The Industrial Revolution 4.0 (IR 4.0) has drastically impacted how the world operates. The Internet of Things (IoT), encompassed significantly by the Wireless Sensor Networks (WSNs), is an important subsection component of the IR 4.0. WSNs are a good demonstration of an ambient intelligence vision, in which the environment becomes intelligent and aware of its surroundings. WSN has unique features which create its own distinct network attributes and is deployed widely for critical real-time applications that require stringent prerequisites when dealing with faults to ensure the avoidance and tolerance management of catastrophic outcomes. Thus, the respective underlying Fault Tolerance (FT) structure is a critical requirement that needs to be considered when designing any algorithm in WSNs. Moreover, with the exponential evolution of IoT systems, substantial enhancements of current FT mechanisms will ensure that the system constantly provides high network reliability and integrity.
- Wireless Sensor Networks (WSNs)
- Fault Tolerance (FT)
- error detection
1. Introduction
2. Faults Classifications in WSN
During the last years, different classifications of faults have been proposed in WSNs [32,35,36,37][9][10][11][12]. A clear understanding of these various classifications provides a defined foundation and enhancements to the proposed algorithms developed to address fault-related issues. Figure 1 illustrates the various categories of errors in WSN as deliberated, respectively, in [17,21,24][13][14][15]. Node behavioral faults, fault period, network infrastructure elements, the region impacted by a fault, and the layer where the error occurred are all factors considered in determining the overall categories [36,37][11][12].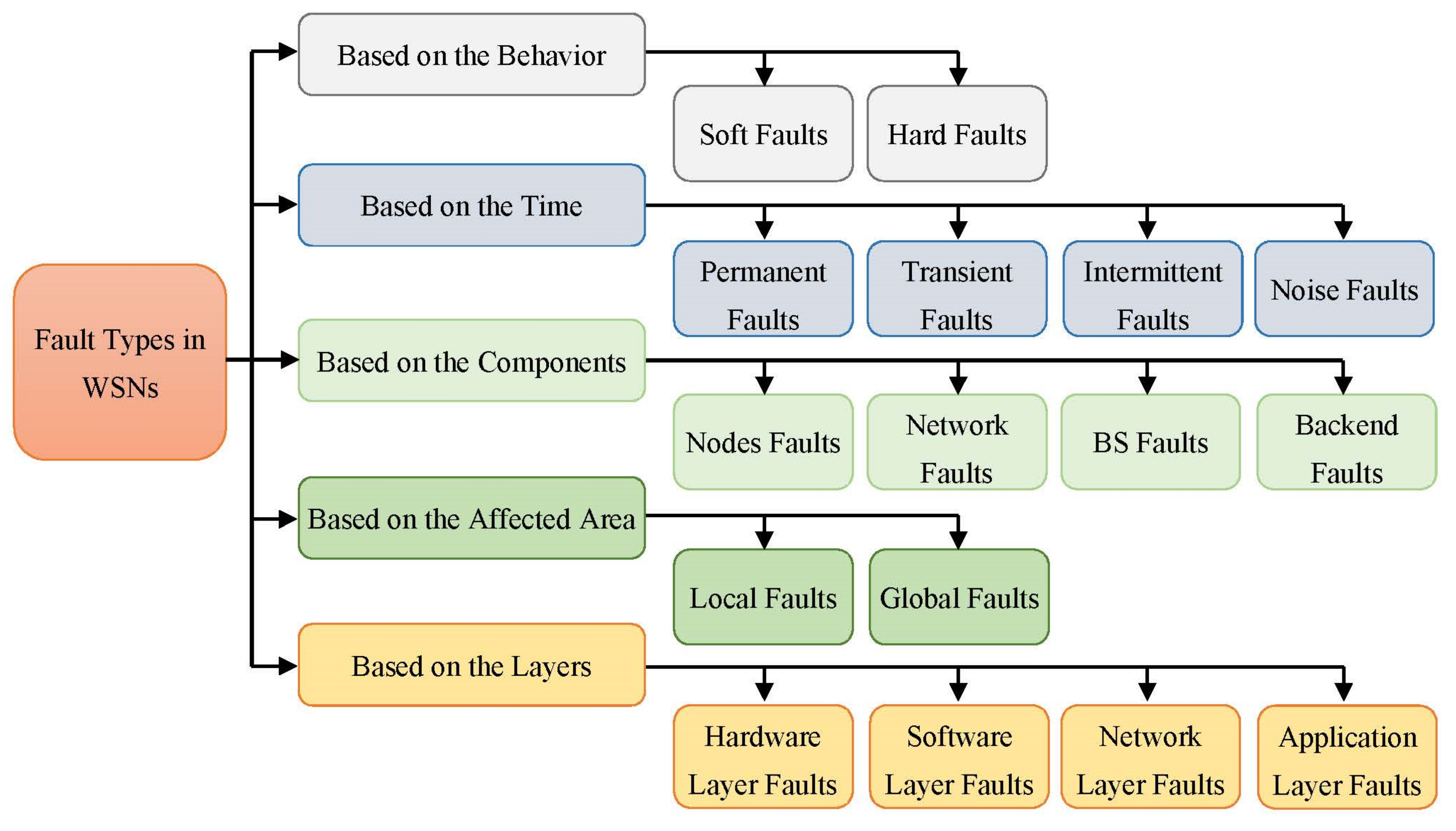
3. Proposed Classification of Fault Tolerance Management Approaches in WSN
Generally, no single fault tolerance structure fits all WSN applications due to its variety and wide use [67][27]. Many approaches and frameworks have been proposed for the same primary purpose: to satisfy the fault-tolerance concept to gain a high level of reliability and integrity. A general categorization of fault management mechanisms is introduced in this section to make the representation of these schemes more understandable. The suggested categorization divided fault management structures into centralized, decentralized, and hybrid. Each category is subdivided into many subcategories. Figure 32 illustrates the categorization of fault management schemes that have been suggested.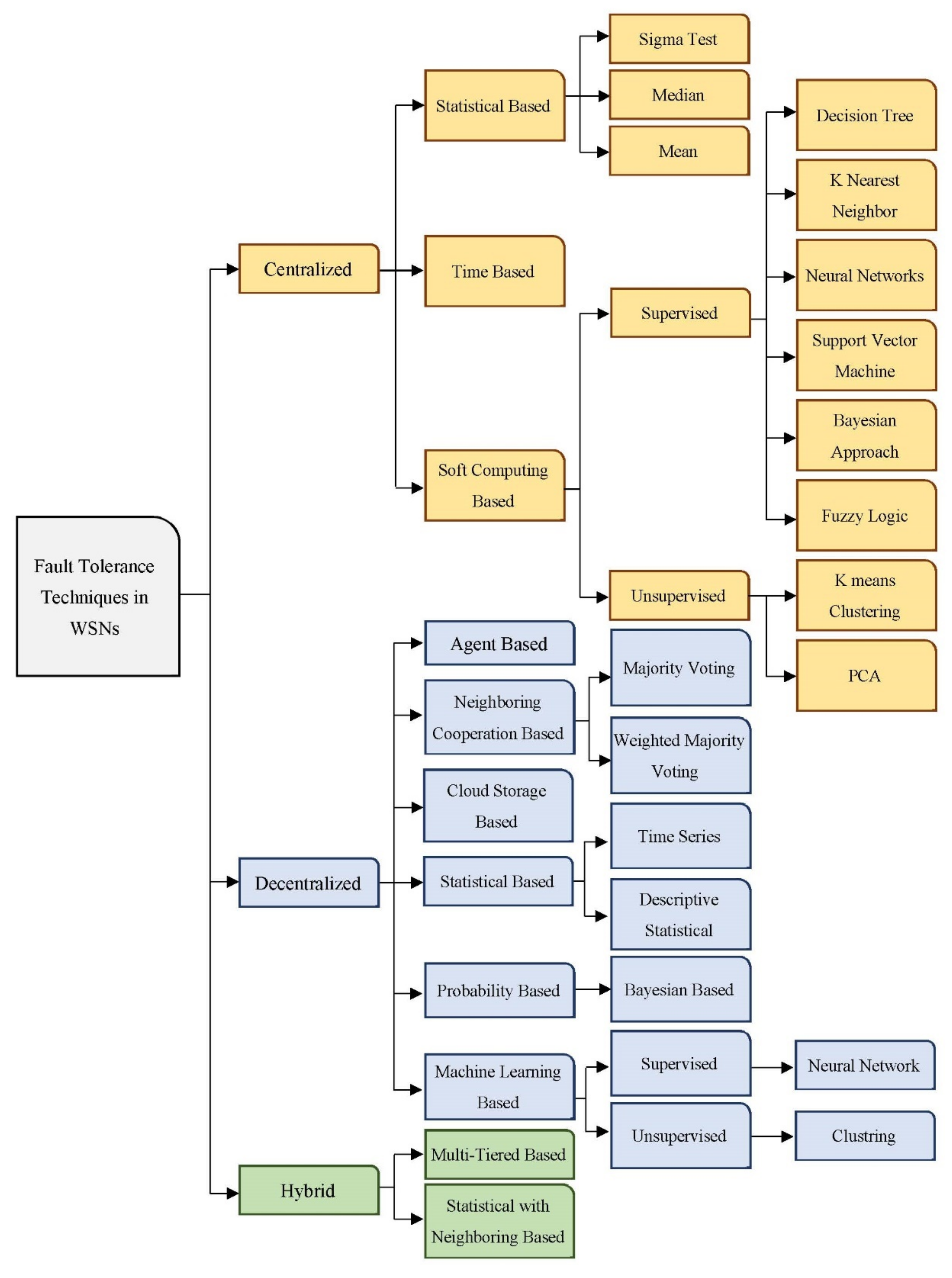
3.1. Centralized Fault Tolerance Approaches
The center administrator or BS takes responsibility for fault detection and occurrence choices. By regularly injecting network status queries into the network to collect state information and evaluate this information to find faults, the BS identifies and handles all errors in the WSN. Although this method is easier for smaller networks, it has several drawbacks, including high message traffic near the BS and high energy usage [68][28]. Based on their effectiveness, centralized approaches may be divided into statistical-based, soft computing-based, and time-based. With statistical methods, the statistics are transmitted to the BS and aggregated; then, it is examined to be assessed via the fault tolerance framework [69][29]. This approach uses statistical methods to identify outliers in the data set under consideration, such as the sigma test, median, and mean. Methods based on soft computing are algorithms primarily focused on machine learning methods [70][30]. There are two types of learning methods: supervised learning and unsupervised learning. In supervised learning, an input-output collection is provided to a system, and the system is instructed to train a given input to outcome pairs in the group. To train the system, this technique needs some input data. Neural networks, support vector machines, K-nearest neighbor, Bayesian statistics, decision trees, and fuzzy logic are examples of learning methods [21,24,31,62][14][15][24][31]. However, in certain situations, supervised learning will not provide the desired results. Another machine learning technique is unsupervised learning. Learning is done on un-marked raw data to uncover unseen forms in unsupervised learning. Principal Component Analysis (PCA) and K-means clustering are examples of unsupervised learning [71][32]. In time-based fault tolerance approaches, nodes utilize Carrier-Sense Multiple Access with Collision Avoidance (CSMA/CA) and constantly listen to the medium while the network is deployed. To begin, the BS builds a tree structure that links nodes and routes traffic. Data from adjacent nodes is collected at this stage. Finally, the BS allocates a slot to each sensor node for information transmission. Many slots are also allocated to nodes for time synchronization and error handling. Nodes use CSMA/CA for communication listening during the listening time to identify problems [72][33]. Even though these methods depend on the nodes to detect the errors, the BS will make the main decision. As aforementioned, all centralized approaches suffer from high overhead and lack in scalability matter even though there are simple to implement. Generally, centralized methods have many drawbacks. First, because of the network’s size and density, a lot of information is communicated to the BS, rapidly depleting the energy of nodes nearby. Centralized paradigms are incompatible with large networks. The approaches also need a huge database to hold a huge number of data, increasing installation costs. Additionally, the BS is a weak point in centralized systems and it may have its own errors. When it fails, the output is inaccurate or absent. A faulty BS is tough to replace in many environments. Because the BS receives all network data, it becomes congested, affecting network performance. Lastly, centralized approaches transmit a huge amount of information over the wireless network to obtain information about its status, leading to increased energy consumption, bandwidth waste, and scalability issues [73][34].3.2. Decentralized Fault Tolerance Approaches
The decentralized fault-tolerant mechanisms will be tackled particularly in this sub-section. Unlike centralized control, these structures use numerous management stations spread throughout the whole wireless network. In decentralized frameworks, each node, cluster head, backbone node, or master node is in charge of a portion of the network. It has the ability to interact directly with other nodes to execute fault detection tasks performed by the BS in the last category [19][35]. In distributed systems, sensor nodes control their resources and management systems. There is less need to communicate with BS when the nodes can make decisions regarding their status. In terms of functionality, distributed fault-tolerant structures are divided into six categories: neighborhood cooperation-based, statistical-based, probability-based, machine learning-based, cloud storage-based, and agent-based. The basic idea behind the neighborhood-based techniques is a correlation among nodes in the same region [74][36]. Neighborhood voting may be split into majority voting and weighted majority voting. To determine the fault state of nodes, the majority of votes presume that neighboring nodes have the majority of error situations. For each node in the WSN, the weighted majority approach gathers weighted votes from all nearby nodes and forecasts a higher number of votes. Statistical methods are algorithms that identify errors in data using analytical techniques. Time-series-based and descriptive statistical-based are two subcategories of statistical methods. The time-series approach examines time-series data to identify patterns and calculate variations. Deviations in WSNs data are detected using tests. One of the preferable tests is the Kolmorgov Smirnov [75][37]. On the other hand, descriptive statistical-based techniques are for determining defects that utilize one of the central tendency metrics, such as the mean of neighborhood nodes. Probability fault tolerance methods rely on the probability of node failure to identify the fault state of nodes in a distributed network environment A node’s fault probability and the fault probability of its neighbors are used to compute the posterior fault probability, which is then used to identify the faulty nodes. Based on the Bayes theorem, Bayesian statistical approaches are used to determine the probability that a node is inaccurate. Machine-learning methods are a subclass of decentralized approaches that have lately received a lot of interest [76][38]. These approaches may be divided into supervised and non-supervised detection techniques. Training data sets are used in supervised error detection methods to learn the difference between real and error data and to anticipate many sensor failures. The node’s weight is used in neural network-based methods to anticipate data mistakes. Unlike supervised learning methods, unsupervised learning methods have not been given any datasets to work with and have not trained with any database. This area includes clustering methods. Clustering-based methods group nodes into different clusters and link them to a cluster head that examines each node. In agent-based algorithms, the ultimate error status of a sensor node is decided by agents chosen from across the WSN or by the sensor nodes themselves, depending on the methodology. Even though these methods use various information from neighbors, individual nodes or agents make the ultimate choice [77][39]. Cloud-based methods take advantage of cloud-based resources to decrease the cost of computing tasks [78][40]. The basic concept behind this method is to move the input data from the nodes to cloud storage and then utilize map reduction to parallelize the error detection process, which would decrease the time it takes to identify faults in the entire system [79][41]. However, this method is not commonly used in WSNs. The goal of decentralized fault tolerance approaches is to solve the issues that centralized fault management frameworks have, such as increasing energy efficiency and minimizing the total overhead [19,27][35][42]. Various numbers of nodes manage faults to achieve the goal instead of entirely depending on BS. However, distributed fault management systems still suffer from delays. They concentrate on lowering energy usage and increasing the accuracy of problem detection. The structures based on neighbor collaboration are focused on improving fault detection accuracy. Neighbor cooperation techniques are gaining popularity due to the requirement for more accurate fault tolerance frameworks in WSNs [58,59][43][44].3.3. Hybrid Fault Tolerance Approaches
The last category in the proposed taxonomy is the hybrid fault tolerance structure, a combination of centralized and decentralized management approaches. Hybrid approaches can be divided into two main subcategories: multi-tiered based and statistical with neighboring based [59][44]. Hybrid algorithms are employed in a large multi WSN, where nodes are grouped into clusters with cluster heads [80][45]. Each cluster’s nodes transmit their information to the cluster leaders. Cluster heads then send the data to a central base station for processing [2]. In the trust matrix method, a trust matrix is utilized to assess the trustworthiness of data. Hybrid algorithms also combine many detection methods that have been mentioned before into a single algorithm. An example of this category is neighborhood algorithms in conjunction with descriptive statistical methods like mean and median. Hybrid methods’ main goal is to reduce energy usage and reduce the delay in fault detection. The fault detection time is minimal since nodes are responsible for detecting their own problems. Furthermore, implementing a fault tolerance system in the cluster heads and master nodes lowers node energy usage since nodes with more energy can detect and recover problems. However, the correct distribution of clusters in a network and their distance from the BS cause the network to become more complicated [81][46].References
- Nagy, J.; Oláh, J.; Erdei, E.; Máté, D.; Popp, J. The Role and Impact of Industry 4.0 and the Internet of Things on the Business Strategy of the Value Chain—The Case of Hungary. Sustainability 2018, 10, 3491.
- Jaiswal, K.; Anand, V. FAGWO-H: A hybrid method towards fault-tolerant cluster-based routing in wireless sensor network for IoT applications. J. Supercomput. 2022, 78, 11195–11227.
- Dowlatshahi, M.B.; Rafsanjani, M.K.; Gupta, B.B. An energy aware grouping memetic algorithm to schedule the sensing activity in WSNs-based IoT for smart cities. Appl. Soft Comput. 2021, 108, 107473.
- Abdali, T.-A.N.; Hassan, R.; Aman, A.M.; Nguyen, Q.; Al-Khaleefa, A. Hyper-Angle Exploitative Searching for Enabling Multi-Objective Optimization of Fog Computing. Sensors 2021, 21, 558.
- Idrees, A.K.; Al-Qurabat, A.K.M. Energy-Efficient Data Transmission and Aggregation Protocol in Periodic Sensor Networks Based Fog Computing. J. Netw. Syst. Manag. 2021, 29, 1–24.
- Abdali, T.-A.N.; Hassan, R.; Aman, A.H.M.; Nguyen, Q.N. Fog Computing Advancement: Concept, Architecture, Applications, Advantages, and Open Issues. IEEE Access 2021, 9, 75961–75980.
- Gao, Y.; Xiao, F.; Liu, J.; Wang, R. Distributed Soft Fault Detection for Interval Type-2 Fuzzy-Model-Based Stochastic Systems With Wireless Sensor Networks. IEEE Trans. Ind. Inform. 2019, 15, 334–347.
- Li, L.; Dai, H.; Chen, G.; Zheng, J.; Dou, W.; Wu, X. Radiation Constrained Fair Charging for Wireless Power Transfer. ACM Trans. Sens. Netw. 2019, 15, 1–33.
- Alwan, H.; Agarwal, A. A Survey on Fault Tolerant Routing Techniques in Wireless Sensor Networks. In Proceedings of the 2009 Third International Conference on Sensor Technologies and Applications, Glyfada, Greece, 14–19 June 2009; pp. 366–371.
- Jiang, P. A New Method for Node Fault Detection in Wireless Sensor Networks. Sensors 2009, 9, 1282–1294.
- Alansari, Z.; Prasanth, A.; Belgaum, M.R. A Comparison Analysis of Fault Detection Algorithms in Wireless Sensor Networks. In Proceedings of the 2018 International Conference on Innovation and Intelligence for Informatics, Computing and Technologies (3ICT), Zallaq, Bahrain, 18–20 November 2018; pp. 1–6.
- Agarwal, V.; Tapaswi, S.; Chanak, P. Intelligent Fault-Tolerance Data Routing Scheme for IoT-enabled WSNs. IEEE Int. Things J. 2022, 4662, 1.
- Vihman, L.; Kruusmaa, M.; Raik, J. Systematic Review of Fault Tolerant Techniques in Underwater Sensor Networks. Sensors 2021, 21, 3264.
- Effah, E.; Thiare, O. Survey: Faults, Fault Detection and Fault Tolerance Techniques in Wireless Sensor Networks. Int. J. Comput. Sci. Inf. Secure 2018, 16, 1–14. Available online: https://sites.google.com/site/ijcsis/ (accessed on 1 October 2018).
- Chouikhi, S.; El Korbi, I.; Ghamri-Doudane, Y.; Saidane, L.A. A survey on fault tolerance in small and large scale wireless sensor networks. Comput. Commun. 2015, 69, 22–37.
- Krivulya, G.; Skarga-Bandurova, I.; Tatarchenko, Z.; Seredina, O.; Shcherbakova, M.; Shcherbakov, E. An Intelligent Functional Diagnostics of Wireless Sensor Network. In Proceedings of the 2019 7th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Istanbul, Turkey, 26–28 August 2019; pp. 135–139.
- Saeed, U.; Lee, Y.-D.; Jan, S.; Koo, I. CAFD: Context-Aware Fault Diagnostic Scheme towards Sensor Faults Utilizing Machine Learning. Sensors 2021, 21, 617.
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Novel Fault Management Framework Using Markov Chain in Wireless Sensor Networks: FMMC. Wirel. Pers. Commun. 2020, 114, 583–608.
- Boussif, A.; Ghazel, M.; Basilio, J.C. Intermittent fault diagnosability of discrete event systems: An overview of automaton-based approaches. Discret. Event Dyn. Syst. 2021, 31, 59–102.
- Chen, L.; Li, G.; Huang, G. A hypergrid based adaptive learning method for detecting data faults in wireless sensor networks. Inf. Sci. 2021, 553, 49–65.
- Swain, R.R.; Khilar, P.M.; Bhoi, S.K. Underlying and Persistence Fault Diagnosis in Wireless Sensor Networks Using Majority Neighbors Co-ordination Approach. Wirel. Pers. Commun. 2020, 111, 763–798.
- Zagrouba, R.; Kardi, A. Comparative Study of Energy Efficient Routing Techniques in Wireless Sensor Networks. Information 2021, 12, 42.
- Mitra, S.; De Sarkar, A.; Roy, S. A review of fault management system in wireless sensor network. In Proceedings of the CUBE International Information Technology Conference on-CUBE’12, Pune, India, 3–6 September 2012; p. 144.
- Huangshui, H.; Guihe, Q. Fault Management Frameworks in Wireless Sensor Networks. In Proceedings of the 2011 Fourth International Conference on Intelligent Computation Technology and Automation, Shenzhen, Guangdong, 28–29 March 2011; pp. 1093–1096.
- Mitra, S.; Das, A.; Mazumder, S. Comparative study of fault recovery techniques in Wireless Sensor Network. In Proceedings of the 2016 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Pune, India, 19–21 December 2016; pp. 130–133.
- Salayma, M.; Al-Dubai, A.; Romdhani, I.; Nasser, Y. Wireless Body Area Network (WBAN). ACM Comput. Surv. 2017, 50, 1–38.
- Baniata, M.; Reda, H.T.; Chilamkurti, N.; Abuadbba, A. Energy-Efficient Hybrid Routing Protocol for IoT Communication Systems in 5G and Beyond. Sensors 2021, 21, 537.
- Chanak, P.; Banerjee, I. Fuzzy rule-based faulty node classification and management scheme for large scale wireless sensor networks. Expert Syst. Appl. 2016, 45, 307–321.
- Yemeni, Z.; Wang, H.; Ismael, W.M.; Hawbani, A.; Chen, Z. CFDDR: A Centralized Faulty Data Detection and Recovery Approach for WSN With Faults Identification. IEEE Syst. J. 2021, 16, 3001–3012.
- Chander, B.; Kumaravelan, G. Outlier detection strategies for WSNs: A survey. J. King Saud Univ. Comput. Inf. Sci. 2021.
- Singh, J.; Kaur, R.; Singh, D. A survey and taxonomy on energy management schemes in wireless sensor networks. J. Syst. Arch. 2020, 111, 101782.
- Azzouz, I.; Boussaid, B.; Zouinkhi, A.; Abdelkrim, M.N. Multi-faults classification in WSN: A deep learning approach. In Proceedings of the International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Monastir, Tunisia, 20–22 December 2020; pp. 343–348.
- Tavallali, P.; Tavallali, P.; Singhal, M. K-means tree: An optimal clustering tree for unsupervised learning. J. Supercomput. 2021, 77, 5239–5266.
- Lavanya, S.; Prasanth, A.; Jayachitra, S.; Shenbagarajan, A. A Tuned Classification Approach for Efficient Heterogeneous Fault Diagnosis in IoT-enabled WSN Applications. Measurement 2021, 183, 109771.
- Moridi, E.; Haghparast, M.; Hosseinzadeh, M.; Jassbi, S.J. Fault management frameworks in wireless sensor networks: A survey. Comput. Commun. 2020, 155, 205–226.
- Rajan, M.S.; Dilip, G.; Kannan, N.; Namratha, M.; Majji, S.; Mohapatra, S.K.; Patnala, T.R.; Karanam, S.R. Diagnosis of fault node in wireless sensor networks using adaptive neuro-fuzzy inference system. Appl. Nanosci. 2021, 1–9.
- Yu, T.; Akhtar, A.M.; Wang, X.; Shami, A. Temporal and spatial correlation based distributed fault detection in wireless sensor networks. In Proceedings of the 28th Canadian Conference on Electrical and Computer Engineering (CCECE), Halifax, NS, Canada, 3–6 May 2015; pp. 1351–1355.
- Jin, X.; Chow, T.W.S.; Sun, Y.; Shan, J.; Lau, B.C.P. Kuiper test and autoregressive model-based approach for wireless sensor network fault diagnosis. Wirel. Netw. 2015, 21, 829–839.
- Kaur, R.; Sandhu, J.K.; Sapra, L. Machine Learning Technique for Wireless Sensor Networks. In Proceedings of the International Conference on Parallel Distributed and Grid Computing (PDGC), Solan, India, 6–8 November 2020; pp. 332–335.
- Javaid, A.; Javaid, N.; Wadud, Z.; Saba, T.; Sheta, O.E.; Saleem, M.Q.; Alzahrani, M.E. Machine Learning Algorithms and Fault Detection for Improved Belief Function Based Decision Fusion in Wireless Sensor Networks. Sensors 2019, 19, 1334.
- Sutagundar, A.V.; Bennur, V.S.; Anusha, A.; Bhanu, K. Agent based fault tolerance in wireless sensor networks. In Proceedings of the 2016 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–27 August 2016; pp. 1–6.
- Diaz, S.; Mendez, D.; Kraemer, R. A Review on Self-Healing and Self-Organizing Techniques for Wireless Sensor Networks. J. Circuits Syst. Comput. 2019, 28, 1930005.
- Seyfollahi, A.; Ghaffari, A. A lightweight load balancing and route minimizing solution for routing protocol for low-power and lossy networks. Comput. Netw. 2020, 179, 107368.
- Biswas, P.; Samanta, T. True Event-Driven and Fault-Tolerant Routing in Wireless Sensor Network. Wirel. Pers. Commun. 2020, 112, 439–461.
- Qiu, T.; Chen, N.; Li, K.; Qiao, D.; Fu, Z. Heterogeneous ad hoc networks: Architectures, advances and challenges. Ad Hoc Netw. 2017, 55, 143–152.
- Kiran, W.S.; Smys, S.; Bindhu, V. Clustering of WSN Based on PSO with Fault Tolerance and Efficient Multidirectional Routing. Wirel. Pers. Commun. 2021, 121, 31–47.