Security is of paramount importance when using edge nodes for data processing since a large attack surface is exposed. User-generated or sensor data that are transferred to edge nodes must be protected for confidentiality and integrity, even if an edge node is attacked
[2]. Data must be protected even when attacks, such as Man-In-The-Middle (MITM), Denial of Service (DoS), eavesdropping, and others (to be discussed later), are underway. Many attacks while performing data analytics have been previously understood in the context of the cloud and are inherited by the edge (for example, Man-In-The-Middle (MITM), Denial of Service (DoS), or eavesdropping). Recent security breaches or incidents in edge computing serve to highlight the severity of security risks in this domain. For example, in 2020, a vulnerability known as “Ripple20” was discovered, affecting millions of IoT devices across various industries, including edge computing devices. This vulnerability allowed attackers to remotely execute malicious code, potentially leading to data breaches or system compromise
[3]. Another notable incident involved the exploitation of a vulnerability in the “Treck” TCP/IP stack, affecting numerous IoT and edge devices. This vulnerability, dubbed “AMNESIA:33,” enabled attackers to execute remote code execution, DoS attacks, and other malicious activities
[4]. These incidents underscore the importance of addressing security vulnerabilities in edge computing environments to mitigate the risk of data breaches, system compromise, and other cyber threats.
2. Background of Edge Data Analytics
Edge data analytics allows preprocessing data for obtaining real-time decisions. The data flow is similar to that on the cloud, with the difference that edge resources process data. The data analytics process will need to consider the following five aspects: (a) data source, (b) content format, (c) data storage, (d) data staging, and (e) data processing
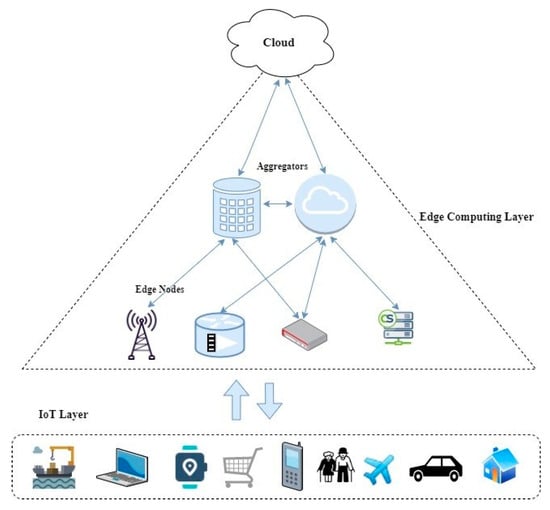
[5][35]. Data processing on edge nodes enables real-time interactions. The flow of data in an edge computing layer sandwiched between the cloud and end-user devices layer (referred to as the Internet of Things (IoT)) is shown in
Figure 1. In edge-based IoT applications, sensing, collecting, and analyzing the data depend on the types of services they provide.
Figure 1.
Flow of data in the edge computing layer.
A data processing model has been proposed for edge computing systems
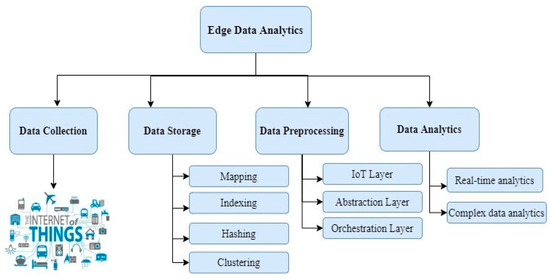
[6][36]. Heterogeneous data are collected from ubiquitous devices and pushed forward through communication channels to preprocess. Real-time analysis and decision-making occur to support quick responses to the applications on IoT devices. The services offering real-time analysis may be transferred to the cloud. Data processing depends on the information gathered from the hierarchical edge layer, how quickly the data are collected, and how they trigger the specific services for decision-making. The components that support this process are shown in
Figure 2.
Figure 2.
Components of edge data analytics.
Data Collection—All devices are the primary source to generate data. The devices may be electrical appliances, homes, or embedded systems connected with the unique Internet Protocol (IP) to establish connection and communication among them. Edge nodes closer to devices collect data and support computation for the IoT devices’ applications by offloading tasks across the cloud and edge nodes. Various deployment models deploy the task as middleware between the cloud and IoT devices with efficient resource utilization
[7][37].
Data Storage—Data collected from devices can be stored in either the device or on edge nodes in virtual machines or containers
[8][38]. Typical efficient storage relies on techniques such as mapping, hashing, clustering, replication, indexing, and so on. Data are collected in clusters and sent to the storage devices
[9][39]. In indexing, indexes are created based on the extraction, recognition, and labeling of real-time data, such as video streams or social media data
[10][40]. In replication, the data are duplicated to support the data-intense applications by encapsulating the coherent data logically
[11][41].
Data Processing—IoT verticals, abstraction layers, and orchestration layers are the three components responsible for data processing in edge computing architectures. IoT verticals include the application that is in use. They provide multitenancy to host the application on edge data servers and provide flexibility and interoperability to the edge nodes. The abstraction layer provides a uniform virtualized platform through a generic API to monitor, provision, and control physical resources. The orchestration layer includes data API and orchestration layer API, which are responsible for node placement or node selection, run-time monitoring, control during execution, and optimizing data-driven decisions
[12][13][42,43].
Data Analytics—Data collected from IoT devices are preprocessed on the edge nodes through intensive real-time task analysis. This establishes real-time interactions between the edge nodes and the users. For example, generating a diagnosis report for a doctor to treat the patient remotely
[14][44] or traffic signal detection for unmanned autonomous vehicles
[11][41]. The volume of data that may be challenging for the edge nodes to analyze is pushed to the cloud for more complex data analysis
[15][16][45,46]. Machine learning (ML) algorithms are usually employed to provide long-term predictive decisions
[17][47].
Decision-Making in Edge Data Analytics
Data analytics and decision management are two critical components of decision-making. The report generated from data analytics is used by the decision management component to identify what decisions should be made. For example, in traffic management applications, information about traffic density, vehicle-specific data, and movement of other vehicles and pedestrians are collected to perform quick data analytics and generate decisions on traffic flow. Hence, agility in decision-making triggers the business process, resource utilization, and customer satisfaction. Based on agility, decision-making is divided into predictive and reactive models: (i) Predictive models rely on the cloud to collect large amounts of data and perform long-term data analysis to identify the best decisions. They evaluate decisions based on various policies in the applications and improve the predictive analysis over time. (ii) Reactive models respond to an event with reactive decisions within a short time interval. These models achieve real-time support without focusing on what the system might look like in the future. The key characteristics of real-time support are the most suitable for edge computing applications. To obtain a decision at an adequate response time, edge nodes have to be placed closer to IoT devices
[18][48]. Whether services need to be placed on the cloud or edge is an optimization problem
[19][49].
However, when edge nodes are scattered and placed closer to IoT devices, monitoring these nodes will be challenging. Geographical factors, such as network infrastructure and regulatory environments, significantly influence the design and deployment of edge security solutions
[20][50]. In regions with limited network infrastructure, edge security solutions must adapt to unreliable or slow connectivity, potentially requiring decentralized architectures to ensure data processing and threat detection can occur locally
[21][51]. Regulatory environments, such as GDPR (General Data Protection Regulation) or HIPAA (Health Insurance Portability and Accountability Act of 1996), dictate strict requirements for data privacy and security, impacting how data are stored, processed, and transmitted in edge computing environments
[22][52]. Compliance with these regulations may necessitate additional encryption measures, data residency requirements, or auditing protocols in the design of edge security solutions. Moreover, variations in network latency due to geographical distances can affect the responsiveness of security measures, prompting the optimization of algorithms or deployment strategies to accommodate latency-sensitive applications. Additionally, geographical factors influence physical security considerations, as edge devices deployed in remote or inaccessible locations may require robust physical protection against tampering or unauthorized access
[23][53]. Overall, accounting for geographical factors is essential in designing and deploying effective edge security solutions that address the unique challenges posed by different environments. Intruders can easily compromise and gain access to the edge layer, and thus they can mine or steal data that are exchanged among edge nodes
[24][54]. In cloud computing, there are regulations and obligations for data protection, as per the European Commission
[8][38]. However, no such standards exist in edge computing, which makes them vulnerable to security attacks. In the next section, the security models that affect decision-making and the normal functioning of an application are reviewed.