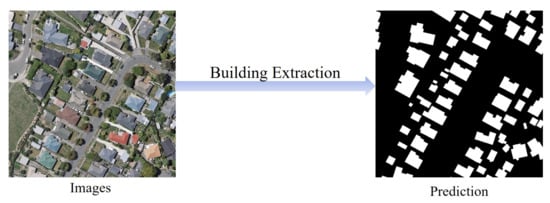
Building extraction from remote sensing (RS) images is a fundamental task for geospatial applications, aiming to obtain morphology, location, and other information about buildings from RS images, which is significant for geographic monitoring and construction of human activity areas. In recent years, deep learning (DL) technology has made remarkable progress and breakthroughs in the field of RS and also become a central and state-of-the-art method for building extraction.
- deep learning
- convolutional neural network
- building extraction
- high resolution
- remote sensing
Deep Learning-Based Building Extraction from Remote Sensing Images: A Comprehensive Review
1. Introduction
-
Building types are in general highly changeable. They differ in interior tones and textures and have a variety of spatial scales. In addition, their shapes and colors may vary from building to building.
-
Buildings generally stand in close proximity to features of similar materials such as roads, and can easily be confused with other elements. The segmentation quality of boundary contours is particularly important.
-
The long-distance association relationship between buildings and surrounding objects is an important concern due to a variety of complex factors that may cause foreground occlusions, such as shadows, artificial non-architectural features, and heterogeneity of building surfaces.
-
RS images have more complex and diverse backgrounds and scenes, and the shapes of buildings are more regular and well-defined than those of natural objects, rendering boundary issues particularly critical.
2. DL Techniques
2.1. Deep CNNs
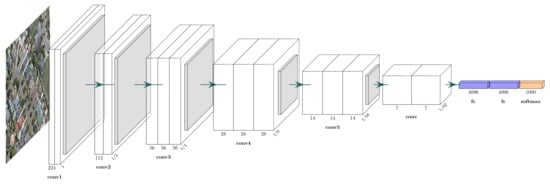
2.1.1. VGG Networks
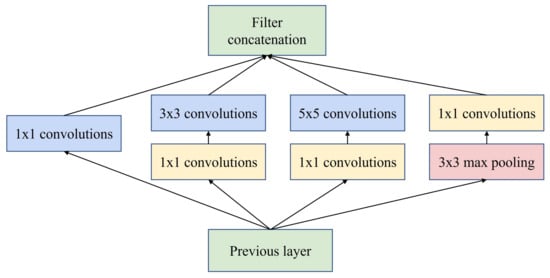
2.1.2. GoogLeNet
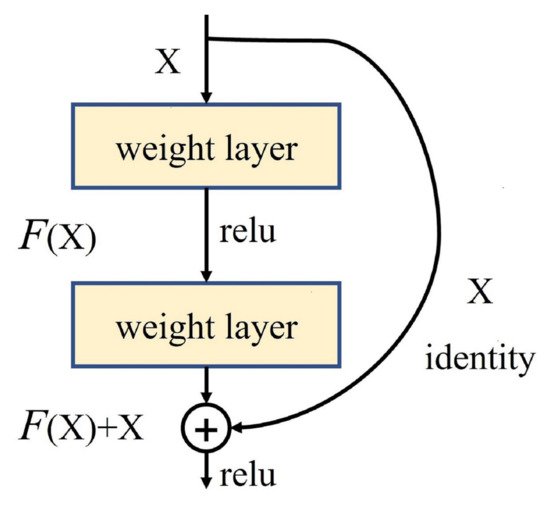
2.1.3. ResNet
Abstract
2.2. Transfer Learning
2.3. Loss Function
Contributions | |||
|---|---|---|---|
|
DeconvNet-Fusion [2] |
** |
** |
Multi-source data post-fusion |
|
FCN [83] |
* |
* |
Early CNNs |
|
ConvNet [84] |
* |
* |
Signed distance |
|
Fused-FCN4s [85] |
** |
** |
Multi-source data post-fusion |
|
SegNet-Dist [86] |
* |
* |
Signed distance |
|
MC-FCN [87] |
* |
** |
Multi-scale architecture |
|
MFRN [88] |
* |
** |
Multi-scale architecture |
|
BR-Net [89] |
** |
** |
Boundary extraction, multiple tasks |
|
GMEDN [90] |
*** |
** |
NB, multi-scale architecture |
|
ENRU-Net [91] |
** |
** |
APNB |
|
PISANet [92] |
** |
** |
Pyramid self-attention module |
|
ELU-FCN-CRFs [93] |
* |
* |
ELU, CRFs |
|
FC-DenseNet-FPCRF [ |
-
Cross entropy loss: Cross entropy loss (CE) is the most commonly used loss function in dense semantic annotation tasks. It can be described as:
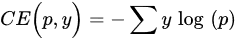
- Weighted Cross Entropy loss: Weighted cross entropy loss (WCE) is obtained by summing over all pixel losses and can not actively cope with application scenarios such as building extraction where the categories are unbalanced. Therefore, WCEs that consider category imbalance, such as median frequency balancing (MFB) [
- 2
-
in East Asia with a ground resolution of 2.7 m. Images of different colors from different sensors and seasons constitute a challenging case for automated building extraction. The vector building map contains 29,085 buildings. The entire image is also seamlessly cropped into 17,388 slices for training and testing, processed in the same way as the aerial dataset. Of these, 21,556 buildings (13,662 tiles) were used for isolated training and the remaining 7529 buildings (3726 tiles) were used for testing. An example is shown in Figure 7.
-
Dice loss: Dice loss is designed for the intersection over union (IoU), an important evaluation metric in semantic segmentation, and is designed to improve the performance of the model by increasing the value of this evaluation metric.
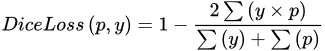
- Focal loss: Focal loss (FL) is improved from CE loss. To address class imbalance, an intuitive idea is to use weighting coefficients to further reduce the loss of the easy classification category. FL can be expressed as:
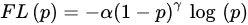
where α is the weighting factor for the classes and γ≥0 is a tunable parameter.
3. Datasets and Evaluation Metrics
3.1. Open Datasets
] | |||
** | |||
** | |||
FPCRFs, GCNs | |||
|
CNN-RNN [94] |
*** |
*** |
Iterative refinement of RNN architecture |
|
EANet [95] |
*** |
*** |
Boundary-aware networks |
|
Networks with BP loss [96] |
** |
** |
BP loss |
|
BRRNet [97] |
*** |
*** |
Residual refinement module |
|
DSFE-GGCN [98] |
** |
*** |
Gated GCN, deep feature embedding |
|
FCN with LFE [99] |
* |
* |
Local feature extraction module |
|
EU-Net [100] |
* |
** |
DSPP, category balanced loss |
|
ScasNet [101] |
*** |
*** |
Multi-scale aggregation |
|
SR-FCN [102] |
* |
** |
Multiscale prediction, ASPP |
|
Building-A-Nets [103] |
** |
*** |
GAN |
|
P-LinkNet [ |
- Massachusetts Buildings Dataset [78]: The datasets, available on the website of Toronto University (https://www.cs.toronto.edu/~vmnih/data/, 15 August 2021), consists of 151 high-resolution aerial images of Boston’s urban and suburban areas. The image size in Massachusetts Buildings Dataset is 1500 × 1500 pixels, and each image covers a widespread area of 2250 × 2250 m2
-
The dataset was randomly divided into three subsets: a training set of 137 images, a validation set of 4 images and a test set of 10 images. It is worth mentioning that these data are restricted to regions where the average missed noise level is about 5% or lower. An example is shown in Figure 5.
-
Inria Aerial Dataset [79]: This dataset, available on https://project.inria.fr/aerialimagelabeling/ (15 August 2021), consists of 360 high-resolution RGB aerial images covering different cities, including Austin, Chicago, Gitza, West/East Tyrol, Vienna, Bellingham, Bloomington, and San Francisco. The areas cover urban buildings with different characteristics. For example, most of the buildings in Chicago and San Francisco are densely distributed and usually smaller in shape, while the buildings in Kitsap are scattered. The images have a spatial resolution of 0.3 m and an image size of 5000 × 5000 pixels, each covering a widespread surface of 1500 × 1500 m2
-
. Only 180 images were provided with public pixel annotation (ground truth), and the remaining 180 images were reserved for testing, where users could submit predicted images and obtain scores on the official website. To test the performance of the segmentation method more easily and quickly, by convention, the first five images of each region from the training set can be selected for validation. It is worth mentioning that all image data are of high quality as they are derived from different aerially captured orthorectified images of the landscape that are officially available locally, ignoring data such as Open Street Maps (OSM). An example is shown in Figure 6.
-
WHU Building Dataset [80]: The whole dataset, available on the website of Photogrammetry and Computer Vision (GPCV) at Wuhan University (http://gpcv.whu.edu.cn/data/, 15 August 2021), contains both aerial image dataset and satellite image dataset. The WHU aerial dataset covers 18,700 buildings of diverse shapes and colors. The entire image and the corresponding vector shapefiles were seamlessly cropped into 8189 patches of 512 × 512 pixels with a ground resolution of 0.3 m. The WHU satellite dataset consists of six adjacent satellite images covering 550 km



3.2. Evaluation Metrics
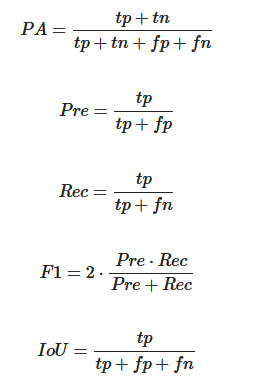
where tp, tn, fp and fn are the number of true positives, true negatives, false positives and false negatives pixels, respectively.
4. Building Extraction Methods Based on DL
DL techniques represented by CNNs have been developed for a long time in the direction of building extraction under the field of RS, whose processing of the input and output can be shown in Figure 8. Various deep neural network architectures for solving building extraction problems have emerged one after another.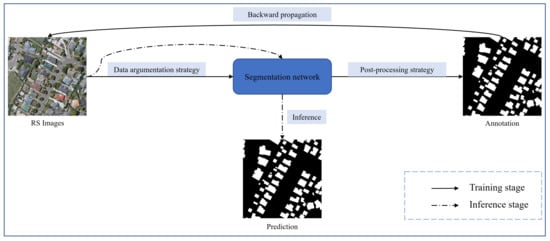
- 1. RS images are usually high-resolution with rich contextual semantic information, while the classical classification network is not sufficient for mining global contextual information.
- 2. CNNs do well in mining local features, but not in modeling long-distance association information. It is difficult for the plain decoder structure to reconstruct the structured hierarchical detail information, such as building boundaries and contours, which is lost due to the decrease of feature map resolution caused by the encoder downsampling.
- 3. The RS images are informative, so the processing of building extraction problem should focus on the model operation efficiency while ensuring the segmentation accuracy.
|
Methods |
Acc. |
Reu. | |
|---|---|---|---|
] | |||
* | |||
** | |||
Multi-scale structure LinkNet | |||
MA-FCN | |||
[ | |||
] | |||
|
* |
** |
Boundary constraints, multiscale prediction |
|
|
GAN-SCA [106] |
** |
*** |
SCA, GAN |
|
HFSA-Unet [107] |
*** |
*** |
Two-stage channel attention |
|
ESFNet [108] |
* |
*** |
Separable factorized residual block |
|
ACR-Net [109] |
** |
*** |
RBAC |
|
SegNet-Dist-Fused [110] |
* |
* |
Signed distance, multi-source data fusion |
|
CFCN [111] |
** |
** |
Boundary constraint networks |
4.1. Baseline Methods
-
The encoders for FCN and SegNet are usually obtained by removing fully connected layers using classification networks such as VGG-16 and ResNet, and the encoder for U-Net is designed to be symmetric with the decoder, allowing the depth of the network to be increased or decreased depending on the complexity of the task.
-
The decoder structure of FCN is the simplest and contains only one deconvolution operation, while U-Net and SegNet adopt multiple upsampling to organize the decoder structure.
-
There is a feature fusion by FCN with feature maps organized by pixel-by-pixel summing, U-Net with feature map stitching, and SegNet with pooling indices generated by pooling operation embedded in the decoder feature map to solve the problem of insufficient recovery information in the upsampling process.
4.2. Contextual Information Mining
4.3. Lightweight Network Design
4.4. Multi-Source Data
References
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust Rooftop Extraction From Visible Band Images Using Higher Order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495.
- Huang, Z.; Cheng, G.; Wang, H.; Li, H.; Shi, L.; Pan, C. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–16 June 2016; pp. 1835–1838.
- Bittner, K.; Cui, S.; Reinartz, P. Building Extraction from Remote Sensing Data Using Fully Convolutional Networks. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Hannover, Germany, 6–9 June 2017; pp. 481–486.
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144.
- Maltezos, E.; Doulamis, A.; Doulamis, N.; Ioannidis, C. Building Extraction From LiDAR Data Applying Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 155–159.
- Sun, G.; Huang, H.; Zhang, A.; Li, F.; Zhao, H.; Fu, H. Fusion of Multiscale Convolutional Neural Networks for Building Extraction in Very High-Resolution Images. Remote Sens. 2019, 11, 227.
- Wu, G.; Guo, Z.; Shao, X.; Shibasaki, R. GEOSEG: A Computer Vision Package for Automatic Building Segmentation and Outline Extraction. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 158–161.
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105.
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic Segmentation-Based Building Footprint Extraction Using Very High-Resolution Satellite Images and Multi-Source GIS Data. Remote Sens. 2019, 11, 403.
- Zhang, Y.; Gong, W.; Sun, J.; Li, W. Web-Net: A Novel Nest Networks with Ultra-Hierarchical Sampling for Building Extraction from Aerial Imageries. Remote Sens. 2019, 11, 1897.
- Davari Majd, R.; Momeni, M.; Moallem, P. Transferable Object-Based Framework Based on Deep Convolutional Neural Networks for Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2627–2635.
- Zhang, Z.; Wang, Y. JointNet: A Common Neural Network for Road and Building Extraction. Remote Sens. 2019, 11, 696.
- Chen, S.; Shi, W.; Zhou, M.; Zhang, M.; Chen, P. Automatic Building Extraction via Adaptive Iterative Segmentation With LiDAR Data and High Spatial Resolution Imagery Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2081–2095.
- Erdem, F.; Avdan, U. Comparison of different U-net models for building extraction from high-resolution aerial imagery. Int. J. Environ. GeoInform. 2020, 7, 221–227.
- Milosavljevi, A. Automated Processing of Remote Sensing Imagery Using Deep Semantic Segmentation: A Building Footprint Extraction Case. ISPRS Int. J. Geo-Inf. 2020, 9, 486.
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241.
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 10–13 December 2015.
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017.
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062.
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848.
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587.
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018.
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460.
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017.
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306.
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890.
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. arXiv 2021, arXiv:2105.05633.
- Ning, F.; Delhomme, D.; LeCun, Y.; Piano, F.; Bottou, L.; Barbano, P. Toward automatic phenotyping of developing embryos from videos. IEEE Trans. Image Process. 2005, 14, 1360–1371.
- Ciresan, D.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. Adv. Neural Inf. Process. Syst. 2012, 25, 2843–2851.
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929.
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 297–312.
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning Rich Features from RGB-D Images for Object Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 345–360.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99.
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 10–13 December 2015; pp. 1395–1403.
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367.
- Feng, T.; Zhao, J. Review and Comparison: Building Extraction Methods Using High-Resolution Images. In Proceedings of the 2009 Second International Symposium on Information Science and Engineering, Shanghai, China, 26–28 December 2009; pp. 419–422.
- Jozdani, S.; Chen, D. On the versatility of popular and recently proposed supervised evaluation metrics for segmentation quality of remotely sensed images: An experimental case study of building extraction. ISPRS J. Photogramm. Remote Sens. 2020, 160, 275–290.
- Bo, Z.; Chao, W.; Hong, Z.; Fan, W. A review on building extraction and Reconstruction from SAR image. Remote Sens. Technol. Appl. 2012, 4.
- Mishra, A.; Pandey, A.; Baghel, A.S. Building detection and extraction techniques: A review. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 May 2016; pp. 3816–3821.
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36.
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40.
- Huang, B.; Reichman, D.; Collins, L.M.; Bradbury, K.; Malof, J.M. Dense labeling of large remote sensing imagery with convolutional neural networks: A simple and faster alternative to stitching output label maps. arXiv 2018, arXiv:1805.12219.
- Clark, R.N.; Roush, T.L. Reflectance spectroscopy: Quantitative analysis techniques for remote sensing applications. J. Geophys. Res. Solid Earth 1984, 89, 6329–6340.
- Zhou, G.; Song, C.; Simmers, J.; Cheng, P. Urban 3D GIS From LiDAR and digital aerial images. Comput. Geosci. 2004, 30, 345–353.
- Tang, J.; Wang, L.; Yao, Z. Analyzing urban sprawl spatial fragmentation using multi-temporal satellite images. Giscience Remote Sens. 2006, 43, 218–232.
- Wu, S.s.; Qiu, X.; Wang, L. Population estimation methods in GIS and remote sensing: A review. Giscience Remote Sens. 2005, 42, 80–96.
- Tian, J.; Cui, S.; Reinartz, P. Building Change Detection Based on Satellite Stereo Imagery and Digital Surface Models. IEEE Trans. Geosci. Remote Sens. 2014, 52, 406–417.
- Montoya-Zegarra, J.A.; Wegner, J.D.; Schindler, K. Semantic segmentation of aerial images in urban areas with class-specific higher-order cliques. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 127–133.
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166.
- Liu, Y.; Li, Z.; Wei, B.; Li, X.; Fu, B. Seismic vulnerability assessment at urban scale using data mining and GIScience technology: Application to Urumqi (China). Geomat. Nat. Hazards Risk 2019, 10, 958–985.
- Li, X.; Li, Z.; Yang, J.; Liu, Y.; Fu, B.; Qi, W.; Fan, X. Spatiotemporal characteristics of earthquake disaster losses in China from 1993 to 2016. Nat. Hazards 2018, 94, 843–865.
- Zhang, B.; Chen, Z.; Peng, D.; Benediktsson, J.A.; Liu, B.; Zou, L.; Li, J.; Plaza, A. Remotely sensed big data: Evolution in model development for information extraction . Proc. IEEE 2019, 107, 2294–2301.
- Liu, Y.; So, E.; Li, Z.; Su, G.; Gross, L.; Li, X.; Qi, W.; Yang, F.; Fu, B.; Yalikun, A.; et al. Scenario-based seismic vulnerability and hazard analyses to help direct disaster risk reduction in rural Weinan, China. Int. J. Disaster Risk Reduct. 2020, 48, 101577.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842.
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 448–456.
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016.
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016.
- Ahmed, A.; Yu, K.; Xu, W.; Gong, Y.; Xing, E. Training Hierarchical Feed-Forward Visual Recognition Models Using Transfer Learning from Pseudo-Tasks. In Proceedings of the Computer Vision—ECCV 2008, Marseille, France, 12–18 October 2008; Forsyth, D., Torr, P., Zisserman, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 69–82.
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and Transferring Mid-Level Image Representations using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014.
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? arXiv 2014, arXiv:1411.1792.
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255.
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252.
- Kaiser, P.; Wegner, J.D.; Lucchi, A.; Jaggi, M.; Hofmann, T.; Schindler, K. Learning Aerial Image Segmentation From Online Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6054–6068.
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Las Vegas, NV, USA, 26 June–1 July 2016.
- Eigen, D.; Fergus, R. Predicting Depth, Surface Normals and Semantic Labels With a Common Multi-Scale Convolutional Architecture. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2016.
- Li, Q.; Shi, Y.; Huang, X.; Zhu, X.X. Building Footprint Generation by Integrating Convolution Neural Network With Feature Pairwise Conditional Random Field (FPCRF). IEEE Trans. Geosci. Remote Sens. 2020, 58, 7502–7519.
- Hosseinpoor, H.; Samadzadegan, F. Convolutional Neural Network for Building Extraction from High-Resolution Remote Sensing Images. In Proceedings of the 2020 International Conference on Machine Vision and Image Processing (MVIP), Qom, Iran, 18–20 February 2020; pp. 1–5.
- Yu, Y.; Ren, Y.; Guan, H.; Li, D.; Yu, C.; Jin, S.; Wang, L. Capsule feature pyramid network for building footprint extraction from high-resolution aerial imagery. IEEE Geosci. Remote Sens. Lett. 2020, 18, 895–899.
- Deng, W.; Shi, Q.; Li, J. Attention-Gate-Based Encoder–Decoder Network for Automatical Building Extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2611–2620.
- Guo, H.; Shi, Q.; Du, B.; Zhang, L.; Wang, D.; Ding, H. Scene-driven multitask parallel attention network for building extraction in high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4287–4306.
- Zhu, Q.; Liao, C.; Hu, H.; Mei, X.; Li, H. MAP-Net: Multiple Attending Path Neural Network for Building Footprint Extraction From Remote Sensed Imagery. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6169–6181.
- Hu, Q.; Zhen, L.; Mao, Y.; Zhou, X.; Zhou, G. Automated building extraction using satellite remote sensing imagery. Autom. Constr. 2021, 123, 103509.
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013.
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Worth, TX, USA, 23–28 June 2017; pp. 3226–3229.
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586.
- Saito, S.; Yamashita, T.; Aoki, Y. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 2016, 1–9.
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149.
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Fully convolutional neural networks for remote sensing image classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–16 June 2016; pp. 5071–5074.
- Yuan, J. Automatic Building Extraction in Aerial Scenes Using Convolutional Networks. arXiv 2016, arXiv:1602.06564.
- Bittner, K.; Adam, F.; Cui, S.; K?rner, M.; Reinartz, P. Building Footprint Extraction From VHR Remote Sensing Images Combined With Normalized DSMs Using Fused Fully Convolutional Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2615–2629.
- Yang, H.L.; Lunga, D.; Yuan, J. Toward country scale building detection with convolutional neural network using aerial images. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Worth, TX, USA, 23–28 June 2017; pp. 870–873.
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic building segmentation of aerial imagery using multi-constraint fully convolutional networks. Remote Sens. 2018, 10, 407.
- Li, L.; Liang, J.; Weng, M.; Zhu, H. A multiple-feature reuse network to extract buildings from remote sensing imagery. Remote Sens. 2018, 10, 1350.
- Wu, G.; Guo, Z.; Shi, X.; Chen, Q.; Xu, Y.; Shibasaki, R.; Shao, X. A boundary regulated network for accurate roof segmentation and outline extraction. Remote Sens. 2018, 10, 1195.
- Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sens. 2020, 12, 2350.
- Wang, S.; Hou, X.; Zhao, X. Automatic Building Extraction From High-Resolution Aerial Imagery via Fully Convolutional Encoder-Decoder Network With Non-Local Block. IEEE Access 2020, 8, 7313–7322.
- Zhou, D.; Wang, G.; He, G.; Long, T.; Yin, R.; Zhang, Z.; Chen, S.; Luo, B. Robust Building Extraction for High Spatial Resolution Remote Sensing Images with Self-Attention Network. Sensors 2020, 20, 7241.
- Shrestha, S.; Vanneschi, L. Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sens. 2018, 10, 1135.
- Maggiori, E.; Charpiat, G.; Tarabalka, Y.; Alliez, P. Recurrent Neural Networks to Correct Satellite Image Classification Maps. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4962–4971.
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-Aware Network for the Extraction of Buildings from Aerial Images. Remote Sens. 2020, 12, 2161.
- Zhang, Y.; Li, W.; Gong, W.; Wang, Z.; Sun, J. An Improved Boundary-Aware Perceptual Loss for Building Extraction from VHR Images. Remote Sens. 2020, 12, 1195.
- Shao, Z.; Tang, P.; Wang, Z.; Saleem, N.; Yam, S.; Sommai, C. BRRNet: A Fully Convolutional Neural Network for Automatic Building Extraction From High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 1050.
- Shi, Y.; Li, Q.; Zhu, X.X. Building segmentation through a gated graph convolutional neural network with deep structured feature embedding. ISPRS J. Photogramm. Remote Sens. 2020, 159, 184–197.
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective Use of Dilated Convolutions for Segmenting Small Object Instances in Remote Sensing Imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450.
- Kang, W.; Xiang, Y.; Wang, F.; You, H. EU-Net: An Efficient Fully Convolutional Network for Building Extraction from Optical Remote Sensing Images. Remote Sens. 2019, 11, 2813.
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95.
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322.
- Li, X.; Yao, X.; Fang, Y. Building-A-Nets: Robust Building Extraction From High-Resolution Remote Sensing Images With Adversarial Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3680–3687.
- Ding, Y.; Wu, M.; Xu, Y.; Duan, S. P-linknet: Linknet with spatial pyramid pooling for high-resolution satellite imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 35–40.
- Wei, S.; Ji, S.; Lu, M. Toward Automatic Building Footprint Delineation From Aerial Images Using CNN and Regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2178–2189.
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building Extraction from High-Resolution Aerial Imagery Using a Generative Adversarial Network with Spatial and Channel Attention Mechanisms. Remote Sens. 2019, 11, 917.
- He, N.; Fang, L.; Plaza, A. Hybrid first and second order attention Unet for building segmentation in remote sensing images. Sci. China Inf. Sci. 2020, 63, 1–12.
- Lin, J.; Jing, W.; Song, H.; Chen, G. ESFNet: Efficient Network for Building Extraction From High-Resolution Aerial Images. IEEE Access 2019, 7, 54285–54294.
- Liu, Y.; Zhou, J.; Qi, W.; Li, X.; Gross, L.; Shao, Q.; Zhao, Z.; Ni, L.; Fan, X.; Li, Z. ARC-Net: An Efficient Network for Building Extraction From High-Resolution Aerial Images. IEEE Access 2020, 8, 154997–155010.
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building Extraction at Scale Using Convolutional Neural Network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614.
- Liu, W.; Yang, M.; Xie, M.; Guo, Z.; Li, E.; Zhang, L.; Pei, T.; Wang, D. Accurate Building Extraction from Fused DSM and UAV Images Using a Chain Fully Convolutional Neural Network. Remote Sens. 2019, 11, 2912.
- Anwar, S.; Hwang, K.; Sung, W. Structured Pruning of Deep Convolutional Neural Networks. ACM J. Emerg. Technol. Comput. Syst. 2015, 13.
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149.
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient transfer learning. arXiv 2016, arXiv:1611.06440.
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147.