Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Prashant Kaushik and Version 2 by Lily Guo.
Along with essential nutrients and trace elements, vegetables provide raw materials for the food processing industry. Despite this, plant diseases and unfavorable weather patterns continue to threaten the delicate balance between vegetable production and consumption. It is critical to utilize machine learning (ML) in this setting because it provides context for decision-making related to breeding goals.
- machine learning
- vegetables
- models
1. ML Models
ML approaches are powerful tools that can solve complex nonlinear problems on their own using sensor data and this allows for more informed decision-making and actions to be taken in practical scenarios with nominal human intervention. ML techniques are constantly evolving and are used in almost every domain. Their applications, however, have some fundamental restrictions. Data quality, model representation, and input-target variable correlations all have an impact on prediction accuracy. Models used for machine learning tasks are divided into three main types, as shown in Figure 12.
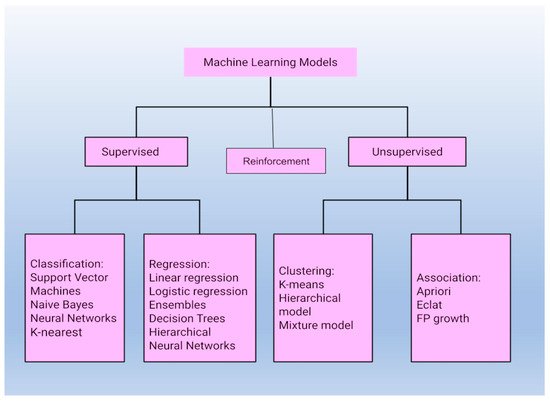
Figure 12.
Classification of models used for machine learning tasks into three major categories.
Regression algorithms, a class of supervised ML technique, generally constitute linear and logistic regression models. Linear regression models primarily represent a linear correlation between independent and dependent variables [1][35], producing a straight line graph. Logistic regression, on the other hand, produces a non-linear curve with output values lying in between 0 and 1. Furthermore, complex regression models have also been created, such as ordinary least squares, multiple linear regression, locally linearized splines, and cubist regression [2][36].
Another ML approach, artificial neural network (ANN), is a type of information processing system that works in a similar way to biological neural networks. This method is used to recognize non-linear and complex functions. In fact, the use of ANN supervised learning techniques can help with both regression and classification problems [3][37]. Further, deep ANNs, also known as deep neural networks (DNNs) or deep learning (DL), allow computational models with multiple processing layers to learn complex data [4][38]. A popular DL model is the convolutional neural network (CNN), which extracts feature maps by carrying out convolutions in the image domain.
Support vector machines (SVMs) are also regularly used for vegetable crops [5][39]. SVM is essentially a binary classifier that creates a linear separating hyperplane to classify data instances. SVM regression algorithms are generally used to predict a continuous response, finding a model that deviates from the calculated data by small amounts; rather than using a hyperplane to separate data, it uses parametric models to detect minor differences [6][40]. Data with a huge number of predictors fit good with it. Yield and sensor data forecasting are two possible supervised learning applications in agriculture [7][41].
Bayesian models (BM), a type of probabilistic graphical models in which Bayesian inference is used to initiate the analysis, also constitute a major class of supervised ML models [8][42]. Bayesian inference, unlike most ML algorithms, requires only a small number of training samples [9][43]. The Bayes’ Theorem, which serves as the foundation for BM, is represented by the equation: P(A|B) = P(B|A) [P(A)/P(B)] [8][42]. This equation is used to compute the posterior probability (P(A|B)) based on the prior probability (P(A)) and the information gathered from the data. P(B|A) denotes the likelihood of the observation B.
Further, Decision trees (DT) have also found their applications in data analysis for vegetable crops. DTs are used to organize the dataset into smaller homogeneous subsets (sub-populations) while simultaneously creating a linked tree graph [10][44]. However, the model can be modified to make it simpler by eliminating branches. DT is ideal for applications that don’t require high predictive accuracy. When compared to other ML methods, simple regression trees do not perform satisfactorily. However, out of the different tree-based approaches, random forests (RFs) have been recognized as the most effective and widespread ML approach [11][45].
Another ML algorithm that needs to be mentioned is ensemble learning (EL). By constructing a linear aggregate of a “base learning algorithm,” EL models aim to improve any model fitting technique’s predictive performance [12][46]. Further, a common method such as the RF (ensemble or grouping of DTs) algorithm avoids overfitting by lowering the variance in DT [13][47].
2. Tasks Employing ML in Vegetables
2.1. Assessment of Seed Quality
Seed quality is a crucial factor in vegetable production because it affects the yield directly [14][15][16][48,49,50]. For example, calculating the germination percentage often necessitates professional technicians manually counting and grading germinating seedlings [17][18][51,52]. Further, seed sowing quality is determined by seed composition, kernel maturity, insect infestation, diseases, cleanliness, and germination ability, and is linked to post-sowing germination and growth conditions. Plant genetic purity can be determined using molecular recognition, DNA analysis, isotope fingerprinting, and mineral element analysis [19][20][53,54]. In addition, in order to determine the seed vigour and germination, several techniques such as high-performance liquid chromatography, tetrazolium tests, and conductivity tests are used [21][22][55,56]. Although the majority of these chemical and physical techniques have high precision and reliability, they come at a high cost, take a long time, and require a lot of operators.
Plant breeding that uses high-quality seeds reduces the cost of field experiments while increasing the chances of finding a better crop variety. However, these procedures are limited by time, subjectivity, and the destructive nature of seed quality assessment. The present scenario demands quick, reliable, non-destructive, and objective methods for detecting seed quality. It has been observed that variations in the chemical composition and internal anatomical features of seeds are often linked to the loss of viability and vigor, however, these changes are difficult to detect when examined visually [22][23][56,57]. Meanwhile, data on complex seed quality traits have been successfully collected using spectrometry and X-ray imaging techniques [24][58]. The agricultural industry has been transformed significantly by recent advances in ML algorithms, which serve as the foundation for developing models to classify products, particularly seed quality attributes. The application of such ML models for assessment of seed quality before germination can significantly help in increasing vegetable production with desired traits. The development of a machine learning model for assessing seed quality has various steps, as shown in Figure 23.
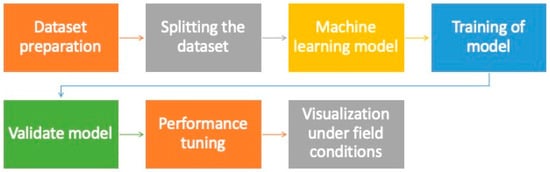
Figure 23.
Step in establishment of a machine learning model for seed quality assessment.
2.2. Disease Detection and Control
The most common pest and disease control method adopted in vegetable production is to spray pesticides evenly across the cropping area [25][26][27][59,60,61]. While this method is relatively effective, it comes at a significant financial and environmental cost. Residues in crop products, groundwater contamination, food chain contamination, and effects on local wildlife and ecosystems are just a few examples of environmental consequences. Plant diseases have long been a major concern in vegetable production due to their ability to reduce crop quality and, subsequently, the production [28][29][30][62,63,64]. They can cause severe damage to entire areas of planted crops, resulting in significant financial loss and a considerable impact on the agricultural economy, especially in developing countries where a single crop or a few crops are the primary sources of income [31][32][65,66].
In order to avoid major losses, various methods for diagnosing disease have been developed. The precise identification of causative agents is now possible thanks to advances in molecular biology and immunology. Many farmers, however, are unable to implement these methods due to the requirement of extensive domain knowledge or a significant amount of money and resources. However, since these farmers bear the responsibility of feeding a large percentage of the world’s population, extensive research has been carried out in order to develop methods that are both accurate and accessible to the vast majority of farmers.
Precision agriculture uses cutting-edge technology to help farmers make better decisions for detection and control of diseases that employ ML to target agrochemical inputs [33][34][67,68]. With the progression of modern digital technologies, a large amount of data is collected in real time, and various ML algorithms are used to make optimal decisions [35][36][12,69]. Further, vegetable production has been impacted by a recent surge in DL methods. Novel solutions may emerge as a result of advances in computer vision and artificial intelligence which are far more effective and accurate than traditional methods at making predictions, thereby allowing for better decision-making. DL methods are now used to solve complex problems related to plant diseases in a reasonable amount of time owing to advancements in hardware technology [37][38][9,70]. Examples of ML applications in the diagnosis, prevention, and control of disease in vegetable crops are provided in Table 1. However, there is still room for improvement in this area, particularly in decision-support systems that aid in the conversion of large amounts of data into actionable recommendations.
| Application | ML Tool | ||
|---|---|---|---|
| Estimation of | Phytophthora infestans | infection in tomato under field condition. | Neural Network |
| Foliar diseases of sugar beet in glasshouse conditions. | Support Vector Machine | ||
| Detection of | Oidium neolycopersici | infestation in tomato. | Support Vector Machine |
| Bacterial infection in | Cucumis melo | under glasshouse conditions. | Logistic Regression, Support Vector Machine, Neural Network |
| Disease detection in plant species including vegetables. | Convolutional Neural Network | ||
| Gene regulatory network of the pathogenic fungus | Fusarium graminearum | constructed from hundreds of transcriptomic datasets. | Bayesian network inference |
| EffectiveT3: Identification of N-terminal signal peptide. | Naïve Bayes | ||
| DeepT3: Identification of bacterial type III secreted effectors. | Deep Convolutional Neural Network | ||
| T4SEpre: prediction of bacterial type IV secreted proteins. | Support Vector Machine | ||
| Bastion6: prediction of bacterial type VI secreted proteins. | Support Vector Machine | ||
| EffectorP: fungal effector prediction. | Naïve Bayes, Ensemble Learner | ||
| ApoplastP: localization of the effector proteins. | Random Forest | ||
| LOCALIZER: localization of plant proteins | Support Vector Machine |
2.3. Prediction of Climatic Variations
The environment (climate), agricultural operations in vegetable production (sowing, cultivation, and harvesting), and plant genotype all influence crop yield and productivity [40][41][42][72,73,74]. The interactions and relationships (direct and/or indirect) among these factors create a complex situation in which potential plant yield is determined. Year-to-year variations in a genotype’s yield and phenotypic trait are caused by environmental variations and genotype × environment interaction (GEI). Stability analysis, which estimates genotypes’ relative performance across different environments, is a perfect solution to these yearly variations [43][75]. The use of deterministic, biophysical crop models for yield modelling for the purpose of assessing the impact of climate change accounts for a significant portion of the work in this area [44][45][76,77]. On the other hand, statistical models outperform them when it comes to predicting over larger spatial scales. Statistical models have been used in a large body of literature to demonstrate a strong link between extreme heat and poor crop performance because their objectives are primarily focused on outcome prediction rather than inference into the nature of the mechanistic processes generating those outcomes. In an ANN model, plant growth indices could be used as dependent variables while climate variables could be used as independent variables [46][47][78,79].
The linear and nonlinear relationships between variables can then be considered using powerful ANN models. Deep phenotyping combined with AI is a useful tool for figuring out how plants interact with their surroundings [48][49][50][80,81,82]. Further, semiparametric neural networks (SNN) are a novel way to combine DNNs with parametric statistical models [51][83]. When used as a crop yield modelling framework, the SNN outperforms everything else in terms of out-of-sample predictive performance [52][53][84,85]. This, when combined with a number of complementary methods, outperforms both existing parametric approaches and fully nonparametric neural networks in terms of efficiency and, ultimately, performance [54][86].
2.4. Crop Monitoring and Yield Prediction
Vegetable production benefits greatly from ML technology, as it makes it easier to monitor, scan, and analyze crops by providing high-quality images [55][56][87,88]. This is highly useful for assessing crop health and determining crop progress. Farmers, for example, can use the images provided by this technology to determine whether or not their crops are ready to harvest. Farmers can use DL and other ML techniques to assess the state of their soil [57][58][89,90]. DL is also used to determine the best times for planting and harvesting and how water and nutrients must be managed [59][91]. This, of course, enhances farming efficiency, and the return on investment (ROI) from specific crops can be predicted by considering their price and market margin [60][61][92,93]. With high-performance computers becoming more common, ML techniques becoming more popular, and satellite imagery data becoming more widely available, there is a chance to develop fast, accurate, and reliable methods for generating crop yield maps [62][63][94,95].
Since there are various crop growth-related biochemical and biophysical characteristics that must be measured at a fine scale to assist in irrigation, fertilizer, and pesticide application decisions, such as leaf nitrogen concentration (N), leaf area index (LAI), and above-ground biomass (AGB), we must track these aspects carefully [64][96]. Furthermore, high-throughput plant phenotyping creates an urgent need for precision crop monitoring that is both cost-effective and non-destructive [65][66][97,98]. Crop monitoring in vegetable production has traditionally relied on field-based surveying and sampling, as well as laboratory-based analyses; however, these methods are time-consuming, can be destructive, and are not practical for large-scale applications. Alternatively, the biochemical and biophysical traits have been estimated using satellite remote sensing [67][68][99,100]. However, satellite remote sensing applications at fine spatial and temporal scales are limited by insufficient spatial resolution and revisiting frequencies [69][101]. Also, the atmospheric conditions and soil background effects may limit the optical satellite data. Furthermore, the lack of three-dimensional (3D) canopy structural information and asymptotic saturation phenomena inherent in optical spectral data limit its use for crop monitoring, especially in dense and diverse canopies at advanced stages of development [68][69][70][100,101,102]. Recent advances in ML and, in particular, deep learning (DL), have enabled the development of several new analytical tools. In this direction, a recent study predicted the yield of tomatoes employing ML and deep learning techniques under controlled greenhouses and in uncontrolled greenhouses. The authors used recurrent neural networks (RNN) for prediction formulations based on the Long Short-Term Memory (LSTM) neuron model of the deep learning approach. The RNN architecture calculates the parameters in conjunction with previous yield, growth, and stem diameter values and microclimate conditions [71][72][103,104].
2.5. ML and Vegetable Breeding
Understanding a complex trait, such as yield, as a function of genetic, phenotypic, and environmental data is one of the most critical targets of plant science and breeding. ML and other approaches are being used to classify quantitative trait loci (QTLs) [73][105] or genomic regions related to phenotypes. In this sense, genetic associations between traits, which calculate the degree of overlap between genetic signals, are concerned. As well, they can estimate trait values for new genotypes with only marker data genomic prediction (GP). Vegetable breeders regularly use genomic selection approaches, which entails selecting material based on GPs rather than phenotypic values and marker-assisted selection, which necessitates QTL mapping [74][106]. Breeders are particularly interested in the genes that underpin QTLs. A variety of architectures for GP, with the help of DL approaches, have been produced [75][107]. Although some researchers have investigated ML methods for QTL mapping (primarily for pre-screening), their use is constrained because practitioners often need p values or other confidence measures to validate the outcomes.
Random-effects are used to estimate GP and effect sizes simultaneously [76][108]. In contrast to parametric random-effects models, ML has several advantages. First, manually designed features are needed where secondary characteristics, such as picture meaning, are more complicated. Second, ML methods (especially DL) could be more resilient in situations where common assumptions such as Gaussianity are breached, such as for traits calculated on an ordinal scale. Third, when a portion of the genetic variation is non-additive, ML may increase accuracy [77][109]. However, ML falls short of random-effects models for certain characteristics. In general, plant breeding in the private sector still relies heavily on rigorous yield assessment in several environments. With a few variations, phenotypes may be very multidimensional, and there are typically hundreds of genotypes. Any recent developments in ML could help solve this problem. It is a big challenge to predict genotype rating within each new setting based on environmental variables that characterize G × E interactions; random-effects approaches were used to show that this is possible using ML approaches [78][110]. More analysis is required to define the most significant environmental variables and realistic data-driven environmental features. The question of when and how they will evolve GP for the target trait, now that these traits are available, emerges. This is true for a single secondary trait with a high enough heritability and genetic resemblance to the target trait. Several authors have used omics, environmental, or management data to forecast yield in the absence of marker data; see, for example, [79][111]. While such models cannot make genomic choices, they can help policymakers and farmers make more educated decisions. These algorithms propose causal relationships between phenotypes that are more closely related to the results, and they may also incorporate previously defined functional relationships. These approaches’ importance lies in their ability to forecast treatment conditions, such as what will happen if different situations or coping mechanisms are employed, or if a gene is silenced.
2.6. ML and Vegetable Biotechnology
Agrobacterium-mediated gene synthesis is a well-known technique for plant gene transformation and genetic alteration [80][112]. For effective gene transfer, the Agrobacterium strain, the period of inoculation, and select antibiotic concentrations must be fine-tuned [81][113]. Moreover, it was determined that resistance to Agrobacterium-assisted gene transformation is easily observable using ML algorithms [82][114]. Polyploidy is often utilized to increase the productivity and vigor of plants [83][115]. This results in a close correlation between the plant genotype and the antimitotic agent in artificial polyploidy induction [84][116].
Many in vitro-based breeding strategies depend on in vitro regeneration, which has a broad variety of applications in plant breeding [83][115]. Micropropagation (proliferation) and in vitro regeneration have clear effects on both in-situ and ex-situ conservation. In vitro culture is an effective tool for widespread reproduction, germplasm survival, and bioactive compound processing in several endangered uncommon plant species, including medicinal plants [85][117]. A variety of variables influence the fate of cultured cells’ in vitro plant regeneration [86][118]. The mixture and interactions between these variables are responsible for the in vitro plant regeneration process’s multifactorial nature. When other factors are introduced, the scenario becomes incredibly difficult to comprehend. Manipulation of the basal medium has been used as a promotion strategy to enhance in vitro studies’ efficiency [87][119]. The cytokinin/auxin ratio is also essential in in vitro tests. The ANN model correctly estimated the number and length of microshoots. In the ANN’s sensitivity study, the immersion time was deemed to be the most critical element affecting pollution level and explant viability. Further, ANNs are often used to forecast plantlet growth from embryos, calculation of cell culture biomass, simulation of temperature distribution in a culture vessel, identification and calculation of in vitro induced shoot weight, and clustering of in vitro regenerated plantlets [88][120].
2.7. ML and Vegetable Genomics
Understanding the movement of information is vital for the study of vegetable sciences and crop improvement, but how to do so is a mystery. This chasm is being filled by advances in two fields of analysis in particular. Association research between molecular phenotype and terminal phenotype benefits from a shorter recognition rail and includes less information transfer than genome-wide connection studies and transcriptome wide-interaction studies. Interaction imaging was used to identify genetic loci associated with molecular or terminal characteristics in natural plant populations [89][121]. Due to widespread linkage imbalance among the neighboring variants and impeding genetic enhancement of plants by genome editing, variants underlying phenotypic variance are difficult to distinguish. On the other hand, advancements in molecular biology over the last half-century have assisted in the discovery of many molecular pathways that control the flow of data from DNA to RNA and protein, and the assortment of such data is determined by a number of omics methods based on sophisticated sequencing techniques [90][122].
CNNs have at least one convolutional layer, which allows them to derive features from a continuous signal (for example, weather data as a time series, a plant image, or a DNA/RNA sequence). A DNA/RNA sequence of N base pairs can be used to train a CNN, and it can be defined as a one-hot encoded 4 N matrix [91][123]. Even if local motifs exist in separate parts of the input, CNNs can catch them. Convolutional layers often reduce the number of weights that must be learned as compared to fully connected layers. Many CNN uses in plant biology are offered as an interactive tutorial for building a CNN to investigate DNA-binding motifs [50][82]. As a consequence of this operation, recurrent neural networks (RNNs) acquire memory capabilities. When dealing with time series inputs, RNNs may also handle a range of input sizes, which is beneficial. When using ML to solve problems in genomics [92][124], there are a few critical aspects to bear in mind. The model should generalize well, which means it should act consistently between test and training sets. Several variables, such as model complexity, high dimensionality, and so on, can lead to overfitting. Large-scale phenotyping trials are often expensive; estimating genomic variant phenotypes almost always costs more than the amount of plant genotypes [93][125]. Overfitting is often concealed and ignored when confronted with genomics problems.
As a result, it seems plausible to anticipate that selecting causative variations can be performed by combining models that “understand” the information flow from DNA to molecular phenotypes with interaction mapping investigations that connect molecular phenotypes to behavioral traits. Indeed, in human genetics, such a structure has been shown not only to be probable but also successful in revealing variants (including rare alleles) at the root of certain genetic disorders [94][126]. On the other hand, the vegetable community is yet to benefit from this trend entirely. DL models have made significant progress in developing molecular phenotype prediction and we believe that such a device would help identify deleterious and adaptive variants in the genome, which would be essential for potential crop editing-based genetic enhancement.
Any protein’s function is directly linked to its tertiary structure. Secondary composition, transmembrane topology, signal peptides, and enzyme dynamics are some of the protein properties that can be integrated and studied to reveal the tertiary structure. Google’s Alpha Fold recently made news as it used AI to predict a protein’s tertiary structure. On the other hand, DL algorithms have shown promise in a variety of fields [95][127]. Still, their utility in predicting protein–protein interactions (PPI) has been constrained by inadequate coverage and noisy data.