Concrete stands as the most widely used construction material globally due to its versatility, encompassing applications ranging from pavement, multifloor structures, and bridges to dams. However, these concrete structures endure structural stress and require close monitoring to prevent accidents and ensure sustainability throughout their complete life cycle. Artificial intelligence (AI) and computer vision (CV) have demonstrated considerable potential in diverse applications within construction engineering, including structural health monitoring (SHM) and inspection processes such as crack and damage detection, as well as rebar exposure. While it is undeniable that CV and deep learning models are transforming the construction industry by offering robust solutions for complex scenarios, there remain numerous challenges pertinent to their applications that require attention. This paper aims to systematically and critically review the literature of the past decade on the application of deep learning models in the construction industry for SHM purposes in concrete structures. The review delves into proposed methodologies and technologies while identifying opportunities and challenges associated with these applications in practice.
- concrete
- structural health monitoring (SHM)
- deep learning
- damage identification
- damage quantification
1. Introduction
2. Damage Identification
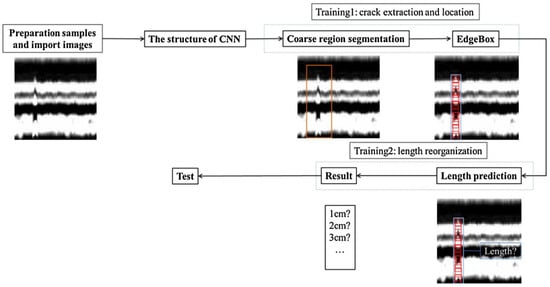
3. Damage Quantification

4. Suggested Future Frameworks
-
Data shortage: Although transfer learning has made the adaptation of deep learning easier. Raw data often need to go through many stages of post processing, which is very time-consuming and labor-intensive. Also, there is a need for annotated datasets, which are essential for any deep learning training [77]. Most studies have been conducted using private datasets; making such datasets public would open multiple doors for researchers in the SHM domain for multiple applications. Although data augmentation plays an important role in dataset incrementation, applying various transformations to existing data, such as rotating, scaling, flipping, or cropping images, is insufficient for research in the SHM area. An alternative method involves utilizing generative adversarial networks (GANs), where a deep learning model comprising two distinct networks (namely a generator and a discriminator) is employed to generate synthetic image data instead of relying on real-world camera inputs only, as reported in [38][51].
-
Impact of the training data on overfitting: Transfer learning has undeniably simplified the application of deep learning models in structural health monitoring (SHM). However, the persistent challenge of overfitting can arise, particularly in instances where there is a paucity of image data. Deep learning models characterized by multiple layers and millions of parameters demand extensive tuning, as illustrated, for example, by the necessity of adjusting at least 100 million parameters in VGG-16 for crack detection [12]. It is imperative that the training data encompass diverse real-world scenarios, accounting for variations in background, lighting, and weather conditions, to ensure the model’s robustness and applicability.
-
Requirement for high-performance computers: Many deep learning techniques necessitate several days for training due to the extensive calculations involved in computing related training parameters, such as loss functions. Adequate hardware, including high-capacity hard disks, multiple GPUs/CPUs, and substantial memory, is essential for storing these calculations. Researchers should prioritize discovering optimized model structures with fewer parameters, facilitating their seamless adaptation in structural health monitoring (SHM) applications.
-
Dealing with background noise: On the other hand, in addressing various background noises in images, researchers have implemented different morphological changes in the CNN architecture [31][38][41][44][45][51][58] to increase the detection accuracy. However, the source code is typically not publicly available. Researchers should be encouraged to make their source code publicly accessible, enabling other researchers to enhance the architecture further and, consequently, increase its applicability in actual practice. Due to the image resizing requirement of deep learning models to be trained on computers with average computing capacities, generalization abilities are often lost. For example, stains are a common issue in concrete structures and often incorrectly identified as cracks. To solve this issue, stains and similar could be categorized as another class [78] to improve the generalization abilities.
4. Suggested Future Frameworks
The number of deep-learning-based applications in concrete research is rapidly growing, especially in the SHM area. Numerous applications have been reported with respect to both concrete damage identification and quantification. The application and integration of stereo cameras and sensors, such as LiDAR and laser sensors, have made deep learning applications for damage quantification. Many researchers have applied various image processing techniques rather than integration with depth cameras or sensors. However, concrete cracks are very fine, so whichever system is adopted must precisely quantify a particular property (either length, width, or diameter). AlexNet, GoogleNet, Faster R-CNN, Mask R-CNN, U-Net, VGG, and YOLO models seem to be popular choices for damage identification. However, compared to other industries, construction falls behind in terms of adopting digitalization; therefore the application of deep-learning- and vision-based systems to monitor concrete health in the SHM area is still not sufficient in real practice, mostly due to the following issues:
- Data shortage: Although transfer learning has made the adaptation of deep learning easier, . Raw data often need to go through many stages of post processing, which is very time-consuming and labor-intensive. Also, there is a need for annotated datasets, which are essential for any deep learning training [129]. Most studies have been conducted using private datasets; making such datasets public would open multiple doors for researchers in the SHM domain for multiple applications.Although data augmentation plays an important role in dataset incrementation, applying various transformations to existing data, such as rotating, scaling, flipping, or cropping images, is insufficient for research in the SHM area. An alternative method involves utilizing generative adversarial networks (GANs), where a deep learning model comprising two distinct networks (namely a generator and a discriminator) is employed to generate synthetic image data instead of relying on real-world camera inputs only, as reported in [87,100].
- Impact of the training data on overfitting: Transfer learning has undeniably simplified the application of deep learning models in structural health monitoring (SHM). However, the persistent challenge of overfitting can arise, particularly in instances where there is a paucity of image data. Deep learning models characterized by multiple layers and millions of parameters demand extensive tuning, as illustrated, for example, by the necessity of adjusting at least 100 million parameters in VGG-16 for crack detection [61]. It is imperative that the training data encompass diverse real-world scenarios, accounting for variations in background, lighting, and weather conditions, to ensure the model’s robustness and applicability.
- Requirement for high-performance computers: Many deep learning techniques necessitate several days for training due to the extensive calculations involved in computing related training parameters, such as loss functions. Adequate hardware, including high-capacity hard disks, multiple GPUs/CPUs, and substantial memory, is essential for storing these calculations. Researchers should prioritize discovering optimized model structures with fewer parameters, facilitating their seamless adaptation in structural health monitoring (SHM) applications.
- Dealing with background noise: On the other hand, in addressing various background noises in images, researchers have implemented different morphological changes in the CNN architecture [80,87,90,93,94,100,107] to increase the detection accuracy. However, the source code is typically not publicly available. Researchers should be encouraged to make their source code publicly accessible, enabling other researchers to enhance the architecture further and, consequently, increase its applicability in actual practice. Due to the image resizing requirement of deep learning models to be trained on computers with average computing capacities, generalization abilities are often lost. For example, stains are a common issue in concrete structures and often incorrectly identified as cracks. To solve this issue, stains and similar could be categorized as another class [131] to improve the generalization abilities.
Despite the challenges and limitations, the use of deep learning and computer vision technologies holds significant promise in structural health monitoring (SHM) and concrete research. A collaborative effort from researchers, scholars, and engineers in the construction, computer science, and civil engineering domains can establish more effective deep -earning-based SHM inspection systems for both damage identification and quantification, regardless of severity, delicacy of the damage, and the influence of the surrounding environment.
5. Conclusion
The aim of this research was to conduct a systematic review of the utilization of deep learning in the identification and quantification of concrete damage for SHM purposes. This study delved into the concepts and historical development of artificial intelligence (AI), computer vision (CV), and deep learning. With the aim of including the latest advancements in concrete research, the analysis was focused on studies spanning from 2017 to 2023, particularly those addressing vision-based crack identification, categorization, and measurement analysis. Additionally, we addressed four critical issues regarding the application of deep learning in the field of SHM. This research provides helpful insights that can aid in future applications of concrete damage identification and quantification with deep learning and guide researchers and engineers in respective applications.
References
- Moein, M.M.; Saradar, A.; Rahmati, K.; Mousavinejad, S.H.G.; Bristow, J.; Aramali, V.; Karakouzian, M. Predictive models for concrete properties using machine learning and deep learning approaches: A review. J. Build. Eng. 2023, 63, 105444.
- Wang, W.; Su, C.; Fu, D. Automatic detection of defects in concrete structures based on deep learning. Structures 2022, 43, 192–199.
- Pu, R.; Ren, G.; Li, H.; Jiang, W.; Zhang, J.; Qin, H. Autonomous Concrete Crack Semantic Segmentation Using Deep Fully Convolutional Encoder–Decoder Network in Concrete Structures Inspection. Buildings 2022, 12, 2019.
- Shibu, M.; Kumar, K.P.; Pillai, V.J.; Murthy, H.; Chandra, S. Structural health monitoring using AI and ML based multimodal sensors data. Meas. Sens. 2023, 27, 100762.
- Yuan, F.G.; Zargar, S.A.; Chen, Q.; Wang, S. Machine learning for structural health monitoring: Challenges and opportunities. Sens. Smart Struct. Technol. Civ. Mech. Aerosp. Syst. 2020, 11379, 1137903.
- Yoon, J.; Lee, J.; Kim, G.; Ryu, S.; Park, J. Deep neural network-based structural health monitoring technique for real-time crack detection and localization using strain gauge sensors. Sci. Rep. 2022, 12, 20204.
- Zhou, Z.; Yan, L.; Zhang, J.; Zheng, Y.; Gong, C.; Yang, H.; Deng, E. Automatic segmentation of tunnel lining defects based on multiscale attention and context information enhancement. Constr. Build. Mater. 2023, 387, 131621.
- DeVries, P.M.; Viégas, F.; Wattenberg, M.; Meade, B.J. Deep learning of aftershock patterns following large earthquakes. Nature 2018, 560, 632–634.
- Spencer, B.F., Jr.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering 2019, 5, 199–222.
- Vodrahalli, K.; Bhowmik, A.K. 3D computer vision based on machine learning with deep neural networks: A review. J. Soc. Inf. Disp. 2017, 25, 676–694.
- Gomez-Cabrera, A.; Escamilla-Ambrosio, P.J. Review of machine-learning techniques applied to structural health monitoring systems for building and bridge structures. Appl. Sci. 2022, 12, 10754.
- Ye, X.W.; Jin, T.; Yun, C.B. A review on deep learning-based structural health monitoring of civil infrastructures. Smart Struct. Syst 2019, 24, 567–585.
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep convolutional neural networks with transfer learning for computer vision-based data-driven pavement distress detection. Constr. Build. Mater. 2017, 157, 322–330.
- Kolar, Z.; Chen, H.; Luo, X. Transfer learning and deep convolutional neural networks for safety guardrail detection in 2d images. Autom. Constr. 2018, 89, 58–70.
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 731–747.
- Tong, Z.; Gao, J.; Zhang, H.T. Recognition, location, measurement, and 3D reconstruction of concealed cracks using convolutional neural networks. Constr. Build. Mater. 2017, 146, 775–787.
- Gibert, X.; Patel, V.M.; Chellappa, R. Deep multitask learning for railway track inspection. IEEE Trans. Intell. Transp. Syst. 2016, 18, 153–164.
- Davoudi, R.; Miller, G.R.; Kutz, J.N. Computer vision based inspection approach to predict damage state and load level for RC members. In Proceedings of the 12th International Workshop on Structural Health Monitoring, Stanford, CA, USA, 10–12 September 2019.
- Lattanzi, D.; Miller, G.R.; Eberhard, M.O.; Haraldsson, O.S. Bridge column maximum drift estimation via computer vision. J. Comput. Civ. Eng. 2016, 30, 04015051.
- Dawood, T.; Zhu, Z.; Zayed, T. Machine vision-based model for spalling detection and quantification in subway networks. Autom. Constr. 2017, 81, 149–160.
- Yeum, C.M.; Dyke, S.J.; Ramirez, J. Visual data classification in post-event building reconnaissance. Eng. Struct. 2018, 155, 16–24.
- Kim, B.; Cho, S. Automated vision based detection of cracks on concrete surfaces using a deep learning technique. Sensors 2018, 18, 3452.
- Kang, D.; Cha, Y.J. Autonomous UAVs for structural health monitoring using deep learning and an ultrasonic beacon system with geo-tagging. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 885–902.
- Xue, Y.D.; Li, Y.C. A fast detection method via region based fully convolutional neural networks for shield tunnel lining defects. Comput. -Aided Civ. Infrastruct. Eng. 2018, 33, 638–654.
- Hoang, N.D.; Nguyen, Q.L.; Tran, V.D. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Automat. Constr. 2018, 94, 203–213.
- Dorafshan, S.; Thomas, R.J.; Maguire, M. Comparison of deep convolutional neural networks and edge detectors for image-based crack detection in concrete. Constr. Build. Mater. 2018, 186, 1031–1045.
- Wang, N.; Zhao, Q.; Li, S.; Zhao, X.; Zhao, P. Damage classification for masonry historic structures using convolutional neural networks based on still images. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1073–1089.
- Gao, Y.; Mosalam, K.M. Deep transfer learning for image-based structural damage recognition. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 748–768.
- Wu, R.T.; Singla, A.; Jahanshahi, M.R.; Bertino, E.; Ko, B.J.; Verma, D. Pruning deep convolutional neural networks for efficient edge computing in condition assessment of infrastructures. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 774–789.
- Zhang, B.; Zhou, L.; Zhang, J. A methodology for obtaining spatiotemporal information of the vehicles on bridges based on computer vision. Comput. Aided Civ. Infrastruct. Eng. 2019, 34, 471–487.
- Wang, M.; Cheng, J.C. A unified convolutional neural network integrated with conditional random field for pipe defect segmentation. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 162–177.
- Li, D.; Cong, A.; Guo, S. Sewer damage detection from imbalanced CCTV inspection data using deep convolutional neural networks with hierarchical classification. Autom. Constr. 2019, 101, 199–208.
- Zha, B.; Bai, Y.; Yilmaz, A.; Sezen, H. November. Deep Convolutional Neural Networks for Comprehensive Structural Health Monitoring and Damage Detection. In Proceedings of the 12th International Workshop on Structural Health Monitoring, Stanford, CA, USA, 10–12 September 2019.
- Zha, B.; Bai, Y.; Yilmaz, A.; Sezen, H. Deep learning–based autonomous concrete crack evaluation through hybrid image scanning. Struct. Health Monit. 2019, 18, 1722–1737.
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139.
- Mohtasham Khani, M.; Vahidnia, S.; Ghasemzadeh, L.; Ozturk, Y.E.; Yuvalaklioglu, M.; Akin, S.; Ure, N.K. Deep-learning-based crack detection with applications for the structural health monitoring of gas turbines. Struct. Health Monit. 2020, 19, 1440–1452.
- Zhang, C.; Chang, C.C.; Jamshidi, M. Concrete bridge surface damage detection using a single-stage detector. Comput.-Aided Civ. Infrastruct. Eng. 2020, 35, 389–409.
- Liu, Y.; Yeoh, J.K.; Chua, D.K. Deep learning–based enhancement of motion blurred UAV concrete crack images. J. Comput. Civ. Eng. 2020, 34, 04020028.
- Kim, B.; Cho, S. Automated multiple concrete damage detection using instance segmentation deep learning model. Appl. Sci. 2020, 10, 8008.
- Ghosh Mondal, T.; Jahanshahi, M.R.; Wu, R.T.; Wu, Z.Y. Deep learning-based multi-class damage detection for autonomous post-disaster reconnaissance. Struct. Control Health Monit. 2020, 27, e2507.
- Deng, W.; Mou, Y.; Kashiwa, T.; Escalera, S.; Nagai, K.; Nakayama, K.; Matsuo, Y.; Prendinger, H. Vision based pixel-level bridge structural damage detection using a link ASPP network. Autom. Constr. 2020, 110, 102973.
- Zheng, M.; Lei, Z.; Zhang, K. Intelligent detection of building cracks based on deep learning. Image Vis. Comput. 2020, 103, 103987.
- Karaaslan, E.; Bagci, U.; Catbas, F.N. Attention-guided analysis of infrastructure damage with semi-supervised deep learning. Autom. Constr. 2021, 125, 103634.
- Miao, Z.; Ji, X.; Okazaki, T.; Takahashi, N. Pixel-level multicategory detection of visible seismic damage of reinforced concrete components. Comput. Aided Civ. Infrastruct. Eng. 2021, 36, 620–637.
- Qiao, W.; Ma, B.; Liu, Q.; Wu, X.; Li, G. Computer vision-based bridge damage detection using deep convolutional networks with expectation maximum attention module. Sensors 2021, 21, 824.
- Huang, Z.; Fu, H.L.; Fan, X.D.; Meng, J.H.; Chen, W.; Zheng, X.J.; Wang, F.; Zhang, J.B. Rapid surface damage detection equipment for subway tunnels based on machine vision system. J. Infrastruct. Syst. 2021, 27, 04020047.
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Deep learning-based road damage detection and classification for multiple countries. Autom. Constr. 2021, 132, 103935.
- Cui, X.; Wang, Q.; Dai, J.; Zhang, R.; Li, S. Intelligent recognition of erosion damage to concrete based on improved YOLO-v3. Mater. Lett. 2021, 302, 130363.
- Pozzer, S.; Rezazadeh Azar, E.; Dalla Rosa, F.; Chamberlain Pravia, Z.M. Semantic segmentation of defects in infrared thermographic images of highly damaged concrete structures. J. Perform. Constr. Facil. 2021, 35, 04020131.
- Andrushia, A.D.N.A.; Lubloy, E. Deep learning based thermal crack detection on structural concrete exposed to elevated temperature. Adv. Struct. Eng. 2021, 24, 1896–1909.
- Munawar, H.S.; Ullah, F.; Heravi, A.; Thaheem, M.J.; Maqsoom, A. Inspecting buildings using drones and computer vision: A machine learning approach to detect cracks and damages. Drones 2021, 6, 5.
- Zou, D.; Zhang, M.; Bai, Z.; Liu, T.; Zhou, A.; Wang, X.; Cui, W.; Zhang, S. Multicategory damage detection and safety assessment of post-earthquake reinforced concrete structures using deep learning. Comput. Aided Civ. Infrastruct. Eng. 2022, 37, 1188–1204.
- Han, X.; Zhao, Z.; Chen, L.; Hu, X.; Tian, Y.; Zhai, C.; Wang, L.; Huang, X. Structural damage-causing concrete cracking detection based on a deep-learning method. Constr. Build. Mater. 2022, 337, 127562.
- Tanveer, M.; Kim, B.; Hong, J.; Sim, S.H.; Cho, S. Comparative Study of Lightweight Deep Semantic Segmentation Models for Concrete Damage Detection. Appl. Sci. 2022, 12, 12786.
- Bai, Z.; Liu, T.; Zou, D.; Zhang, M.; Zhou, A.; Li, Y. Image-based reinforced concrete component mechanical damage recognition and structural safety rapid assessment using deep learning with frequency information. Autom. Constr. 2023, 150, 104839.
- Crognale, M.; De Iuliis, M.; Rinaldi, C.; Gattulli, V. Damage detection with image processing: A comparative study. Earthq. Eng. Eng. Vib. 2023, 22, 333–345.
- Chen, L.; Chen, W.; Wang, L.; Zhai, C.; Hu, X.; Sun, L.; Tian, Y.; Huang, X.; Jiang, L. Convolutional neural networks (CNNs)-based multi-category damage detection and recognition of high-speed rail (HSR) reinforced concrete (RC) bridges using test images. Eng. Struct. 2023, 276, 115306.
- Wan, H.; Gao, L.; Yuan, Z.; Qu, H.; Sun, Q.; Cheng, H.; Wang, R. A novel transformer model for surface damage detection and cognition of concrete bridges. Expert Syst. Appl. 2023, 213, 119019.
- Zhu, Y.; Tang, H. Automatic damage detection and diagnosis for hydraulic structures using drones and artificial intelligence techniques. Remote Sens. 2023, 15, 615.
- Huang, B.; Zhao, S.; Kang, F. Image-based automatic multiple-damage detection of concrete dams using region-based convolutional neural networks. J. Civ. Struct. Health Monit. 2023, 13, 413–429.
- Kim, H.; Lee, J.; Ahn, E.; Cho, S.; Shin, M.; Sim, S.H. Concrete crack identification using a UAV incorporating hybrid image processing. Sensors 2017, 17, 2052.
- Tong, Z.; Gao, J.; Sha, A.; Hu, L.; Li, S. Convolutional neural network for asphalt pavement surface texture analysis. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1056–1072.
- Huang, Z.; Fu, H.; Chen, W.; Zhang, J.; Huang, H. Damage detection and quantitative analysis of shield tunnel structure. Autom. Constr. 2018, 94, 303–316.
- Tayo, C.O.; Linsangan, N.B.; Pellegrino, R.V. Portable crack width calculation of concrete road pavement using machine vision. In Proceedings of the 2019 IEEE 11th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Laoag, Philippines, 29 November–1 December 2019; pp. 1–5.
- Kim, B.; Cho, S. Image-based concrete crack assessment using mask and region-based convolutional neural network. Struct. Control Health Monit. 2019, 26, e2381.
- Wei, F.; Yao, G.; Yang, Y.; Sun, Y. Instance-level recognition and quantification for concrete surface bughole based on deep learning. Autom. Constr. 2019, 107, 102920.
- Beckman, G.H.; Polyzois, D.; Cha, Y.J. Deep learning-based automatic volumetric damage quantification using depth camera. Autom. Constr. 2019, 99, 114–124.
- Park, S.E.; Eem, S.H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096.
- Bhowmick, S.; Nagarajaiah, S.; Veeraraghavan, A. Vision and deep learning-based algorithms to detect and quantify cracks on concrete surfaces from UAV videos. Sensors 2020, 20, 6299.
- Flah, M.; Suleiman, A.R.; Nehdi, M.L. Classification and quantification of cracks in concrete structures using deep learning image-based techniques. Cem. Concr. Compos. 2020, 114, 103781.
- Yuan, C.; Xiong, B.; Li, X.; Sang, X.; Kong, Q. A novel intelligent inspection robot with deep stereo vision for three-dimensional concrete damage detection and quantification. Struct. Health Monit. 2022, 21, 788–802.
- Miao, P.; Srimahachota, T. Cost-effective system for detection and quantification of concrete surface cracks by combination of convolutional neural network and image processing techniques. Constr. Build. Mater. 2021, 293, 123549.
- Song, L.; Sun, H.; Liu, J.; Yu, Z.; Cui, C. Automatic segmentation and quantification of global cracks in concrete structures based on deep learning. Measurement 2022, 199, 111550.
- Kumarapu, K.; Mesapam, S.; Keesara, V.R.; Shukla, A.K.; Manapragada, N.V.S.K.; Javed, B. RCC Structural deformation and damage quantification using unmanned aerial vehicle image correlation technique. Appl. Sci. 2022, 12, 6574.
- Bae, H.; An, Y.K. Computer vision-based statistical crack quantification for concrete structures. Measurement 2023, 211, 112632.
- Li, Y.; Bao, T.; Huang, X.; Wang, R.; Shu, X.; Xu, B.; Tu, J.; Zhou, Y.; Zhang, K. An integrated underwater structural multi-defects automatic identification and quantification framework for hydraulic tunnel via machine vision and deep learning. Struct. Health Monit. 2023, 22, 2360–2383.
- Chowdhury, A.M.; Moon, S. Generating integrated bill of materials using mask R-CNN artificial intelligence model. Autom. Constr. 2023, 145, 104644.
- Yokoyama, S.; Matsumoto, T. Development of an automatic detector of cracks in concrete using machine learning. Procedia Eng. 2017, 171, 1250–1255.