Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Muhammad Sohaib and Version 2 by Rita Xu.
To prevent potential instability, the early detection of cracks is imperative due to the prevalent use of concrete in critical infrastructure. Automated techniques leveraging artificial intelligence, machine learning, and deep learning as the traditional manual inspection methods are time-consuming. The existing automated concrete crack detection algorithms, despite recent advancements, face challenges in robustness, particularly in precise crack detection amidst complex backgrounds and visual distractions, while also maintaining low inference times.
- crack detection
- concrete structures
- structural health monitoring
1. Introduction
Concrete is an extensively used material in building infrastructures, including bridges, buildings, roads, and pavements. Nevertheless, the structural integrity of concrete constructions undergoes a natural degradation process due to several factors. These factors include environmental impacts, excessive loads, and the slow deterioration of components [1][2][3]. The identification of cracks in concrete structures has great significance. These cracks indicate the early stages of degradation, presenting a substantial threat to the durability and stability of the structure [4]. Cracks function as entry points, facilitating the ingress of water and deleterious chemicals in concrete structures. As a consequence, issues such as corrosion of reinforcing bars (rebar), disintegration, and spalling in the structures arise [5][6]. These concerns have the potential to significantly undermine public safety and endanger the structural integrity of the construction project.
Historically, the conventional practice for detecting these fissures has used manual visual examinations [7]. Nevertheless, this approach is not without its difficulties as it is characterized by a significant investment of time, a large amount of effort, and a strong dependence on the inspector’s competence. Moreover, the practice of human inspections is accompanied by inherent safety hazards [8]. Therefore, non-invasive methods for assessing the health of concrete structures have been developed and studied in the literature which are becoming increasingly essential in the management of smart facilities [8]. These systems are based on data-driven artificial intelligence (AI) techniques in which data are usually collected through magnetic shape memory alloys (MSMA), capacitive sensors, embedded piezoelectric (PZT) sensors, and digital cameras [9][10][11]. Automated procedures provide a more economically advantageous, streamlined, and secure substitute for human inspections. The use of machine learning and digital image processing methods for crack detection has been a notable focus of study in this field [12].
It is effective and robust in detecting cracks in concrete structures through the segmentation of digital images. In this perspective, Bhattacharya et al. proposed an interleaved deep artifacts-aware attention mechanism (iDAAM) to classify images containing structural faults [13]. The algorithm could extract local discriminant features benefiting the defect identification in the images. In another study, Zhao et al. [14] proposed a feature pyramid network (crack-FPN) for crack detection, segmentation, and width estimation. First crack detection was performed through You Only Look Once version 5 (YOLOv5) model, and it was later segmented by crack-FPN. Although the proposed algorithm could effectively detect and segment the crack, the proposed methodology had a relatively greater inference time on the test images. Similarly, Zhang et al. [15] presented a MobileNetv3-based broad learning-based effective concrete surface cracks detection mechanism with high accuracy and improved learning time. In this work, first, features were extracted from the images through MobileNetv3 which were later mapped in a broad learning system to identify cracks. A binary convolutional neural network (CNN) was presented for the identification of cracks in concrete structures [16]. It integrated regression models such as random forest (RF) and XGBoost and exhibited a high accuracy on a publicly available dataset. However, the accuracy of the model deteriorated when tested with unseen data. In [17] an optimized Deeplabv3+ BDF network is proposed for concrete crack segmentation. The network is trained using transfer learning, coarse-annotation, and fine-annotation techniques. The developed model could effectively detect cracks in the images.
2. Overview of the YOLOv8 Model
The basic structure of the You Only Look Once (YOLOv1) network as described in [18] is given in Figure 1. It contains a total of 26 layers of which 24 are convolutional layers and 2 are fully connected layers. The convolution layers are used to extract feature maps from the inputs. The extracted feature maps through convolution operations are down-sampled to reduce their dimensions. The output of the network is a 7 × 7 × 30 tensor. Moreover, it uses stochastic gradient descent as an optimizer. Over the years, different variants of the YOLO network have been released with YOLOv8 the latest member of the YOLO series. The schematics of this latest variant are presented in Figure 2. This current iteration maintains the same architectural structure as its previous versions, namely version 6 [19]. However, it incorporates some enhancements in comparison to other versions of YOLO, i.e., it integrates the feature pyramid network (FPN) with the path aggregation network (PAN). Moreover, it also has an updated image annotation mechanism including automated labeling, shortcuts to perform labeling efficiently, and hotkeys that facilitate the training of a model. The FPN module steadily decreases the spatial resolution of the inputs while instantaneously increasing the number of channels for the feature. In this way, it forms feature maps that can identify objects of varying scales and resolutions. In contrast, the PAN module combines features from different layers of the network by using skip connections. This technique is helpful for the model to explore features at various scales and resolutions, hence, benefiting the model to identify objects with diverse dimensions and configurations [20]. The complete architecture of YOLOv8 is discussed in the following subsections.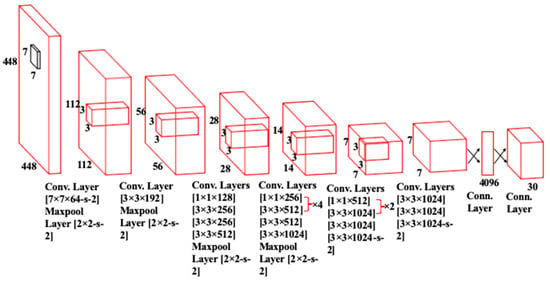
Figure 1. The architecture of YOLOv1 Network.
2.1. Backbone Network
In YOLOv8, the backbone network consists of a customized CSPDarknet53 network [21], in which inputs are first down-sampled five times, resulting in five distinct scales of features. In the updated structure, the backbone network uses a C2f module, i.e., a faster cross-stage partial (CSP) bottleneck with two convolutions instead of traditional CSP. In the C2f module, the information flow is optimized through a gradient shunt connection. It provides a richer flow of gradients within the architecture, hence, reducing the computational complexity and also lightweight network design. First, convolution and batch normalization operations are performed on the inputs, and later, the output of the network is obtained by activating the information stream using a sigmoid-weighted linear unit (SiLU). In YOLOv8 the spatial pyramid pooling fast (SPPF) is used to generate feature maps of constant size at the input, and adjustable dimensions at the output. Moreover, it also effectively reduces computational complexity and latency by linking the three highest pooling levels [22], as compared to the SPPF.2.2. Neck Module
The neck part of YOLOv8 is inspired by the PANet architecture [23] and incorporates a Path Aggregation Network and Feature Pyramid Network (PAN-FPN) arrangement. In contrast to YOLOv5 and YOLOv6, the convolutional (conv) step that follows the up-sampling (U) of the PAN module is absent in YOLOv8 which results in a more efficient and lightweight model. The PAN-FPN architecture unifies top-down and bottom-up approaches that concatenate (C) the shallow and deep semantic information resulting in diverse and comprehensive features.2.3. Head Module
The detection module of YOLOv8 applies a decoupled head structure where there is a separate branch for classification and predicted bounding box regression. This detection structure helps in object detection with high precision and accelerates the convergence of the model. Moreover, YOLOv8 relies on an anchor-free approach for the detection module that effectively identifies positive and negative samples. In addition, to improve detection accuracy and resilience, it incorporates the Task-Aligned Assigner [24] to dynamically allocate samples.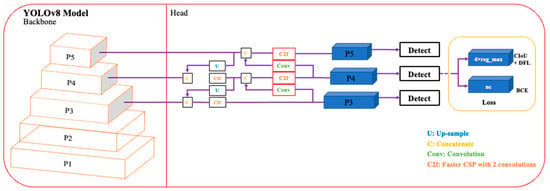
Figure 2. An illustration of YOLOv8 Architecture.
References
- Janev, D.; Nakov, D.; Arangjelovski, T. Concrete for Resilient Infrastructure: Review of Benefits, Challenges and Solutions. In Proceedings of the 20th International Symposium of MASE, Skopje, North Macedonia, 28–29 September 2023; Macedonian Association of Structural Engineers (MASE): Skopje, North Macedonia; pp. 208–219.
- Rasheed, P.A.; Nayar, S.K.; Barsoum, I.; Alfantazi, A. Degradation of Concrete Structures in Nuclear Power Plants: A Review of the Major Causes and Possible Preventive Measures. Energies 2022, 15, 8011.
- Asmara, Y.P. Concrete Reinforcement Degradation and Rehabilitation: Damages, Corrosion and Prevention; Springer: Singapore, 2023; ISBN 9819959330.
- Olurotimi, O.J.; Yetunde, O.H.; Akah, A.R.C.U. Assessment of the Determinants of Wall Cracks in Buildings: Investigating the Consequences and Remedial Measure for Resilience and Sustainable Development. Int. J. Adv. Educ. Manag. Sci. Technol. 2023, 6, 121–132.
- Al Fuhaid, A.F.; Niaz, A. Carbonation and Corrosion Problems in Reinforced Concrete Structures. Buildings 2022, 12, 586.
- Feng, G.; Zhu, D.; Guo, S.; Rahman, M.Z.; Jin, Z.; Shi, C. A Review on Mechanical Properties and Deterioration Mechanisms of FRP Bars under Severe Environmental and Loading Conditions. Cem. Concr. Compos. 2022, 134, 104758.
- Wang, J.; Ueda, T. A Review Study on Unmanned Aerial Vehicle and Mobile Robot Technologies on Damage Inspection of Reinforced Concrete Structures. Struct. Concr. 2023, 24, 536–562.
- Lattanzi, D.; Miller, G. Review of Robotic Infrastructure Inspection Systems. J. Infrastruct. Syst. 2017, 23, 4017004.
- Eslamlou, A.D.; Ghaderiaram, A.; Schlangen, E.; Fotouhi, M. A Review on Non-Destructive Evaluation of Construction Materials and Structures Using Magnetic Sensors. Constr. Build. Mater. 2023, 397, 132460.
- Ghosh, A.; Edwards, D.J.; Hosseini, M.R.; Al-Ameri, R.; Abawajy, J.; Thwala, W.D. Real-Time Structural Health Monitoring for Concrete Beams: A Cost-Effective ‘Industry 4.0’ Solution Using Piezo Sensors. Int. J. Build. Pathol. Adapt. 2021, 39, 283–311.
- Bang, H.; Min, J.; Jeon, H. Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera. Sensors 2021, 21, 2759.
- Vijayan, V.; Joy, C.M.; Shailesh, S. A Survey on Surface Crack Detection in Concretes Using Traditional, Image Processing, Machine Learning, and Deep Learning Techniques. In Proceedings of the 2021 International Conference on Communication, Control and Information Sciences (ICCISc), Idukki, India, 16–18 June 2021; IEEE, 2021; Volume 1, pp. 1–6.
- Bhattacharya, G.; Mandal, B.; Puhan, N.B. Interleaved Deep Artifacts-Aware Attention Mechanism for Concrete Structural Defect Classification. IEEE Trans. Image Process. 2021, 30, 6957–6969.
- Zhao, W.; Liu, Y.; Zhang, J.; Shao, Y.; Shu, J. Automatic Pixel-Level Crack Detection and Evaluation of Concrete Structures Using Deep Learning. Struct. Control Health Monit. 2022, 29, e2981.
- Zhang, J.; Cai, Y.-Y.; Yang, D.; Yuan, Y.; He, W.-Y.; Wang, Y.-J. MobileNetV3-BLS: A Broad Learning Approach for Automatic Concrete Surface Crack Detection. Constr. Build. Mater. 2023, 392, 131941.
- Laxman, K.C.; Tabassum, N.; Ai, L.; Cole, C.; Ziehl, P. Automated Crack Detection and Crack Depth Prediction for Reinforced Concrete Structures Using Deep Learning. Constr. Build. Mater. 2023, 370, 130709.
- Shen, Y.; Yu, Z.; Li, C.; Zhao, C.; Sun, Z. Automated Detection for Concrete Surface Cracks Based on Deeplabv3+ BDF. Buildings 2023, 13, 118.
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A Comprehensive Review of YOLO Architectures in Computer Vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716.
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976.
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO: From YOLOv1 and beyond. arXiv 2023, arXiv:2304.00501.
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916.
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768.
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-Aligned One-Stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499.
More