Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Yifan Zhang and Version 2 by Sirius Huang.
Occlusion in facial photos poses a significant challenge for machine detection and recognition. Consequently, occluded face recognition for camera-captured images has emerged as a prominent and widely discussed topic in computer vision. The standard face recognition methods have achieved remarkable performance in unoccluded face recognition but performed poorly when directly applied to occluded face datasets. The main reason lies in the absence of identity cues caused by occlusions. Therefore, a direct idea of recovering the occluded areas through an inpainting model has been proposed.
- occluded face recognition
- identity-guided inpainting
- image synthesis
- generative adversarial net (GAN)
1. Introduction
In recent years, occluded face recognition has become a research hotspot in computer vision. Unlike unoccluded faces, occluded faces suffer from incomplete visual components and insufficient identity cues, which lead to degradation in recognition accuracy by normal recognizors [1][2][3][4][1,2,3,4]. Inspired by the recovery mechanism of the nervous system, researchers have proposed two types of approach, i.e., occlusion-robust and occlusion-recovery.
The occlusion-robust approach attempts to improve the robustness of recognizers on occluded faces by improving the “representation”. The latest work, FROM [5], proposed an end-to-end occluded face recognition model to learn the feature masks and deep occlusion-robust features simultaneously. However, compared with normal recognizers, it has weakened generalization ability over datasets with wide age and angle differences, such as the CFP-FP [6] and AgeDB-30 [7].
Unlike the occlusion-robust approach, the occlusion-recovery approach recovers the occluded regions before recognition. GAN-based inpainting methods [8][9][8,9] have remarkably improved realistic content generation. At the same time, identity-preserving inpainting models [10][11][12][13][14][15][10,11,12,13,14,15] have been demonstrated to be effective for occluded face recognition. These methods often adopt encoder-decoder-structured networks but with different identity loss during training, as Figure 1 shows. Dolhansky et al. [10] imported identity features to preserve identity information in eye regions by L2 feature loss, as Figure 1b shows. Inspired by the perceptual loss [11][12][16][11,12,16] used identity loss which combined perceptual items and identity feature items, as Figure 1c shows. The perceptual item is computed with semantic features from a low-level layer of the pretrained recognizer, while the identity feature item is from the output of the top-level layer. Ge et al. [15] proposed an identity-diversity loss that combines perceptual loss and identity-centered triplet loss to guide face recovery, which achieved state-of-the-art performance in identity preserving inpainting, as Figure 1d shows. Duan et al. [13] designed two-stage GAN models to deal with face completion and frontalization simultaneously. However, these methods are also limited by the challenge of preserving the inherent identity information against large occlusions. These methods often utilize incomplete datasets to learn the identity distribution with the supervision of identity and reconstruction loss functions, which makes the learned distribution deviate from its real one. Then, the decoder generates a new face from sampling the biased identity space, further enhancing the identity offset of the generated image.
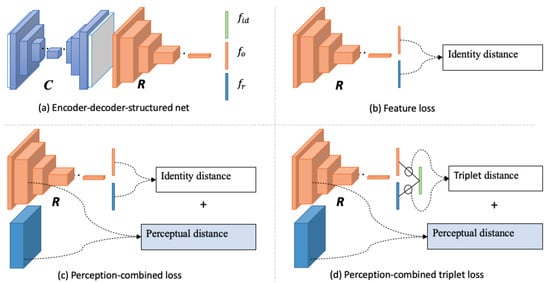
Figure 1. Encoder-decoder-structured identity-preserving inpainting networks with different identity training loss. 𝑪 is an encoder-decoder-structured content inpainting network, and 𝑹 is a pretrained recognizer. 𝑓𝑖𝑑, 𝑓𝑜, 𝑓𝑟 are identity-centered features, occlusion-recovered features, and real face features, respectively.
2. Occluded Face Recognition
Face recognition is a computer vision task that recognizes the identity among multiple face images. It is closely related to feature extraction, classification [17], and detection [18] technology. As one of the most successful practical cases, face recognition has a long history of research which has extended to various application scenarios [15][19][20][15,19,20]. Traditional face models are designed for unoccluded face images (see, for example, [1][2][1,2]). When they are applied directly to occluded datasets, their accuracy drops dramatically. There are two main approaches to solving the problem: occlusion-robust and occlusion-recovery.
The occlusion-robust approach reduces the accuracy drop by improving the robustness of recognizers on occluded faces. One idea is to improve the “representation”. Refs. [21][22][23][21,22,23] report various kinds of representation methods for facial features. The latest work called FROM [5] is an end-to-end occluded face recognition model to learn the feature masks and deep occlusion-robust features simultaneously and achieved the SOTA result on the occluded LFW dataset.
Unlike the occlusion-robust approach, the occlusion-recovery approach recovers the occluded facial regions and then performs recognition on the recovered faces. Ge et al. [15] proposed an identity-diversity inpainting network to facilitate occluded face recognition. It improved the recovery step by integrating GAN with a novel CNN network, which used identity-centered features as supervision to enable the inpainted faces to cluster towards their identity centers. In [14], occlusions were removed with a CNN-based deep inpainting network. However, these methods are also limited by the challenge of preserving the inherent identity information against large occlusions. The core reason lies in the insufficient transformation of identity information. So, if we can improve the identity information transformation in the inpainting phase, we will further improve the performance of occluded face recognition.
3. Identity-Preserving Face Inpainting
A simple approach for face inpainting is to borrow general deep learning inpainting methods directly, which are good at rebuilding the overall structure of the face. For example, generative inpainting methods [9][24][9,24] involve the design of attention layers to improve the global structure consistency and fidelity and have performed well in face inpainting. Although these methods have been shown to maintain the consistency of facial structure, they showed limited improvement in occluded face recognition. So, some researchers have turned their attention to identity-preserving face inpainting.
Identity-preserving face inpainting attempts to perceive the identity information from the uncorrupted region. Some attempts, e.g., [14][15][25][14,15,25], imported identity loss to solve the problem and were demonstrated to be effective for occluded face recognition, but not significantly. For example, Ge et al. [15] proposed an identity-preserving face completion model that combined a CNN network and a third recognizer player to complete identity-diversity inpainting. It was designed explicitly for occluded face recognition but failed to improve performance on large-size occlusions. The main reason is that the traditional encoder-decoder network trained on occluded datasets can not build real identity space, leading to a prominent identity offset in the inpainting process. Li et al. [26] creatively combined a general inpainting network with AAD-generator [27] to solve identity-guided inpainting tasks, regenerating missing content from a pretrained identity distribution. However, there is still a certain distance in style and structure between the generated face and the ground truth face. Although an additional Poisson blending module is used to repair the style difference, the structure bias cannot be erased.