Machine learning (ML), an area of artificial intelligence (AI), enables researchers, physicians, and patients to solve some of these issues. Many researchers and practitioners illustrate the promise of machine-learning-based disease diagnosis (MLBDD), which is inexpensive and time-efficient. Traditional diagnosis processes are costly, time-consuming, and often require human intervention. While the individual’s ability restricts traditional diagnosis techniques, ML-based systems have no such limitations, and machines do not get exhausted as humans do. As a result, a method to diagnose disease with outnumbered patients’ unexpected presence in health care may be developed. To create MLBDD systems, health care data such as images (i.e., X-ray, MRI) and tabular data (i.e., patients’ conditions, age, and gender) are employed.
- artificial neural networks
- convolutional neural networks
- COVID-19
- deep learning
1. Basics and Background
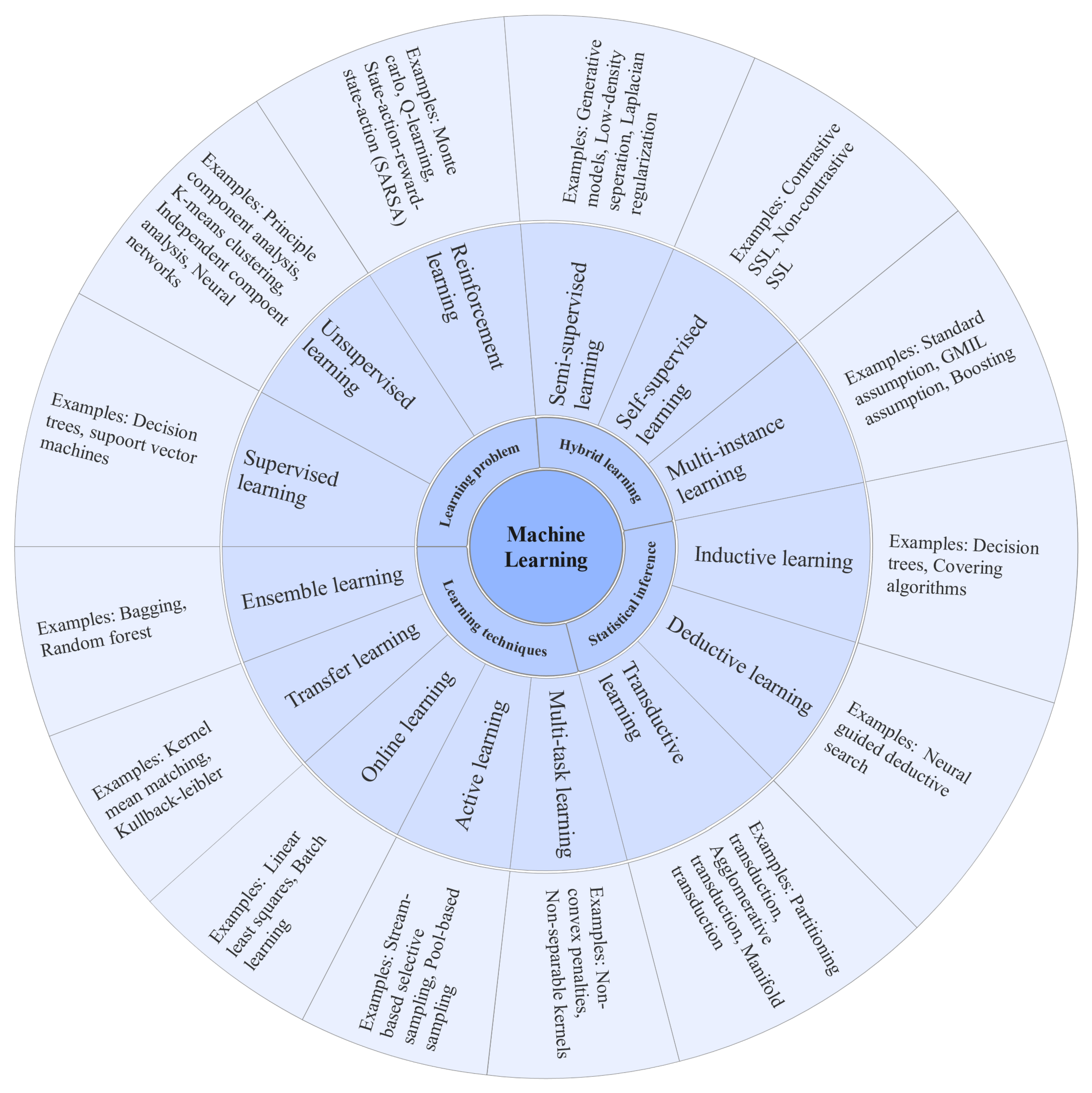
2. Machine Learning Techniques for Different Disease Diagnosis
2.1. Heart Disease
2.2. Kidney Disease
2.3. Breast Cancer
2.4. Diabetes
2.5. Parkinson’s Disease
2.6. COVID-19
2.7. Alzheimer’s Disease
2.8. Other Diseases
References
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229.
- Brownlee, J. Machine learning mastery with Python. Mach. Learn. Mastery Pty Ltd. 2016, 527, 100–120.
- Houssein, E.H.; Emam, M.M.; Ali, A.A.; Suganthan, P.N. Deep and machine learning techniques for medical imaging-based breast cancer: A comprehensive review. Expert Syst. Appl. 2021, 167, 114161.
- Ansari, A.Q.; Gupta, N.K. Automated diagnosis of coronary heart disease using neuro-fuzzy integrated system. In Proceedings of the 2011 World Congress on Information and Communication Technologies, Mumbai, India, 11–14 December 2011; pp. 1379–1384.
- Ahsan, M.M.; Mahmud, M.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine Learning algorithms and model performance. Technologies 2021, 9, 52.
- Rubin, J.; Abreu, R.; Ganguli, A.; Nelaturi, S.; Matei, I.; Sricharan, K. Recognizing abnormal heart sounds using deep learning. arXiv 2017, arXiv:1707.04642.
- Miao, J.H.; Miao, K.H. Cardiotocographic diagnosis of fetal health based on multiclass morphologic pattern predictions using deep learning classification. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 1–11.
- Levey, A.S.; Coresh, J. Chronic kidney disease. Lancet 2012, 379, 165–180.
- Charleonnan, A.; Fufaung, T.; Niyomwong, T.; Chokchueypattanakit, W.; Suwannawach, S.; Ninchawee, N. Predictive analytics for chronic kidney disease using machine learning techniques. In Proceedings of the 2016 Management and Innovation Technology International Conference, Bang-Saen, Chonburi, Thailand, 12–14 October 2016; pp. MIT-80–MIT-83.
- Aljaaf, A.J.; Al-Jumeily, D.; Haglan, H.M.; Alloghani, M.; Baker, T.; Hussain, A.J.; Mustafina, J. Early prediction of chronic kidney disease using machine learning supported by predictive analytics. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–9.
- Ma, F.; Sun, T.; Liu, L.; Jing, H. Detection and diagnosis of chronic kidney disease using deep learning-based heterogeneous modified artificial neural network. Future Gener. Comput. Syst. 2020, 111, 17–26.
- Miranda, G.H.B.; Felipe, J.C. Computer-aided diagnosis system based on fuzzy logic for breast cancer categorization. Comput. Biol. Med. 2015, 64, 334–346.
- Zheng, B.; Yoon, S.W.; Lam, S.S. Breast cancer diagnosis based on feature extraction using a hybrid of K-means and support vector machine algorithms. Expert Syst. Appl. 2014, 41, 1476–1482.
- Asri, H.; Mousannif, H.; Al Moatassime, H.; Noel, T. Using machine learning algorithms for breast cancer risk prediction and diagnosis. Procedia Comput. Sci. 2016, 83, 1064–1069.
- Mohammed, S.A.; Darrab, S.; Noaman, S.A.; Saake, G. Analysis of breast cancer detection using different machine learning techniques. In Proceedings of the International Conference on Data Mining and Big Data, Belgrade, Serbia, 14–20 July 2020; Springer: Berlin/Heidelberg, Gemany, 2020; pp. 108–117.
- Assegie, T.A. An optimized K-Nearest Neighbor based breast cancer detection. J. Robot. Control (JRC) 2021, 2, 115–118.
- Bhattacherjee, A.; Roy, S.; Paul, S.; Roy, P.; Kausar, N.; Dey, N. Classification approach for breast cancer detection using back propagation neural network: A study. In Deep Learning and Neural Networks: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 1410–1421.
- Alshayeji, M.H.; Ellethy, H.; Gupta, R. Computer-aided detection of breast cancer on the Wisconsin dataset: An artificial neural networks approach. Biomed. Signal Process. Control 2022, 71, 103141.
- Sultana, Z.; Khan, M.R.; Jahan, N. Early breast cancer detection utilizing artificial neural network. WSEAS Trans. Biol. Biomed. 2021, 18, 32–42.
- Ghosh, P.; Azam, S.; Hasib, K.M.; Karim, A.; Jonkman, M.; Anwar, A. A performance based study on deep learning algorithms in the effective prediction of breast cancer. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Online, 18–22 July 2021; pp. 1–8.
- Naz, H.; Ahuja, S. Deep learning approach for diabetes prediction using PIMA Indian dataset. J. Diabetes Metab. Disord. 2020, 19, 391–403.
- Kandhasamy, J.P.; Balamurali, S. Performance analysis of classifier models to predict diabetes mellitus. Procedia Comput. Sci. 2015, 47, 45–51.
- Yahyaoui, A.; Jamil, A.; Rasheed, J.; Yesiltepe, M. A decision support system for diabetes prediction using machine learning and deep learning techniques. In Proceedings of the 2019 1st International Informatics and Software Engineering Conference (UBMYK), Ankara, Turkey, 6–7 November 2019; pp. 1–4.
- Ashiquzzaman, A.; Tushar, A.K.; Islam, M.; Shon, D.; Im, K.; Park, J.H.; Lim, D.S.; Kim, J. Reduction of overfitting in diabetes prediction using deep learning neural network. arXiv 2017, arXiv:1707.08386.
- Alhassan, Z.; McGough, A.S.; Alshammari, R.; Daghstani, T.; Budgen, D.; Al Moubayed, N. Type-2 diabetes mellitus diagnosis from time series clinical data using deep learning models. In Proceedings of the 2019 International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 468–478.
- Grover, S.; Bhartia, S.; Yadav, A.; Seeja, K.R. Predicting severity of Parkinson’s disease using deep learning. Procedia Comput. Sci. 2018, 132, 1788–1794.
- Sriram, T.V.; Rao, M.V.; Narayana, G.S.; Kaladhar, D.; Vital, T.P.R. Intelligent Parkinson disease prediction using machine learning algorithms. Int. J. Eng. Innov. Technol. (IJEIT) 2013, 3, 1568–1572.
- Esmaeilzadeh, S.; Yang, Y.; Adeli, E. End-to-end Parkinson disease diagnosis using brain mr-images by 3d-cnn. arXiv 2018, arXiv:1806.05233.
- Warjurkar, S.; Ridhorkar, S. A Study on Brain Tumor and Parkinson’s Disease Diagnosis and Detection using Deep Learning. In Proceedings of the 3rd International Conference on Integrated Intelligent Computing Communication & Security (ICIIC 2021), Online, 27–28 August 2021; Atlantis Press: Amsterdam, The Netherlands, 2021; pp. 356–364.
- Ahsan, M.M.; Nazim, R.; Siddique, Z.; Huebner, P. Detection of COVID-19 patients from ct scan and chest X-ray data using modified mobilenetv2 and lime. Healthcare 2021, 9, 1099.
- Haghanifar, A.; Majdabadi, M.M.; Choi, Y.; Deivalakshmi, S.; Ko, S. Covid-cxnet: Detecting COVID-19 in frontal chest X-ray images using deep learning. arXiv 2020, arXiv:2006.13807.
- Tahamtan, A.; Ardebili, A. Real-time RT-PCR in COVID-19 detection: Issues affecting the results. Expert Rev. Mol. Diagn. 2020, 20, 453–454.
- Chen, J.; Wu, L.; Zhang, J.; Zhang, L.; Gong, D.; Zhao, Y.; Chen, Q.; Huang, S.; Yang, M.; Yang, X.; et al. Deep learning-based model for detecting 2019 novel coronavirus pneumonia on high-resolution computed tomography. Sci. Rep. 2020, 10, 19196.
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795.
- Wang, L.; Lin, Z.Q.; Wong, A. Covid-net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest X-ray images. Sci. Rep. 2020, 10, 19549.
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology 2020.
- Hemdan, E.E.D.; Shouman, M.A.; Karar, M.E. Covidx-net: A framework of deep learning classifiers to diagnose COVID-19 in X-ray images. arXiv 2020, arXiv:2003.11055.
- Sethy, P.K.; Behera, S.K. Detection of Coronavirus Disease (COVID-19) Based on Deep Features and Support Vector Machine. 2020. Available online: https://pdfs.semanticscholar.org/9da0/35f1d7372cfe52167ff301bc12d5f415caf1.pdf (accessed on 10 December 2021).
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220.
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays. Comput. Methods Programs Biomed. 2020, 196, 105608.
- Ghoshal, B.; Tucker, A. Estimating uncertainty and interpretability in deep learning for coronavirus (COVID-19) detection. arXiv 2020, arXiv:2003.10769.
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Phys. Eng. Sci. Med. 2020, 43, 635–640.
- Graham, N.; Warner, J. Alzheimer’s Disease and Other Dementias; Family Doctor Publications Limited: Northampton, UK, 2009.
- Neelaveni, J.; Devasana, M.G. Alzheimer disease prediction using machine learning algorithms. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: Manhattan, NY, USA, 2020; pp. 101–104.
- Collij, L.E.; Heeman, F.; Kuijer, J.P.; Ossenkoppele, R.; Benedictus, M.R.; Möller, C.; Verfaillie, S.C.; Sanz-Arigita, E.J.; van Berckel, B.N.; van der Flier, W.M.; et al. Application of machine learning to arterial spin labeling in mild cognitive impairment and Alzheimer disease. Radiology 2016, 281, 865–875.
- Vidushi, A.R.; Shrivastava, A.K. Diagnosis of Alzheimer disease using machine learning approaches. Int. J. Adv. Sci. Technol. 2019, 29, 7062–7073.
- Ahmed, S.; Kim, B.C.; Lee, K.H.; Jung, H.Y.; Initiative, A.D.N. Ensemble of ROI-based convolutional neural network classifiers for staging the Alzheimer disease spectrum from magnetic resonance imaging. PLoS ONE 2020, 15, e0242712.
- Nawaz, H.; Maqsood, M.; Afzal, S.; Aadil, F.; Mehmood, I.; Rho, S. A deep feature-based real-time system for Alzheimer disease stage detection. Multimed. Tools Appl. 2020, 1–19.
- Haft-Javaherian, M.; Fang, L.; Muse, V.; Schaffer, C.B.; Nishimura, N.; Sabuncu, M.R. Deep convolutional neural networks for segmenting 3D in vivo multiphoton images of vasculature in Alzheimer disease mouse models. PLoS ONE 2019, 14, e0213539.
- Aderghal, K.; Benois-Pineau, J.; Afdel, K. Classification of sMRI for Alzheimer’s disease diagnosis with CNN: Single Siamese networks with 2D+? Approach and fusion on ADNI. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 494–498.
- Mao, Y.; He, Y.; Liu, L.; Chen, X. Disease classification based on eye movement features with decision tree and random forest. Front. Neurosci. 2020, 14, 798.
- Nosseir, A.; Shawky, M.A. Automatic classifier for skin disease using k-NN and SVM. In Proceedings of the 2019 8th International Conference on Software and Information Engineering, Cairo, Egypt, 9–12 April 2019; pp. 259–262.
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 565.
- Amin, J.; Sharif, M.; Raza, M.; Yasmin, M. Detection of brain tumor based on features fusion and machine learning. J. Ambient Intell. Human. Comput. 2018, 1–17.
- Dai, X.; Spasić, I.; Meyer, B.; Chapman, S.; Andres, F. Machine learning on mobile: An on-device inference app for skin cancer detection. In Proceedings of the 2019 Fourth International Conference on Fog and Mobile Edge Computing (FMEC), Rome, Italy, 10–13 June 2019; IEEE: Manhattan, NY, USA, 2019; pp. 301–305.
- Daghrir, J.; Tlig, L.; Bouchouicha, M.; Sayadi, M. Melanoma skin cancer detection using deep learning and classical machine learning techniques: A hybrid approach. In Proceedings of the 2020 5th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sfax, Tunisia, 2–5 September 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1–5.