The implementation of intelligent technology in agriculture is seriously investigated as a way to increase agriculture production while reducing the amount of human labor. In agriculture, recent technology has seen image annotation utilizing deep learning techniques. Due to the rapid development of image data, image annotation has gained a lot of attention. The use of deep learning in image annotation can extract features from images and has been shown to analyze enormous amounts of data successfully. Deep learning is a type of machine learning method inspired by the structure of the human brain and based on artificial neural network concepts. Through training phases that can label a massive amount of data and connect them up with their corresponding characteristics, deep learning can conclude unlabeled data in image processing. For complicated and ambiguous situations, deep learning technology provides accurate predictions. This technology strives to improve productivity, quality and economy and minimize deficiency rates in the agriculture industry.
- Image annotation
- Deep learning
- Agriculture
- Plant recognition
- Disease detection
- Classification
- Yiled estimation
1. Introduction
2. Deep Learning for Image Annotation
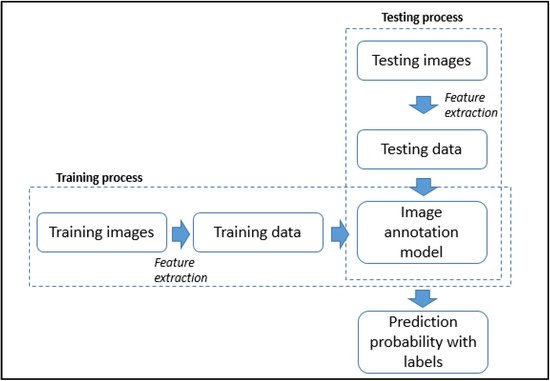



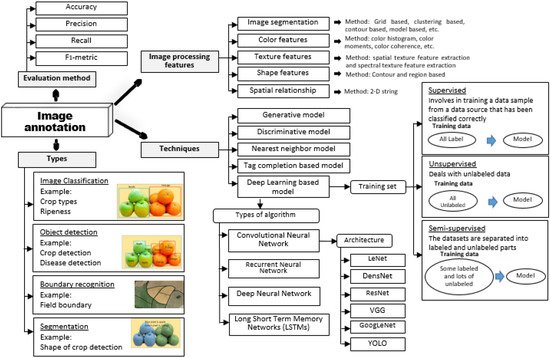
This entry is adapted from 10.3390/agriculture12071033
References
- Khan, T.; Sherazi, H.; Ali, M.; Letchmunan, S.; Butt, U. Deep Learning-Based Growth Prediction System: A Use Case of China Agriculture. Agronomy 2021, 11, 1551.
- Ahmad, N.; Singh, S. Comparative study of disease detection in plants using machine learning and deep learning. In Proceedings of the 2nd International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2021; pp. 54–59.
- Zheng, Y.-Y.; Kong, J.-L.; Jin, X.-B.; Wang, X.-Y.; Su, T.-L.; Zuo, M. CropDeep: The Crop Vision Dataset for Deep-Learning-Based Classification and Detection in Precision Agriculture. Sensors 2019, 19, 1058.
- Velumani, K.; Madec, S.; de Solan, B.; Lopez-Lozano, R.; Gillet, J.; Labrosse, J.; Jezequel, S.; Comar, A.; Baret, F. An automatic method based on daily in situ images and deep learning to date wheat heading stage. Field Crop. Res. 2020, 252, 107793.
- Santos, L.; Santos, F.N.; Oliveira, P.M.; Shinde, P. Deep learning applications in agriculture: A short review. In Proceedings of the Iberian Robotics Conference, Proceedings of the Robot 2019: Fourth Iberian Robotics Conference, Porto, Portugal, 20–22 November 2019; Springer: Cham, Switzerland, 2019; pp. 139–151.
- Khan, N.; Ray, R.; Sargani, G.; Ihtisham, M.; Khayyam, M.; Ismail, S. Current Progress and Future Prospects of Agriculture Technology: Gateway to Sustainable Agriculture. Sustainability 2021, 13, 4883.
- Cecotti, H.; Rivera, A.; Farhadloo, M.; Pedroza, M.A. Grape detection with convolutional neural networks. Expert Syst. Appl. 2020, 159, 113588.
- Kayad, A.; Paraforos, D.; Marinello, F.; Fountas, S. Latest Advances in Sensor Applications in Agriculture. Agriculture 2020, 10, 362.
- Cheng, C.Y.; Liu, L.; Tao, J.; Chen, X.; Xia, R.; Zhang, Q.; Xiong, J.; Yang, K.; Xie, J. The image annotation algorithm using convolutional features from intermediate layer of deep learning. Multimed. Tools Appl. 2021, 80, 4237–4261.
- Niu, Y.; Lu, Z.; Wen, J.-R.; Xiang, T.; Chang, S.-F. Multi-Modal Multi-Scale Deep Learning for Large-Scale Image Annotation. IEEE Trans. Image Process. 2018, 28, 1720–1731.
- Blok, P.M.; van Henten, E.J.; van Evert, F.K.; Kootstra, G. Image-based size estimation of broccoli heads under varying degrees of occlusion. Biosyst. Eng. 2021, 208, 213–233.
- Chen, S.; Wang, M.; Chen, X. Image Annotation via Reconstitution Graph Learning Model. Wirel. Commun. Mob. Comput. 2020, 2020, 8818616.
- Bhagat, P.; Choudhary, P. Image annotation: Then and now. Image Vis. Comput. 2018, 80, 1–23.
- Wang, R.; Xie, Y.; Yang, J.; Xue, L.; Hu, M.; Zhang, Q. Large scale automatic image annotation based on convolutional neural network. J. Vis. Commun. Image Represent. 2017, 49, 213–224.
- Mori, Y.; Takahashi, H.; Oka, R. Image-to-word transformation based on dividing and vector quantizing images with words. In Proceedings of the First International Workshop on Multimedia Intelligent Storage and Retrieval Management, Orlando, FL, USA, October 1999; pp. 1–9.
- Ma, Y.; Liu, Y.; Xie, Q.; Li, L. CNN-feature based automatic image annotation method. Multimed. Tools Appl. 2019, 78, 3767–3780.
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255.
- Mohanty, S.P.; Hughes, D.P.; Salathé, M. Using Deep Learning for Image-Based Plant Disease Detection. Front. Plant Sci. 2016, 7, 1419.
- Hani, N.; Roy, P.; Isler, V. MinneApple: A Benchmark Dataset for Apple Detection and Segmentation. IEEE Robot. Autom. Lett. 2020, 5, 852–858.
- Altaheri, H.; Alsulaiman, M.; Muhammad, G.; Amin, S.U.; Bencherif, M.; Mekhtiche, M. Date fruit dataset for intelligent harvesting. Data Brief 2019, 26, 104514.
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135.
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A Multiclass Weed Species Image Dataset for Deep Learning. Sci. Rep. 2019, 9, 2058.
- Madsen, S.L.; Mathiassen, S.K.; Dyrmann, M.; Laursen, M.S.; Paz, L.-C.; Jørgensen, R.N. Open Plant Phenotype Database of Common Weeds in Denmark. Remote Sens. 2020, 12, 1246.
- Giselsson, T.M.; Jørgensen, R.N.; Jensen, P.K.; Dyrmann, M.; Midtiby, H.S. Midtiby, A public image database for benchmark of plant seedling classification algorithms. arXiv 2017, arXiv:1711.05458.
- Cheng, Q.; Zhang, Q.; Fu, P.; Tu, C.; Li, S. A survey and analysis on automatic image annotation. Pattern Recognit. 2018, 79, 242–259.
- Randive, K.; Mohan, R. A State-of-Art Review on Automatic Video Annotation Techniques. In Proceedings of the International Conference on Intelligent Systems Design and Applications, Vellore, India, 6–8 December 2018; Springer: Cham, Switzerland, 2018; pp. 1060–1069.
- Sudars, K.; Jasko, J.; Namatevs, I.; Ozola, L.; Badaukis, N. Dataset of annotated food crops and weed images for robotic computer vision control. Data Brief 2020, 31, 105833.
- Cao, J.; Zhao, A.; Zhang, Z. Automatic image annotation method based on a convolutional neural network with threshold optimization. PLoS ONE 2020, 15, e0238956.
- Dechter, R. Learning while searching in constraint-satisfaction problems. In Proceedings of the Fifth National Conference on Artificial Intelligence (AAAI-86), Philadelphia, PN, USA, 11–15 August 1986.
- Aizenberg, I.; Aizenberg, N.N.; Vandewalle, J.P. Multi-Valued and Universal Binary Neurons: Theory, Learning and Applications; Springer Science & Business Media: Cham, Switzerland, 2000.
- Schmidhuber, J. Deep learning. Scholarpedia 2015, 10, 32832.
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117.
- Adnan, M.M.; Rahim, M.S.M.; Rehman, A.; Mehmood, Z.; Saba, T.; Naqvi, R.A. Automatic Image Annotation Based on Deep Learning Models: A Systematic Review and Future Challenges. IEEE Access 2021, 9, 50253–50264.
- Chen, J.; Ran, X. Deep Learning with Edge Computing: A Review. Proc. IEEE 2019, 107, 1655–1674.
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the ECCV: European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 139–156.
- Bakhshipour, A.; Jafari, A. Evaluation of support vector machine and artificial neural networks in weed detection using shape features. Comput. Electron. Agric. 2018, 145, 153–160.
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90.
- Bresilla, K.; Perulli, G.D.; Boini, A.; Morandi, B.; Corelli Grappadelli, L.; Manfrini, L. Single-Shot Convolution Neural Networks for Real-Time Fruit Detection Within the Tree. Front. Plant Sci. 2019, 10, 611.
- Tsironis, V.; Bourou, S.; Stentoumis, C. Evaluation of Object Detection Algorithms on A New Real-World Tomato Dataset. ISPRS Arch. 2020, 43, 1077–1084.
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association. Comput. Electron. Agric. 2020, 170, 105247.
- Dos Santos Ferreira, A.; Freitas, D.M.; da Silva, G.G.; Pistori, H.; Folhes, M.T. Unsupervised deep learning and semi-automatic data labeling in weed discrimination. Comput. Electron. Agric. 2019, 165, 104963.
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440.
- Shorewala, S.; Ashfaque, A.; Sidharth, R.; Verma, U. Weed Density and Distribution Estimation for Precision Agriculture Using Semi-Supervised Learning. IEEE Access 2021, 9, 27971–27986.
- Hu, C.; Thomasson, J.A.; Bagavathiannan, M.V. A powerful image synthesis and semi-supervised learning pipeline for site-specific weed detection. Comput. Electron. Agric. 2021, 190, 106423.
- Khan, S.; Tufail, M.; Khan, M.T.; Khan, Z.A.; Iqbal, J.; Alam, M. A novel semi-supervised framework for UAV based crop/weed classification. PLoS ONE 2021, 16, e0251008.
- Karami, A.; Crawford, M.; Delp, E.J. Automatic Plant Counting and Location Based on a Few-Shot Learning Technique. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5872–5886.
- Noon, S.K.; Amjad, M.; Qureshi, M.A.; Mannan, A. Use of deep learning techniques for identification of plant leaf stresses: A review. Sustain. Comput. Inform. Syst. 2020, 28, 100443.
- Fountsop, A.N.; Fendji, J.L.E.K.; Atemkeng, M. Deep Learning Models Compression for Agricultural Plants. Appl. Sci. 2020, 10, 6866.
- Xuan, G.; Gao, C.; Shao, Y.; Zhang, M.; Wang, Y.; Zhong, J.; Li, Q.; Peng, H. Apple Detection in Natural Environment Using Deep Learning Algorithms. IEEE Access 2020, 8, 216772–216780.
- Rahnemoonfar, M.; Sheppard, C. Real-time yield estimation based on deep learning. Autonomous Air and Ground Sensing Systems for Agricultural Optimization and Phenotyping II. In Proceedings of the SPIE Commercial + Scientific Sensing and Imaging, Anaheim, CA, USA, 8 May 2017; p. 1021809.
- Bah, M.D.; Hafiane, A.; Canals, R. Deep Learning with Unsupervised Data Labeling for Weed Detection in Line Crops in UAV Images. Remote. Sens. 2018, 10, 1690.
- Huang, H.; Lan, Y.; Yang, A.; Zhang, Y.; Wen, S.; Deng, J. Deep learning versus Object-based Image Analysis (OBIA) in weed mapping of UAV imagery. Int. J. Remote Sens. 2020, 41, 3446–3479.
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136.
- Franco, C.; Guada, C.; Rodríguez, J.T.; Nielsen, J.; Rasmussen, J.; Gómez, D.; Montero, J. Automatic detection of thistle-weeds in cereal crops from aerial RGB images. In Proceedings of the International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Cádiz, Spain, 11–15 June 2018; Springer: Cham, Switzerland, 2018; pp. 441–452.
- Kalampokas, Τ.; Vrochidou, Ε.; Papakostas, G.A.; Pachidis, T.; Kaburlasos, V.G. Grape stem detection using regression convolutional neural networks. Comput. Electron. Agric. 2021, 186, 106220.
- Liu, X.; Ghazali, K.H.; Han, F.; Mohamed, I.I. Automatic Detection of Oil Palm Tree from UAV Images Based on the Deep Learning Method. Appl. Artif. Intell. 2021, 35, 13–24.
- Yang, Q.; Shi, L.; Han, J.; Yu, J.; Huang, K. A near real-time deep learning approach for detecting rice phenology based on UAV images. Agric. For. Meteorol. 2020, 287, 107938.
- Tetila, E.C.; Machado, B.B.; Astolfi, G.; Belete, N.A.D.S.; Amorim, W.P.; Roel, A.R.; Pistori, H. Detection and classification of soybean pests using deep learning with UAV images. Comput. Electron. Agric. 2020, 179, 105836.
- Mhango, J.; Harris, E.; Green, R.; Monaghan, J. Mapping Potato Plant Density Variation Using Aerial Imagery and Deep Learning Techniques for Precision Agriculture. Remote Sens. 2021, 13, 2705.
- Tri, N.C.; Duong, H.N.; Van Hoai, T.; Van Hoa, T.; Nguyen, V.H.; Toan, N.T.; Snasel, V. A novel approach based on deep learning techniques and UAVs to yield assessment of paddy fields. In Proceedings of the 2017 9th International Conference on Knowledge and Systems Engineering (KSE), Hue, Vietnam, 19–21 October 2017; pp. 257–262.
- Trujillano, F.; Flores, A.; Saito, C.; Balcazar, M.; Racoceanu, D. Corn classification using Deep Learning with UAV imagery. An operational proof of concept. In Proceedings of the IEEE 1st Colombian Conference on Applications in Computational Intelligence (ColCACI), Medellin, Colombia, 16–18 May 2018; pp. 1–4.
- Vaeljaots, E.; Lehiste, H.; Kiik, M.; Leemet, T. Soil sampling automation case-study using unmanned ground vehicle. Eng. Rural Dev. 2018, 17, 982–987.
- Cantelli, L.; Bonaccorso, F.; Longo, D.; Melita, C.D.; Schillaci, G.; Muscato, G. A Small Versatile Electrical Robot for Autonomous Spraying in Agriculture. AgriEngineering 2019, 1, 29.
- Cutulle, M.A.; Maja, J.M. Determining the utility of an unmanned ground vehicle for weed control in specialty crop system. Ital. J. Agron. 2021, 16, 1426–1435.
- Jun, J.; Kim, J.; Seol, J.; Kim, J.; Son, H.I. Towards an Efficient Tomato Harvesting Robot: 3D Perception, Manipulation, and End-Effector. IEEE Access 2021, 9, 17631–17640.
- Mazzia, V.; Salvetti, F.; Aghi, D.; Chiaberge, M. Deepway: A deep learning estimator for unmanned ground vehicle global path planning. arXiv 2020, arXiv:2010.16322.
- Li, Y.; Iida, M.; Suyama, T.; Suguri, M.; Masuda, R. Implementation of deep-learning algorithm for obstacle detection and collision avoidance for robotic harvester. Comput. Electron. Agric. 2020, 174, 105499.
- Persello, C.; Tolpekin, V.; Bergado, J.; de By, R. Delineation of agricultural fields in smallholder farms from satellite images using fully convolutional networks and combinatorial grouping. Remote Sens. Environ. 2019, 231, 111253.
- Mounir, A.J.; Mallat, S.; Zrigui, M. Analyzing satellite images by apply deep learning instance segmentation of agricultural fields. Period. Eng. Nat. Sci. 2021, 9, 1056–1069.
- Gastli, M.S.; Nassar, L.; Karray, F. Satellite images and deep learning tools for crop yield prediction and price forecasting. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8.
- Waldner, F.; Diakogiannis, F.I. Deep learning on edge: Extracting field boundaries from satellite images with a convolutional neural network. Remote Sens. Environ. 2020, 245, 111741.
- Nguyen, T.T.; Hoang, T.D.; Pham, M.T.; Vu, T.T.; Huynh, Q.-T.; Jo, J. Monitoring agriculture areas with satellite images and deep learning. Appl. Soft Comput. 2020, 95, 106565.
- Dhyani, Y.; Pandya, R.J. Deep learning oriented satellite remote sensing for drought and prediction in agriculture. In Proceedings of the 2021 IEEE 18th India Council International Conference (INDICON), Guwahati, India, 19–21 December 2021; pp. 1–5.
- Gadiraju, K.K.; Ramachandra, B.; Chen, Z.; Vatsavai, R.R. Multimodal deep learning based crop classification using multispectral and multitemporal satellite imagery. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 3234–3242.
- Ahmed, A.; Deo, R.; Raj, N.; Ghahramani, A.; Feng, Q.; Yin, Z.; Yang, L. Deep Learning Forecasts of Soil Moisture: Convolutional Neural Network and Gated Recurrent Unit Models Coupled with Satellite-Derived MODIS, Observations and Synoptic-Scale Climate Index Data. Remote Sens. 2021, 13, 554.
- Wang, C.; Liu, B.; Liu, L.; Zhu, Y.; Hou, J.; Liu, P.; Li, X. A review of deep learning used in the hyperspectral image analysis for agriculture. Artif. Intell. Rev. 2021, 54, 5205–5253.
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234.
- Darwin, B.; Dharmaraj, P.; Prince, S.; Popescu, D.; Hemanth, D. Recognition of Bloom/Yield in Crop Images Using Deep Learning Models for Smart Agriculture: A Review. Agronomy 2021, 11, 646.
- Moazzam, S.I.; Khan, U.S.; Tiwana, M.I.; Iqbal, J.; Qureshi, W.S.; Shah, S.I. A Review of application of deep learning for weeds and crops classification in agriculture. In Proceedings of the 2019 International Conference on Robotics and Automation in Industry (ICRAI), Rawalpindi, Pakistan, 21–22 October 2019; pp. 1–6.
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of Deep Learning for Dense Scenes Analysis in Agriculture: A Review. Sensors 2020, 20, 1520.
- Chen, Y.; Zeng, X.; Chen, X.; Guo, W. A survey on automatic image annotation. Appl. Intell. 2020, 50, 3412–3428.
- Bouchakwa, M.; Ayadi, Y.; Amous, I. A review on visual content-based and users’ tags-based image annotation: Methods and techniques. Multimedia Tools Appl. 2020, 79, 21679–21741.
- Dananjayan, S.; Tang, Y.; Zhuang, J.; Hou, C.; Luo, S. Assessment of state-of-the-art deep learning based citrus disease detection techniques using annotated optical leaf images. Comput. Electron. Agric. 2022, 193, 106658.
- He, Z.; Xiong, J.; Chen, S.; Li, Z.; Chen, S.; Zhong, Z.; Yang, Z. A method of green citrus detection based on a deep bounding box regression forest. Biosyst. Eng. 2020, 193, 206–215.
- Morbekar, A.; Parihar, A.; Jadhav, R. Crop disease detection using YOLO. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, Karnataka, India, 5–7 June 2020; pp. 1–5.
- Lamb, N.; Chuah, M.C. A strawberry detection system using convolutional neural networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2515–2520.
- Tassis, L.M.; de Souza, J.E.T.; Krohling, R.A. A deep learning approach combining instance and semantic segmentation to identify diseases and pests of coffee leaves from in-field images. Comput. Electron. Agric. 2021, 186, 106191.
- Fawakherji, M.; Youssef, A.; Bloisi, D.; Pretto, A.; Nardi, D. Crop and weeds classification for precision agriculture using context-independent pixel-wise segmentation. In Proceedings of the Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 146–152.
- Bosilj, P.; Aptoula, E.; Duckett, T.; Cielniak, G. Transfer learning between crop types for semantic segmentation of crops versus weeds in precision agriculture. J. Field Robot. 2019, 37, 7–19.
- Storey, G.; Meng, Q.; Li, B. Leaf Disease Segmentation and Detection in Apple Orchards for Precise Smart Spraying in Sustainable Agriculture. Sustainability 2022, 14, 1458.
- Wspanialy, P.; Brooks, J.; Moussa, M. An image labeling tool and agricultural dataset for deep learning. arXiv 2021, arXiv:2004.03351.
- Biffi, L.; Mitishita, E.; Liesenberg, V.; Santos, A.; Gonçalves, D.; Estrabis, N.; Silva, J.; Osco, L.P.; Ramos, A.; Centeno, J.; et al. ATSS Deep Learning-Based Approach to Detect Apple Fruits. Remote Sens. 2020, 13, 54.
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M. Crop Yield Estimation Using Deep Learning Based on Climate Big Data and Irrigation Scheduling. Energies 2021, 14, 3004.
- Mamdouh, N.; Khattab, A. YOLO-Based Deep Learning Framework for Olive Fruit Fly Detection and Counting. IEEE Access 2021, 9, 84252–84262.
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49.
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36.
- Fukushima, K. Neocognitron: A hierarchical neural network capable of visual pattern recognition. Neural Netw. 1988, 1, 119–130.
- Rahnemoonfar, M.; Sheppard, C. Deep Count: Fruit Counting Based on Deep Simulated Learning. Sensors 2017, 17, 905.
- Thenmozhi, K.; Reddy, U.S. Crop pest classification based on deep convolutional neural network and transfer learning. Comput. Electron. Agric. 2019, 164, 104906.
- Huang, N.; Chou, D.; Lee, C.; Wu, F.; Chuang, A.; Chen, Y.; Tsai, Y. Smart agriculture: Real-time classification of green coffee beans by using a convolutional neural network. IET Smart Cities 2020, 2, 167–172.
- Asad, M.H.; Bais, A. Weed detection in canola fields using maximum likelihood classification and deep convolutional neural network. Inf. Process. Agric. 2020, 7, 535–545.
- Hamidinekoo, A.; Martínez, G.A.G.; Ghahremani, M.; Corke, F.; Zwiggelaar, R.; Doonan, J.H.; Lu, C. DeepPod: A convolutional neural network based quantification of fruit number in Arabidopsis. GigaScience 2020, 9, giaa012.
- Onishi, Y.; Yoshida, T.; Kurita, H.; Fukao, T.; Arihara, H.; Iwai, A. An automated fruit harvesting robot by using deep learning. ROBOMECH J. 2019, 6, 13.
- Adi, M.; Singh, A.K.; Reddy, H.; Kumar, Y.; Challa, V.R.; Rana, P.; Mittal, U. An overview on plant disease detection algorithm using deep learning. In Proceedings of the 2021 2nd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 28–30 April 2021; pp. 305–309.
- Sharma, P.; Berwal, Y.P.S.; Ghai, W. Performance analysis of deep learning CNN models for disease detection in plants using image segmentation. Inf. Process. Agric. 2020, 7, 566–574.
- Kang, H.; Chen, C. Fruit detection, segmentation and 3D visualisation of environments in apple orchards. Comput. Electron. Agric. 2020, 171, 105302.
- Khattak, A.; Asghar, M.U.; Batool, U.; Ullah, H.; Al-Rakhami, M.; Gumaei, A. Automatic Detection of Citrus Fruit and Leaves Diseases Using Deep Neural Network Model. IEEE Access 2021, 9, 112942–112954.
- Yang, W.; Nigon, T.; Hao, Z.; Paiao, G.D.; Fernández, F.G.; Mulla, D.; Yang, C. Estimation of corn yield based on hyperspectral imagery and convolutional neural network. Comput. Electron. Agric. 2021, 184, 106092.
- Fuentes, A.; Yoon, S.; Kim, S.C.; Park, D.S. A Robust Deep-Learning-Based Detector for Real-Time Tomato Plant Diseases and Pests Recognition. Sensors 2017, 17, 2022.
- Maheswari, P.; Raja, P.; Apolo-Apolo, O.E.; Pérez-Ruiz, M. Intelligent Fruit Yield Estimation for Orchards Using Deep Learning Based Semantic Segmentation Techniques—A Review. Front. Plant Sci. 2021, 12, 684328.
- Mu, C.; Yuan, Z.; Ouyang, X.; Sun, P.; Wang, B. Non-destructive detection of blueberry skin pigments and intrinsic fruit qualities based on deep learning. J. Sci. Food Agric. 2021, 101, 3165–3175.
- Lee, S.H.; Goëau, H.; Bonnet, P.; Joly, A. New perspectives on plant disease characterization based on deep learning. Comput. Electron. Agric. 2020, 170, 105220.
- Verma, S.; Chug, A.; Singh, A.P. Application of convolutional neural networks for evaluation of disease severity in tomato plant. J. Discret. Math. Sci. Cryptogr. 2020, 23, 273–282.
- Gehlot, M.; Saini, M.L. Analysis of different CNN architectures for tomato leaf disease classification. In Proceedings of the 2020 5th IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 1–3 December 2020; pp. 1–6.
- Zhang, D.; Islam, M.; Lu, G. A review on automatic image annotation techniques. Pattern Recognit. 2012, 45, 346–362.