Knowledge graphs (KGs) have rapidly emerged as an important area in AI over the last ten years. Building on a storied tradition of graphs in the AI community, a KG may be simply defined as a directed, labeled, multi-relational graph with some form of semantics. In part, this has been fueled by increased publication of structured datasets on the Web, and well-publicized successes of large-scale projects such as the Google Knowledge Graph and the Amazon Product Graph. However, another factor that is less discussed, but which has been equally instrumental in the success of KGs, is the cross-disciplinary nature of academic KG research. Arguably, because of the diversity of this research, a synthesis of how different KG research strands all tie together could serve a useful role in enabling more ‘moonshot’ research and large-scale collaborations.
- knowledge graphs
- applications
- natural language processing
- semantic web
- data mining
- knowledge representation
- graph databases
1. Introduction
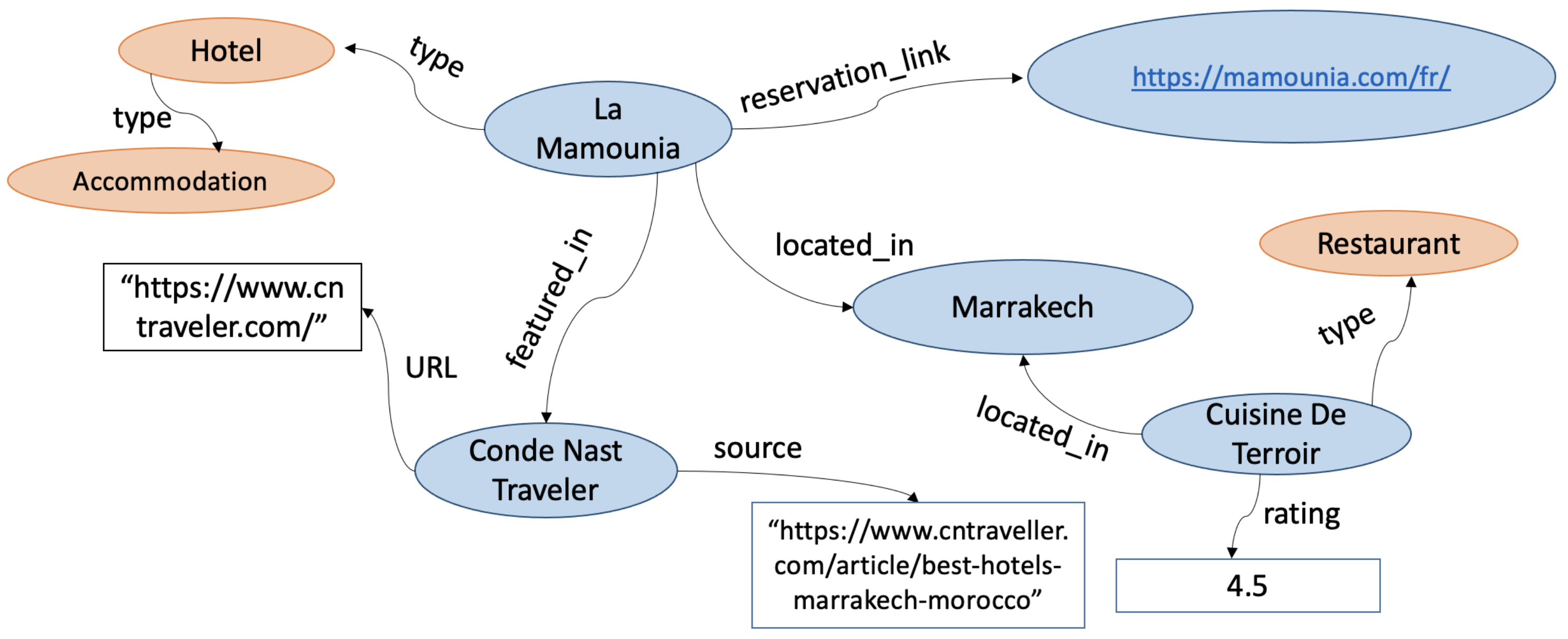
With accelerating growth of the Web over the 2000s, and the rise of both e-commerce and social media, knowledge graphs (KGs) have emerged as important models for representing, storing and querying heterogeneous pieces of data that have some relational structure between them, and that typically have real-world semantics [1]. The semantics are closely associated with the domain for which the KG has been designed [2]. A formal way to define such a domain, favored in the Semantic Web (SW) community, is through an ontology [3]. The most common definition of a KG is that it is a directed graph where both edges and nodes have labels. Nodes are considered to be entities, ranging from everyday entities such as people, organizations and locations to highly domain-specific entities such as proteins and viruses (assuming the domain is a biological one). Edges, also known as properties or predicates, represent either relations between entities (e.g., an ‘employed_at’ relation between a person and organization entity) or an attribute of an entity (e.g., a person’s date of birth), typically represented as a literal. Edges and nodes may also be used to represent an entity’s attribute (e.g., the ‘date_of_birth’ of a person entity) and the attribute’s value (e.g., ‘1970-01-01’), respectively. Even definitionally, diversity is observed in KG research. For example, the SW community makes formal distinctions between the two uses of nodes and edges mentioned above, while others, such as NLP, are less formal. (Within SW, nodes representing entities and attribute values are generally referred to as ‘resources’ and ‘literals’, respectively. Similarly, edges representing entity-relations and attributes are, respectively, referred to as ‘object properties’ and ‘datatype properties’.) An illustrative KG fragment from the tourism domain is visualized in Figure 1. The fragment contains both the actual KG fragment (called the A-Box) and the concepts (nodes shaded in orange) that are part of the T-Box or ontology that models the domain of interest. Put differently, concepts are the types or classes of entities allowable in the domain. Another important aspect of the domain is the set of allowable edge-labels (called properties or predicates) and the constraints associated with them. For example, the ‘employed_at’ relation can be constrained to only map from an entity of type ‘Person’ to an entity of type ‘Organization’. Formally, ‘Person’ and ‘Organization’ would be declared as the allowable domain and range of the predicate ‘employed_at’, similar to a functional constraint in mathematics. The ontology can also have other axioms and constraints. (An intuitive example is a cardinality constraint, e.g., the requirement can be imposed that a ‘married_to’ predicate can be linked to at most one entity-object.) A special predicate called rdf:type serves as an explicit bridge between the A-Box and the T-Box by declaring an entity’s type (which, by definition, is in the T-Box).