Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Siok Yee Tan and Version 2 by Vivi Li.
Facial recognition is a prevalent method for biometric authentication that is utilized in a variety of software applications. This technique is susceptible to spoofing attacks, in which an imposter gains access to a system by presenting the image of a legitimate user to the sensor, hence increasing the risks to social security. Consequently, facial liveness detection has become an essential step in the authentication process prior to granting access to users. A patch-based convolutional neural network (CNN) with a deep component for facial liveness detection for security enhancement was developed, which was based on the VGG-16 architecture.
- biometric
- liveness detection
- social security
- artificial intelligence
- CNN
- VGG-16
- LSTM
1. Introduction
Biometric systems have been utilized in various security applications in recent years due to ongoing research into their implementation [1][2][1,2]. Facial recognition-based liveness detection is one of the major branches of biometric technology that have been effectively applied in e-commerce, device security and organizational attendance, as well as for ensuring top-notch security, especially in the era of the IR 4.0. The core role of liveness detection is to verify whether the source of a biometric sample is a live human being or a fake representation. This process provides more safety and improvements to traditional facial recognition-based security systems [3], which use a person’s unique biometric information, such as their face, to allow that individual to access specific systems or data. However, one of the primary impediments to biometric identification systems is the risk of spoofing attacks [4]. A facial spoofing attack is an attempt by an unauthorized person to circumvent the facial authentication protocol and the facial verification process by employing deception techniques, such as identity forgery [5]. A printed image of an authorized face or a recorded video from a display may provide sufficient unique data to deceive the system [6][7][6,7]. As a result, the resiliency of these security systems can be diminished.
A multitude of applications use facial biometric authentication, such as automated teller machines (ATMs), smart security systems and other similar systems [8][9][8,9]. Advanced artificial intelligence models increase the data processing capability of biometric technology, which results in more effective biometric security systems [10]. Nevertheless, spoofing attacks are a common form of attack that reduce the effectiveness of biometric authentication systems [11]. A facial spoofing attack is an attempt by an illegal user to circumvent a facial authentication system and facial verification system using deception methods, such as counterfeiting the identity of an authorized user [5]. Therefore, the implementation of liveness detection systems that are powered by artificial intelligence has the potential to make existing biometric-based security systems more sustainable and secure while also providing better social security.
Recently, numerous effective facial anti-spoofing methods have been developed [4][5][6][7][8][4,5,6,7,8]. They can be generally divided into fixed feature-based facial anti-spoofing algorithms [12] and automated learnable feature-based facial anti-spoofing algorithms [13]. Facial anti-spoofing techniques utilize hand-crafted features from actual and counterfeit faces to detect spoofing. The features of actual and false faces are determined before training facial anti-spoofing algorithms. Motion, texture, image quality, 3D shape and multi-spectral reflectance are examples of fixed feature-based algorithms. Automated learnable feature-based facial anti-spoofing methods distinguish between legitimate and fake faces using deep learning approaches, such as convolutional neural networks (CNNs). CNNs learn the properties of real and fake faces during training. By transmitting raw pixels through hidden layers, CNNs translate the raw pixels of images into probabilities. The number of hidden layers determines the depth of a CNN [14][15][14,15]. Although deep CNNs are the optimal solution for most applications, their usage in facial anti-spoofing applications has been restricted due to a lack of training data.
2. FacLial Anti-Spoofing Approachesterature Review
2.1. Feature-Based Facial Anti-Spoofing Approaches
Liu et al. proposed an improved local binary pattern for face maps that could be used as a classification feature [16]. When these characteristics were put into a support vector machine (SVM) classifier, the face maps could be classified as genuine or false. Tan et al. proposed a technique for formulating the anti-spoofing objective as a binary classification problem [17]. They implemented Difference of Gaussian (DoG) filtering to eliminate noise from 2D Fourier spectra and then extended a sparse logistic regression classifier both nonlinearly and spatially for the classification. Matta et al. utilized multiscale local binary patterns to examine the texture of facial images [18]. Afterward, the macrotexture patterns were encoded into an improved feature histogram, which was then input into an SVM classifier. Parveen et al. proposed a texture descriptor that they described as the dynamic local ternary pattern, in which the textural features of skin were examined using an adaptive threshold configuration and the classification was performed using a support vector machine with a linear kernel [19]. Das et al. proposed a method that was based on a frequency and texture analysis to distinguish between real and artificial faces [20]. The frequency evaluation was accomplished by Fourier transforming the images into the frequency domain and then calculating the frequency descriptor to detect dynamic variations in the faces. LBP was employed to analyze the texture and an SVM classifier with a radial basis function kernel was used to classify the generated feature vectors. The method that was proposed by Luan et al. involved three characteristics: blurriness, the specular reflection ratio and color channel distribution characteristics [21]. The images were classified using an SVM, according to these three characteristics. Chan et al. developed a technique that utilized flash to defend against 2D spoofing attacks [22]. This technique captured two images per individual: one with flash and the other without. Three additional descriptors were employed to extract the textural information of the faces: a descriptor that was based on uniform LBP and the standard deviation and mean of the grayscale difference between the two recorded images of each person. The difference between the pictures with and without flash, as assessed by the four descriptors, was used to classify the images. Kim et at. proposed a method that defined the differences between the surface characteristics of live and fake faces by calculating the diffusion speeds and extracting anti-spoofing characteristics that were based on the local patterns of the diffusion speeds [23]. These characteristics were input into a linear SVM classifier to assess the liveness of the images. Yeh et al. developed a method that utilized digital focus properties with different depths of field to accomplish liveness detection [24]. The nose and the lower right portion of the cheek were examined for preprocessing. Due to the impact of the depth of field, the degree of blurriness differed between real and false images. The k-nearest neighbor method was used to classify the results. Although hand-crafted feature extraction was also utilized in [12][13][12,13], rwesearchers adopted a patch-based CNN that was built on VGG-16 architecture to conduct feature extraction automatically, which removed the need for hand-crafted feature extraction.2.2. Deep Learning-Based Facial Anti-Spoofing Approaches
Deep CNN models have been employed in recent facial liveness identification studies because they provide more accurate liveness detection than the previously presented strategies [7][8][14][15][7,8,14,15]. For facial anti-spoofing detection, Atoum et al. suggested a two-stream CNN-based method that included a patch-based CNN and a depth-based CNN [25]. While the first CNN extracted local features from face image patches, the second extracted depth features by computing the depth from the entire image and then using an SVM for feature extraction. This two-stream network could be trained end-to-end to discriminate between real and fake faces based on their rich appearance attributes by including these parameters. Rehman et al. proposed a technique that concentrated on data randomization in mini-batches to train deep CNNs for liveness detection [26]. The method that was proposed by Alotaibi et al. used a mix of input facial diffusion accompanied by a three-layer CNN architecture [27]. For facial liveness detection, Alotaibi et al. suggested an approach that employed nonlinear diffusion, accompanied by a tailored deep convolutional network [28]. By rapidly diffusing the input image, nonlinear diffusion aided in differentiating between fake and genuine images. As a result, the edges of flat images faded away while the edges of genuine faces stayed visible. Furthermore, to extract the most significant properties for classification, a customized deep convolutional neural network was suggested. Koshy et al. proposed a method that combined nonlinear diffusion with three architectures: CNN-5, ResNet50 and Inception v4. They found that the Inception v4 architecture was the best [29]. Jourabloo et al. addressed the facial anti-spoofing problem as an image denoising problem, which resulted in the development of an anti-spoofing method that was based on CNNs to achieve the facial anti-spoofing objective [30]. In the first layer of a Lenet-5-based neural network model, De Souza et al. applied the LBP descriptor, which improved the accuracy of facial spoofing detection [31]. An improved version of LBPnet, which is called n-LBPnet, was suggested to achieve higher accuracy for real-time facial spoofing detection by integrating the local response normalization (LRN) step into the second layer of the network. Xu et al. demonstrated that facial anti-spoofing in videos could be achieved using a deep architecture that integrated LSTM and a CNN [32]. The LSTM obtained the temporal correlations in the input sequences while the CNN retrieved the local and dense features. Tu et al. proposed that facial spoofing detection in video sequences could be achieved using a CNN–LSTM network, which concentrated on motion cues throughout video frames [33]. To enhance the facial emotions of the humans in the videos, they used Eulerian motion magnification. Highly discriminative features were extracted from the video frames using a CNN and LSTM, which were also used to capture the temporal dynamics from the videos. Recently, Khade et al. proposed an iris liveness detection technique that used several deep convolutional networks [34]. Densenet121, Inceptionv3, VGG-16, EfficientNetB7 and Resnet50 were employed in that study to identify iris liveness using transfer learning approaches. The limited dataset necessitated the use of a transfer learning approach to prevent overfitting. As stated above, numerous well-referenced CNN models have demonstrated the ability to distinguish between real and fake faces. Therefore, this papentryr presents a patch-based CNN architecture for training complicated and differentiating features to improve the security of present facial recognition-based biometric authentication systems against printed images and replay attacks.3. Architecture of the Proposed System
3.1. Liveness Detection
A patch-based CNN that was built on the VGG-16 architecture with a deep aspect was proposed for liveness detection to improve security. After the patches are constructed, the input images are transmitted sequentially to the CNN, which serves as the front-end of the architecture. The CNN output is then passed to an LSTM, which identifies temporal features in the sequence and determines whether the dense layer in the neural network output is real or fake. The workflow of the proposed method is shown Figure 1.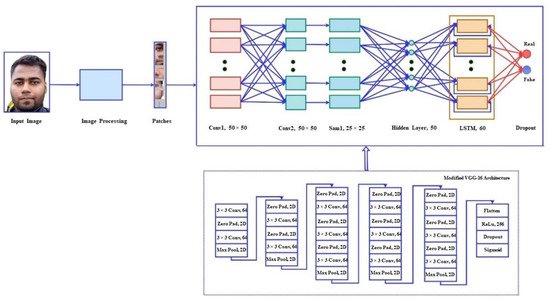
Figure 1.
The workflow of the patch-based CNN–LSTM architecture with the modified VGG-16.