Building extraction from remote sensing (RS) images is a fundamental task for geospatial applications, aiming to obtain morphology, location, and other information about buildings from RS images, which is significant for geographic monitoring and construction of human activity areas. In recent years, deep learning (DL) technology has made remarkable progress and breakthroughs in the field of RS and also become a central and state-of-the-art method for building extraction.
1. Introduction
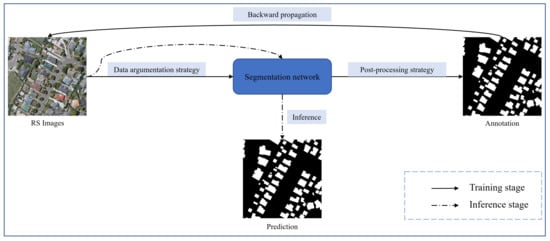
With the rapid development of imaging technology, high-resolution remote sensing (RS) imagery is becoming more and more readily available. Therefore, research within the field of RS has flourished, and automatic building segmentation from high-resolution images has received widespread attention [1][2][3][4][5][6][7][8][9][10][11][12][13][14][15]. The process of extracting buildings from RS images is shown in Figure 1, which is essentially a pixel-level classification of RS images to obtain binary images with contents of building or non-building, and this process can be modeled as a semantic segmentation problem [16][17][18][19][20][21][22][23][24][25][26][27][28][29].
Figure 1. Illustration of extracting buildings from remote sensing images. The white and black pixels in prediction denote buildings and background respectively.
Deep learning (DL), with convolutional neural networks (CNN) [30][31][32][33][34] as its representative, is an automated artificial intelligence technique that has emerged in recent years, specializing in learning general patterns from large amounts of data as well as exploiting the knowledge learned to solve unknown problems. It has been successfully applied and rapidly developed in areas such as image classification [35], target detection [36], boundary detection [37], semantic segmentation [16], and instance segmentation [38] in the field of computer vision. Proving to be a powerful tool for breakthroughs in many fields, DL techniques applied to building extraction in RS have emerged and become the mainstream technical tools. Although there are some reviews on RS image building extraction [39][40][41][42] or DL-based RS image processing [43][44][45], there is still a lack of a research that summarizes the latest results of RS image building extraction based on DL techniques. In this paper, we extensively review the DL-based building extraction from RS images, excluding the extraction of roads and other man-made features, in which the processing inputs include aerial images, satellite images, and other multi-source data such as light detection and ranging (LiDAR) point cloud data and elevation data.
As a fundamental task in the field of RS, automatic building extraction is of great significance in a wide range of application areas such as urban planning, change detection, map services and disaster management [46][47][48][49][50][51][52][53][54][55][56]. It is the basis for accomplishing these applications to have efficient and accurate building information. Building extraction has some unique features and challenges, which mainly include the following:
-
Building types are in general highly changeable. They differ in interior tones and textures and have a variety of spatial scales. In addition, their shapes and colors may vary from building to building.
-
Buildings generally stand in close proximity to features of similar materials such as roads, and can easily be confused with other elements. The segmentation quality of boundary contours is particularly important.
-
The long-distance association relationship between buildings and surrounding objects is an important concern due to a variety of complex factors that may cause foreground occlusions, such as shadows, artificial non-architectural features, and heterogeneity of building surfaces.
-
RS images have more complex and diverse backgrounds and scenes, and the shapes of buildings are more regular and well-defined than those of natural objects, rendering boundary issues particularly critical.
Deep Learning-Based Building Extraction from Remote Sensing Images: A Comprehensive Review
2. DL Techniques
Semantic segmentation, one of the research directions of DL most closely related to building extraction, is not an isolated research area, but a natural step in the process from coarse to refined inference. It is a downstream task of image classification, a fundamental computer vision task, for which image classification models provide feature extractors that extract rich semantic features from different layers. Here, firstly, we recall the classic deep CNNs and design inspirations used as deep semantic segmentation systems, and point out its enlightening role for subsequent segmentation networks. Then, transfer learning, an important means of training DL models, is introduced. Finally, we introduce the loss functions used to train segmentation networks.
2.1. Deep CNNs
As one of the most fundamental tasks in computer vision, the image classification task assigns labels based on the input image and predefined categories. CNN-based image classification methods have matured in recent years and have become an important part of the downstream task of semantic segmentation. Here, we briefly review some classical CNN architectures for image processing, which include VGG, GooLeNet, and ResNet.
2.1.1. VGG Networks
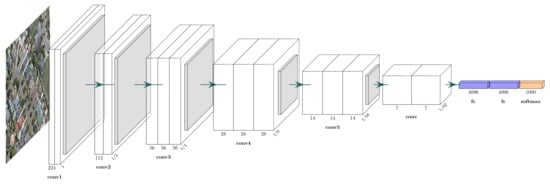
In 2014, Visual Geometry Group (VGG) [57] at the University of Oxford proposed a network with more than 10 layers with concise design principles to build deeper neural network models. The structure of the VGG network is shown in Figure 2, with the main components being a 3 × 3 convolution operation and a 2 × 2 max-pooling operation. The small-sized convolutional layer has a smaller number of parameters and computations than the convolutional layer with large-sized convolutional kernels (e.g., 5 × 5 or 7 × 7 convolution operations in AlexNet [35]) to obtain a similar perceptual field. In addition, a remarkable feature is to increase the number of feature maps after using the pooling layer, reducing the phenomenon of useful information loss in feature maps after downsampling.
Figure 2. VGG network architecture.
VGG network is one of the most influential CNN models because of its reinforcing the important idea in DL that CNNs with deeper architectures can facilitate hierarchical feature representation of visual data. It could be a guide to the structural design of subsequent deep CNN models. Meanwhile, VGG with 16 layers (VGG-16) has become one of the common feature extractors for downstream tasks.
Abstract
2.1.2. GoogLeNet
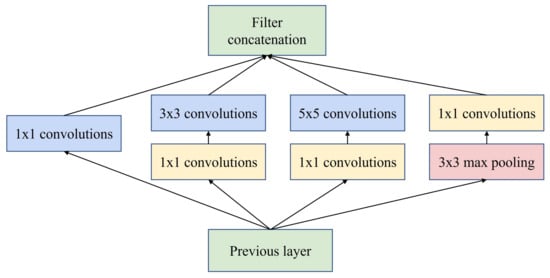
GoogLeNet based on inception modules was proposed by Google in 2014 [58], which won the ImageNet competition that year. It has been improved several times in the following years, leading to InceptionV2 [59], InceptionV3 [60] and InceptionV4 [61]. The structure of the inception module is shown in Figure 3, presenting a net-in-network (NIN) architecture. The same network layer including large-size convolution, small-size convolution and pooling operations can capture feature information separately in a parallel manner. In addition, inception modules control the number of channels with 1×1
convolution and enhance the network representation by fusing information from different sensory domains or scales. Due to these modules, the number of parameters and operations is greatly reduced, while the network advances in terms of storage footprint and time consumption. The idea of inception provides a new way of stacking networks for CNN architecture design, rather than just sequential stacking, as well as it can be designed to be much wider. For the same number of parameters, inception-based networks are wider and more expressive, providing a fundamental direction for lightweight design of deep neural networks.
Figure 3. Inception module with dimensionality reduction from the GoogLeNet architecture.
2.1.3. ResNet
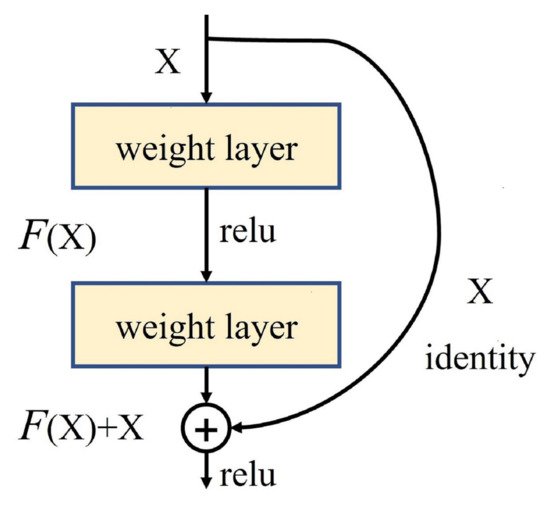
Presented in 2015, ResNet [62] is a landmark research result that pushed neural networks to deeper layers. 152-layer ResNet ranked in the top five at ILSVRC 2015 with an error rate of 3.6% and achieved a new record with respect to classification, detection, and localization in a single network architecture. Through experiments and analysis of several deep CNN models, it was found that deep networks experience network degradation during layer deepening and could not necessarily perform better than shallow networks. In response, a deep residual structure was proposed as shown in Figure 4, allowing the network to shift to learning of residuals. The residual network learns new information different from what was previously available, relieving the pressure on the deep network to learn feature representations and update parameters. It allows the DL model to move once again in a deeper and better direction.
Figure 4. Residual block from the ResNet architecture.
2.2. Transfer Learning
Training a deep neural network from scratch is often difficult for two reasons. On the one hand, training a deep network from scratch requires enough dataset, and the dataset of the target task is not large enough. On the other hand, it takes a long time for the network to reach convergence. Even if a sufficiently large dataset is obtained and the network can reach convergence in a short time, it is much better to start the training process with weights from previous training results than with randomly initialized weights [63][64]. Yosinski et al. [65] demonstrated that even features learned by migration from less relevant tasks are better than those learned directly from random initialization. It also takes into account that the transferability will decrease as the difference between the source task and the target task increases.
However, the application of transfer learning techniques is not so straightforward. The use of pre-trained networks must satisfy the network architecture constraint of using existing network architectures or network components for transfer learning. Then, the training process itself in transfer learning is very small compared to the training process from scratch, so it can pave the way for fast convergence of downstream tasks. An important practice in transfer learning is to continue the training process from a previously trained network to fine-tune the weight values of the model. It is important to choose the layers for fine-tuning wisely, generally choosing the higher layers in the network, as the underlying layers generally tend to retain more general features.
ImageNet [66][67] is a large image classification dataset in the field of computer vision and is often used to train the feature extraction network part of segmentation networks. VGG-16 and ResNet pre-trained by ImageNet are easily available to be used as the encoder part of the segmentation network as well. In addition, a large collection of RS image segmentation data has also been collected and merged into a large dataset and used to pre-train the segmentation network [68].
2.3. Loss Function
Deep neural network models are trained with the loss-gradient back-propagation algorithm, so that the design of the loss function is also directly related to the efficiency of the network training and the performance of the model on the target task. Then the rest of this section describes several commonly used loss functions in building segmentation networks. To facilitate the expression of the computational process, y and p denote the ground truth label and prediction result, respectively.
|
| Contributions |
|
|---|
|
DeconvNet-Fusion [2]
|
**
|
**
|
Multi-source data post-fusion
|
|
FCN [83]
|
*
|
*
|
Early CNNs
|
|
ConvNet [84]
|
*
|
*
|
Signed distance
|
|
Fused-FCN4s [85]
|
**
|
**
|
Multi-source data post-fusion
|
|
SegNet-Dist [86]
|
*
|
*
|
Signed distance
|
|
MC-FCN [87]
|
*
|
**
|
Multi-scale architecture
|
|
MFRN [88]
|
*
|
**
|
Multi-scale architecture
|
|
BR-Net [89]
|
**
|
**
|
Boundary extraction, multiple tasks
|
|
GMEDN [90]
|
***
|
**
|
NB, multi-scale architecture
|
|
ENRU-Net [91]
|
**
|
**
|
APNB
|
|
PISANet [92]
|
**
|
**
|
Pyramid self-attention module
|
|
ELU-FCN-CRFs [93]
|
*
|
*
|
ELU, CRFs
|
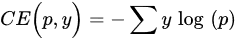
- Weighted Cross Entropy loss: Weighted cross entropy loss (WCE) is obtained by summing over all pixel losses and can not actively cope with application scenarios such as building extraction where the categories are unbalanced. Therefore, WCEs that consider category imbalance, such as median frequency balancing (MFB) [69][70] CEs, have emerged.
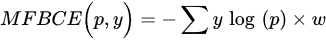
where w is the category balance weight in median form, expressed by the ratio of the median of the pixel frequencies of all the categories to the pixel frequencies of that category.
-
Dice loss: Dice loss is designed for the intersection over union (IoU), an important evaluation metric in semantic segmentation, and is designed to improve the performance of the model by increasing the value of this evaluation metric.
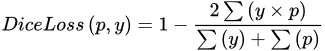
- Focal loss: Focal loss (FL) is improved from CE loss. To address class imbalance, an intuitive idea is to use weighting coefficients to further reduce the loss of the easy classification category. FL can be expressed as:
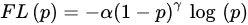
where α is the weighting factor for the classes and γ≥0 is a tunable parameter.
3. Datasets and Evaluation Metrics
In the case of DL, data is an extremely important component, specially with the deepening of the network and the increasing number of parameters. The establishment of each new building extraction method for basic DL requires the validation of a dataset.
3.1. Open Datasets
The data sources used to validate the building extraction methods are numerous including datasets compiled by several research institutions and data obtained by literature authors from publicly available websites (e.g., Google Earth, OpenStreetMap, and United States Geological Survey [71][72][73][74][75][76][77]). The former is of higher quality, while the latter is relatively more confusing and less generalized.
|
|
FC-DenseNet-FPCRF |
[ |
71 |
] |
|
|
|
|
** |
|
|
|
| **
|
FPCRFs, GCNs
|
|
CNN-RNN [94]
|
***
|
***
|
Iterative refinement of RNN architecture
|
|
EANet [95]
|
***
|
***
|
Boundary-aware networks
|
|
Networks with BP loss [96]
|
**
|
**
|
BP loss
|
|
BRRNet [97] |
-
in East Asia with a ground resolution of 2.7 m. Images of different colors from different sensors and seasons constitute a challenging case for automated building extraction. The vector building map contains 29,085 buildings. The entire image is also seamlessly cropped into 17,388 slices for training and testing, processed in the same way as the aerial dataset. Of these, 21,556 buildings (13,662 tiles) were used for isolated training and the remaining 7529 buildings (3726 tiles) were used for testing. An example is shown in Figure 7.
|
|
|
|
*** |
|
|
|
|
*** |
|
|
|
|
Residual refinement module |
|
|
|
|
DSFE-GGCN |
[98]
|
**
|
***
|
Gated GCN, deep feature embedding
|
|
FCN with LFE [99]
|
*
|
*
|
Local feature extraction module
|
|
EU-Net [100]
|
*
|
**
|
DSPP, category balanced loss
|
|
ScasNet [101]
|
***
|
***
|
Multi-scale aggregation
|
|
SR-FCN [102]
|
*
|
**
|
Multiscale prediction, ASPP
|
|
Building-A-Nets [103]
|
**
|
***
|
GAN
|
|
P-LinkNet [104]
|
Massachusetts Buildings Dataset [78]: The datasets, available on the website of Toronto University (https://www.cs.toronto.edu/~vmnih/data/, 15 August 2021), consists of 151 high-resolution aerial images of Boston’s urban and suburban areas. The image size in Massachusetts Buildings Dataset is 1500 × 1500 pixels, and each image covers a widespread area of 2250 × 2250 m2
-
The dataset was randomly divided into three subsets: a training set of 137 images, a validation set of 4 images and a test set of 10 images. It is worth mentioning that these data are restricted to regions where the average missed noise level is about 5% or lower. An example is shown in Figure 5.
-
Inria Aerial Dataset [79]: This dataset, available on https://project.inria.fr/aerialimagelabeling/ (15 August 2021), consists of 360 high-resolution RGB aerial images covering different cities, including Austin, Chicago, Gitza, West/East Tyrol, Vienna, Bellingham, Bloomington, and San Francisco. The areas cover urban buildings with different characteristics. For example, most of the buildings in Chicago and San Francisco are densely distributed and usually smaller in shape, while the buildings in Kitsap are scattered. The images have a spatial resolution of 0.3 m and an image size of 5000 × 5000 pixels, each covering a widespread surface of 1500 × 1500 m2
-
. Only 180 images were provided with public pixel annotation (ground truth), and the remaining 180 images were reserved for testing, where users could submit predicted images and obtain scores on the official website. To test the performance of the segmentation method more easily and quickly, by convention, the first five images of each region from the training set can be selected for validation. It is worth mentioning that all image data are of high quality as they are derived from different aerially captured orthorectified images of the landscape that are officially available locally, ignoring data such as Open Street Maps (OSM). An example is shown in Figure 6.
-
WHU Building Dataset [80]: The whole dataset, available on the website of Photogrammetry and Computer Vision (GPCV) at Wuhan University (http://gpcv.whu.edu.cn/data/, 15 August 2021), contains both aerial image dataset and satellite image dataset. The WHU aerial dataset covers 18,700 buildings of diverse shapes and colors. The entire image and the corresponding vector shapefiles were seamlessly cropped into 8189 patches of 512 × 512 pixels with a ground resolution of 0.3 m. The WHU satellite dataset consists of six adjacent satellite images covering 550 km
Figure 5. An example of the Massachusetts Building Dataset. (a) Original image; (b) Ground truth label.
Figure 6. An example of the Inria dataset. (a) Original image; (b) Ground truth label.
Figure 7. An example of the WHU dataset. (a) Original image; (b) Ground truth label.
3.2. Evaluation Metrics
In order to evaluate the performance of segmentation methods, it is usually necessary to select some quantitative evaluation metrics to evaluate the accuracy of different methods. Here, we introduce the commonly used evaluation metrics, including pixel accuracy (PA), precision (Pre), recall (Rec), F1 score (F1), and IoU. In the building extraction task, the building is the positive case and the background category is the negative case. These four metrics are defined as:
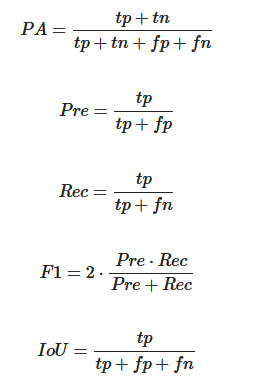
where tp, tn, fp and fn are the number of true positives, true negatives, false positives and false negatives pixels, respectively.
4. Building Extraction Methods Based on DL
DL techniques represented by CNNs have been developed for a long time in the direction of building extraction under the field of RS, whose processing of the input and output can be shown in Figure 8. Various deep neural network architectures for solving building extraction problems have emerged one after another.
Figure 8. Processing of input and output on DL-based building extraction study. The dataset is partially enhanced to supply the model for back-propagation training until a certain termination condition is reached, such as iteration time and number of iterations. After that, the model can enter the application phase, where inference on unseen data produces predictions that match the requirements.
Patch-based annotation networks [81][82] are the key process of the adoption of DL into the building segmentation problem, with the main advantage of helping researchers to free themselves from complex manual feature design and perform automated building extraction for high- and even ultra-high-resolution RS images. The patch-based approach is essentially an image classification network that assigns a specified label to each patch, where the last layer of the network is usually a fully connected layer. The method cuts the image into a number of sub-images much smaller than the original size, i.e. patches, after which a CNN is applied to process the individual patches and give a single classification for each one, and finally stitch them together to form a complete image. The patch-level annotation method does not require high capacity of the network, and the network is usually uncomplicated in structure and easy to design. Saito et al. [81] designed a simple neural network containing three convolutional layers and two fully connected layers to accomplish automatic extraction of buildings, in which the feasibility and effectiveness of the method was confirmed by experiments. However, the patch-based classification method has two inherent defects that can not be avoided. On the one hand, the features of neighboring patches are similar and the proportion of overlapping regions is extremely large. Thus, there is a large amount of redundant computation, resulting in wasted resources and low efficiency. On the other hand, there is a lack of long-distance information exchange. As a result, the method can not fully exploit the contextual information in high-resolution RS images, with difficulty in completely and accurately extracting buildings from complex backgrounds.
Fully convolutional network (FCN) [16] is a landmark pixel-based segmentation method proposed to provide new inspiration for applying CNNs to advance building extraction research. The core idea is to use existing CNNs as encoders to generate hierarchical features and use upsampling means such as deconvolution as decoders to reconstruct images and generate the semantic labels, eliminating the fully connected layer exclusively. A classical encoder-decoder structure is formed, which can theoretically accept images of different sizes as network inputs and output semantically labeled images at pixel level with the same resolution. There exists a common point in current segmentation networks, i.e., feature extraction is performed by the encoder in the process of performing multi-stage downsampling, and the decoder gradually recovers the size and structure of the image in the process of upsampling and generates semantic annotations. Based on this starting point consideration, a popular approach is to use the image classification network with the fully connected layer removed directly as a feature extraction network, i.e., encoder, such as VGG-16, GoogLeNet and ResNet; the decoder part is composed of upsampling modules such as deconvolution, which eventually generates dense pixel-level labels.
However, in spite of a robust approach, there are limitations in the classical FCN model for building extraction from RS images:
- 1. RS images are usually high-resolution with rich contextual semantic information, while the classical classification network is not sufficient for mining global contextual information.
- 2. CNNs do well in mining local features, but not in modeling long-distance association information. It is difficult for the plain decoder structure to reconstruct the structured hierarchical detail information, such as building boundaries and contours, which is lost due to the decrease of feature map resolution caused by the encoder downsampling.
- 3. The RS images are informative, so the processing of building extraction problem should focus on the model operation efficiency while ensuring the segmentation accuracy.
Table 1 shows the main methods involved here, containing the architectures involved in the methods, their main contributions, and a hierarchy based on their task objectives: accuracy (ACC) and reusability (Reu) of the model structure. Specifically, Reu indicates whether the advanced network modules proposed in the literature can be reused relatively easily by other partitioned networks or studies. Each objective is divided into three grades, depending on the degree of focus of the corresponding work on that objective. From the perspective of accuracy, aggregating multi-scale contextual information, considering boundary information, iterative refinement and adopting appropriate post-processing strategies are aspects to be considered. Network components with good reusability are usually robust while not producing large changes in the size of the input and output feature maps, such as attention modules. Moreover, they are usually designed with the objective of aggregating certain elements that are useful for accomplishing the target task.
Table 1. Deep learning-based methods on building extraction.
|
Methods
|
Acc.
|
Reu.
|
|
|
* |
|
|
|
|
** |
|
|
|
|
Multi-scale structure LinkNet |
|
|
|
|
MA-FCN |
[ |
105 |
] |
|
|
|
|
* |
|
|
**
|
Boundary constraints, multiscale prediction
|
|
GAN-SCA [106]
|
**
|
***
|
SCA, GAN
|
|
HFSA-Unet [107]
|
***
|
***
|
Two-stage channel attention
|
|
ESFNet [108]
|
*
|
***
|
Separable factorized residual block
|
|
ACR-Net [109]
|
**
|
***
|
RBAC
|
|
SegNet-Dist-Fused [110]
|
*
|
*
|
Signed distance, multi-source data fusion
|
|
CFCN [111]
|
**
|
**
|
Boundary constraint networks
|
4.1. Baseline Methods
FCN, SegNet, and U-Net all employ an encoder-decoder architecture, but offer different aspects of design mindsets that are reflected in the encoder, upsampling, and skip connection, respectively.
-
The encoders for FCN and SegNet are usually obtained by removing fully connected layers using classification networks such as VGG-16 and ResNet, and the encoder for U-Net is designed to be symmetric with the decoder, allowing the depth of the network to be increased or decreased depending on the complexity of the task.
-
The decoder structure of FCN is the simplest and contains only one deconvolution operation, while U-Net and SegNet adopt multiple upsampling to organize the decoder structure.
-
There is a feature fusion by FCN with feature maps organized by pixel-by-pixel summing, U-Net with feature map stitching, and SegNet with pooling indices generated by pooling operation embedded in the decoder feature map to solve the problem of insufficient recovery information in the upsampling process.
These three types of basic methods have been applied to the building extraction problem since a few years ago [3][83][84][86][87][88][89], which have recently been used mainly as a baseline to motivate new methods and to compare their effectiveness.
4.2. Contextual Information Mining
The key points of building extraction are mining local information (short-distance contextual information around pixels such as building outline and boundary) and global information (long-distance contextual information between buildings and background and overall association relationship between buildings and buildings with other pixels in the image). Rich local information helps to improve the accuracy of pixel-level annotation, while complete global information is also essential to resolve local blur. It is the concern of all DL-based building extraction methods to balance and fuse these two aspects.
4.3. Lightweight Network Design
Building extraction is usually performed in high-resolution images so that the design of segmentation networks has to take into account the consumption of computational resources such as GPU memory and the inference speed of the prediction phase. However, most existing methods usually require a large number of parameters and floating-point operations to obtain high accuracy, which leads to high computational resource consumption and low inference speed.
In order to achieve a better balance between accuracy and efficiency, a common approach is to apply an existing lightweight network or adopt a more efficient convolutional module to develop a lightweight network as a feature extraction network [112][113][114]. Lin et al. [108] and Liu et al. [109] developed new feature extraction backbone networks with deep separable convolutional asymmetric convolution respectively, incorporating decoder networks to achieve segmentation results with accuracy no less than mainstream networks such as U-Net, SegNet, and earlier lightweight networks such as ENet [115], with significantly lower number of parameters and computational effort.
4.4. Multi-Source Data
Extracting buildings from RGB images is currently the most widely used method. However, DSM elevation data and LiDAR data are widely used as auxiliary data to correct the angle of the building and pinpoint the location of the building to improve the accuracy of building segmentation. In other words, RGB data provides extensive background color information and building shape information, while DSM elevation data and LIDAR data provide accurate relative position information and three-dimensional spatial information. The fusion of RGB images with data from other sources exists in two main stages, the pre-processing stage before input to the network and the post-processing stage of the network.
Data fusion in the previous stage typically involves attaching multi-source data such as DSM as an additional channel to RGB images to form multi-channel data [110][111]. However, the approach of direct fusion of data ignores the variability of different data sources. Huang et al. [2] utilizes independent FCNs to provide segmentation results based on data from different data sources and performs feature fusion at the final layer with confidence votes to obtain the results. Bittner et al. [85] employs multiple mutually independent encoder networks for feature extraction from multiple sources of data separately, and the segmentation results are derived with a decoder after fusing the features.
Building extraction from remote sensing (RS) images is a fundamental task for geospatial applications, aiming to obtain morphology, location, and other information about buildings from RS images, which is significant for geographic monitoring and construction of human activity areas. In recent years, deep learning (DL) technology has made remarkable progress and breakthroughs in the field of RS and also become a central and state-of-the-art method for building extraction. This paper provides an overview over the developed DL-based building extraction methods from RS images. Firstly, we describe the DL technologies of this field as well as the loss function over semantic segmentation. Next, a description of important publicly available datasets and evaluation metrics directly related to the problem follows. Then, the main DL methods are reviewed, highlighting contributions and significance in the field. After that, comparative results on several publicly available datasets are given for the described methods, following up with a discussion. Finally, we point out a set of promising future works and draw our conclusions about building extraction based on DL techniques.