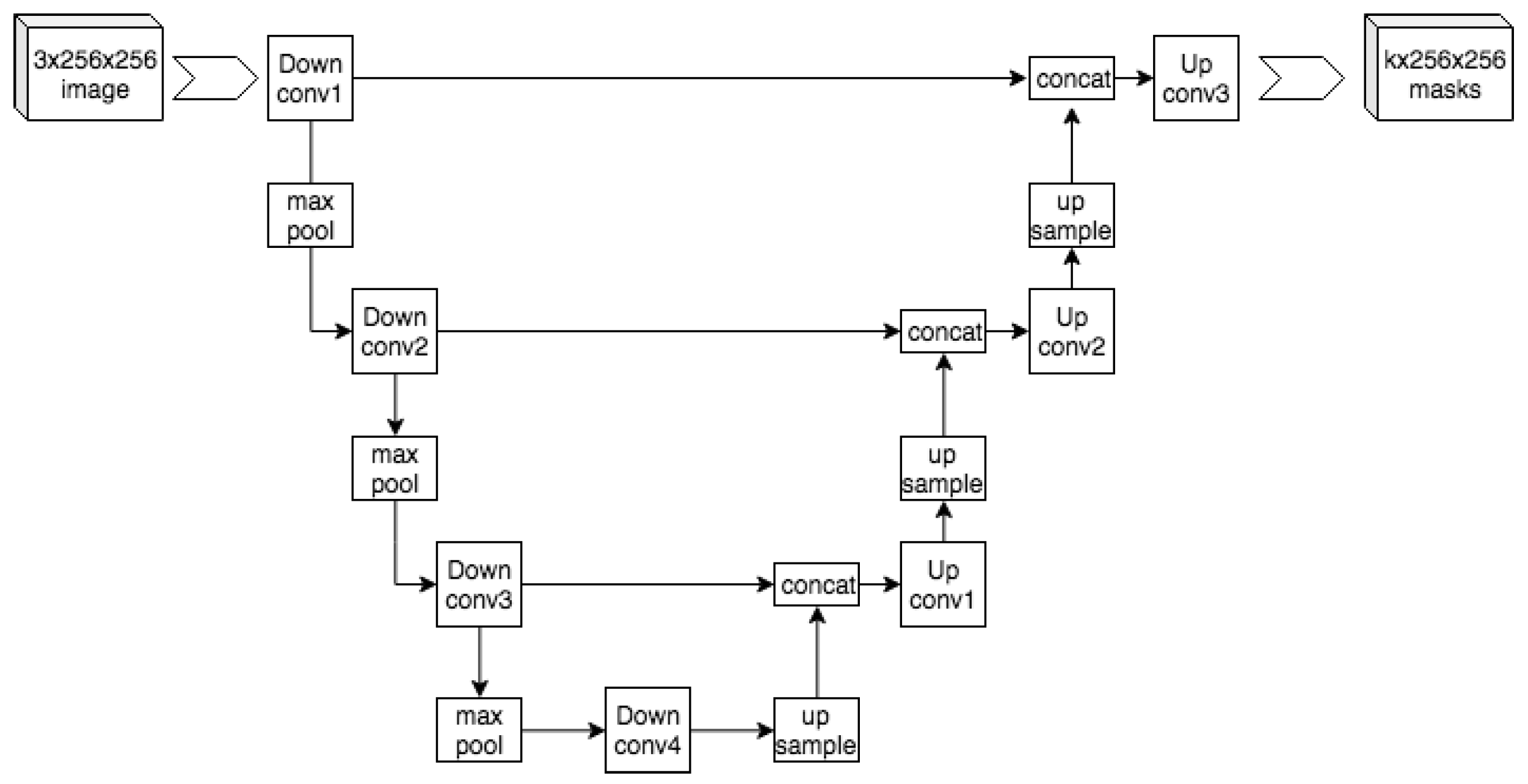
Figure 43. The structure of a UNet model similar to the original one proposed in [17]. Image distributed under a CC BY-SA 4.0 license.
The structure of a UNet model similar to the original one proposed in [15]. Image distributed under a CC BY-SA 4.0 license.
2.3.2. VGG Frameworks
The visual geometry group (VGG) model [18][16] shown in Figure 54 is a basic deep 2D convolutional neural network architecture. The general structure of a VGG model uses many blocks of convolutional layers, followed by three fully connected layers for the task of classification. The convolutional layers use a kernel size of 3×3, with a convolutional stride of 1 pixel, with a standard input size of 224×224 pixels. Each convolutional block contains a couple of convolutional layers and ends with a pooling layer. This pooling layer is used to reduce the dimensions of the image before moving to the next block. The fully connected layers use the ReLU activation, and the final layer uses the SoftMax activation to predict the output. There are 4096 channels in the first two layers, while the channel in the last layer is equal to the number of output classes. For the ImageNet database (which VGG was created for), there are 1000 channels for each of the 1000 image classes. There are a few types of VGG architectures, denoted by the depth of the layers—VGG16 uses 16 neural network layers (13 convolutional with three fully connected), while VGG19 uses 19.
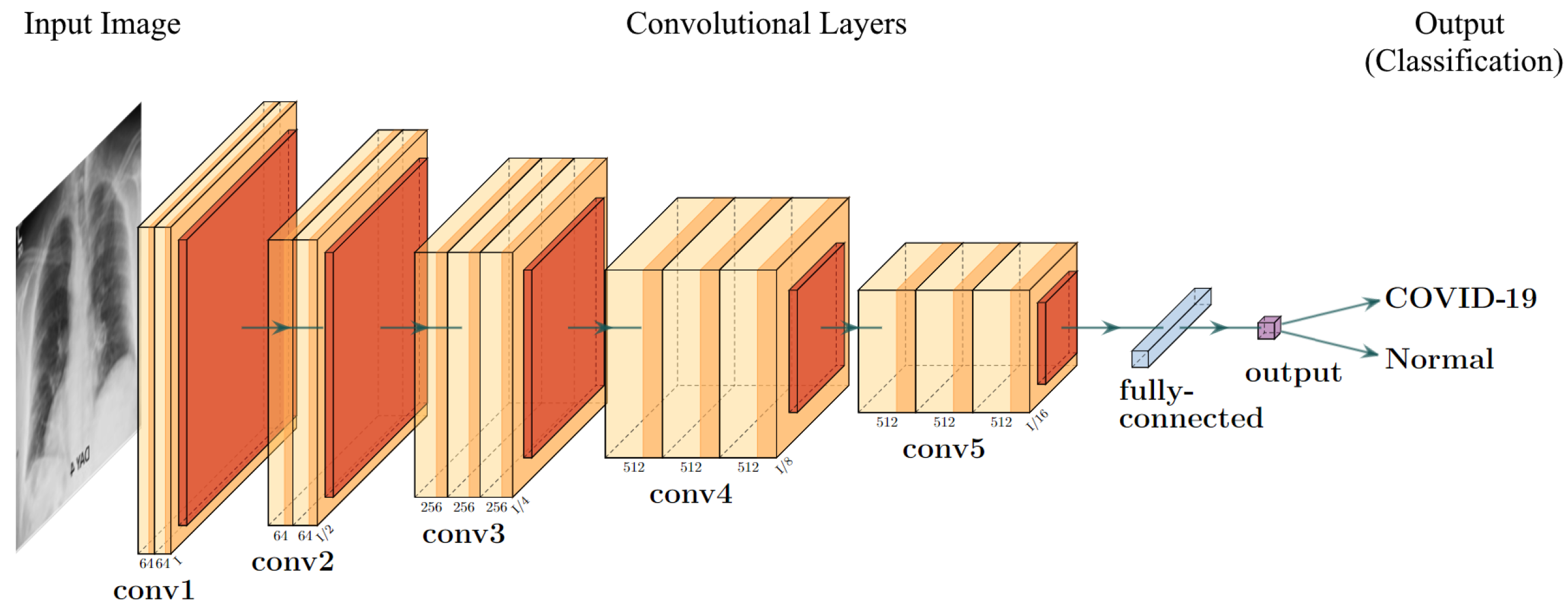
Figure 54.
The structure of VGG-16 model adapted for prediction of COVID-19 using CXR.
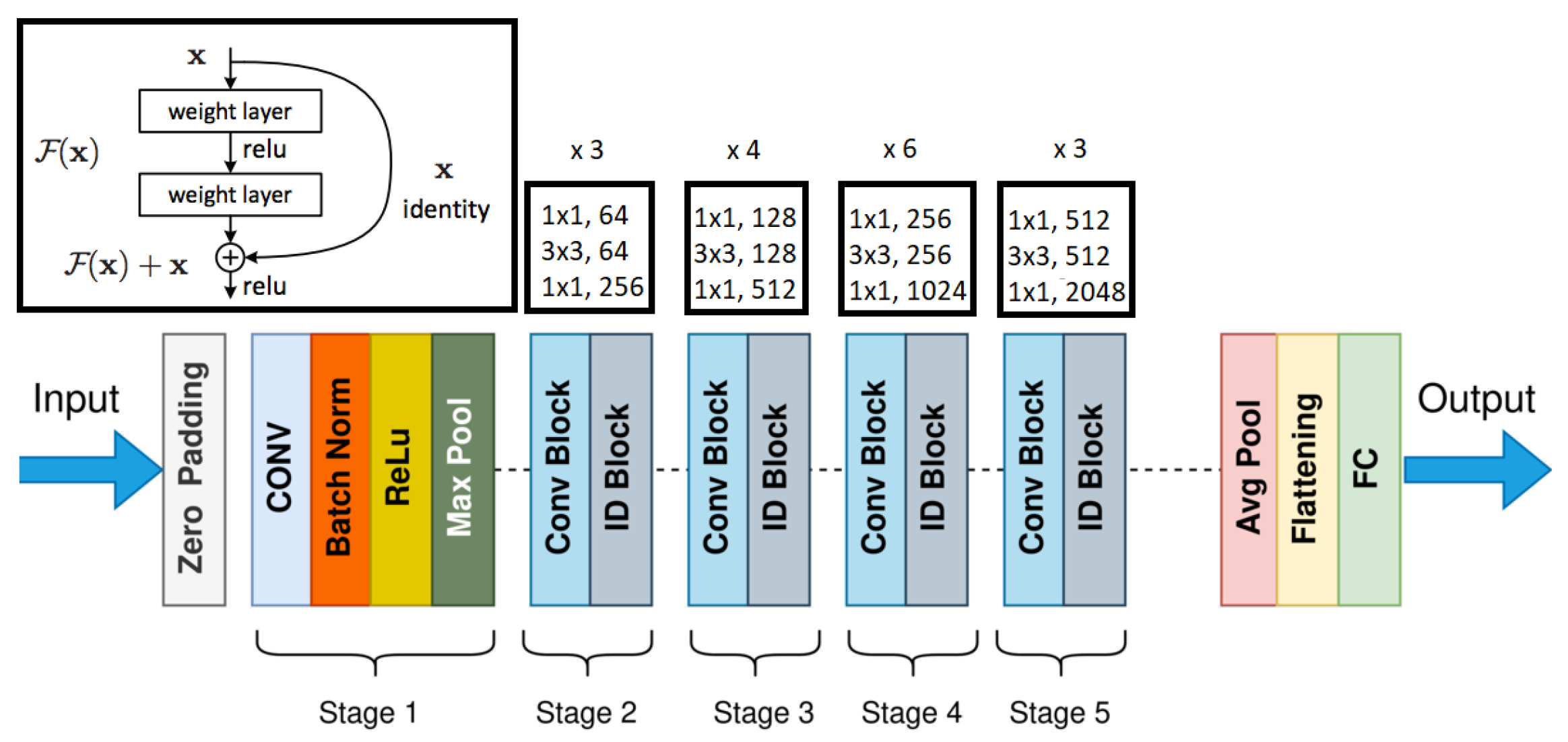
2.3.3. Residual Networks
The ResNet architecture [19][17] is a 2D convolutional neural network that uses identity shortcut connections to skip a number of weighted layers in the network. The basic structure of ResNet shown in Figure 65 uses 34 weighted layers, consisting of 33 convolutional layers and only one fully connected layer for classification. The convolutional layers use a 3×3 kernel, and down sampling occurs directly by certain convolutional layers using a stride of 2. ResNet was created to allow a deeper model while avoiding the vanishing gradient problem, which occurs when the weights in deeper layers of the model are not significantly impacted during training. Because of the use of the ReLU activation, along with the residual layers, ResNet is able to use 34 total layers, while this is a lot of layers, it uses fewer filters and is much less complex than similar architectures. The baseline ResNet model only has 18% of the FLOPs seen in the VGG19 architecture.
3. COVID-19 Prediction Using Deep Learning
COVID-19 has tremendously impacted patients and medical systems globally and deep learning has been extensively used to create COVID-19 prediction models. Figure 106 highlights some of the commonly used models by researchers. Much of the datasets used were CT scans and chest radiographs. The research was focused on both classification and segmentation to identify patterns during diagnosis. The following section contains a discussion on variants of deep learning models along with the machine learning approach utilized so far.
Figure 106.
Common deep learning architectures explored in COVID-19 diagnosis.
3.1. Diagnosis Using Chest Radiographs
In [53][18], the authors proposed CovNNet, a custom convolutional neural network, to detect COVID-19 in CXR. The second approach for the model used a fuzzy preprocessing step, in which fuzzy and normal CXR are fed into separate CovNNet models. The CovNNet architecture consists of three convolutional blocks, which contain a convolutional layer with ReLU activation followed by a max pooling layer. These features are combined, and then the model feeds to a multi-layer perceptron, which classifies the input as either COVID-19 or non-COVID-19. This second approach has the highest accuracy and time requirement of 80.9% and 50 s, respectively. The dataset used contained a CXR of 64 COVID-19 positive patients and 57 patients with interstitial pneumonia. In [54][19], the authors proposed a join-fusion model which combines clinical data and CXR to increase the accuracy of the final prediction. CXR images are fed into EfficientNetB7 (which uses the ImageNet weights) which feeds to a global average pooling 2D layer before reaching the concatenation layer. Clinical data is passed to a feature set layer before reaching the concatenation layer. After this concatenation layer, the data is passed through three dense layers, separated by dropout layers. Finally, binary classification is performed to diagnose the patient as either COVID-19 positive or healthy. The proposed model achieves an accuracy of 97% after training on a collection of 270 records from King Fahad University Hospital.
Research in [55][20] proposed two models—the first uses a DNN on the fractal features of images and the second is a CNN which uses CXR images. The whole model architecture is as follows: a COVID-19 and non-COVID-19 image are fed through feature extraction before being passed to the DNN for classification. The non-COVID input image is also passed to the CNN before feature extraction, and the CNN classifies the image. The COVID input image is passed to the CNN for segmentation, and ground truth is generated. The DNN concluded with an accuracy of 84.11%, which is significantly lower than the accuracy of the CNN, which concluded at 94.6%. CNNs are a type of deep learning neural network suited for image processing. This is due to the use of kernels, which process groups of pixels during each convolution. This allows CNN to capture spatial information, which is extremely useful in the localization of infections. DNNs mostly lack the ability to capture this spatial information due to their inherent architecture thereby leading to CNNs having higher accuracy. The dataset used consists of 812 total images, where 437 are of COVID-19 positive patients and 383 are of healthy patients. In [56][21], CXR were used to detect infected patients. The authors proposed a hybrid model after comparing 11 different deep learning architectures. The proposed model was optimized using k-fold cross-validations alongside a spotted hyena optimizer for better feature extraction. It was observed that a combination of Resnet-101, with the J48 algorithm decision tree, and the hyena optimizer showed the highest performance across accuracies. The dataset however was smaller with 50 normal and 50 COVID-19 patients. This study [57][22] developed a deep learning model called XR-CAPS that incorporates a UNet model for image segmentation and a capsule network for feature extraction for the prediction of COVID-19 from CXR images. The dataset consisted of 896 patients who were either healthy, had pneumonia or were COVID-19 positive. The results showed an accuracy of 93.2%, a sensitivity of 94% and a specificity of 97.1%, which outperformed similar models such as ResNet50, DenseNet21, and DenseCapsNet.
In [41][23], the authors created a system called COVID-CheXNet which used CXR to detect COVID-19. Prior to using ResNet-34 to classify scans as having COVID-19, the authors used contrast enhancement on the CXR and noise reduction technique by applying adaptive histogram equalization and Butterworth bandpass filter. The system achieved an accuracy rate of 99.99%, a sensitivity of 99.98%, and a specificity of 100% using the weighted sum rule at the score level. The model was trained using 400 COVID-19 and 400 normal CXRs gathered from five different sources. Discussions in [58][24] proposes two experiments to predict COVID-19 in CXR images. The first experiment performs a binary classification between COVID-19 and normal patients. In the second experiment, the classes COVID-19, normal, and pneumonia were considered. The proposed Deep CP-CXR model includes batch normalization first. This is followed by six blocks, which consist of a convolutional 2D layer and a leaky ReLU layer. After this is a max pooling 2D layer, a dropout layer, a flatten layer, a dense layer, a dropout layer, and a final dense classification layer. The accuracy of binary classification was 100%, and the accuracy of multi-class classification was 98.57%. The dataset used 1626 COVID-19 positive images, and 1802 normal images.
Research in [59][25], the neural network architecture CapsNet was used to classify COVID-19 in CXR images. In contrast to a normal CNN, CapsNet uses capsule layers. High-level capsules reuse the output of multiple lower-level capsules to produce an output vector that measures the probability of an entity existing in the image. This allows a capsule architecture to better capture spatial information, which traditional CNNs degrade through the pooling technique. The model classified images as either normal, COVID-19, and pneumonia. A train/validation/testing split of 60/20/20 percent, respectively, was used on the dataset of 454 COVID-19 images, 4273 pneumonia images, and 1583 normal images. The method of convolutional and capsule neural networks was compared in experiments, in which the proposed capsule model outperformed the conventional CNN architecture. The accuracy of normal, pneumonia and COVID-19 was 77.9%, 88.1%, and 81.2% for the CNN and 86.6%, 89%, and 94% for the proposed capsule network. This study [60][26] also proposed the use of CNNs for the purpose of classifying CXR images as either healthy, COVID-19, or other viral-induced pneumonia. The dataset used was created from a previous study, which worked to combine public datasets of COVID-19 and other pneumonia images, along with normal images. The final dataset included 10,192 normal images, 3616 COVID-19 images, and 1345 pneumonia images. Multiple CNN architectures were tested—namely ResNet18, GoogLeNet, AlexNet, VGG16, DenseNet161, along with a minimal CNN model created by this study. Each of the popular architectures contained a minimum of 6,000,000 parameters, while the proposed model only contained approximately 130,000 parameters. Every model tested, including this minimal CNN, achieved an accuracy of 97% or higher on the given data. Of these models, ResNet18 held the highest experimental performance by correctly classifying 256 of the total 269 testing images. This ResNet18 model was passed to an end-user application, which was given to a total of 10 experts, each with 12 to 23 years of professional experience in radiological analysis. The experts independently selected 150 images from their own datasets, for a total of 1500 total images being tested. The model correctly classified a total of 1486 of these images, which was confirmed by the experts. The greatest source of incorrect classification came from uncertain images (such as early stages of infection), and in these cases, the experts reported that it was also hard for humans to classify.
The study in [61][27] similarly proposed a CNN for the use of classifying CXR images as either COVID-19, pneumonia, or normal. The architecture used was based on the popular architecture EfficientNet B5, which had been pretrained using the noisy student approach. Transfer learning was applied to the model in order to fit it to the given classes, and the rest of the deep learning model was based on a prior study. The datasets used by this study were COVIDx, COVIDBIMCV, and COVIDprivate which contain 13,958, 10,953, and 305 images, respectively. An equal amount of testing images for each class were selected, with 300 from COVIDBIMCV and 150 from COVIDprivate. This was the same for validation, with 300 images each from COVIDx and COVIDBIMCV, and 90 from COVIDprivate. Five separate random divisions of training and validation datasets were created, each with a respective EfficientNet model. This created five separately trained EfficientNet models, which were combined into an ensemble approach for classification. The final ensemble model was compared to the skills of six radiologists, with 10 months to 15 years of experience. The deep learning model in this study scored higher than all six radiologists on the classification of COVID-19 and showed results comparable to the other models or radiologists for non-COVID-19 pneumonia and normal images. Researchers in [62][28] propose a model which combines feature maps from trained models to classify images as either COVID-19, viral pneumonia, or normal. Two public CXR datasets from the Kaggle website were used, each with the classes normal, COVID-19, and viral pneumonia. In terms of COVID-19, viral pneumonia, and normal images, the first dataset had 137, 90, and 90 images, respectively, while the second has 3616, 1345, and 10,192 images. The proposed approach involves the use of feature maps from MobileNetV2, EfficientNet0, and DarkNet53 in that order. After these feature maps are concatenated, the NCA optimization algorithm is applied to select the best 82 features out of the 3000 which is given by the concatenated feature maps, which serves to reduce time and cost in the proposed approach. Multiple classification techniques were tested, with SVM classification providing the best results across each of the datasets. The proposed techniques performed well with an average accuracy of 99.05% on the first dataset and 97.1% on the second dataset.
The study in [63][29] proposed a fusion-based CNN named COVDC-Net to classify CXR images into either three or four classes. The paper claims to address not only the need for rapid and accurate detection of COVID-19 but also the possibility that the currently overworked radiologists might have an increased rate of error due to exhaustion. Two datasets were used in this study—the first contains 4883 total images of the classes COVID-19, normal, and pneumonia. The second dataset explores the use of four classes for the classification task, with 305 COVID-19, 375 healthy, 379 bacterial pneumonia, and 355 viral pneumonia images. The proposed fusion method combines VGG16 and MobileNetV2, both of which are pretrained on the ImageNet dataset. These models were selected as a pair after testing many combinations between VGG16, VGG19, MobileNetV2, ResNet50, and DenseNet. Using confidence fusion, the types of features can be taken from both CNN architectures to create a more effective classification system. An overall accuracy of 96.48% is achieved for the first database of three classes, and an overall accuracy of 90.22% was achieved for the second database of four classes. A note is made to the vague or incomplete representation of metrics from other studies, which may cause repercussions if the techniques are later used in practical settings. The full metrics of this study are displayed. This study [64][30] used a lightweight CNN with edge computing to efficiently detect COVID-19 in CXR images. To increase the number of samples available in the dataset, DCGAN was implemented. DCGAN is a deep convolutional generative adversarial network, which uses deep learning in an unsupervised approach that replicates the distribution of data in each dataset. This generates new training images, which improved the accuracy of the classification model. For classification, the models MobileNetV2, ResNet18, and VGG19 were tested, and each model achieved functionally high accuracies. In order, MobileNetV2, ResNet18, and VGG19 achieved an F1 score of 82, 87, and 83 percent. The authors conclude that the accuracy achieved through MobileNetV2 is very comparable to the other models while utilizing a much smaller model. The use of edge computing further increases the efficiency of the system by processing information locally instead of relying on a centralized server.
The research done in [65][31] utilized image processing and a proposed CNN architecture to accurately classify CXR images as COVID-19, pneumonia, or normal. The dataset used in this study is a combination of three separate datasets. A total of 864 COVID-19, 6235 pneumonia, and 4254 normal images were available across these three datasets. These collected images were subjected to preprocessing, which extracted the lungs from the image as the ROI. This ROI is then combined with the original image and given to CNN for classification. The proposed CNN architecture C-COVIDNet is designed to be extremely lightweight and only consists of eight total layers. Five convolutional layers are used, followed by three dense layers, and between each layer, a dropout is used. The last dense layer uses SoftMax activation to generate the class prediction. In total, 97.5% accuracy was achieved using the preprocessing techniques and C-COVIDNet, which beats other state-of-the-art CNNs. The study in [66][32] proposes a novel model to detect COVID-19 and pneumonia using CXR images in real-time. The dataset used in the study contains 1102 COVID-19, 1341 normal, and 1345 viral pneumonia images. The proposed model COVID-CXDNetV2 uses an implementation of YOLOv2, which is then modified using ResNet. There are 14 convolutional blocks, five max-pooling layers, and four residual connections included in the model followed by a convolution layer, flatten layer and linear layer in that order. In differentiating between the three classes (normal, COVID-19, and pneumonia), the overall accuracy of the proposed model is 97.9%, which outperforms some state-of-the-art models. The study in [67][33] proposed both an LSTM and CNN model to detect COVID-19 and influenza in CXR images. For this study, a time-series dataset was gathered from Kaggle, UCI repository, and hospitals in Islamabad. For this experiment, 70% of the images were used to train the models, and 30% of the images were used to test. The proposed system is as follows: A series of CT scans are fed into the CNN, which identifies the images as either healthy or infected. If a patient is determined to be healthy, then this information is passed on to medical records. If the patient is determined to be infected, the images will be sent to the LSTM model which classifies the infection as either COVID-19 or Influenza, which would then be passed to medical records. This architecture is designed to better differentiate between COVID-19 and Influenza in the early stages of infection, which poses a challenge due to the similarity between the two infections. Of the two models developed, the LSTM performed the best—the CNN achieved 94% accuracy, while the LSTM achieved 98% accuracy. Both accuracies are high, which shows that the proposed deep learning techniques can accurately differentiate between healthy, Influenza, and COVID-19 using CXR images.
Researchers in [68][34] explore the potential of semi-supervised neural networks in detecting COVID-19 in CXR when only a small number of training images is available. The dataset contains five image classes—normal, bacterial pneumonia, COVID-19, lung opacity, and viral pneumonia. There are 404 training images for each of the classes, as well as 207 testing images for each class which were collected from a different source than the training images. These images were resized to 224 × 244, and a percentage of data was assigned to be unlabeled data to employ semi-supervised learning. The labeled proportions tested were 80, 60, 40, 20, 10, and 5 percent. These tests also included varied distributions of the majority/minority classes, all to test the robustness of FixMatch. The algorithm used in this study is the FixMatch algorithm, which utilizes consistency regularization and pseudo-labeling techniques. An artificial label is produced for an image with weak augmentation before the model is trained, and the model learns to predict the label with a stronger augmentation of the same image. The FixMatch algorithm utilizes ResNet18 as the underlying model. The proposed methods achieved an accuracy of approximately 78% when the proportion of labeled data was between 80 and 20 percent. In comparison to other CNNs and an ensemble approach, it was on par with the standard supervised learning techniques. The ensemble approach achieved the highest accuracy of 81%, but the proposed method is very effective with data and computational efficiency considered as FixMatch only uses ResNet18. This data also suggests that FixMatch could be robust to data imbalances.
A deep learning model to diagnose COVID-19 through the identification of structural abnormalities in CXR images was proposed in [69][35]. The model architecture uses two convolutional 2D layers followed by a max pool 2d and a dropout layer. Then, three blocks which consist of three convolutional 2D layers, a max pool 2D, and a dropout are used. The model then uses a flattened layer, a dense layer, a dropout layer, and a final dense classification layer. The final accuracy of the model is 97.67%. After data augmentation, the CXR dataset contains 1000 COVID-19 positive images and 1000 normal images. Another deep learning model proposing risk stratification was implemented in [70][36] using a patient’s CXR images. A modified commercial deep learning model, M-qXR, was used. The model performed well, with 98% of the total interpretations successfully compared to the ground truth. A dataset containing 2.5 million CXR images was used, which contains many pulmonary pathologies such as pneumonia and tuberculosis. The study in [71][37] provides evidence that CNNs along with transfer learning can be used to train models which can detect COVID-19 in CXR with high accuracy. A dataset of 300 normal images and 200 COVID-19 images was used, where 20 images of each class were set aside for validation, and 50 images of each class were set aside for testing. Data augmentation techniques were used to prevent overfitting and increase variation in the dataset, including a random flip and rotation of 5 degrees (both clockwise and counterclockwise). The best performance of a model used a CNN along with the VGG16 architecture using the transfer learning technique. Not only was the accuracy of this model the highest at 99.3%, but it also had the lowest loss at 0.03 and took the least time to train. This proposed architecture took only two minutes to achieve these results, while the second-best accuracy of 96.6% took almost ten minutes. The proposed combination of techniques provides a faster, more accurate, and adaptable network to detect COVID-19 when compared to the current testing standards.
Data used in deep learning goes through preprocessing, which ensures that the data can fit the input size requirement for the model. It is a common practice to include other preprocessing steps to clean the data, such as the removal of bad samples. A bad sample of an X-ray used in COVID detection could have labels written over the data or be extremely noisy. Preprocessing can also include steps that increase the size and quality of the dataset. Image augmentation uses one image to create multiple versions which slightly deviate from the original by methods such as zoom, rotation, and cropping. This prepares the model for these types of deviations and increases the performance on diverse data. There are additional techniques that actually generate new images to match existing data, often with the goal of balancing a mismatched dataset. Synthetic Minority Over-Sampling Technique, or SMOTE, is used to increase the number of images or balance data pertaining to different classes. These techniques are often used when a large dataset is not available for training, which was an extremely common setback at the beginning of the COVID-19 pandemic as there was little data collected, and it was often private. If CXR images are insufficient for the deep learning task, more data can be included in the form of clinical variables. With the increase in relevant data, deep learning models can give more accurate predictions.
The study in [72][38] proposed novel architecture using convolutional and temporal neural networks to detect COVID-19 in CXR. For the study, some datasets were combined for a total of 1670 COVID-19 images, 1672 normal images, and 1670 pneumonia images. These images were preprocessed using the empirical wavelet transform, which is useful for removing noise and increasing the resolution of the CXR images. Four models were tested alongside the proposed model, including InceptionV3, ResNet50, and ResNet50-TCN. In the proposed RESCOVIDTCNnet, features are extracted from these images using ResNet50, which are then passed to TCN. ResNet50-TCN is the proposed architecture, the difference being that RESCOVIDTCNnet includes the Empirical Wavelet Transform (EWT) preprocessing. Classification is then performed by either SVM or MLP, with MLP performing the best. In both cases, RESCOVIDTCNnet achieved an accuracy of over 99%. The paper reports that the proposed model outperforms the other models with a correlation coefficient of 0.999, and a standard deviation of 0.1.
3.2. Diagnosis Using Primarily CT Imaging
In [73][39], the authors talk about generic background information and human processes for a diagnosis via deep learning. Other models are brought up with their accuracies, with an emphasis on the models the research team recreated themselves. Dataset used had 349 COVID-19 images from 216 patients and 463 from non-COVID-19 patients. The researchers found VGG-19 worked best in their studies, at 94.52% accuracy. Research in [74][40] creates an argument for utilizing the VGG19 model while comparing Alexnet, Googlenet, Inception v3, VGG16&19, Shufflenet, Mobilenet v2, Resnet 18, 50 & 101. VGG19 showed the best performance across “covid”, “normal” and “pneumonia” case datasets. COVID-19 datasets used were large, open-source verified sets.
Authors in [75][41] used both chest X-rays (CXR) and CT scans to propose a CNN model named CoroDet. This model is able to perform a 2-class, 3-class and 4-class classification using a 22-layer sequential CNN which consists of convolutional, max pooling, dense layer, flatten layer, and three activation functions, namely Sigmoid, ReLU, and Leaky ReLU. Training on a dataset called COVID-R containing 7390 total CXR, 2843 COVID-19, 3108 Normal, and 1439 Pneumonia (Viral + Bacteria) the researchers ended with an average accuracy of 91.2%. Research in [76][42] used CT and CXR images to evaluate pre-trained deep neural networks in their ability to detect COVID-19. Data augmentation is used to increase the size of the training dataset to avoid overfitting and increase model performance. Among the tested models—ResNet50, InceptionV3, VGGNet-19, and Xception—it was found that VGGNet-19 performs the best on the CT dataset with 88.5% precision, 86% recall, 86.5% F1-score, and 87% accuracy. Xception performed the best on the CXR dataset with precision, recall, F1-score, and accuracy equalling 98%. Notably, the VGG-19 model performs the best across the two datasets with an average of 90.5% accuracy. The dataset used contained 3000 healthy scans and 623 COVID-19 positive CT scans.
Eight CNN CovNet models were compared in [77][43] in their ability to diagnose COVID-19 in CT scans as well as CXR images. A ninth model was proposed, which consists of four blocks of a 2D convolutional layer followed by a dropout layer, an activation layer, and a max pooling 2D layer. After these four blocks, there is a flattened layer, a dense layer, a dropout layer, and finally a dense classification layer. This proposed model achieved the highest accuracy at 98%, a precision and F1-score of 96%, and a recall of 95%. Their CXR dataset contains a total of 4107 COVID-19 positive images and more than 4105 healthy images. Their CT dataset contains a total of 1605 COVID-19 positive images and 1626 healthy images. Hybrid models were also implemented with success. Research in this domain was targeted toward rapid real-time COVID-19 detection. In [78][44], the authors highlight how computed tomography (CT) or CXR have become a significant tool for quick diagnoses. Thus, it is essential to develop an online and real-time computer-aided diagnosis (CAD) approach to support physicians and avoid further spreading of the disease. Using the ResNet50 model it was able to achieve a 98% accuracy with the CXR dataset. Thise paper highlights how CXR can get great accuracy and be a lot easier to get from patients. CT images can effectively complement reverse transcription-polymerase chain reaction testing. Using the COVIDx-CT dataset containing 104,009 CT images from 1489 patients and putting them through the COVID-Net CT-2 and ResNet-v2 models, research in [79][45] was able to achieve an accuracy of 98.7% which is comparable to CXR showing how CT and CXR can get the same accuracy.
In [80][46], a self-named DREnet model comprised of a pretrained ResNet 50 model using a Feature Pyramid Network to extract top-K details, before being passed into a multi-layer perceptron to make predictions. The goal of the model was the accurate diagnosis of COVID-19 in patients. The model was run on a dataset of 88 COVID-19 patients, 100 patient cases of bacterial pneumonia, and 86 healthy people. In [81][47], used a ResNet(50) model, with a proposed accuracy of 98.8%, with a dataset of 2267 CT scans, including 1357 COVID-19 patients and 1235 CT scans from non-COVID-19 patients. The paper confirmed that no image augmentation is necessary for diagnosing COVID-19 and it can be done using highly compressed JPEG files as well. Pre-trained models of ResNet 18,50, and 101 alongside SqueezeNet were used in [82][48] to detect COVID-19 from CT scans. Using the familiar 349 COVID-19 images from 216 patients, with 463 from non-COVID-19 patients, their findings showed that ResNet18 worked best for their dataset, with a validation accuracy of 97.32%, training 99.82%, and testing 99.4%.
In [39][49], the authors used 48,260 CT scan images from 282 normal patients and 15,589 images from 95 patients with COVID-19 infections. The researchers used an image pre-processing and filtering algorithm to remove CT image slices that did not represent the region of interest associated with COVID-19 detection. Much of this filtering approach was based on removing CT slices from the top and the bottom of the scan, and also implementing a threshold for the Hounsfield Units that is suitable for lung tissue analysis. Using this scheme, lead to higher accuracy and less false detection. When ResNet50V2 model was used on the modified dataset, the researchers were able to achieve an accuracy of 98.49% using a single image classification stage. In [83][50], the authors created an effective deep learning algorithm to screen for COVID-19. The dataset included 1065 images from 259 patients. As a pre-processing stage, the authors delineated tissue in CT images using Region of Interest (ROI) for the training and validation step. This patch-based method allowed the model to focus on features that are evident during the early stages of COVID-19 prognosis compared to viral pneumonia. Proposing an Inception-v3 model with these patch-based ROI, they achieved an accuracy range of 79.3–89.5% through their tests.
In [84][51], the authors compared pre-trained models to detect COVID-19 in CT scan images, with the attempt to offer a model to perform autonomous prediction. Among the models tested are InceptionV3, ResNet50, VGG16, and VGG19. ResNet performed the best, with an accuracy of 98.86%. The research used a CT dataset of 7395 COVID-19 positive images and 6018 suspicious case images, while most models proposed earlier require a lot of computing resources, researchers in [85][52] made an effort to diagnose COVID-19 with limited resources. With the use of a fine-tuned MobileNet-V2 model being fit on a real-world dataset consisting of 2482 CT scan images, the authors were able to achieve an accuracy of 85.6%. The proposed model was significantly smaller at around 8.45 MB compared to the similarly sized VGG16 model at 512 MB, DenseNet 201 at 70.9 MB and VGG19 at 532 MB. The average classification time on test data images was also less at 21.3 s with 43 msec/image compared to 315 s for VGG-19. In [86][53], the authors proposed COVID-AL, a weakly-supervised COVID-19 detection module using a pre-trained UNet model for transfer learning. Their model is described as a “tailor-designed 2D U-Net”, cropping images to 352 × 320 before input. The significance of this research was that the authors were able to train and test the model on separate datasets. The model began by segmenting the lung region from 402 CT scans using the Non-Small Cell Lung Cancer (NSCLC) dataset. This objective of this stage is similar to [83][50], however, instead of extracting ROIs, the UNet was creating a segmented mask of the lung from an entire CT scan which could have several slices. The UNet segmentation is then used on 617,775 CT scan slices from 4154 patients in the China Consortium of Chest CT Image Investigation (CC-CCII) dataset. Through their model, they attained an accuracy of between 96.2 and 96.8%.
Research in [87][54], examines the problem with deep learning models requiring labeled training datasets. It takes pre-trained models ResNet18, ResNet50, and ResNet101 and uses them for the automatic detection of COVID-19. ResNet50 performed the best with a recall of 98.8% and an F-1 score of 98.41%. Different layers of the model are explored through support vector machine, logistic regression and K-nearest neighbor classifiers. A fusion of the classifiers was deployed as a strategy and the recall score increased to 99.2% while the F-1 score increased to 99.4%. Research in [88][55], examines the challenge of diagnosing patients with COVID-19 and differentiating it from pulmonary edema. A machine learning model EDECOVID-net was used to differentiate using lung Computed Tomography radiomic features. The model was able to distinguish between COVID-19 and pulmonary edema with an accuracy of 0.98. Research in [89][56], examines early diagnosis of COVID-19 through a deep learning model approach combined with CT image analysis. The model is based on convolutional long short term memory and was tested on CXR images. The performance of the model had an accuracy of 97.3% at 50 epochs. This [90][57] paper proposes using a CNN model for the diagnosis of COVID-19 patients using CT images. This predictive model was used for binary classification of other pulmonary diseases. The binary classification had an accuracy of 98.79%, a precision of 94.98%, and a sensitivity of 98.85%.
The researchers in [91][58] address the need for quick and automated detection of COVID-19 by proposing a transfer-learning deep CNN to classify images as normal, COVID-19, and pneumonia. The transfer learning is performed using pre-trained DensNet121, in which the model is given images augmented with random flips, rotation up to 10 degrees, zoom up to 5%, and changes to brightness and contrast. The model weights are adjusted to fit the new inputs and outputs. Data preprocessing occurs before images are passed to the model during testing, which includes a resize to 224 × 224 × 3 and normalization. DensNet121 is pretrained on the popular ImageNet dataset, which contains over 1.2 million images belonging to 1000 classes. A publicly available dataset was then used for transfer learning, consisting of 180 images per class. In total, 80% of images were used to train, and 20% of images were used to validate the model. In experiments, the proposed model showed an accuracy of 96.52% across the three classes. Compared to other popular architectures, this was the highest performing model with at least 2% higher accuracy than other models.
Research in [92][59], utilizes preprocessing techniques and a bidirectional LSTM to classify images as normal, viral pneumonia, lung opacity, or COVID-19. The image dataset used contains 3616 COVID-19 images, 10,192 normal images, 6012 Lung opacity images, and 1345 viral pneumonia images. The first step of preprocessing was to use modified histogram equalization to enhance contrast. The equation was modified to change the level of the histogram based on the contrast level of the input image. Preprocessing also included an extended dual-tree complex wavelet transform with trigonometric transform to extract effective features. A custom optimization technique was used to avoid overfitting by selecting features with reduced dimensionality. These preprocessing techniques increased the final accuracy of the model from 97.34% to 99.07%, proving their effectiveness. Classification was performed by the adaptive dual-stage horse herd BiLSTM architecture. This model uses an embedding layer, followed by a bidirectional LSTM (forward and back), then a concatenation layer. This concatenation layer leads to another bidirectional LSTM and concatenation layer, which is passed to an optimized attention layer, which gives an output class. When compared to ResNet50 and AlexNet models, the proposed model obtained the highest accuracy at 99.07%. The accuracy per class was always greater than other models by at least 1.73%.
The study in [93][60] proposed a data-efficient deep neural network to account for the lack of data available during a pandemic situation. Two datasets were employed, and a general adversarial network was utilized to increase the number of samples while creating different types of lung deformations. This novel approach was added to the methods because while data augmentation increases accuracy in varied datasets, it is ultimately using data with the same exact deformation in the augmented images. The first dataset—COVID-19-CT—has 324 train and 40 test COVID-19 images, and for normal images, there are 293 training sets and 37 test sets. The second dataset—MosMed—has 168 train and 20 test images for both COVID-19 and normal images. After augmentation and GAN implementation, the COVID-19-CT dataset contains 2172 train and 37 test normal images, along with 1893 train and 37 test COVID-19 images. The MosMed dataset ends up with approximately 1200 images for both COVID-19 and normal. The highest AUC value of 0.89 was achieved using ResNet18 on the first dataset along with augmentation and GAN. Without the GAN implementation, the AUC value is only 0.77, which proves the utility of GAN for synthetic image generation. The study in [94][61] proposed a deep learning model to segment COVID-19 infection in lung CT scans using the UNet architecture. For this purpose, a dataset of 3138 lung CT images belonging to 20 patient scans was used, each with a respective label and segmentation verified by expert radiologists. A training/validation split of 70/30 was used to verify the accuracy of the model during training. The proposed diagnosis system consists of four separate phases—lung segmentation, infection segmentation, COVID-19 classification, and 3D reconstruction. The lung segmentation phase utilizes contrast-limited adaptive histogram equalization (CLAHE) as a preprocessing step and cropped away any background slices. The U-Net architecture is then used to segment the lungs. The infection segmentation phase performs the same preprocessing of CLAHE and background slice removal, segmenting only the infection. The COVID-19 classification phase uses a three-layer CNN with fully connected layers and softmax activation to then classify the infection segmentation as either COVID-19 or normal. The final phase gave a 3D reconstruction which was used to identify the rate of infection, quantified by the ratio of the infected lung to the healthy lung. For the final classification, an accuracy of 98% was achieved. By using these techniques, the model was able to achieve high performance with a limited training dataset.
The study in [95][62] utilizes lung segmentation to increase the accuracy of a CNN in the classification of COVID-19 in CT images. A Kaggle dataset is used, which contains a total of 1834 images along with masks. To segment the lungs, the techniques of canny edge detection, thresholding, and UNet are compared. The Intersect over Union scores indicate that UNet greatly outperforms the other techniques. A CNN is then used to classify the lung as either COVID-19 positive or negative. The final accuracy achieved through these techniques is 95%. The inclusion of segmentation both increased the accuracy and decreased the loss, proving the utility of the technique. The study in [96][63] proposes a novel CNN model named DCML to detect COVID-19 in CT and CXR images. A binary classification occurs, labeling images as either COVID-19 positive or negative. For this research, three total datasets were used to train and test the models. Each dataset provided separate characteristics—the first dataset had less than 600 total images to train on, the second dataset was overall fair, and the third dataset had a large data imbalance. In total, 70% of each dataset was used for training, while 30% was reserved for testing. Each training dataset is augmented using the Fast AutoAugment method. Deep mutual learning is then employed, and the models are strongly fused. Contrastive learning is included in the knowledge transfer during the mutual learning phase, which increases the model’s performance in distinguishing between classes. The final proposition of this research is the adaptive model fusion strategy, which utilizes the correlation between the heterogeneous networks to better mimic the learning and decision-making processes of trained radiologists. The feature maps from two separate networks are combined using a feature fusion model, which creates a new fused feature map. This is then passed to the fully connected layers and a SoftMax classification. Across each of the datasets, the proposed DCML using Fast AutoAugment provided the highest accuracy when compared to a variety of fine-tuned popular CNN architectures.
The study in [97][64] proposed the novel DMDF-Net for the segmentation of COVID-19-related lesions in CT scans. For this deep learning model, two datasets were used—the first contains 2049 images with a COVID-19 infection ground truth, and the second contains 3520 images with masks for the left and right lungs along with the COVID-19 infection mask. Before images are passed to the model, a preprocessing step occurs where the color and contrast are adjusted. The DMDF-Net model uses dual multiscale feature fusion in both the encoding and decoding phases, which increases the accuracy of the segmentation. The encoding phase is based from MobileNetV2. Postprocessing is also implemented, in which the lung mask ROI is applied to the original CT image for further processing the data and segmenting the infected regions. This technique was observed to increase the accuracy of the model. The final model—including all pre- and post-processing techniques—was able to outperform other state-of-the-art models with a DICE score of 75.7% and an IOU of 67.22%.
Research in [98][65] aimed to contribute a decision-aiding tool that can detect COVID-19 in CT images. The images are preprocessed first by a random window level between −500 and −600 HU, and a window width of 1200 HU. The randomness of the window level is chosen to account for the discrepancies between CT scans taken with different machines. The second step in preprocessing includes a normalization to between 0 and 255, and the removal of unrelated features or noise in the image. The model architecture is an end-to-end segmentation model based on the UNet architecture, which utilizes an encoder and a decoder along with the SoftMax activation to generate a predicted mask. To tackle the imbalanced class problem where the infection is always between 0 and 20 percent of the image, a custom loss function is used. The loss is a class-balanced cross-loss function, which was observed to effectively handle the imbalance. The DICE score of the proposed model, including preprocessing, was 83.3 and 83.4 percent for datasets one and two, respectively. Compared to the performance of popular baseline architectures, this model achieved the highest DICE score. The study in [99][66] fine-tuned existing models VGG16 and miniVGGNet for the prediction of COVID-19 on CT imaging. In total, 6368 CT images were used from the Corona Hack-Chest X-Ray dataset of which 3184 were COVID-19 positive and 3184 were normal. The efficiency of each model was evaluated with VGG16 having a precision of 0.98, recall of 0.81 and F1 score of 0.89 for COVID-19 while miniVGGNet had a precision of 0.97, recall of 0.89 and F1 score of 0.93 for COVID-19. Both models performed best with data augmentation with VGG16 achieving an accuracy of 89% while miniVGGNet had an accuracy of 93%.
In [100][67], the authors proposed using a deep learning model for quantitative assessment of COVID-19 CT imaging. A total of 14 patients were reviewed with both initial and follow-up CT. The deep learning model was based on the CNN VB-Net, which was used for automatic segmentation and delineation of affected regions. The results showed the percentage of infection was 3.4% for the entire lung, with a percentage of infection decrease in the follow-up period for all 14 patients. The study in [101][68] developed a model called Deep Covix-net that used image segmentation along with a machine learning algorithm to accurately predict and diagnose COVID-19. The dataset that was utilized in this study was an open-source Kaggle and GitHub repository that contained 9000 CXR images, of which 3000 are COVID-19 positive, 3000 are normal, and 3000 have pneumonia. It also contains 6000 CT images, of which 3000 are COVID-19 and 3000 are normal. Feature extraction and selection involved using advanced image segmentation techniques such as texture, grey-level co-occurrence matrix (GLCM), grey-level difference method (GLDM), fast Fourier transform (FFT) and discrete wavelet transform (DWT). The statistical features were combined into the Deep Covix-net model and a random forest classifier for classification. The CXR dataset had an accuracy of 96.8% while the chest CT images had an accuracy of 97%.
3.3. Diagnosis Using Ensemble Techniques
An ensemble approach to combining results from multiple deep learning models was also reported in [102][69]. Here authors used VGG-16, ResNet50, and Xception models and then combined their results to generate a final prediction on 2482 CT-scan images, 1252 of which are scans with positive COVID-19 cases. With a 98.79% accuracy, these models have proven themselves very useful. Another stacked ensemble approach was explained in [103][70] which looked at the predictions of VGG19, ResNet101, DenseNet169, and WideResNet 50-2. Five datasets were used to verify the proposed approach with 15,286 CT scans and 3120 CXRs. The proposed model was compared with 11 existing models from previous research. The proposed model outperformed in all five datasets with accuracy values of 85.45%, 93%, 99%, 99.75% and 91.5%.
Research in [104][71] combines the use of Stacking and Weighted Average Ensemble (WAE) on popular models (VGG19, ResNet50, and DenseNet201) in an ensemble learning approach to diagnosing COVID-19. The input is passed to the fine-tuned popular models mentioned before, and the output is passed to Random Forest and Extra Trees classifiers. That output is passed to a Logistic Regression level, which then produces an output of either positive or negative. The F1 scores of the WAE model were the highest, at 98.65% and 94.93% respectively for the two CT datasets. Two separate CT scan datasets were employed—the first contains 1252 COVID-19 positive images and 1230 healthy images. The second contains 349 COVID-19 positive images and 463 healthy images. Researchers in [105][72] made an effort to create a generalized detection model that can look at unknown datasets and detect COVID-19 with significant accuracy. A meta-classifier-based approach along with EfficentNet-based pretrained model was used to extract significant features from datasets. These features were then reduced using Principal Component Analysis (PCA). The final classification layer was a 2-stage approach. In the first stage, Random Forest and Support Vector machines were used to bag the prediction results followed by a logistic regression classifier to delineate the final outcome of COVID-19 or not. The authors tested the model on 8055 CT images and 9544 CXR. Seven variants of EfficentNet were trained based on image scaling along with 18 variants of deep learning models used by previous researchers. The proposed approach reported a precision and recall of 0.99 for COVID-19 images and 1 for Non-COVID-19 images.
The excerpt from [106][73] used a binary classification IKONOS-CT to differentiate COVID-19 patients from non-COVID-19 using CT images. The classifiers that were used were multilayer perceptron, SVM, random tree, random forest, and Bayesian networks. The best feature extractor was Haralick and SVM which had an accuracy of 96.994% and recall of 0.952. Research in [107][74], uses machine learning techniques to identify COVID-19 through extracted feature fusion. Curvelet Transform, Gabor Wavelet Transform and Local Gradient Increasing Pattern were used for fusion and then used to classify CXR images. The machine learning classifiers used were Discriminant Analysis, Ensemble, Random Forest, and SVM. The model had an overall accuracy of 96.18%, a precision of 95.46%, a sensitivity of 96.98% and an F-1 score of 96.21% with SVM. Research in [108][75], classifies the severity of COVID-19 positive CT images through feature extraction. The text features are then classified using Random Forest. The images are then placed into four levels of severity of COVID-19, which had an accuracy of 90.95%.
Research in [109][76], develops a machine learning-assisted model for the detection of severe COVID-19. They use blood tests clinical variables along with quantitative CT parameters such as volume, percentage, and ground glass opacities. Correlation between the variables was first done using a Pearson test, then features were selected through an independent t-test and least absolute shrinkage and selection operator regression. Support vector machines, Gaussian Naïve Bayes, K-nearest neighbor, decision tree, random forest and multi-layer perceptron algorithms were all used as classifiers. For the selected features, lesion percentage contributed the most to classification. Random forest had the highest accuracy for the identification of severe COVID-19 cases at 91.38%. Research in [110][77] used a hybrid of deep transfer learning and machine learning to classify CT scans as either COVID-19 or normal. For this study, a dataset of 1252 COVID-19 images and 1230 normal images was collected from a hospital in Brazil. The approach uses a popular CNN architecture to extract the hidden features of the images, which are then passed to one of two machine learning algorithms—support vector machines and k-nearest neighbors (KNN). The transfer learning approach was chosen to account for the small dataset, as the model only needs to adapt the existing weights to fit the new data. The final layer of each tested deep learning architecture was a pooling layer, which consisted of the extracted features. This was then passed to the chosen machine learning algorithm, which performed the final classification. A final accuracy of 98.2% was achieved using the features extracted by the ResNet50 architecture and the SVM classification. The ResNet50 architecture also returned the highest accuracy when used with the KNN classification at 97.5%. Both proposed approaches outperformed other studies which utilized the same dataset.
References
- Feng, W.; Newbigging, A.M.; Le, C.; Pang, B.; Peng, H.; Cao, Y.; Wu, J.; Abbas, G.; Song, J.; Wang, D.B.; et al. Molecular diagnosis of COVID-19: Challenges and research needs. Anal. Chem. 2020, 92, 10196–10209.
- Kanne, J.P.; Little, B.P.; Chung, J.H.; Elicker, B.M.; Ketai, L.H. Essentials for radiologists on COVID-19: An update—Radiology scientific expert panel. Radiology 2020, 296, E113–E114.
- Sousa, R.T.; Marques, O.; Soares, F.A.A.; Sene, I.I., Jr.; de Oliveira, L.L.; Spoto, E.S. Comparative performance analysis of machine learning classifiers in detection of childhood pneumonia using chest radiographs. Procedia Comput. Sci. 2013, 18, 2579–2582.
- Ahsan, M.; Gomes, R.; Denton, A. Application of a convolutional neural network using transfer learning for tuberculosis detection. In Proceedings of the 2019 IEEE International Conference on Electro Information Technology (EIT), Brookings, SD, USA, 20–22 May 2019; pp. 427–433.
- Bentley, P.; Ganesalingam, J.; Jones, A.L.C.; Mahady, K.; Epton, S.; Rinne, P.; Sharma, P.; Halse, O.; Mehta, A.; Rueckert, D. Prediction of stroke thrombolysis outcome using CT brain machine learning. NeuroImage Clin. 2014, 4, 635–640.
- Li, Y.; Hara, S.; Shimura, K. A machine learning approach for locating boundaries of liver tumors in ct images. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 1, pp. 400–403.
- Garapati, S.S.; Hadjiiski, L.; Cha, K.H.; Chan, H.P.; Caoili, E.M.; Cohan, R.H.; Weizer, A.; Alva, A.; Paramagul, C.; Wei, J.; et al. Urinary bladder cancer staging in CT urography using machine learning. Med. Phys. 2017, 44, 5814–5823.
- Rozario, P.; Gomes, R. Comparison of data mining algorithms in remote sensing using Lidar data fusion and feature selection. In Proceedings of the 2021 IEEE International Conference on Electro Information Technology (EIT), Mt. Pleasant, MI, USA, 14–15 May 2021; pp. 236–243.
- Gomes, R.; Ahsan, M.; Denton, A. Fusion of SMOTE and Outlier Detection Techniques for Land-Cover Classification Using Support Vector Machines. In Proceedings of the 2018 Midwest Instruction and Computing Symposium (MICS), Duluth, MN, USA, 6–7 April 2018; p. 42.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32.
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297.
- Mahdavifar, S.; Ghorbani, A.A. Application of deep learning to cybersecurity: A survey. Neurocomputing 2019, 347, 149–176.
- Yang, H.; An, Z.; Zhou, H.; Hou, Y. Application of machine learning methods in bioinformatics. AIP Conf. Proc. 2018, 1967, 040015.
- Zhu, Q.; Li, X.; Conesa, A.; Pereira, C. GRAM-CNN: A deep learning approach with local context for named entity recognition in biomedical text. Bioinformatics 2018, 34, 1547–1554.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Ieracitano, C.; Mammone, N.; Versaci, M.; Varone, G.; Ali, A.R.; Armentano, A.; Calabrese, G.; Ferrarelli, A.; Turano, L.; Tebala, C.; et al. A Fuzzy-enhanced Deep Learning Approach for Early Detection of COVID-19 Pneumonia from Portable Chest X-ray Images. Neurocomputing 2022, 481, 202–215.
- Khan, I.U.; Aslam, N.; Anwar, T.; Alsaif, H.S.; Chrouf, S.M.; Alzahrani, N.A.; Alamoudi, F.A.; Kamaleldin, M.M.A.; Awary, K.B. Using a Deep Learning Model to Explore the Impact of Clinical Data on COVID-19 Diagnosis Using Chest X-ray. Sensors 2022, 22, 669.
- Kumar, A.; Mahapatra, R.P. Detection and diagnosis of COVID-19 infection in lungs images using deep learning techniques. Int. J. Imaging Syst. Technol. 2022, 32, 462–475.
- Dhiman, G.; Chang, V.; Kant Singh, K.; Shankar, A. Adopt: Automatic deep learning and optimization-based approach for detection of novel coronavirus COVID-19 disease using X-ray images. J. Biomol. Struct. Dyn. 2022, 40, 5836–5847.
- Darji, P.A.; Nayak, N.R.; Ganavdiya, S.; Batra, N.; Guhathakurta, R. Feature extraction with capsule network for the COVID-19 disease prediction though X-ray images. Mater. Today Proc. 2022, 56, 3556–3560.
- Al-Waisy, A.S.; Al-Fahdawi, S.; Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Maashi, M.S.; Arif, M.; Garcia-Zapirain, B. COVID-CheXNet: Hybrid deep learning framework for identifying COVID-19 virus in chest X-rays images. Soft Comput. 2020, 1–16.
- Kumar, S.; Gaur, A.; Singh, K.; Shastri, S.; Mansotra, V. Deep Cp-Cxr: A Deep Learning Model for Identification of COVID-19 and Pneumonia Disease Using Chest X-ray Images. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4010398 (accessed on 5 May 2022).
- Ragab, M.; Alshehri, S.; Alhakamy, N.A.; Mansour, R.F.; Koundal, D. Multiclass Classification of Chest X-Ray Images for the Prediction of COVID-19 Using Capsule Network. Comput. Intell. Neurosci. 2022, 2022, 6185013.
- Sevli, O. A deep learning-based approach for diagnosing COVID-19 on chest X-ray images, and a test study with clinical experts. Comput. Intell. 2022. Early View.
- Nishio, M.; Kobayashi, D.; Nishioka, E.; Matsuo, H.; Urase, Y.; Onoue, K.; Ishikura, R.; Kitamura, Y.; Sakai, E.; Tomita, M.; et al. Deep learning model for the automatic classification of COVID-19 pneumonia, non-COVID-19 pneumonia, and the healthy: A multi-center retrospective study. Sci. Rep. 2022, 12, 8214.
- Yildirim, M.; Eroğlu, O.; Eroğlu, Y.; Çinar, A.; Cengil, E. COVID-19 Detection on Chest X-ray Images with the Proposed Model Using Artificial Intelligence and Classifiers. New Gener. Comput. 2022, 1–15.
- Sharma, A.; Singh, K.; Koundal, D. A novel fusion based convolutional neural network approach for classification of COVID-19 from chest X-ray images. Biomed. Signal Process. Control 2022, 77, 103778.
- Xu, W.; Chen, B.; Shi, H.; Tian, H.; Xu, X. Real-time COVID-19 detection over chest X-ray images in edge computing. Comput. Intell. 2022. Early View.
- Rajawat, N.; Hada, B.S.; Meghawat, M.; Lalwani, S.; Kumar, R. C-COVIDNet: A CNN Model for COVID-19 Detection Using Image Processing. Arab. J. Sci. Eng. 2022, 1–12.
- Musha, A.; Al Mamun, A.; Tahabilder, A.; Hossen, M.; Jahan, B.; Ranjbari, S. A deep learning approach for COVID-19 and pneumonia detection from chest X-ray images. Int. J. Electr. Comput. Eng. 2022, 12, 2088–8708.
- Aftab, M.; Amin, R.; Koundal, D.; Aldabbas, H.; Alouffi, B.; Iqbal, Z. Research Article Classification of COVID-19 and Influenza Patients Using Deep Learning. Contrast Media Mol. Imaging 2022, 2022, 8549707.
- Sajun, A.R.; Zualkernan, I.; Sankalpa, D. Investigating the Performance of FixMatch for COVID-19 Detection in Chest X-rays. Appl. Sci. 2022, 12, 4694.
- Xue, Y.; Onzo, B.M.; Mansour, R.F.; Su, S. Deep Convolutional Neural Network Approach for COVID-19 Detection. Comput. Syst. Sci. Eng. 2022, 42, 201–211.
- Canario, D.A.H.; Fromke, E.; Patetta, M.A.; Eltilib, M.T.; Reyes-Gonzalez, J.P.; Rodriguez, G.C.; Cornejo, V.A.F.; Dunckner, S.; Stewart, J.K. Using artificial intelligence to risk stratify COVID-19 patients based on chest X-ray findings. Intell. Based Med. 2022, 6, 100049.
- Amin, S.; Alouffi, B.; Uddin, M.I.; Alosaimi, W. Optimizing Convolutional Neural Networks with Transfer Learning for Making Classification Report in COVID-19 Chest X-rays Scans. Sci. Program. 2022, 2022, 5145614.
- El-Dahshan, E.S.A.; Bassiouni, M.M.; Hagag, A.; Chakrabortty, R.K.; Loh, H.; Acharya, U.R. RESCOVIDTCNnet: A residual neural network-based framework for COVID-19 detection using TCN and EWT with chest X-ray images. Expert Syst. Appl. 2022, 204, 117410.
- Shah, V.; Keniya, R.; Shridharani, A.; Punjabi, M.; Shah, J.; Mehendale, N. Diagnosis of COVID-19 using CT scan images and deep learning techniques. Emerg. Radiol. 2021, 28, 497–505.
- Loddo, A.; Pili, F.; Di Ruberto, C. Deep Learning for COVID-19 Diagnosis from CT Images. Appl. Sci. 2021, 11, 8227.
- Hussain, E.; Hasan, M.; Rahman, M.A.; Lee, I.; Tamanna, T.; Parvez, M.Z. CoroDet: A deep learning based classification for COVID-19 detection using chest X-ray images. Chaos Solitons Fractals 2021, 142, 110495.
- Chouat, I.; Echtioui, A.; Khemakhem, R.; Zouch, W.; Ghorbel, M.; Hamida, A.B. COVID-19 detection in CT and CXR images using deep learning models. Biogerontology 2022, 23, 65–84.
- Kumar, N.; Hashmi, A.; Gupta, M.; Kundu, A. Automatic Diagnosis of COVID-19 Related Pneumonia from CXR and CT-Scan Images. Eng. Technol. Appl. Sci. Res. 2022, 12, 7993–7997.
- Rehman, A.; Sadad, T.; Saba, T.; Hussain, A.; Tariq, U. Real-time diagnosis system of COVID-19 using X-ray images and deep learning. It Prof. 2021, 23, 57–62.
- Zhao, W.; Jiang, W.; Qiu, X. Deep learning for COVID-19 detection based on CT images. Sci. Rep. 2021, 11, 14353.
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Wang, R.; Zhao, H.; Chong, Y.; et al. Deep Learning Enables Accurate Diagnosis of Novel Coronavirus (COVID-19) With CT Images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 2775–2780.
- Zhu, Z.; Xingming, Z.; Tao, G.; Dan, T.; Li, J.; Chen, X.; Li, Y.; Zhou, Z.; Zhang, X.; Zhou, J.; et al. Classification of COVID-19 by compressed chest CT image through deep learning on a large patients cohort. Interdiscip. Sci. Comput. Life Sci. 2021, 13, 73–82.
- Ahuja, S.; Panigrahi, B.K.; Dey, N.; Rajinikanth, V.; Gandhi, T.K. Deep transfer learning-based automated detection of COVID-19 from lung CT scan slices. Appl. Intell. 2021, 51, 571–585.
- Rahimzadeh, M.; Attar, A.; Sakhaei, S.M. A fully automated deep learning-based network for detecting COVID-19 from a new and large lung CT scan dataset. Biomed. Signal Process. Control 2021, 68, 102588.
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Cai, M.; Yang, J.; Li, Y.; Meng, X.; et al. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). Eur. Radiol. 2021, 31, 6096–6104.
- Hassan, E.; Shams, M.Y.; Hikal, N.A.; Elmougy, S. Detecting COVID-19 in Chest CT Images Based on Several Pre-Trained Models; Research Square: Durham, NC, USA, 2022.
- Singh, V.K.; Kolekar, M.H. Deep learning empowered COVID-19 diagnosis using chest CT scan images for collaborative edge-cloud computing platform. Multimed. Tools Appl. 2022, 81, 3–30.
- Wu, X.; Chen, C.; Zhong, M.; Wang, J.; Shi, J. COVID-AL: The diagnosis of COVID-19 with deep active learning. Med. Image Anal. 2021, 68, 101913.
- Kaur, T.; Gandhi, T.K. Classifier Fusion for Detection of COVID-19 from CT Scans. Circuits Syst. Signal Process. 2022, 41, 3397–3414.
- Velichko, E.; Shariaty, F.; Orooji, M.; Pavlov, V.; Pervunina, T.; Zavjalov, S.; Khazaei, R.; Radmard, A.R. Development of computer-aided model to differentiate COVID-19 from pulmonary edema in lung CT scan: EDECOVID-net. Comput. Biol. Med. 2022, 141, 105172.
- Alajmi, M.; Elshakankiry, O.A.; El-Shafai, W.; El-Sayed, H.S.; Sallam, A.I.; El-Hoseny, H.M.; Faragallah, O.S. Smart and Automated Diagnosis of COVID-19 Using Artificial Intelligence Techniques. Intell. Autom. Soft Comput. 2022, 32, 1403–1413.
- Fazle Rabbi, M.; Mahedy Hasan, S.M.; Champa, A.I.; Rifat Hossain, M.; Asif Zaman, M. A Convolutional Neural Network Model for Screening COVID-19 Patients Based on CT Scan Images. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning; Arefin, M.S., Kaiser, M.S., Bandyopadhyay, A., Ahad, M.A.R., Ray, K., Eds.; Springer: Singapore, 2022; pp. 141–151.
- El Idrissi, E.B.Y.; Otman, A. Transfer Learning for Automatic Detection of COVID-19 Disease in Medical Chest X-ray Images. Available online: http://www.iaeng.org/IJCS/issues_v49/issue_2/IJCS_49_2_09.pdf (accessed on 5 May 2022).
- Mannepalli, D.P.; Namdeo, V. An effective detection of COVID-19 using adaptive dual-stage horse herd bidirectional long short-term memory framework. Int. J. Imaging Syst. Technol. 2022, 32, 1049–1067.
- Serte, S.; Dirik, M.A.; Al-Turjman, F. Deep Learning Models for COVID-19 Detection. Sustainability 2022, 14, 5820.
- Mahmoudi, R.; Benameur, N.; Mabrouk, R.; Mohammed, M.A.; Garcia-Zapirain, B.; Bedoui, M.H. A Deep Learning-Based Diagnosis System for COVID-19 Detection and Pneumonia Screening Using CT Imaging. Appl. Sci. 2022, 12, 4825.
- Vijayakumari, B.; Ramya, S. Deep Learning Based COVID-19 Diagnosis Using Lung Images; Research Square: Durham, NC, USA, 2022.
- Zhang, H.; Liang, W.; Li, C.; Xiong, Q.; Shi, H.; Hu, L.; Li, G. DCML: Deep Contrastive Mutual Learning for COVID-19 Recognition. Biomed. Signal Process. Control 2022, 77, 103770.
- Owais, M.; Baek, N.R.; Park, K.R. DMDF-Net: Dual Multiscale Dilated Fusion Network for Accurate Segmentation of Lesions Related to COVID-19 in Lung Radiographic Scans. Expert Syst. Appl. 2022, 202, 117360.
- El Biach, F.Z.; Imad, I.; Laanaya, H.; Minaoui, K. CovSeg-Unet: End-to-End Method-based Computer-Aided Decision Support System in Lung COVID-19 Detection on CT Images. Int. J. Adv. Comput. Sci. Appl. 2022, 13.
- Tani, T.B.; Afroz, T.; Khaliluzzaman, M. Deep Learning Based Model for COVID-19 Pneumonia Prediction with Pulmonary CT Images. In Computational Intelligence in Machine Learning; Kumar, A., Zurada, J.M., Gunjan, V.K., Balasubramanian, R., Eds.; Springer: Singapore, 2022; pp. 365–379.
- Li, J. CT-Based Quantitative Assessment of Coronavirus Disease 2019 Using a Deep Learning-Based Segmentation System: A Longitudinal Study; Research Square: Durham, NC, USA, 2021.
- Vinod, D.N.; Jeyavadhanam, B.R.; Zungeru, A.M.; Prabaharan, S. Fully automated unified prognosis of COVID-19 chest X-ray/CT scan images using Deep Covix-Net model. Comput. Biol. Med. 2021, 136, 104729.
- Biswas, S.; Chatterjee, S.; Majee, A.; Sen, S.; Schwenker, F.; Sarkar, R. Prediction of COVID-19 from chest ct images using an ensemble of deep learning models. Appl. Sci. 2021, 11, 7004.
- Jangam, E.; Barreto, A.A.D.; Annavarapu, C.S.R. Automatic detection of COVID-19 from chest CT scan and chest X-rays images using deep learning, transfer learning and stacking. Appl. Intell. 2022, 52, 2243–2259.
- Mouhafid, M.; Salah, M.; Yue, C.; Xia, K. Deep Ensemble Learning-Based Models for Diagnosis of COVID-19 from Chest CT Images. Healthcare 2022, 10, 166.
- Ravi, V.; Narasimhan, H.; Chakraborty, C.; Pham, T.D. Deep learning-based meta-classifier approach for COVID-19 classification using CT scan and chest X-ray images. Multimed. Syst. 2021, 1–15.
- de Santana, M.A.; Gomes, J.C.; de Freitas Barbosa, V.A.; de Lima, C.L.; Bandeira, J.; Valença, M.J.S.; de Souza, R.E.; Masood, A.I.; dos Santos, W.P. An Intelligent Tool to Support Diagnosis of COVID-19 by Texture Analysis of Computerized Tomography X-ray Images and Machine Learning. In Assessing COVID-19 and Other Pandemics and Epidemics Using Computational Modelling and Data Analysis; Pani, S.K., Dash, S., dos Santos, W.P., Chan Bukhari, S.A., Flammini, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 259–282.
- Ahmad, F.H.; Wady, S.H. COVID-19 Infection Detection from Chest X-Ray Images Using Feature Fusion and Machine Learning. Sci. J. Cihan Univ. Sulaimaniya 2022, 5, 10–30.
- Amini, N.; Shalbaf, A. Automatic classification of severity of COVID-19 patients using texture feature and random forest based on computed tomography images. Int. J. Imaging Syst. Technol. 2022, 32, 102–110.
- Development of a Machine Learning-Assisted Model for the Early Detection of Severe COVID-19 Cases Combining Blood Test and Quantitative Computed Tomography Parameters. J. Med. Imaging Health Inf. 2021, 11, 2747–2753.
- Al-jumaili, S.; Duru, D.G.; Ucan, B.; Uçan, O.N.; Duru, A.D. Classification of COVID-19 Effected CT Images Using a Hybrid Approach Based on Deep Transfer Learning and Machine Learning; Research Square: Durham, NC, USA, 2022.
More