Distributed edge intelligence is a disruptive research area that enables the execution of machine learning and deep learning (ML/DL) algorithms close to where data are generated. Since edge devices are more limited and heterogeneous than typical cloud devices, many hindrances have to be overcome to fully extract the potential benefits of such an approach (such as data-in-motion analytics).
- machine learning
- artificial intelligence
- distributed
- edge intelligence
- fog intelligence
- Internet of Things
1. Introduction
- High latency [8]: offloading intelligence tasks to the edge enables achievement of faster inference, decreasing the inherent delay in data transmission through the network backbone;
- Security and privacy issues [9][10]: it is possible to train and infer on sensitive data fully at the edge, preventing their risky propagation throughout the network, where they are susceptible to attacks. Moreover, edge intelligence can derive non-sensitive information that could then be submitted to the cloud without further processing;
- The need for continuous internet connection: in locations where connectivity is poor or intermittent, the ML/DL could still be carried out;
- Bandwidth degradation: edge computing can perform part of processing tasks on raw data and transmit the produced data to the cloud (filtered/aggregated/pre-processed), thus saving network bandwidth. Transmitting large amounts of data to the cloud burdens the network and impacts the overall Quality of Service (QoS) [11];
- Power waste [12]: unnecessary raw data being transmitted through the internet demands power, decreasing energy efficiency on a large scale.
2. Related Work
Some surveys have been published that address the edge intelligence subject recently. However, they adopt different perspectives from the one adopted in this SLR. Al-Rakhami et al. [13] propose and analyze a framework based on the distributed edge/cloud paradigm using docker technology which provides a very lightweight and effective virtualization solution. This solution can be utilized to manage, deploy and distribute applications onto clusters (e.g., small board devices such as Raspberry PI). It is able to provide an advantageous combination of various benefits and lower costs of data processing performed at the edge instead of central servers. However, the authors base their proposal on experiments to support the proposal of a new framework. The research does not mention any of the nine groups of techniques the researchers present in the work. Wang et al. [14] survey is centered on the connection between Deep Learning and the edge, either to apply DL in optimizing the edge or to use the edge to run DL algorithms. The study is divided into five fronts: DL applications on edge; DL inference in edge; edge computing for DL; DL training at the edge; DL for optimizing the edge. The paper discusses hardware and virtualization aspects. Concerning the (groups of) techniques and strategies, it is more restricted to Federated Learning and the optimization of the edge with DL. Xu et al. [10] approach edge intelligence under the perspectives of edge caching, edge training, edge inference, and edge offloading in a very comprehensive way. The researchers discuss all these aspects in the work but explore additional techniques, and strategies related to pre-processing, federated learning, and scheduling. One intersection of this paper with the researcheours' research is the overlap of three groups of techniques the researchers present (Federated Learning, Edge Pre-processing and Scheduling). However, the researchers deepened the discussion into more groups of techniques. The work presented by Zhou et al. [15] covers artificial intelligence to edge AI, showing a generalized representation of application architecture used in the lifecycle management of ML. In the edge layer: sensors/actuators; edge analytics; logging and monitoring. In the fog layer: visualization; live streaming engines; batch processing; data ingestion; storage and ML model development platforms and libraries. The researchers' rpapesearchr approaches several more domains in which edge intelligence is used, which are not present in this survey. Compared to these other surveys, the researchers analyze the literature more comprehensively, including a discussion on application domains of edge intelligence and their correlation with identified techniques. Verbraeken et al. [16] provide an extensive overview of the current state-of-the-art in terms of outlining the challenges and opportunities of distributed machine learning over conventional machine learning, discussing the techniques used for distributed machine learning. The paper follows the same line of research of Wang et al. [14], with a focus on machine learning applied to the distributed environment. To this end, it makes inroads into the various types of algorithms to solve problems using ML. Table 1 shows the comparison between the researchers' work and the other surveys mentioned in this section. In summary, the main gaps of the analyzed works are focused on aspects such as “Techniques and Strategies” on the edge. The table also shows the aspects of “Challenges”and “Different Application Domains”, where edge intelligence can be used.Challenges | Scope | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Paper | Challenges | Group | of Techniques | Different Application | Domains | ||||||||||||
Al-Rakhami et al. [13] | 0/6 | ||||||||||||||||
CH1 | |||||||||||||||||
[ | |||||||||||||||||
] | |||||||||||||||||
3.2. RQ2—Techniques and Strategies
4.2. RQ2—Techniques and Strategies
Here, the researchers focus on three main aspects, namely: (i) the system architecture, (ii) how the ML tasks are distributed among the devices, and (iii) the underlying adopted techniques. The researchers classify the several approaches used in distributed learning based on these three aspects. The researchers identified nine groups of techniques and strategies, described in what follows: Federated learning; Model partitioning; Right-sizing; Edge pre-processing; Scheduling; Cloud pre-training; Edge only; Model Compression; and Other techniques.3.3. RQ3—Frameworks for Edge Intelligence
4.3. RQ3—Frameworks for Edge Intelligence
This section describes the studies that provided answers to the RQ3 of this survey. Table 4 lists the main frameworks currently used in distributed ML applications. The table also correlates each framework with the corresponding EI group of techniques or the main related strategy.Framework | Groups of | Techniques or | Strategies | Comments | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
2/8 | |||||||||||||||||
Neurosurgeon [ | 1/6 | ||||||||||||||||
Running ML/DL on devices with limited resources | |||||||||||||||||
Model Partitioning | Lightweight scheduler to automatically partition DNN computation between edge devices and cloud at the granularity of NN layers | Wang et al. [14] | CH2 | ||||||||||||||
1/6 | 4/8 | 4/6 | |||||||||||||||
[ | Verbraeken et al. [16] | 1/6 | 0/8 | ||||||||||||||
CH2 | Ensuring energy efficiency without compromising the accuracy | ||||||||||||||||
] | [ | Model Partitioning | |||||||||||||||
JointDNN provides an energy- and performance-efficient method of querying some layers on the mobile device and some layers on the cloud server. | CH3 | CH3 | Communication efficiency |
||||||||||||||
[10 | 0/6 | ||||||||||||||||
] | Model Partitioning | [16][1718][1920][2930][3031][3132][3233][3536][3940][4243][5253][6465][6566] | |||||||||||||||
They divide the NN layers and deploy the part with the lower ones (closer to the input) into edge servers and the part with higher layers (closer to the output) into the cloud for offloading processing. They also propose an offline and an online algorithm that schedules tasks in Edge servers. | Zhou et al. [15] | ||||||||||||||||
CH4 | 2/6 | CH4 | |||||||||||||||
Ensuring data privacy and security | 4/8 | Model Partitioning | [8][ | 0/6 | |||||||||||||
Dianlei Xu et al. [10] | |||||||||||||||||
CH5 | 6/6 | Handling failure in edge devices | 3/8 | 0/6 | |||||||||||||
The researchers' work | 6/6 | 8/8 | 6/6 |
3. Research Methodology
3. Answering the RQs
The research methodology used in this paper consists of a Systematic Literature Review (SLR), where a rigorous protocol of searching the literature is defined and applied to extract information that answers specific research questions. The use of this methodology enables impartial results and an auditable process. This section details the methodology used in the review. According to Brereton et al. [17], an SLR is performed procedurally through distinct processes. This proposal includes an initial phase called ’Plan Review’, which includes: (i) specifying research questions; (ii) developing review protocol; (iii) validating review protocol. In the second phase, ’Conduct Review’, the following are carried out: (iv) identifying relevant research; (v) selecting primary studies; (vi) assessing study quality; (vii) extracting required data; (viii) synthesising data. In the last phase, ’Document Review’, the activities of producing and validating the reports with the reviewed findings are performed, respectively: (ix) writing of the review report, and (x) validating the report.3.1. RQ1—Research Challenges in Edge Intelligence (EI)
4. Answering the RQs
4.1. RQ1—Research Challenges in Edge Intelligence (EI)
In this section, the researchers summarize the challenges faced by the Edge Intelligence (EI) paradigm that the analyzed studies either mentioned or aimed to tackle. The discussion presented in this section aims to provide answers to RQ1: What are the main challenges and open issues in the distributed learning field? As mentioned earlier, performing ML techniques at the edge of the network promises to bring several benefits, but it raises several challenges. As this field is still in its beginning, solutions to such challenges are still being investigated. The surveyed studies tackle several challenges, which can be broadly grouped into six categories, displayed in Table 2 and described in what follows.CH6 | ||
Heterogeneity and low quality of data |
References | Works That Tackle the Challenges | |||||
|---|---|---|---|---|---|---|
CH1 | [10][15][1819][1920][2021][2122][2223][2324][2425][2526][2627][2728] | |||||
[ | ||||||
] | ||||||
Data Quantization | ||||||
Model Partitioning | ||||||
Data compression by jointly considering compression rate and model accuracy. A latency-aware deep decoupling strategy to minimize the overall execution latency is employed. Decouples a deep NN to run a part of it at edge devices and the other part inside the conventional cloud. | ||||||
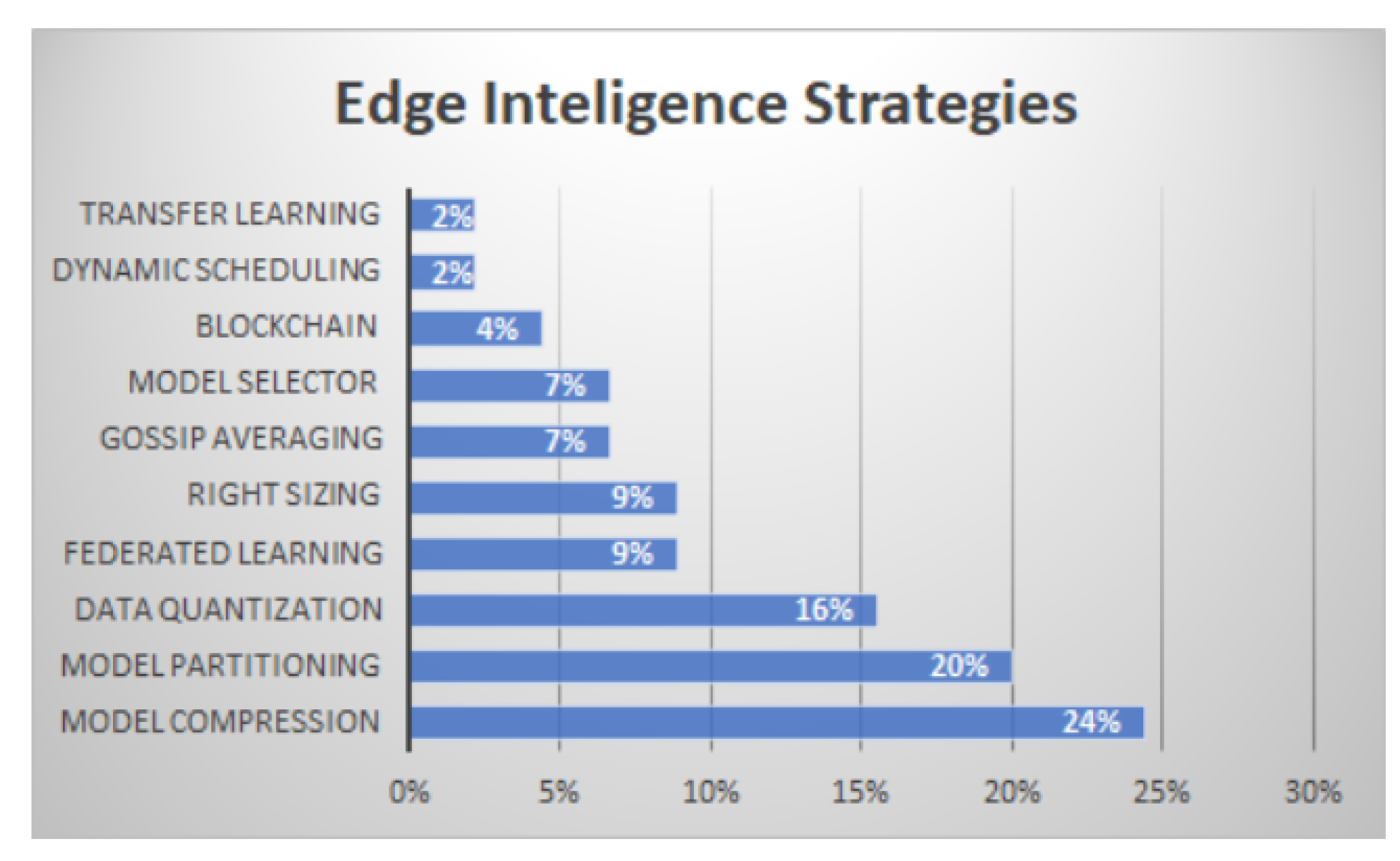

3.4. RQ4—Edge Intelligence Application Domains
4.4. RQ4—Edge Intelligence Application Domains
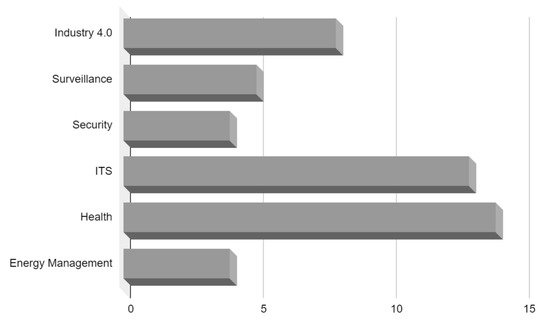
In this section, the researchers present a taxonomy to characterize the application domains where the field of EI has been adopted, providing inputs to answer the RQ4. According to the researched articles, it was possible to group them into six main domains: (i) Industry, (ii) Surveillance, (iii) Security, (iv) Intelligent Transport, (v) Health, and (vi) Energy Management. This does not mean that other domains cannot be created due to new research. Figure 2 illustrates this taxonomy up to a third level. Table 5 shows the works that tackle these domains. Figure 3 summarizes the statistics of the six domains of the publishing by field.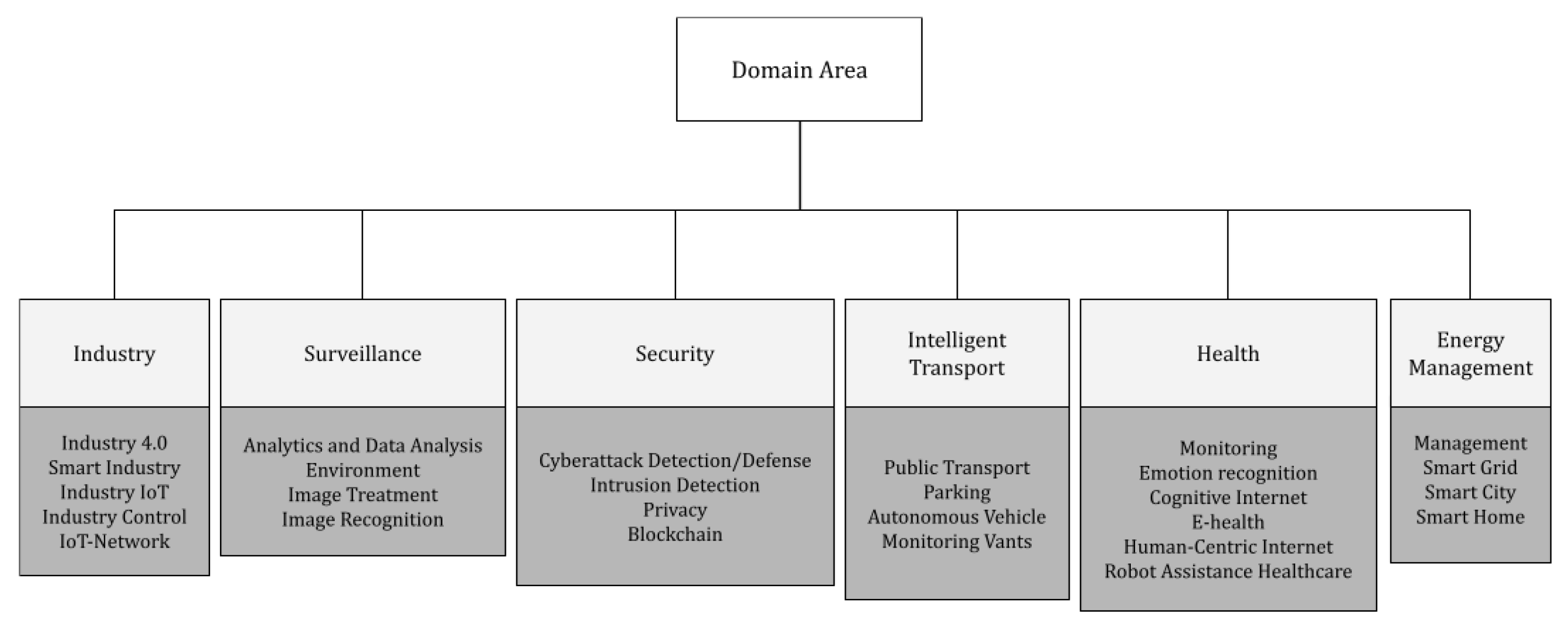

Domains | Works That Approach the Theme | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Industry (8) | [14][2425][2728][2829][2930][3031][3132][3233][3334][3435][3536][3637][3738][3839][3940][4041][4142][4243][4344][4445][4546][4647][4748][4849][4950][5051][5152][5253][5354][5455][5556][5657][5758][5859][5960][6061][ |
||||||||||||||||
Surveillance (5) | |||||||||||||||||
Security (4) | |||||||||||||||||
Intelligent Transport Systems (ITS) (13) | [2223][3637][3940][4142][4748][4849][5253][5455][7172][102103][103104][104105][105106], | ||||||||||||||||
Musical Chair aims at alleviating the compute cost and overcoming the resource barrier by distributing their computation: data parallelism and model parallelism. | CH5 | ||||||||||||||||
Health (14) | Model Partitioning | – | |||||||||||||||
Accurate segmenting NNs under multi-layer IoT architectures | CH6 | ||||||||||||||||
Energy Management (4) | [10] |
Model Compression | Model Selector | [ | Presented by Google Inc., the two hyperparameters introduced allow the model builder to choose the right sized model for the specific application. | ||||||||||||
Squeezenet | Model Compression | It is a reduced DNN that achieves AlexNet-level accuracy with 50 times fewer parameters | |||||||||||||||
Tiny-YOLO | Model Compression | Tiny Yolo is a very lite NN and is hence suitable for running on edge devices. It has an accuracy that is comparable to the standard AlexNet for small class numbers but is much faster. | |||||||||||||||
BranchyNet | Right sizing | Open source DNN training framework that supports the early-exit mechanism. | |||||||||||||||
Model Compression | Transfer Learning | TeamNet trains shallower models using the similar but downsized architecture of a given SOTA (state of the art) deep model. The master node compares its uncertainty with the worker’s and selects the one with the least uncertainty as to the final result. | |||||||||||||||
Model Compression | Data Quantization | Model Selector | The algorithms are optimized by compressing the size of the model, quantizing the weight. The model selector will choose the most suitable model based on the developer’s requirement (the default is accuracy) and the current computing resource. | ||||||||||||||
Data Quantization | TensorFlow’s lightweight solution, which is designed for mobile and edge devices. It leverages many optimization techniques, including quantized kernels, to reduce the latency. | ||||||||||||||||
Data Quantization | Developed by Facebook, is a mobile-optimized library for high-performance NN inference. It provides an implementation of common NN operators on quantized 8-bit tensors. | ||||||||||||||||
Model Compression | Inspired by k-Nearest Neighbor (KNN) and could be deployed on the edges with limited storage and computational power. | ||||||||||||||||
Right Sizing | It requires 72 times less computation than standard Long Short term Memory Networks (LSTM) and improves its accuracy by 1%. | ||||||||||||||||
Model Compression | Data Quantization | Published by Apple, it is a deep learning package optimized for on-device performance to minimize memory footprint and power consumption. Users are allowed to integrate the trained machine learning model into Apple products, such as Siri, Camera, and QuickType. | |||||||||||||||
Model Compression | Data Quantization | The DroNet topology was inspired by residual networks and was reduced in size to minimize the bare image processing time (inference). The numerical representation of weights and activations reduces from the native one, 32-bit floating-point (Float32), down to a 16-bit fixed point one (Fixed16). | |||||||||||||||
Model Selector | Dynamic Scheduling | Stratum can select the best model by evaluating a series of user-built models. A resource monitoring framework within Stratum keeps track of resource utilization and is responsible for triggering actions to elastically scale resources and migrate tasks, as needed, to meet the ML workflow’s Quality of Services (QoS). ML modules can be placed on the edge of the Cloud layer, depending on user requirements and capacity analysis. | |||||||||||||||
Model Compression | Model Partitioning | Right-Sizing | A systematic and structured scheme based on balanced incomplete block design (BIBD) used in situations where the dataflows in DNNs are sparse. Vertical and horizontal model partition and grouped convolution techniques are used to reduce computation and memory. To speed up the inference, BranchyNet is utilized. | ||||||||||||||
In-Edge AI [5] | Federated Learning | Utilizes the collaboration among devices and edge nodes to exchange the learning parameters for better training and inference of the models. | |||||||||||||||
Blockchain | Edgence (EDGe + intelligENCE) is proposed to serve as a blockchain-enabled edge-computing platform to intelligently manage massive decentralized applications in IoT use cases. | ||||||||||||||||
Federated Learning | Combines local stochastic gradient descent (SGD) on each client with a server that performs model averaging. | ||||||||||||||||
Federated Learning | System that enables multiple parties to jointly learn an accurate neural network model for a given objective without sharing their input datasets. | ||||||||||||||||
Blockchain | Federated Learning | Mobile devices’ local model updates are exchanged and verified by leveraging blockchain. | |||||||||||||||
Edgent [6] | Model Partitioning | Right-Sizing | Adaptively partitions DNN computation between the device and edge, in order to leverage hybrid computation resources in proximity for real-time DNN inference. DNN right-sizing accelerates DNN inference through the early exit at a proper intermediate DNN layer to further reduce the computation latency. | ||||||||||||||
Model Partitioning | PipeDream keeps all available GPUs productive by systematically partitioning DNN layers among them to balance work and minimize communication. | ||||||||||||||||
Gossip Averaging | Method to share information between different threads based on gossip algorithms and showing good consensus convergence properties. | ||||||||||||||||
Gossip Averaging | Asynchronous method that replaces the all-reduce collective operation of synchronous training with a gossip aggregation algorithm. | ||||||||||||||||
Gossip Averaging | Asynchronous communication of gradients for further reducing the communication cost. | ||||||||||||||||
Data Quantization | Lossy-compression algorithm for floating-point gradients. The framework reduces the communication time by 70.9 80.7% and offers 2.2 3.1× speedup over the conventional training system while achieving the same level of accuracy. | ||||||||||||||||
Data Quantization | Model compression | Quantization analysis minimizes bit widths without exceeding a strict prediction error bound. Compared to a 16-bit fixed-point baseline, Minerva reduces power consumption by 1.5×. Minerva identifies operands that are close to zero and removes them from the prediction computation such that model accuracy is not affected. Selective pruning further reduces power consumption by 2.0× on top of bit width quantization. | |||||||||||||||
Model Compression | Automatically selects a combination of compression techniques for a given DNN that will lead to an optimal balance between user-specified performance goals and resource constraints. AdaDeep enables up to 9.8× latency reduction, 4.3× energy efficiency improvement, and 38× storage reduction in DNNs while incurring negligible accuracy loss. | ||||||||||||||||
JALAD |