Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Mengying Xu and Version 2 by Camila Xu.
Fundus images are used by ophthalmologists and computer-aided diagnostics to detect fundus disease such as diabetic retinopathy, glaucoma, age-related macular degeneration, cataracts, hypertension, and myopia.
- attention mechanisms
- deep learning
- feature fusion
1. Introduction
Fundus images are used by ophthalmologists and computer-aided diagnostics to detect fundus disease such as diabetic retinopathy, glaucoma, age-related macular degeneration, cataracts, hypertension, and myopia. Ophthalmologists have progressively adopted computer-aided diagnosis as its accuracy has increased in recent years. The system assists doctors in making partial diagnoses and saves both doctors and patients time and effort [1][2][3][1,2,3].
Early detection of fundus disease is critical for patients to avoid blindness. Abnormalities in the fundus can indicate different types of disease when a single fundus image is analyzed in three color channels. Patients usually develop ocular diseases differently in each eye due to the complexity and mutual independence of ocular diseases. Figure 1 shows right and left fundus images, taken from the ODIR dataset [4], of a patient with diabetic retinopathy and myopia in the right eye but not the left. The majority of fundus image research focuses on segmenting fundus structures or detecting anomalies in certain fundus diseases [5][6][5,6]. As a result, the ability to classify the whole range of disease on fundus images is critical for the development of future diagnosis systems.


Figure 1.
Images of the ODIR dataset. (
a
) No disease. (
b) Diabetic retinopathy and myopia.
) Diabetic retinopathy and myopia.
Various algorithms in the fields of enhancement [7], segmentation [8][9][10][8,9,10], and classification [11][12][11,12] of fundus images have been developed based on merging image processing and deep learning principles. Deep learning algorithms can be sufficiently trained and are less prone to overfitting for datasets with more images, and test results accuracy can exceed 95%. The fundamental issue in classifying multi-label fundus images is the insufficient data, which prevents the model from being effectively trained. The second is that fundus images with more obvious lesions, such as glaucoma and other disorders that develop later before more obvious lesions appear, are easier to identify, and classification accuracy is significantly lower.
2. Classification of Fundus Images
Most fundus image classification challenges nowadays are focused on identifying a single disease with or without conditions such as diabetic retinopathy [13], myopia [14], glaucoma [15], age-related macular degeneration [16], and other eye disorders. Gour et al. [17] used a single fundus image and developed a convolutional neural network using a transfer learning model to achieve high classification accuracy for multi-labeled images. SGD was used to optimize the network and improved the training set accuracy from 85.25% to 96.49%. However, the classification accuracy is low for fundus images containing glaucoma; one of the reasons is that the dissimilarity of early lesions in these diseases is not significant and not easily detected during classification. Second, the dataset has significantly less data than other disease images, making the model sensitive to overfitting when classifying these diseases. Joon Yul Choi et al. [18] discovered that the number of classes has a significant impact on classification performance. The VGG-19 network was used in this researchtudy to classify three types of fundus images, and the accuracy fell to 41.9% when the number of classes was increased to five. As a result, the critical problems that should be solved as soon as possible are how to handle the test dataset so that it is equally distributed and how to train a high-performance neural network to increase the classification accuracy of fundus images for each disease class.3. Image Augmentation
A major challenge is averaging positive and negative sample distributions and enhancing image quality to increase classification accuracy. The number of input modules in a classification model impacts how well the network performs. The problem of unequal image distribution is common with multi-label data. The data upsampling method, in which the images are rotated, flipped, cropped, and other operations to augment the dataset with insufficient samples. The transfer learning method, in which the weight parameters are obtained by training on large ImageNet image datasets, and it is easier to obtain optimal results when using the pre-trained weights. Luquan et al. [19] improved the accuracy from 62.82% to 75.16% using transfer learning, but the model is prone to overfitting for image classes with small datasets. Third, by changing the underlying network, the model can perform better, even with small samples, Wang et al. [20] used Vgg16 to classify multi-labeleed fundus images with an accuracy of 86%, and changing to EfficientNetB3 improved the accuracy to 90%.4. Attention Mechanisms
Image augmentation solves the problem of unequal sample distribution, but complicated lesions in the fundus, such as microaneurysms and hemorrhages, remain hard to identify. The shallow neural network learns the image’s texture features; as the network deepens, it learns the image’s semantic information. The rich semantic information can improve the network’s classification performance. Including the attention module allows the image to properly learn the spatial position information of lesions. This module imitates humans in finding significant regions in complicated situations and has applications in a variety of vision tasks [21], including image classification, target identification, image segmentation, and facial recognition. As indicated in the correlations in Figure 2, it may be split into six types based on the data domain: channel, spatial, temporal, and branching attention mechanisms, as well as channel and spatial attention and spatial and temporal attention mechanisms. Hu et al. [22] proposed the SENet channel attention network, which includes a squeeze-and-excitation (SE) module at its foundation. The SE module can gather data information, capture inter-channel relationships, and enhance the representation. However, it has the disadvantage of being unable to capture complex global information and having a high model complexity. Sanghyun Woo et al. [23] proposed the convolutional block attention module (CBAM) to improve global information exploitation. It connects the channel attention and spatial attention mechanisms, allowing the network to focus on features and their spatial locations. CBAM can also be added to any existing network architecture due to the network’s lightweight design.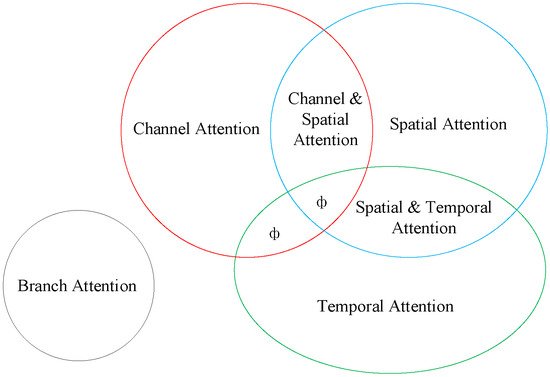
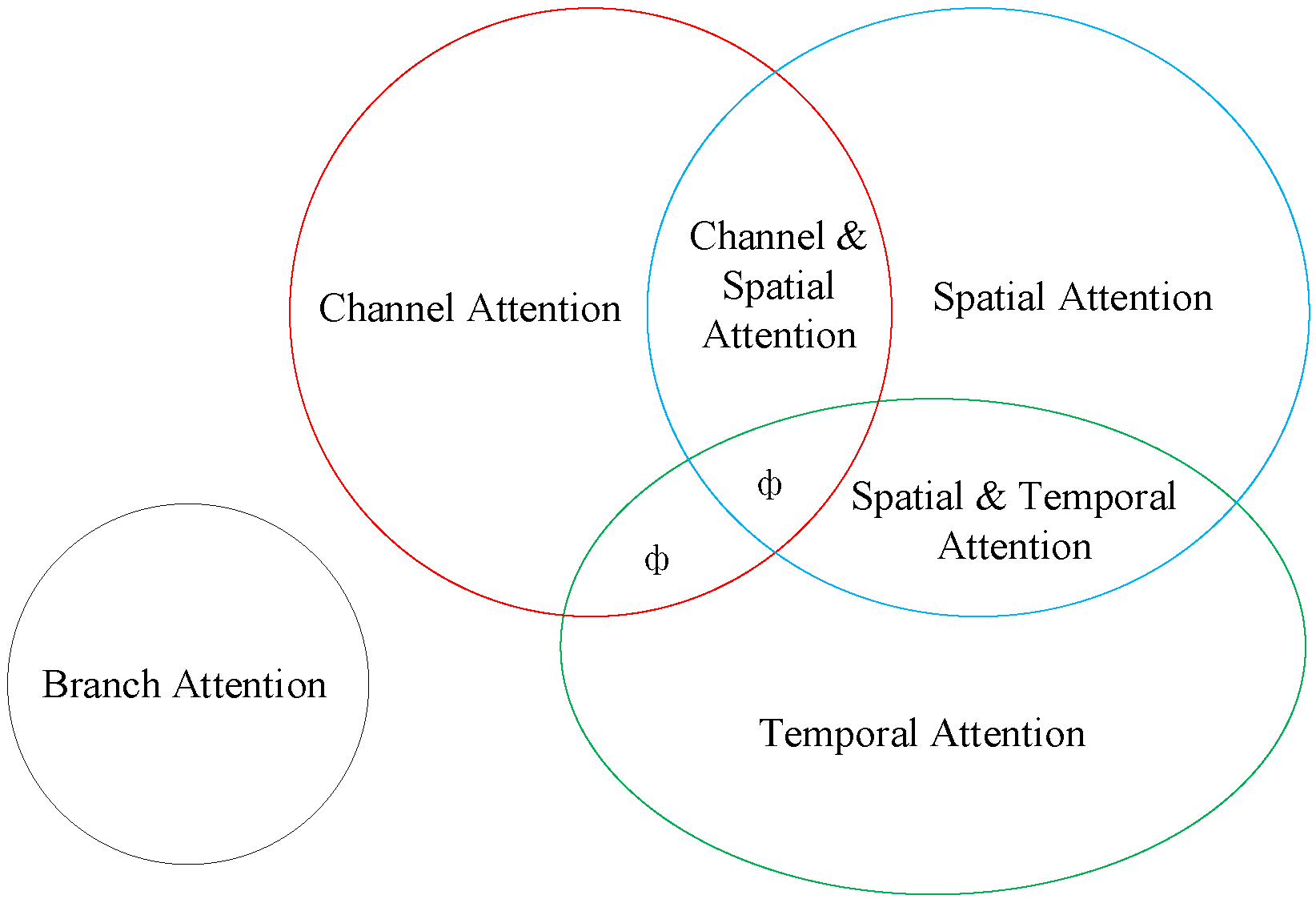
Figure 2. Classification of attentional mechanisms (ф indicates no relevant classification).
Classification of attentional mechanisms (ф indicates no relevant classification).