Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Loris Nanni and Version 2 by Lindsay Dong.
In computer vision and image analysis, Convolutional Neural Networks (CNNs) and other deep-learning models are at the forefront of research and development. These advanced models have proven to be highly effective in tasks related to computer vision. One technique that has gained prominence in recent years is the construction of ensembles using deep CNNs. These ensembles typically involve combining multiple pretrained CNNs to create a more powerful and robust network.
- convolutional neural networks
- ensembles
- fusion
1. Introduction
Artificial neural networks (ANNs), which were initially developed in the 1950s, have had a checkered history, at times appreciated for their unique computational capabilities and at other times disparaged for being no better than statistical methods. Opinions shifted about a decade ago with deep neural networks, whose performance swiftly overshadowed that of other learners across various scientific (e.g., [1][2][1,2]), medical (e.g., [3][4][3,4]), and engineering domains (e.g., [5][6][5,6]). The prowess of deep learners is especially exemplified by the remarkable achievements of Convolutional Neural Networks (CNNs), one of the most renowned and robust deep-learning architectures.
CNNs have consistently outperformed other classifiers in numerous applications, particularly in image-recognition competitions where they frequently emerge as winners [7]. Not only do CNNs surpass traditional classifiers, but they also often outperform the recognition abilities of human beings. In the medical realm, CNNs have demonstrated superior performance compared to human experts in tasks such as skin cancer detection [8][9][8,9], identification of skin lesions on the face and scalp, and diagnosis of esophageal cancer (e.g., [10]). These remarkable achievements have naturally triggered a substantial increase in research focused on utilizing CNNs and other deep-learning techniques in medical imaging.
For instance, deep-learning models have emerged as the state-of-the-art for diagnosing conditions like diabetic retinopathy [11], Alzheimer’s disease [12], skin detection [13], gastrointestinal ulcers, and various types of cancer, as demonstrated in recent reviews and studies (see, for instance, [14][15][14,15]). Enhancing performance within the medical field carries the greater real impact of this technology compared to other applications.
CNNs, however, have limitations. It is widely recognized that they require many samples to avoid overfitting [16]. Acquiring image collections numbering in the hundreds of thousands for proper CNN training is an enormous enterprise [17]. In certain medical domains, it is prohibitively labor-intensive and costly [18]. Several well-established techniques have been developed to address the issue of overfitting with limited data, the two most common being transfer learning using pretrained CNNs and data augmentation [19][20][19,20]. The literature is abundant with studies investigating both methods, and it has been observed that combining the two yields better results (e.g., [21]).
In addition to transfer learning and data augmentation, another powerful technique for enhancing the performance of deep learners generally, as well as on small sample sizes, is to construct ensembles of pretrained CNNs [22]. Ensemble learning is a powerful technique in machine learning that aims to enhance predictive performance by combining the outputs of multiple classifiers [23]. The fundamental idea behind ensemble learning is to introduce diversity among the individual classifiers so that they collectively provide more accurate and robust predictions. This diversification can be achieved through various means, each contributing to the ensemble’s overall effectiveness [24].
One common approach to creating diversity among classifiers is to train each classifier on different subsets or variations of the available data [25]. This approach, known as data sampling or bootstrapping, allows each classifier to focus on different aspects or nuances within the dataset, which can lead to improved generalization and robustness. Another technique for introducing diversity is to use different types of CNN architectures within the ensemble [26]. By combining CNNs with distinct architectural features, such as varying kernel sizes, filter depths, or connectivity patterns, the ensemble can capture different aspects of the underlying data distribution, enhancing its overall predictive power [27][28][27,28]. In addition to varying architectural aspects, ensemble diversity can also be achieved by modifying network depth. Some classifiers within the ensemble may have shallower network architectures, while others may be deeper. This diversity in network depth can help the ensemble address different levels of complexity within the data, improving its adaptability to varying patterns and structures.
Furthermore, the ensemble can introduce diversity by using different activation functions within the neural networks. Activation functions play a crucial role in determining how information flows through the neural network layers. By employing a variety of activation functions, the ensemble can capture different types of non-linear relationships in the data, enhancing its ability to model complex patterns. Figure 1 depicts an example of a neural network in which each layer adopts an activation function that could be chosen at random among a set of available ones. The chosen activation function is then used by all the neurons in that layer.
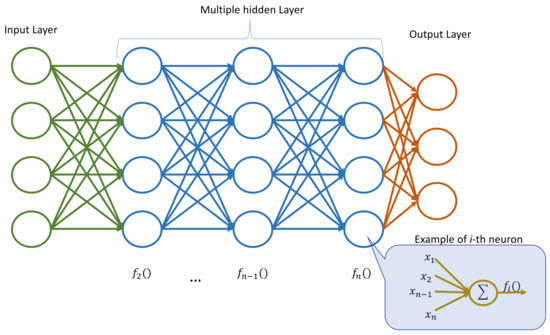
Figure 1. Example of neural network with multiple hidden layers. Each layer adopts a (possibly) different activation function to be used by all the neurons in that layer.
2. Methods for Building Ensembles of Convolutional Neural Networks
The related work in this field explores various strategies for creating ensembles of CNNs, with a focus on achieving high performance and maximizing the independence of predictions. Already addressed in the introduction are approaches based on training networks with different architectures and activation functions and using diverse training sets and data-augmentation approaches for the same network architecture. In addition, ensembles can be generated by combining multiple pretrained CNNs, employing various training algorithms, and applying distinct rules for combining networks.
The most intuitive approach to forming an ensemble involves training different models and then combining their outputs. Identifying the optimal classifier for a complex task can be a challenging endeavor [23]. Various classifiers may excel in leveraging the distinctive characteristics of specific areas within the given domain, potentially resulting in higher accuracy exclusively within those particular regions [29][30][35,36].
Most researchers taking this intuitive approach primarily fine-tune or train well-known architectures from scratch, average the results, and then demonstrate through experiments that the ensemble outperforms individual stand-alone networks. For instance, in [31][37], Kassani et al. employed an ensemble of VGG19 [32][38], MobileNet [33][34], and DenseNet [34][39] to classify histopathological biopsies, showing that the ensemble consistently achieved better performance than each individual network across four different datasets. Similarly, Qummar et al. [11] proposed an ensemble comprising ResNet50 [35][33], Inception v3 [36][40], Xception [37][41], DenseNet121, and DenseNet169 [34][39] to detect diabetic retinopathy.
In their study, Liu et al. [38][42] constructed an ensemble comprising three distinct CNNs proposed in their paper and averaged their results. Their ensemble achieved higher accuracy than the best individual model on the FER2013 dataset [39][43]. Similarly, Kumar et al. [40][44] introduced an ensemble of pretrained AlexNet and GoogleNet [41][45] models from ImageNet, which were then fine-tuned on the ImageCLEF 2016 collection dataset [42][46]. They utilized the features extracted from the last fully connected layers of these networks to train an SVM, an approach that outperformed CNN baselines and remained competitive with state-of-the-art methods at that time. Pandey et al. [43][47] proposed FoodNet, an ensemble composed of finetuned AlexNet, GoogleNet, and ResNet50 models designed for food image recognition. The output features from these models were concatenated and passed through a fully connected layer and softmax classifier.
Utilizing diverse training sets to train a classifier proves to be an effective approach to generating independent classifiers [23]. This can be achieved through various methods, with one classic technique being bagging [44][45][46][48,49,50]. Bagging involves creating m training sets of size n from a larger training set by randomly selecting samples with uniform probability and with replacement. Subsequently, the same model is trained on each of these training sets. Figure 2 depicts the bagging process. Examples of this approach to building ensembles include the work of Kim and Lim [47][51], who proposed a bagging-based approach to train three distinct CNNs for vehicle-type classification. Similarly, Dong et al. [48][52] applied bagging and CNNs to improve short-term load forecasting in a smart grid, resulting in a significant reduction of the mean absolute percentage error (MAPE) from 33.47 to 28.51. As another example, Guo and Gould [49][53] employed eight different datasets to train eight distinct networks for object detection. These datasets were formed by combining existing datasets in various ways. Remarkably, this straightforward approach led to substantial performance gains compared to individual models and brought the ensembles’s performance close to the state-of-the-art on competitive datasets like COCO 2012.
The training algorithms employed in CNNs follow stochastic trajectories and operate on stochastic data batches. Consequently, training the same network multiple times may lead to different models at the end of the process. Scholars can enhance the diversity among the final models in many ways: for instance, by employing different initialization of the initial model, or by adopting different optimization algorithms or loss functions during the training phase. Figure 3 depicts an example of an ensemble which adopt different optimization algorithms to introduce diversity. For instance, the authors in [50][54] constructed an ensemble for facial expression recognition using soft-label perturbation, where different losses were propagated for different samples. Similarly, Antipov et al. [51][55] utilized different network initializations to train multiple networks for gender predictions from face images.
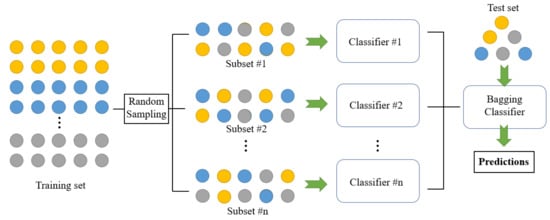
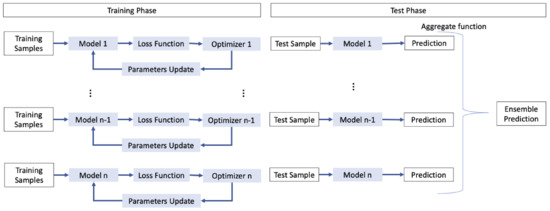
Figure 3.
Example of ensemble that can use different optimization algorithms to introduce diversity.
Another approach to building ensembles is to adopt the same architecture but vary the activation functions. This can be done in a set of CNNs or within different layers of a single CNN [53][57]. One way to implement the latter approach is to select a random activation function from a pool for each layer in the original network [53][57].
Finally, ensembles can vary in the selection of rules for merging results. A straightforward approach is majority voting, where the predominant output selected by the majority of the networks is taken [54][55][56][57][58,59,60,61]. Another common technique frequently cited in the literature is to average the softmax outputs of the networks [58][59][60][62,63,64].