Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Pascal Meißner and Version 3 by Rita Xu.
“Active Scene Recognition” (ASR) is an approach for mobile robots to identify scenes in configurations of objects spread across dense environments. This identification is enabled by intertwining the robotic object search and the scene recognition on already detected objects. “Implicit Shape Model (ISM) trees” are proposed as the scene model underpinning the ASR approach. These trees are a hierarchical model of multiple interconnected ISMs.
- Hough transform
- spatial relations
- object arrangements
- object search
1. Introduction
To act autonomously in various situations, robots not only need the capabilities to perceive and act, but must also be provided with models of the possible states of the world. If we imagine such a robot as a household helper, it will have to master tasks such as setting, clearing, or rearranging tables. Let us imagine that such a robot looks at the table in Figure 1 and tries to determine which of these tasks is pending. More precisely, the robot must choose between four different actions, each of which contributes to the solution of one of the tasks. An autonomous robot may choose an action based on a comparison of its perceptions with its world model, i.e., its assessment of the state of the world. Which scenes are present is an elementary aspect of such a world state. In particular, we model scenes not by the absolute poses of the objects in them, but by the spatial relations between these objects. Such a model can be more easily reused across different environments because it models a scene regardless of where it occurs.
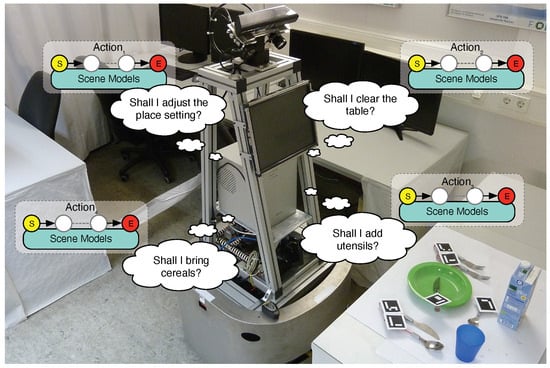
Figure 1. Motivating example for scene recognition: The mobile robot MILD looking at an object configuration (a.k.a. an arrangement). It reasons which of its actions to apply.
1.1. Scene Recognition—Problem and Approach
“Implicit Shape Model (ISM) trees” provide a solution to the problem of classifying into scenes a configuration (a.k.a. an arrangement) of objects whose poses are given in six degrees of freedom (6-DoF). Recognizing scenes based on the objects present is an approach suggested for indoor environments by [1] and successfully investigated by [2]. The trees, i.e., the classifier proposed, not only describe a single configuration of objects, but rather a multitude of configurations that these objects can take on while still representing the same scene. Hereinafter, this multitude of configurations will be referred to as a “scene category” rather than as a “scene”, which is a specific object configuration. For Figure 1, the classification problem addressed can be paraphrased as follows: “Is the present tableware an example of the modeled scene category?”, “How well does each of these objects fit our scene category model?”, “Which objects on the table belong to the scene category?”, and “How many objects are missing from the scene category?” This classifier is learned from object configurations demonstrated by a human in front of a robot and perceived by the robot using 6-DoF object pose estimation.
Many scene categories require that the spatial characteristics of relations, including uncertainties, be accurately described. For example, a table setting requires that some utensils be exactly parallel to each other, whereas their positions relative to the table are less critical. To meet such requirements, single implicit shape models (ISMs) were proposed as scene classifiers in [3]. Inspired by Hough voting, a classic but still popular approach (see [4][5][4,5]), these ISMs let each detected object in a configuration vote on which scenes it might belong to, thus using the spatial relations in which the object participates. The fit of these votes yields a confidence level for the presence of a scene category in an object configuration.
1.2. Object Search—Problem and Approach
Figure 2 shows an experimental kitchen setup as an example of the many indoor environments where objects are spatially distributed and surrounded by clutter. A robot will have to acquire several points of view before it has observed all the objects in such a scene. This problem is addressed in a field called three-dimensional object search ([6]). The existing approaches often rely on an informed search. This method is based on the fact that detected objects specify areas where other objects should be searched. However, these areas are predicted by individual objects rather than by entire scenes. Predicting poses utilizing individual objects can lead to ambiguities, since, e.g., a knife in a table setting would expect the plate to be beneath itself when a meal is finished, whereas it would expect the plate to be beside itself when the meal has not yet started. Instead, using estimates for scenes to predict poses resolves this problem.


Figure 2. Experimental setup mimicking a kitchen. The objects are distributed over a table, a cupboard, and some shelves. Colored dashed boxes are used to discern the searched objects from the clutter and to assign objects to exemplary scene categories.
To this end, ’Active Scene Recognition’ (ASR) was presented in [7][8][7,8], which is a procedure that integrates scene recognition and object search. Roughly, the procedure is as follows: The robot first detects some objects and computes which scene categories these objects may belong to. Assuming that these scene estimates are valid, it then predicts where missing objects, which would also belong to these estimates, could be located. Based on these predictions, camera views are computed for the robot to check. The flow of the overall approach (see [9]), which consists of two phases—first the learning of scene classifiers and then the execution of active scene recognition—is shown in Figure 3.
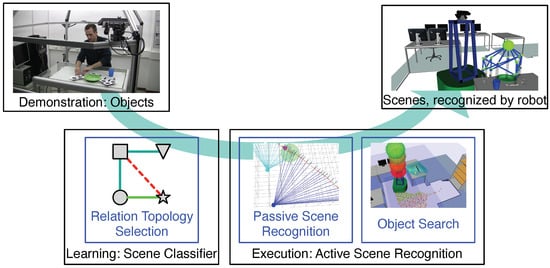
Figure 3. Overview of the research problems (in blue) addressed by the overall approach. At the top are the inputs and outputs of the approach. Below are the two phases of the approach: scene classifier learning and ASR execution.
1.3. Relation Topology Selection—Problem
The authors train their scene classifiers using sensory-perceived demonstrations (see [10]), which consist of a two- to three-digit number of recorded object configurations. This learning task involves the problem of selecting pairs of objects in a scene to be related by spatial relations. Which combination of relations is modeled determines the number of false positives returned by a classifier and the runtime of the scene recognition. Combinations of relations are hereinafter referred to as relation topologies.
2. Scene Recognition
The research generally defines scene understanding as an image labeling problem. There are two approaches to address it. One derives scenes from detected objects and relations between them, and the other derives scenes directly from image data without intermediary concepts such as objects, as [11][14] has investigated. Descriptions of scenes in the form of graphs (modeling existing objects and relation types), as derived by an object-based approach, are far more informative for further use, e.g., for mapping ([12][13][15,16]) or object search, than the global labels for images that are instead derived using the “direct” approach. Work in line with [14][17] or [15][18] (see [16][19] for an overview) that follows the object-based approach relies on neural nets for object detection, including feature extraction (e.g., through the work by [17][18][20,21]), wherein they combined it with neural nets to generate scene graphs. This approach is made possible by datasets that include relations ([19][20][22,23]), which have been published in recent years alongside object detection datasets ([21][22][24,25]). These scene graph nets are very powerful, but they are designed to learn models of relations that focus on relation types or meanings rather than the spatial characteristics of relations. In contrast, in this work, the authors want to focus on accurately modeling the spatial properties of relations and their uncertainties. Nevertheless, their model should be able to cope with small amounts of data, since the authors want it to learn from demonstrations of people’s personal preferences concerning object configurations. Indeed, users must provide personal data, wherein they tend to put in a limited effort.
Examples of preferences in object configurations can be breakfast tables, which only few people will want to have set in the same way. Nevertheless, people will expect household robots to consider their preferences when arranging objects. For example, ref. [23][26] addressed personal preferences by combining a relation model for learning preferences for arranging objects on a shelf with object detection. However, while their approach could even successfully handle conflicting preferences, it also missed subtle differences between spatial relations in terms of their extent. Classifiers explicitly designed to model relations and their uncertainties, such as the part-based models [24][27] from the 2000s, are a more expressive alternative. They also have low sample complexity, thus making them suitable for learning from demonstrations. By replacing their outdated feature extraction component with CNN-based object detectors or pose estimators (e.g., DOPE [25][28], PoseCNN [26][29], or CenterPose [27][30]), the authors obtain an object-based scene classifier that combines the power of CNNs with the expressiveness of part-based models in relation modeling. Thus, the authors' approach combines pretrained object pose estimators with the relation modeling of part-based models.
Ignoring the outdated feature extraction of part-based models, the authors note that [28][31] already successfully used a part-based model, the constellation model [29][32], to represent scenes. Constellation models define spatial relations using a parametric representation over Cartesian coordinates (a normal distribution), just like the pictorial structures models [30][33] (another part-based model) do. Recently, ref. [31][34]’s approach of using probability distributions over polar coordinates to define relations has proven to be more effective for describing practically relevant relations. Whereas such distributions are more expressive than the model in [23][26], they are still too coarse for us. Moreover, they use a fixed number of parameters to represent relations. What would be most appropriate when learning from demonstrations of varying length is a relation model whose complexity grows with the number of training samples demonstrated, i.e., a nonparametric model [10]. Such flexible models are the implicit shape models (ISMs) of [32][33][35,36]. Therefore, the authors chose ISMs as the basis for their approach. One shortcoming that ISMs have in common with constellation and pictorial structures models is that they can only represent a single type of relation topology. However, the topology that yields the best tradeoff between the number of false positives and scene recognition runtime can vary from scene to scene. The authors extended the ISMs to our hierarchical ISM trees to account for this. The authors also want to mention scene grammars ([34][37]), which are similar to part-based models but motivated by formal languages. Again, they model relations probabilistically and only use star topologies. For these reasons, the authors chose ISMs over scene grammars.
3. Object Pose Prediction
The research addresses the search for objects in 3D either as an active vision ([35][36][37][38][39][40][38,39,40,41,42,43]) or as a manipulation problem ([41][42][43][44][45][46][44,45,46,47,48,49]). Active vision approaches are divided into direct ([47][48][50,51]) and indirect ([49][52]) searches depending on the type of knowledge about the potential object poses used. An indirect search uses spatial relations to predict from the known poses of objects those of searched objects. An indirect search can be classified according to the type ([50][53]) of relations used to predict the poses. Refs. [51][52][53][54,55,56], for example, used the relations corresponding to natural language concepts such as ’above’ in robotics. Even though such symbolic relations provide high-quality generalization, they can only provide coarse estimates of metric object poses—too coarse for many object search tasks. For example, ref. [54][57] successfully adapted and used Boltzmann machines to encode symbolic relations. Representing relations metrically with probability distributions showed promising results in [55][58]. However, their pose predictions were derived exclusively from the known locations of individual objects, thereby leading to ambiguities that the use of scenes can avoid.