Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Majdi Sukkar and Version 2 by Rita Xu.
Effective collision risk reduction in autonomous vehicles relies on robust and straightforward pedestrian tracking. Challenges posed by occlusion and switching scenarios significantly impede the reliability of pedestrian tracking.
- pedestrian tracking
- object detection
- multi-object tracking (MOT)
- autonomous vehicles
1. Introduction
In recent years, the significance of pedestrian tracking in autonomous vehicles has garnered considerable attention due to its pivotal role in ensuring pedestrian safety. Existing state-of-the-art approaches for pedestrian tracking in autonomous vehicles predominantly rely on object detection and tracking algorithms, including Faster R-CNN (Region-based Convolutional Neural Network), YOLO (You Only Look Once) and SORT algorithms [1]. However, these methods encounter issues in scenarios where pedestrians are occluded or only partially visible [2][2]. These challenges serve as the impetus for our research, as we strive to enhance the reliability and effectiveness of pedestrian tracking, particularly in complex scenarios.
More specifically, the challenges in pedestrian tracking are multifaceted, ranging from crowded urban environments to unpredictable pedestrian behavior [3]. Existing algorithms often struggle to handle scenarios where individuals move behind obstacles, cross paths, or exhibit sudden changes in direction. Furthermore, adverse weather conditions, low lighting, and dynamic urban landscapes pose additional hurdles for accurate pedestrian tracking [4]. These issues underscore the need for advanced pedestrian tracking solutions that can adapt to diverse and complex real-world scenarios.
In response to these challenges, theour research takes inspiration from recent advancements in deep learning and object detection. Deep learning techniques, with their ability to learn intricate patterns and representations from data, have shown promise in overcoming the limitations of traditional tracking methods. Leveraging the capabilities of the YOLOv8 algorithm for object detection, theour approach aims to enhance the accuracy and robustness of pedestrian tracking in dynamic and challenging environments [5]. By addressing the limitations of existing algorithms, rwesearchers aspire to contribute to the development of pedestrian tracking systems that are both reliable and adaptable.
The quest for improved pedestrian tracking is not solely confined to the domain of autonomous vehicles [6]. The relevant applications extend to various fields, such as surveillance, crowd management, and human–computer interaction. Accurate pedestrian tracking is crucial for ensuring public safety, optimizing traffic flow, and enhancing the overall efficiency of smart city initiatives [7][8][7,8]. The effectiveness of pedestrian tracking is also integral for a myriad of applications in the context of urban environments, and in smart cities, where the integration of technology aims to enhance the quality of life, with pedestrian tracking playing a crucial role. Efficient tracking systems can contribute to optimized traffic management, improved public safety, and enhanced urban planning [9]. Beyond traffic applications, pedestrian tracking finds applications in surveillance, where monitoring and analyzing pedestrian movement are essential for security [10]. Additionally, in human–computer interaction scenarios, accurate tracking is pivotal for creating responsive and adaptive interfaces, offering a wide array of possibilities for innovative applications [11]. Therefore, the advancements in pedestrian tracking have far-reaching implications, influencing various aspects of theour daily lives and the development of smart city ecosystems.
2. Pedestrian Tracking in Autonomous Vehicles
Recent advancements in pedestrian tracking encompass a diverse array of methods and algorithms, broadly classified into the following categories:-
Multi-Object Tracking (MOT) Methods:
-
These methods are designed to concurrently track multiple pedestrians within a scene. Traditional approaches often employ the Hungarian algorithm for association, linking detections across frames [5].
-
-
Re-identification-based Methods:
-
Multi-Cue Fusion: Strategies in this category amalgamate various cues, such as color, shape, and motion, to enhance tracking robustness in complex scenes. For instance, the multi-cue multi-camera pedestrian tracking (MCMC-PT) method integrates color, shape, and motion cues from multiple cameras for comprehensive pedestrian tracking [15][18].
Table 1. Comparison overview between StrongSORT and other multi-object trackers.
| Method | Advantages | Disadvantages |
|---|---|---|
| StrongSORT [4] |
|
|
| DeepSORT [26][28] | Simple and efficient | Limited robustness to occlusions and identity switches |
| TrackletNet [12][15] | Robust to occlusions and identity switches | Complex architecture and not real-time |
| DMAN [27][29] | Robust to occlusions and identity switches | Not real-time |
| SORT [28][30] | Simple and efficient | Limited robustness to occlusions and identity switches |
| ATOM [29][31] | Accurate tracking | Complex architecture and not real-time |
| IVDM [23][25] | Enhanced handling of occlusions and identity switches | Needs evaluation against real-time performance |
2.1. YOLOv8
YOLOv8 (You Only Look Once version 8) represents a significant advancement over its predecessors, YOLOv7 and YOLOv6, incorporating multiple features that enhance both speed and accuracy. A notable addition is the spatial pyramid pooling (SPP) module, enabling YOLOv8 to extract features at varying scales and resolutions [30][32]. This facilitates the precise detection of objects of different sizes. Another key feature is the cross stage partial network (CSP) block, reducing the network’s parameters without compromising accuracy, thereby improving both training times and overall performance [31][33]. Evaluation of prominent object detection benchmarks, including COCO and Pascal VOC datasets, showcases YOLOv8’s exceptional capabilities. The COCO dataset, with 80 object categories and complex scenes, saw YOLOv8 achieving the highest-ever mean average precision (mAP) score of 55.3% among single-stage object detection algorithms. Additionally, it achieved a remarkable real-time speed of 58 frames per second on an NVIDIA GTX 1080 Ti GPU. In summary, YOLOv8 stands out as an impressive object detection algorithm, delivering high accuracy and real-time performance. Its ability to process the entire image simultaneously makes it well suited for applications such as autonomous driving and robotics. With its innovative features and outstanding performance, YOLOv8 is poised to remain a preferred choice for object detection tasks in the foreseeable future [32][34]. Figure 1 illustrates the performance of YOLOv8 in real-world scenarios [33][35].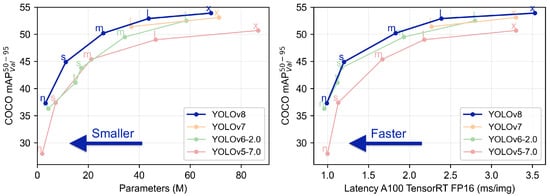
Figure 1. YOLOv8 performance.
2.2. DeepSORT
DeepSORT is an advanced real-time multiple objects tracking algorithm that leverages deep learning-based feature extraction coupled with the Hungarian algorithm for assignment. The code structure of DeepSORT comprises the following key components [34][36]:-
Feature Extraction: Responsible for extracting features from input video frames, including bounding boxes and corresponding features.
-
Detection and Tracking: Detects objects in each video frame and associates them with their tracks using the Hungarian algorithm.
-
Kalman Filter: Predicts the location of each object in the next video frame based on its previous location and velocity.
-
Re-identification: Matches the appearance of an object in one video frame with its appearance in a previous frame.
-
Output: Generates the final output—a set of object tracks for each video frame.
- Occlusion: Tracking challenges when objects overlap or obstruct each other
- [
- ]
- [
- 18].
2.3. StrongSORT
The StrongSORT algorithm enhances the original DeepSORT by introducing the AFLink algorithm for temporal matching to person tracking and the GSI algorithm for temporal interpolation of matched individuals. New configuration options have been incorporated to facilitate these improvements [4]:-
AFLink: A flag indicating whether the AFLink algorithm should be utilized for temporal matching.
-
Path_AFLink: The path to the AFLink algorithm model to be employed.
- Appearance Model: Stores and updates the appearance features of each object over time, facilitating re-identification and appearance updates.
- GSI: A flag indicating whether the GSI algorithm should be employed for temporal interpolation.
-
Transparent Objects: Challenges in detecting objects made of transparent materials.
-
Fast Motion: Challenges posed by quickly moving objects.
-
Interval: The temporal interval to be applied in the GSI algorithm.
-
Tau: The temporal interval to be used in the GSI algorithm.].
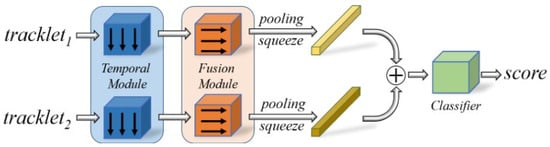
Figure 2. Framework of the AFLink model.