Underground sewerage systems (USSs) are a vital part of public infrastructure that contributes to collecting wastewater or stormwater from various sources and conveying it to storage tanks or sewer treatment facilities. A healthy USS with proper functionality can effectively prevent urban waterlogging and play a positive role in the sustainable development of water resources. Since it was first introduced in the 1960s, computer vision (CV) has become a mature technology that is used to realize promising automation for sewer inspections.
- survey
- computer vision
- defect inspection
- condition assessment
- sewer pipes
1. Introduction
1.1. Background
1.2. Defect Inspection Framework
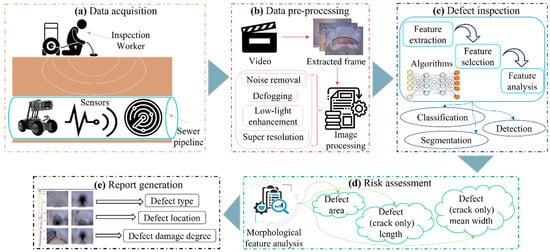
2. Defect Inspection
In this section, several classic algorithms are illustrated, and the research tendency is analyzed. Figure 2 provides a brief description of the algorithms in each category. In order to comprehensively analyze these studies, the publication time, title, utilized methodology, advantages, and disadvantages for each study are covered. Moreover, the specific proportion of each inspection algorithm is computed in Figure 3. It is clear that the defect classification accounts for the most significant percentages in all the investigated studies.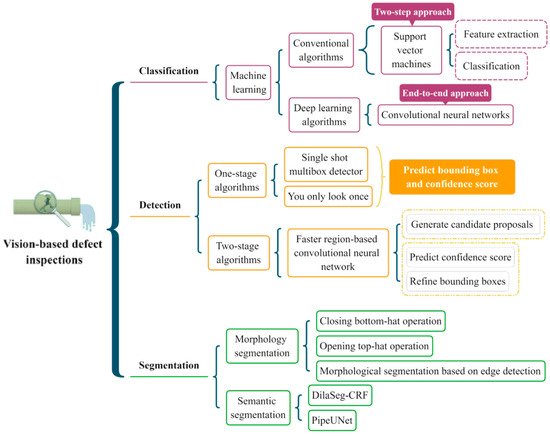
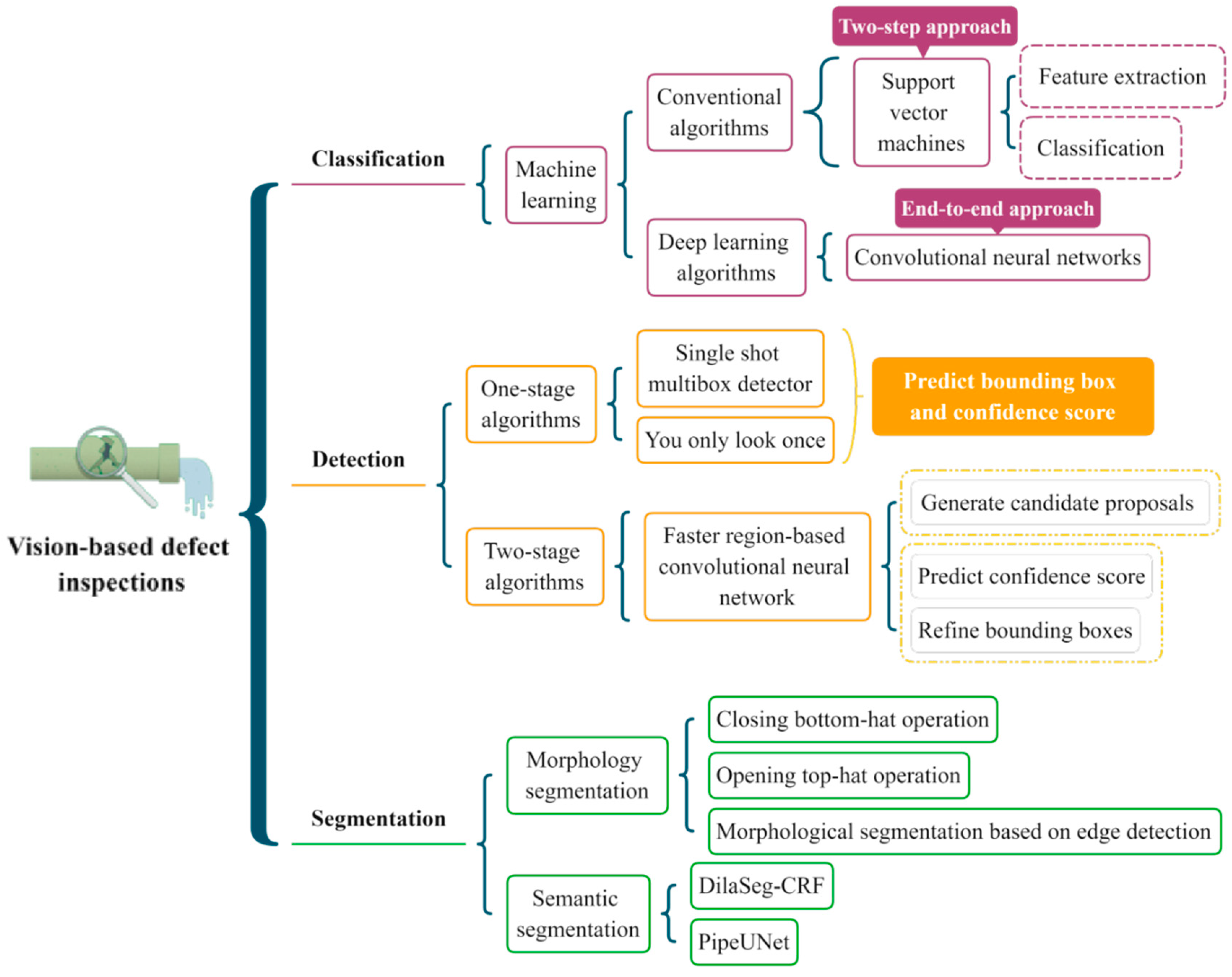
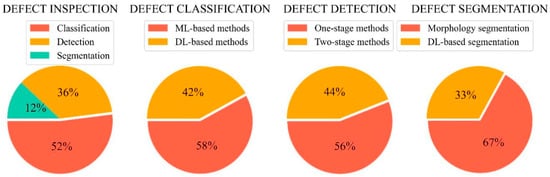
2.1. Defect Classification
Due to the recent advancements in ML, both the scientific community and industry have attempted to apply ML-based pattern recognition in various areas, such as agriculture [32][14], resource management [33][15], and construction [34][16]. At present, many types of defect classification algorithms have been presented for both binary and multi-class classification tasks.2.2. Defect Detection
Rather than the classification algorithms that merely offer each defect a class type, object detection is conducted to locate and classify the objects among the predefined classes using rectangular bounding boxes (BBs) as well as confidence scores (CSs). In recent studies, object detection technology has been increasingly applied in several fields, such as intelligent transportation [75[17][18][19],76,77], smart agriculture [78[20][21][22],79,80], and autonomous construction [81,82,83][23][24][25]. The generic object detection consists of the one-stage approaches and the two-stage approaches. The classic one-stage detectors based on regression include YOLO [84][26], SSD [85][27], CornerNet [86][28], and RetinaNet [87][29]. The two-stage detectors are based on region proposals, including Fast R-CNN [88][30], Faster R-CNN [89][31], and R-FCN [90][32].2.3. Defect Segmentation
Defect segmentation algorithms can predict defect categories and pixel-level location information with exact shapes, which is becoming increasingly significant for the research on sewer condition assessment by re-coding the exact defect attributes and analyzing the specific severity of each defect. The previous segmentation methods were mainly based on mathematical morphology [112,113][33][34]. However, the morphology segmentation approaches were inefficient compared to the DL-based segmentation methods. As a result, the defect segmentation methods based on DL have been recently explored in various fields.3. Dataset and Evaluation Metric
The performances of all the algorithms were tested and are reported based on a specific dataset using specific metrics. As a result, datasets and protocols were two primary determining factors in the algorithm evaluation process. The evaluation results are not convincing if the dataset is not representative, or the used metric is poor. It is challenging to judge what method is the SOTA because the existing methods in sewer inspections utilize different datasets and protocols. Therefore, benchmark datasets and standard evaluation protocols are necessary to be provided for future studies.3.1. Dataset
3.1.1. Dataset Collection
Currently, many data collection robotic systems have emerged that are capable of assisting workers with sewer inspection and spot repair. Table 1 lists the latest advanced robots along with their respective information, including the robot’s name, company, pipe diameter, camera feature, country, and main strong points. Figure 4 introduces several representative robots that are widely utilized to acquire images or videos from underground infrastructures. As shown in Figure 4a, LETS 6.0 is a versatile and powerful inspection system that can be quickly set up to operate in 150 mm or larger pipes. A representative work (Robocam 6) of the Korean company TAP Electronics is shown in Figure 4b. Robocam 6 is the best model to increase the inspection performance without the considerable cost of replacing the equipment. Figure 4c is the X5-HS robot that was developed in China, which is a typical robotic crawler with a high-definition camera. In Figure 4d, Robocam 3000, sold by Japan, is the only large-scale system that is specially devised for inspecting pipes ranging from 250 mm to 3000 mm. It used to be unrealistic to apply the crawler in huge pipelines in Korea.

Name | Company | Pipe Diameter | Camera Feature |
|---|
Metric | Description | Country | Strong Point | ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Ref. | |||||||||||||||||||||||||||||||||||||||||
Ref. | |||||||||||||||||||||||||||||||||||||||||
Accuracy (%) | |||||||||||||||||||||||||||||||||||||||||
Processing Speed | |||||||||||||||||||||||||||||||||||||||||
CAM160 (https://goolnk.com/YrYQob accessed on 20 February 2022) | Sewer Robotics | 200–500 mm | NA | 1 | USA | ● Auto horizon adjustment | ● Intensity adjustable LED lighting | ● Multifunctional | |||||||||||||||||||||||||||||||||
Broken, crack, deposit, fracture, hole, root, tap | NA | NA | 4056 | Canada |
[9] |
LETS 6.0 (https://ariesindustries.com/products/ accessed on 20 February 2022) | |||||||||||||||||||||||||||||||||||
2 | ARIES INDUSTRIES | Connection, crack, debris, deposit, infiltration, material change, normal, root | 150 mm or larger | ||||||||||||||||||||||||||||||||||||||
Precision | The proportion of positive samples in all positive prediction samples |
[9] |
Recall | 1440 × 720–320 × 256 | Self-leveling lateral camera or a Pan and tilt camera | RedZone® | Solo CCTV crawler | USA | The proportion of positive prediction samples in all positive samples |
[48] | ● Slim tractor profile | ● Superior lateral camera | ● Simultaneously acquire mainline and lateral videos | ||||||||||||||||||||||||||||
[ | 12,000 | USA |
[48] |
[36] |
36] |
||||||||||||||||||||||||||||||||||||
AUPR: 6.8 | NA | [48] |
[36] |
wolverine® 2.02 | |||||||||||||||||||||||||||||||||||||
3 | ARIES INDUSTRIES | Attached deposit, defective connection, displaced joint, fissure, infiltration, ingress, intruding connection, porous, root, sealing, settled deposit, surface | |||||||||||||||||||||||||||||||||||||||
3 | 150–450 mm | NA | USA | Dataset 1: 2 classes | 1040 × 1040 | ● Powerful crawler to maneuver obstacles |
Two-level hierarchical CNNs | Front-facing and back-facing camera with a 185∘ wide lens | Classification | 2,202,582 | Accuracy: 94.5 | Precision: 96.84 | Recall: 92 | ● Minimum set uptime | ● Camera with lens cleaning technique | ||||||||||||||||||||||||||
F1-score: 94.36 | The Netherlands | [49] | 1.109 h for 200 videos[37] |
[69] |
[38] |
X5-HS (https://goolnk.com/Rym02W accessed on 20 February 2022) | EASY-SIGHT | ||||||||||||||||||||||||||||||||||
4 | 300–3000 mm | ≥2 million pixels | Dataset 1: defective, normal | NA | |||||||||||||||||||||||||||||||||||||
Dataset 2: 6 classes | China | NA | Accuracy: 94.96 | Precision: 85.13 | Recall: 84.61 | 40,000 | ● High-definition | ● Freely choose wireless and wired connection and control | ● Display and save videos in real time | ||||||||||||||||||||||||||||||||
F1-score: 84.86 | China | [69] |
|||||||||||||||||||||||||||||||||||||||
4 | 8 classes | Deep CNN | Classification | Accuracy: 64.8 | NA |
[70] |
[39] |
True accuracy | The proportion of all predictions excluding the missed defective images among the entire actual images |
[58] |
[65] |
||||||||||||||||||||||||||||||
AUROC | |||||||||||||||||||||||||||||||||||||||||
5 | 6 classes | CNN | Classification | Accuracy: 96.58 | NA |
[71] |
[41] |
Area under the receiver operator characteristic (ROC) curve | |||||||||||||||||||||||||||||||||
6 |
[49] |
[37] |
|||||||||||||||||||||||||||||||||||||||
8 classes | CNN | Classification | Accuracy: 97.6 | 0.15 s/image |
[52] |
[42] |
AUPR | ||||||||||||||||||||||||||||||||||
7 | Area under the precision-recall curve | 7 classes | [49] |
[37] |
|||||||||||||||||||||||||||||||||||||
Multi-class random forest | Classification | Accuracy: 71 | 25 FPS |
[66] |
[43] |
mAP | mAP first calculates the average precision values for different recall values for one class, and then takes the average of all classes | ||||||||||||||||||||||||||||||||||
8 |
[9] |
||||||||||||||||||||||||||||||||||||||||
7 classes | SVM | Classification | Accuracy: 84.1 | NA |
[41] |
[40 |
Detection rate | The ratio of the number of the detected defects to total number of defects |
[106] |
[57] |
|||||||||||||||||||||||||||||||
Error rate | The ratio of the number of mistakenly detected defects to the number of non-defects |
[106] |
[57] |
||||||||||||||||||||||||||||||||||||||
PA | Pixel accuracy calculating the overall accuracy of all pixels in the image |
[116] |
[48] |
||||||||||||||||||||||||||||||||||||||
[ | ] | ||||||||||||||||||||||||||||||||||||||||
1 | 3 classes | Multiple binary CNNs | Classification | ||||||||||||||||||||||||||||||||||||||
Accuracy: 86.2 | Precision: 87.7 | Recall: 90.6 | NA |
[48] |
[36] |
||||||||||||||||||||||||||||||||||||
] | |||||||||||||||||||||||||||||||||||||||||
mPA | |||||||||||||||||||||||||||||||||||||||||
The average of pixel accuracy for all categories |
[116] | ||||||||||||||||||||||||||||||||||||||||
mIoU | The ratio of intersection and union between predictions and GTs |
[116] |
[48] |
||||||||||||||||||||||||||||||||||||||
fwIoU | Frequency-weighted IoU measuring the mean IoU value weighing the pixel frequency of each class |
[116] |
[48] |
||||||||||||||||||||||||||||||||||||||
ID | Number of Images | Algorithm | Task | Performance | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2 | 12 classes | Single CNN | Classification | AUROC: 87.1 | |||||||||||||||||
Accuracy | The proportion of correct prediction in all prediction samples |
[48] |
[36] |
||||||||||||||||||
[ | ] | ||||||||||||||||||||
Robocam 6 (https://goolnk.com/43pdGA accessed on 20 February 2022) | TAP Electronics | 600 mm or more | Sony 130-megapixel Exmor 1/3-inch CMOS | Korea | ● High-resolution | ● All-in-one subtitle system | |||||||||||||||
RoboCam Innovation4 | TAP Electronics | 600 mm or more | Sony 130-megapixel Exmor 1/3-inch CMOS | Korea | ● Best digital record performance | ● Super white LED lighting | ● Cableless | ||||||||||||||
Robocam 30004 | TAP Electronics’ Japanese subsidiary | 250–3000 mm | Sony 1.3-megapixel Exmor CMOS color | Japan | ● Can be utilized in huge pipelines | ● Optical 10X zoom performance | |||||||||||||||
3.1.2. Benchmarked Dataset
Open-source sewer defect data is necessary for academia to promote fair comparisons in automatic multi-defect classification tasks. In this survey, a publicly available benchmark dataset called Sewer-ML [125][35] for vision-based defect classification is introduced. The Sewer-ML dataset, acquired from Danish companies, contains 1.3 million images labeled by sewer experts with rich experience. Figure 5 shows some sample images from the Sewer-ML dataset, and each image includes one or more classes of defects. The recorded text in the image was redacted using a Gaussian blur kernel to protect private information. Besides, the detailed information of the datasets used in recent papers is described in Table 2. This paper summarizes 32 datasets from different countries in the world, of which the USA has 12 datasets, accounting for the largest proportion. The largest dataset contains 2,202,582 images, whereas the smallest dataset has only 32 images. Since the images were acquired by various types of equipment, the collected images have varied resolutions ranging from 64 × 64 to 4000 × 46,000.

ID | Defect Type | Image Resolution | Equipment | Number of Images | Country | Ref. | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Dataset 2: barrier, deposit, disjunction, fracture, stagger, water | |||||||||||||||||||||||||||||||||
15,000 | |||||||||||||||||||||||||||||||||
5 | Broken, deformation, deposit, other, joint offset, normal, obstacle, water | 1435 × 1054–296 × 166 | NA | 18,333 | China |
[70] |
[39] |
||||||||||||||||||||||||||
6 | Attached deposits, collapse, deformation, displaced joint, infiltration, joint damage, settled deposit | NA | NA | 1045 | China |
[41] |
[40] |
||||||||||||||||||||||||||
7 | Circumferential crack, longitudinal crack, multiple crack | 320 × 240 | NA | 335 | USA |
[11] |
|||||||||||||||||||||||||||
8 | Debris, joint faulty, joint open, longitudinal, protruding, surface | NA | Robo Cam 6 with a 1/3-in. SONY Exmor CMOS camera | 48,274 | South Korea |
[71] |
[41] |
||||||||||||||||||||||||||
9 | |||||||||||||||||||||||||||||||||
9 | Broken, crack, debris, joint faulty, joint open, normal, protruding, surface | 3 classes | 1280 × 720 | SVM | Robo Cam 6 with a megapixel Exmor CMOS sensor | 115,170 | Classification | South Korea | Recall: 90.3 | Precision: 90.3 |
[52] |
[42] |
|||||||||||||||||||||
10 FPS | 10 | Crack, deposit, else, infiltration, joint, root, surface | NA | Remote cameras | 2424 | F1-score: 96.6 | UK | 15 min 30 images |
[66] |
[43] |
|||||||||||||||||||||||
[ | ] | [51] |
11 | ||||||||||||||||||||||||||||||
11 | Broken, crack, deposit, fracture, hole, root, tap | 3 classes | NA | RotBoost and statistical feature vector | NA | 1451 | Canada | Classification | Accuracy: 89.96 | [104 |
1.5 s/image | ] |
[44] |
||||||||||||||||||||
[ | ] | [52] |
12 | Crack, deposit, infiltration, root | |||||||||||||||||||||||||||||
12 | 7 classes | 1440 × 720–320 × 256 | Neuro-fuzzy classifier | RedZone® Solo CCTV crawler | Classification | 3000 | Accuracy: 91.36 | USA | NA |
[98] |
[45] |
||||||||||||||||||||||
[ | ] | [53] |
13 | Connection, fracture, root | 1507 × 720–720 × 576 | ||||||||||||||||||||||||||||
13 | Front facing CCTV cameras | 3600 | USA | 4 classes | Multi-layer perceptions |
[ |
Classification | Accuracy: 98.2 | 99] |
[46] |
|||||||||||||||||||||||
NA | 14 | Crack, deposit, root | 928 × 576–352 × 256 | NA | 3000 | USA |
[97] |
[47] |
|||||||||||||||||||||||||
[ | ] | ||||||||||||||||||||||||||||||||
14 | 2 classes | Rule-based classifier | Classification | Accuracy: 87 | FAR: 18 | Recall: 89 | NA |
[57] |
[55] |
15 | |||||||||||||||||||||||
15 | Crack, deposit, root | 2 classes | 512 × 256 | OCSVM | NA | Classification | 1880 | Accuracy: 75 | USA |
[ |
NA | 116] |
[48] |
||||||||||||||||||||
[ | ] | [58] |
16 | Crack, infiltration, joint, protruding | 1073 × 749–296 × 237 | NA | 1106 | China |
[122] | ||||||||||||||||||||||||
16 | 4 classes |
[49] |
|||||||||||||||||||||||||||||||
CNN | Classification | Recall: 88 | Precision: 84 | Accuracy: 85 | NA |
[67] |
[59] |
17 | Crack, non-crack | 64 × 64 | |||||||||||||||||||||||
17 | 2 class | Rule-based classifier | NA | Classification | 40,810 | Accuracy: 84 | FAR: 21 | True accuracy: 95 | NA |
[58] |
[65] |
4000 × 46,000–3168 × 4752 | |||||||||||||||||||||
18 | 4 classes | RBN | Canon EOS. Tripods and stabilizers | Classification | 294 | Accuracy: 95 | China | NA |
[73] |
[51] |
|||||||||||||||||||||||
[ | ] |
[ | ] |
[64] |
19 | Collapse, crack, root | |||||||||||||||||||||||||||
19 | NA |
7 classes | YOLOv3 | SSET system | Detection | 239 | mAP: 85.37 | USA |
[61] |
[52] |
|||||||||||||||||||||||
33 FPS | [ | 9] |
20 | Clean pipe, collapsed pipe, eroded joint, eroded lateral, misaligned joint, perfect joint, perfect lateral | |||||||||||||||||||||||||||||
20 | NA | 4 classes | Faster R-CNNSSET system | 500 | USA | Detection |
[56] |
mAP: 83 | 9 FPS |
[53] |
|||||||||||||||||||||||
[ | ] |
[45] |
21 | Cracks, joint, reduction, spalling | 512 × 512 | CCTV or Aqua Zoom camera | 1096 | Canada |
[54] |
||||||||||||||||||||||||
21 | 3 classes | Faster R-CNN | Detection | 22 | Defective, normal | NA | CCTV (Fisheye) | 192 | USA |
[57] |
[55] |
||||||||||||||||||||||
mAP: 77 | 110 ms/image |
[99] |
[46] |
23 | Deposits, normal, root | 1507 × 720–720 × 576 | Front-facing CCTV cameras | 3800 | USA |
[72] |
[56] |
||||||||||||||||||||||
24 | Crack, non-crack | 240 × 320 | CCTV | 200 | South Korea |
[106] | |||||||||||||||||||||||||||
F1-score | Harmonic mean of precision and recall |
[69] |
[38] |
||||||||||||||||||||||||||||||
10 | 3 classes | CNN | Classification | Accuracy: 96.7 | Precision: 99.8 | Recall: 93.6Australia |
[109] |
[50] |
|||||||||||||||||||||||||
18 | Crack, normal, spalling | ||||||||||||||||||||||||||||||||
22 | 3 classes | Faster R-CNN | Detection | Precision: 88.99 | Recall: 87.96 | F1-score: 88.21 | 110 ms/image |
[97] |
[47] |
[ | |||||||||||||||||||||||
23 | 2 classes | CNN | Detection | Accuracy: 96 | Precision: 90 |
57] |
|||||||||||||||||||||||||||
0.2782 s/image | [ | ] |
[50] |
25 | Faulty, normal | NA | CCTV | 8000 | UK |
[65] |
[58] |
||||||||||||||||||||||
26 | |||||||||||||||||||||||||||||||||
24 | 3 classes | Faster R-CNN | Detection | mAP: 71.8 | 110 ms/image |
[105] |
[63] |
||||||||||||||||||||||||||
SSD | mAP: 69.5 | 57 ms/image | Blur, deposition, intrusion, obstacle | ||||||||||||||||||||||||||||||
YOLOv3 | mAP: 53 | NA | 33 ms/image | CCTV | 27 | Crack, deposit, displaced joint, ovality | NA | CCTV (Fisheye) | 32 | Qatar |
[ | ||||||||||||||||||||||
25 | 2 classes | 103] |
[60] |
||||||||||||||||||||||||||||||
29 | Crack, non-crack | 320 × 240–20 × 20 | CCTV | 100 | NA | ||||||||||||||||||||||||||||
FAR | False alarm rate in all prediction samples |
[57] |
[55] |
12,000 | NA |
[67] |
[59] |
Rule-based detector | Detection | Detection rate: 89.2 | Error rate: 4.44 | 1 FPS |
[106] |
[57] |
|||||||||||||||||||
26 | 2 classes | GA and CNN | Detection | Detection rate: 92.3 | NA[100] |
[61] |
|||||||||||||||||||||||||||
[ | ] |
[61] |
30 | Barrier, deposition, distortion, fraction, inserted | 600 × 480 | CCTV and quick-view (QV) cameras | |||||||||||||||||||||||||||
27 | 5 classes | SRPN | 10,000 |
Detection | mAP: 50.8 | Recall: 82.4 | China | 153 ms/image |
[110] |
[62] |
|||||||||||||||||||||||
[ | ] | [62] |
31 | ||||||||||||||||||||||||||||||
28 | Fracture | 1 class | NA | CNN and YOLOv3 | CCTV | 2100 | USA | Detection | AP: 71 |
[ |
65 ms/image | 105] |
[63] |
||||||||||||||||||||
[ | ] | [66] |
32 | Broken, crack, fracture, joint open | |||||||||||||||||||||||||||||
29 | NA |
3 classes | CCTV | DilaSeg-CRF | 291 | China |
[59] |
[64] |
3.2. Evaluation Metric
The studied performances are ambiguous and unreliable if there is no suitable metric. In order to present a comprehensive evaluation, multitudinous methods are proposed in recent studies. Detailed descriptions of different evaluation metrics are explained in Table 3. Table 4 presents the performances of the investigated algorithms on different datasets in terms of different metrics.Segmentation | |||||||||||||||||||
PA: 98.69 | |||||||||||||||||||
mPA: 91.57 | |||||||||||||||||||
mIoU: 84.85 | |||||||||||||||||||
fwIoU: 97.47 | |||||||||||||||||||
107 ms/image | |||||||||||||||||||
[ | |||||||||||||||||||
] | |||||||||||||||||||
[ | |||||||||||||||||||
] | |||||||||||||||||||
30 | 4 classes | PipeUNet | Segmentation | mIoU: 76.37 | 32 FPS |
[122] |
[49] |
References
- The 2019 Canadian Infrastructure Report Card (CIRC). 2019. Available online: http://canadianinfrastructure.ca/downloads/canadian-infrastructure-report-card-2019.pdf (accessed on 20 February 2022).
- Tscheikner-Gratl, F.; Caradot, N.; Cherqui, F.; Leitão, J.P.; Ahmadi, M.; Langeveld, J.G.; Le Gat, Y.; Scholten, L.; Roghani, B.; Rodríguez, J.P.; et al. Sewer asset management–state of the art and research needs. Urban Water J. 2019, 16, 662–675.
- 2021 Report Card for America’s Infrastructure 2021 Wastewater. Available online: https://infrastructurereportcard.org/wp-content/uploads/2020/12/Wastewater-2021.pdf (accessed on 20 February 2022).
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering 2019, 5, 199–222.
- Duran, O.; Althoefer, K.; Seneviratne, L.D. State of the art in sensor technologies for sewer inspection. IEEE Sens. J. 2002, 2, 73–81.
- 2021 Global Green Growth Institute. 2021. Available online: http://gggi.org/site/assets/uploads/2019/01/Wastewater-System-Operation-and-Maintenance-Guideline-1.pdf (accessed on 20 February 2022).
- Haurum, J.B.; Moeslund, T.B. A Survey on image-based automation of CCTV and SSET sewer inspections. Autom. Constr. 2020, 111, 103061.
- Mostafa, K.; Hegazy, T. Review of image-based analysis and applications in construction. Autom. Constr. 2021, 122, 103516.
- Yin, X.; Chen, Y.; Bouferguene, A.; Zaman, H.; Al-Hussein, M.; Kurach, L. A deep learning-based framework for an automated defect detection system for sewer pipes. Autom. Constr. 2020, 109, 102967.
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-based defect detection and classification approaches for industrial applications—A survey. Sensors 2020, 20, 1459.
- Zuo, X.; Dai, B.; Shan, Y.; Shen, J.; Hu, C.; Huang, S. Classifying cracks at sub-class level in closed circuit television sewer inspection videos. Autom. Constr. 2020, 118, 103289.
- Dang, L.M.; Hassan, S.I.; Im, S.; Mehmood, I.; Moon, H. Utilizing text recognition for the defects extraction in sewers CCTV inspection videos. Comput. Ind. 2018, 99, 96–109.
- Li, C.; Lan, H.-Q.; Sun, Y.-N.; Wang, J.-Q. Detection algorithm of defects on polyethylene gas pipe using image recognition. Int. J. Press. Vessel. Pip. 2021, 191, 104381.
- Li, Y.; Wang, H.; Dang, L.M.; Sadeghi-Niaraki, A.; Moon, H. Crop pest recognition in natural scenes using convolutional neural networks. Comput. Electron. Agric. 2020, 169, 105174.
- Wang, H.; Li, Y.; Dang, L.M.; Ko, J.; Han, D.; Moon, H. Smartphone-based bulky waste classification using convolutional neural networks. Multimed. Tools Appl. 2020, 79, 29411–29431.
- Hassan, S.I.; Dang, L.-M.; Im, S.-H.; Min, K.-B.; Nam, J.-Y.; Moon, H.-J. Damage Detection and Classification System for Sewer Inspection using Convolutional Neural Networks based on Deep Learning. J. Korea Inst. Inf. Commun. Eng. 2018, 22, 451–457.
- Sumalee, A.; Ho, H.W. Smarter and more connected: Future intelligent transportation system. Iatss Res. 2018, 42, 67–71.
- Veres, M.; Moussa, M. Deep learning for intelligent transportation systems: A survey of emerging trends. IEEE Trans. Intell. Transp. Syst. 2019, 21, 3152–3168.
- Li, Y.; Wang, H.; Dang, L.M.; Nguyen, T.N.; Han, D.; Lee, A.; Jang, I.; Moon, H. A deep learning-based hybrid framework for object detection and recognition in autonomous driving. IEEE Access 2020, 8, 194228–194239.
- Yahata, S.; Onishi, T.; Yamaguchi, K.; Ozawa, S.; Kitazono, J.; Ohkawa, T.; Yoshida, T.; Murakami, N.; Tsuji, H. A hybrid machine learning approach to automatic plant phenotyping for smart agriculture. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1787–1793.
- Boukhris, L.; Abderrazak, J.B.; Besbes, H. Tailored Deep Learning based Architecture for Smart Agriculture. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 964–969.
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742.
- Melenbrink, N.; Rinderspacher, K.; Menges, A.; Werfel, J. Autonomous anchoring for robotic construction. Autom. Constr. 2020, 120, 103391.
- Lee, D.; Kim, M. Autonomous construction hoist system based on deep reinforcement learning in high-rise building construction. Autom. Constr. 2021, 128, 103737.
- Tan, Y.; Cai, R.; Li, J.; Chen, P.; Wang, M. Automatic detection of sewer defects based on improved you only look once algorithm. Autom. Constr. 2021, 131, 103912.
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 779–788.
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37.
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750.
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988.
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149.
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387.
- Su, T.-C.; Yang, M.-D.; Wu, T.-C.; Lin, J.-Y. Morphological segmentation based on edge detection for sewer pipe defects on CCTV images. Expert Syst. Appl. 2011, 38, 13094–13114.
- Su, T.-C.; Yang, M.-D. Application of morphological segmentation to leaking defect detection in sewer pipelines. Sensors 2014, 14, 8686–8704.
- Haurum, J.B.; Moeslund, T.B. Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13456–13467.
- Kumar, S.S.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Starr, J. Automated defect classification in sewer closed circuit television inspections using deep convolutional neural networks. Autom. Constr. 2018, 91, 273–283.
- Meijer, D.; Scholten, L.; Clemens, F.; Knobbe, A. A defect classification methodology for sewer image sets with convolutional neural networks. Autom. Constr. 2019, 104, 281–298.
- Xie, Q.; Li, D.; Xu, J.; Yu, Z.; Wang, J. Automatic detection and classification of sewer defects via hierarchical deep learning. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1836–1847.
- Li, D.; Cong, A.; Guo, S. Sewer damage detection from imbalanced CCTV inspection data using deep convolutional neural networks with hierarchical classification. Autom. Constr. 2019, 101, 199–208.
- Ye, X.; Zuo, J.; Li, R.; Wang, Y.; Gan, L.; Yu, Z.; Hu, X. Diagnosis of sewer pipe defects on image recognition of multi-features and support vector machine in a southern Chinese city. Front. Environ. Sci. Eng. 2019, 13, 17.
- Hassan, S.I.; Dang, L.M.; Mehmood, I.; Im, S.; Choi, C.; Kang, J.; Park, Y.-S.; Moon, H. Underground sewer pipe condition assessment based on convolutional neural networks. Autom. Constr. 2019, 106, 102849.
- Dang, L.M.; Kyeong, S.; Li, Y.; Wang, H.; Nguyen, T.N.; Moon, H. Deep Learning-based Sewer Defect Classification for Highly Imbalanced Dataset. Comput. Ind. Eng. 2021, 161, 107630.
- Myrans, J.; Kapelan, Z.; Everson, R. Automatic identification of sewer fault types using CCTV footage. EPiC Ser. Eng. 2018, 3, 1478–1485.
- Yin, X.; Chen, Y.; Zhang, Q.; Bouferguene, A.; Zaman, H.; Al-Hussein, M.; Russell, R.; Kurach, L. A neural network-based application for automated defect detection for sewer pipes. In Proceedings of the 2019 Canadian Society for Civil Engineering Annual Conference, CSCE 2019, Montreal, QC, Canada, 12–15 June 2019.
- Cheng, J.C.; Wang, M. Automated detection of sewer pipe defects in closed-circuit television images using deep learning techniques. Autom. Constr. 2018, 95, 155–171.
- Wang, M.; Kumar, S.S.; Cheng, J.C. Automated sewer pipe defect tracking in CCTV videos based on defect detection and metric learning. Autom. Constr. 2021, 121, 103438.
- Wang, M.; Luo, H.; Cheng, J.C. Towards an automated condition assessment framework of underground sewer pipes based on closed-circuit television (CCTV) images. Tunn. Undergr. Space Technol. 2021, 110, 103840.
- Wang, M.; Cheng, J.C. A unified convolutional neural network integrated with conditional random field for pipe defect segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 162–177.
- Pan, G.; Zheng, Y.; Guo, S.; Lv, Y. Automatic sewer pipe defect semantic segmentation based on improved U-Net. Autom. Constr. 2020, 119, 103383.
- Rao, A.S.; Nguyen, T.; Palaniswami, M.; Ngo, T. Vision-based automated crack detection using convolutional neural networks for condition assessment of infrastructure. Struct. Health Monit. 2021, 20, 2124–2142.
- Chow, J.K.; Su, Z.; Wu, J.; Li, Z.; Tan, P.S.; Liu, K.-f.; Mao, X.; Wang, Y.-H. Artificial intelligence-empowered pipeline for image-based inspection of concrete structures. Autom. Constr. 2020, 120, 103372.
- Wu, W.; Liu, Z.; He, Y. Classification of defects with ensemble methods in the automated visual inspection of sewer pipes. Pattern Anal. Appl. 2015, 18, 263–276.
- Sinha, S.K.; Fieguth, P.W. Neuro-fuzzy network for the classification of buried pipe defects. Autom. Constr. 2006, 15, 73–83.
- Moselhi, O.; Shehab-Eldeen, T. Classification of defects in sewer pipes using neural networks. J. Infrastruct. Syst. 2000, 6, 97–104.
- Guo, W.; Soibelman, L.; Garrett, J., Jr. Visual pattern recognition supporting defect reporting and condition assessment of wastewater collection systems. J. Comput. Civ. Eng. 2009, 23, 160–169.
- Khan, S.M.; Haider, S.A.; Unwala, I. A Deep Learning Based Classifier for Crack Detection with Robots in Underground Pipes. In Proceedings of the 2020 IEEE 17th International Conference on Smart Communities: Improving Quality of Life Using ICT, IoT and AI (HONET), Charlotte, NC, USA, 14–16 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 78–81.
- Heo, G.; Jeon, J.; Son, B. Crack automatic detection of CCTV video of sewer inspection with low resolution. KSCE J. Civ. Eng. 2019, 23, 1219–1227.
- Myrans, J.; Kapelan, Z.; Everson, R. Using automatic anomaly detection to identify faults in sewers. WDSA/CCWI Joint Conference Proceedings. 2018. Available online: https://ojs.library.queensu.ca/index.php/wdsa-ccw/article/view/12030 (accessed on 20 February 2022).
- Chen, K.; Hu, H.; Chen, C.; Chen, L.; He, C. An intelligent sewer defect detection method based on convolutional neural network. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1301–1306.
- Hawari, A.; Alamin, M.; Alkadour, F.; Elmasry, M.; Zayed, T. Automated defect detection tool for closed circuit television (cctv) inspected sewer pipelines. Autom. Constr. 2018, 89, 99–109.
- Oullette, R.; Browne, M.; Hirasawa, K. Genetic algorithm optimization of a convolutional neural network for autonomous crack detection. In Proceedings of the 2004 Congress on Evolutionary Computation (IEEE Cat. No. 04TH8753), Portland, OR, USA, 19–23 June 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 516–521.
- Li, D.; Xie, Q.; Yu, Z.; Wu, Q.; Zhou, J.; Wang, J. Sewer pipe defect detection via deep learning with local and global feature fusion. Autom. Constr. 2021, 129, 103823.
- Kumar, S.S.; Wang, M.; Abraham, D.M.; Jahanshahi, M.R.; Iseley, T.; Cheng, J.C. Deep learning–based automated detection of sewer defects in CCTV videos. J. Comput. Civ. Eng. 2020, 34, 04019047.
- Yang, M.-D.; Su, T.-C. Segmenting ideal morphologies of sewer pipe defects on CCTV images for automated diagnosis. Expert Syst. Appl. 2009, 36, 3562–3573.
- Guo, W.; Soibelman, L.; Garrett, J., Jr. Automated defect detection for sewer pipeline inspection and condition assessment. Autom. Constr. 2009, 18, 587–596.
- Kumar, S.S.; Abraham, D.M. A deep learning based automated structural defect detection system for sewer pipelines. In Computing in Civil Engineering 2019: Smart Cities, Sustainability, and Resilience; American Society of Civil Engineers: Reston, VA, USA, 2019; pp. 226–233.