Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Rita Xu and Version 1 by Manju Vallayil.
The rapid growth in Artificial Intelligence (AI) has led to considerable progress in Automated Fact Verification (AFV). This process involves collecting evidence for a statement, assessing its relevance, and predicting its accuracy.
- automated fact verification
- AFV
- explainable artificial intelligence
1. Introduction
Advances in Artificial Intelligence (AI), particularly the transformer architecture [1] and the sustained success it has brought in transferring learning approaches in natural language processing, have led to advances in Automated Fact Verification (AFV). AFV systems are increasingly used in AI applications, making it imperative that AI-assisted decisions are also accompanied by reasoning, especially in sensitive sectors like medicine and finance [2]. In addition, researchers have also increasingly recognized the significance of AFV in the modern media landscape, where the rapid dissemination of information and misinformation has become a pressing concern [3]. Consequently, AFV systems have become pivotal in addressing the challenges posed by the spread of online misinformation, particularly in verifying claims and assessing their accuracy based on evidence from textual sources [4]. An AFV pipeline involves the sub tasks of collecting evidence related to a claim, sorting the most relevant evidence sentences, and predicting the veracity of the claim. Some systems such as [5] follow an additional step in the preliminary stage to detect whether a claim is check-worthy or not before commencing on the other sub tasks in the pipeline. Besides these sub tasks, recent studies like [6] have started exploring how to generate automatic explanations as the reason for veracity prediction. However, not as much effort has been put into the explanation functionality of AFV compared to the strong progress made over the past few years both in fact checking technology and datasets [7]. The lack of focus on explanation is behind the growing interest in explainable AI research [7]. Explainable AI is also known as interpretable AI or explainable machine learning. Although used interchangeably, there is a subtle difference between explainability and interpretability, where the latter is not necessarily easily understood by those with little experience in the field, unlike the former. Explainable AI aims to provide the reasoning behind the decision (prediction) made, in contrast to the ‘black box’ impression (https://en.wikipedia.org/wiki/Explainable_artificial_intelligence, accessed on 15 September 2023) of machine learning, where even the AI practitioners fail to explain the reason behind a particular decision made by an AI system they designed. Similarly, the goal of explainable AFV systems is to go beyond simple fact verification by generating interpretations that are grounded in facts and that are communicated in a way that is easily understood and accepted by humans. Although there is broad agreement in the research community on the importance of the explainability of AI systems [8,9[8][9][10],10], there is much less agreement on the current state of explainable AFV. The latest studies on the verification of facts [11,12,13][11][12][13] do not cohere around an aligned view on the subject, while researchers like [12] state that “Modern fact verification systems have distanced themselves from the black-box paradigm”. The authors of [13] contradict this by stating that modern AFV systems estimate the truthfulness “using numerical scores which are not human-interpretable”. The same impression, as articulated in the latter statement, can be drawn from the literature review of state-of-the-art AFV systems. Another of the most recent arguments supporting this view is [11]. They assert that, despite being a “nontrivial task”, the explainability of AFV is “mostly unexplored” and “needs to evolve” compared to the developments in explainable NLP.
This issue is further exacerbated by the fact that providing justifications for claim verdicts has always been a crucial aspect of human fact checking [3,7][3][7]. Therefore, it becomes evident that the transition from manual to automated fact checking falls short of achieving its intended human aspect to the functionality for ‘Automated Fact Verification’ unless there is a clear incorporation of explainability.
2. Explainable AFV
Despite notable progress in the development of explainable AI techniques, achieving comprehensive global explainability in AFV models remains a challenging task. However, this issue encompasses multiple aspects that pose significant obstacles to research in the field of explainable AFV. First, only a relatively small number of automated fact-checking systems include explainability components. Second, explainable AFV systems currently do not possess the capability of global explainability. Finally, the existing datasets for AFV suffer from a lack of explanations.2.1. Architectural Perspective
The majority of AFV systems broadly adopt a three-stage pipeline architecture similar to the Fact Extraction and VERification (FEVER) shared task [26][14], as identified and commented on by many researchers [26,27,28,29,30,31,32][14][15][16][17][18][19][20]. These three stages (also called sub-tasks) are document retrieval (evidence retrieval), sentence selection (evidence selection), and recognizing textual entailment or RTE (label/veracity prediction). The document retrieval component is responsible for gathering relevant documents from a knowledge base, such as Wikipedia, based on a given query. The sentence-retrieval component then selects the most pertinent evidence sentences from the retrieved documents. Lastly, the RTE component predicts the entailment relationship between the query and the retrieved evidence. Although the above framework is generally followed in AFV, alternative approaches incorporate additional distinct components to identify credible claims and provide justifications for label predictions, as shown in Figure 1. The inclusion of a justification component in such alternative approaches contributes to the system’s capacity for explainability within the AFV paradigm.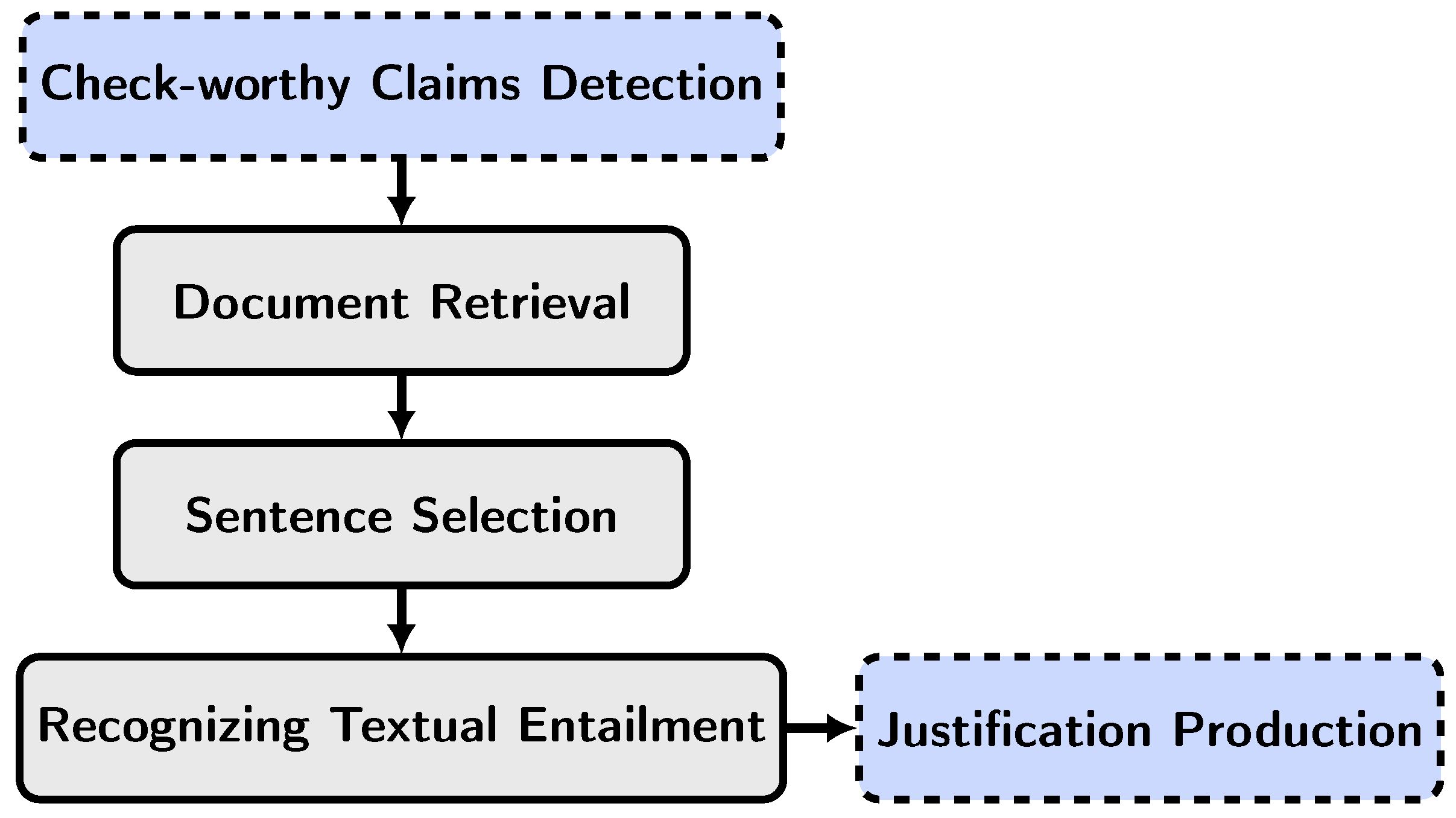
Figure 1. Overview of stages in Automated Fact Verification. This figure depicts the primary stages—document retrieval, sentence selection, and recognition of textual entailment—along with optional components for assessing the check-worthiness of claims and providing justifications.
2.2. Methodological Perspective
The methodological aspect looks at the different approaches utilized in the existing literature to develop explainable AFV systems.2.2.1. Summarization Approach
In AFV, extractive and abstractive explanations serve as two types of summarization methodologies, providing a summary along with the predicted label as a form of justification or explanation. Extractive explanations involve directly extracting relevant information or components from the input data that contribute to the prediction or fact-checking outcome. These explanations typically rely on the emphasis of specific words, phrases, or evidence within the input. On the other hand, abstractive explanations involve generating novel explanations that may not be explicitly present in the input data. These explanations focus on capturing the essence or key points of the prediction or fact-checking decision by generating new text that conveys the rationale or reasoning behind the outcome. It is important to note that terminology can vary across fields. For instance, in the explainable natural language processing (explainable NLP) literature, ref. [14][22] refers to extractive explanations as ‘Highlights’ and abstractive explanations as ‘Free-text explanations’. The approaches to explainability employed by existing explainable AFV systems are primarily extractive. For example, the work of [23] presents the first investigation of the generation of explanations automatically based on the available claim context, utilizing the transformer model architecture for extraction summarization purposes. Two models are trained with the intention of addressing this issue. One model focuses on generating post hoc explanations, where the predictive and explanation models are trained independently, while the other model is trained jointly to handle both tasks simultaneously. The model that trains the explainer separately tends to slightly outperform the model trained jointly. In [34][24], the task of explanation generation as a form of summarization is also approached. However, their methodology differs from that of [23]. Specifically, the explanation models of [34][24] are fine-tuned for extractive and abstractive summarization, with the aim of generating novel explanations that go beyond mere extractive summaries. By training the models on a combination of extractive and abstractive summarization tasks, they enabled the models to generate more comprehensive and insightful explanations by both leveraging existing information in the input and generating new text to convey the reasoning behind the fact-checking outcomes. A potential concern is that these models (both extractive and abstractive) may generate explanations that, while plausible in relation to the decision, do not accurately reflect the actual veracity prediction process. This issue is particularly problematic in the case of abstractive models, as they can generate misleading justifications due to the possibility of hallucinations [3].2.2.2. Logic-Based Approach
In logic-based explainability, the focus is on capturing the logical relationships and dependencies between various pieces of information involved in fact verification. This includes representing knowledge in the form of logical axioms, rules, and constraints to provide justifications for the verification results. For example, refs. [6,32][6][20] are recent studies that focus on the explainability of fact verification using logic-based approaches. In [6], a logic-regularized reasoning framework, LOREN, is proposed for fact verification. By incorporating logical rules and constraints, LOREN ensures that the reasoning process adheres to logical principles, improving the transparency and interpretability of the fact verification system. The experimental results demonstrate the effectiveness of LOREN in achieving an explainable fact verification. Similarly, ref. [32][20] highlights the potential of natural logic theorem proving as a promising approach for explainable fact verification systems. The system, named ProoFVer, applies logical inference rules to derive conclusions based on given premises, providing transparent explanations for the verification process. The experimental evaluation shows the efficacy of ProoFVer in accurately verifying factual claims while also offering interpretable justifications through the logical reasoning steps. It is important to acknowledge certain limitations and drawbacks associated with this logic-based approach. First, the complexity and computational cost of logic-based reasoning can limit its scalability and practical applicability in real-world fact verification scenarios. Furthermore, while logic provides a structured and interpretable framework for reasoning, it may not capture all the nuances and complexities of natural language and real-world information. This means that the effectiveness of these approaches heavily relies on the adequacy and comprehensiveness of the predefined logical rules, which may not cover all possible scenarios and domains. Lastly, the interpretability of the generated explanations may still be challenging for non-expert users. They may involve complex logical steps that require expertise to fully understand and interpret.2.2.3. Attention-Based Approach
Different from the summarization and the logic-based techniques, explainable AFV systems such as [24,35][25][26] use visualizations to illustrate important features or evidence utilized by AFV models for predictions. This provides users with a means to understand the relationships that influence the decision-making process. For example, the AFV model proposed in [35][26] introduces an attention mechanism that directs the focus towards the salient words in an article in relation to a claim. This enables the generation of the most significant words in the article as evidence (words with more weights are highlighted in darker shades in the verdict) and [35][26] claims that this strategy enhances the transparency and interpretability of the model. The explanation module of the fact checking framework in [24][25] also utilizes the attention mechanism to generate explanations for the model’s predictions, highlighting the important features and evidence used for classification. However, ref. [3] illustrated several critical concerns associated with the reliability of attention as an explanatory method, citing pertinent studies [36,37,38][27][28][29] to reinforce the argument. The authors point out that the removal of tokens assigned high attention scores does not invariably affect the model’s predictions, illustrating that some tokens, despite their high scores, may not be pivotal. On the contrary, certain tokens with lower scores have been found to be crucial for accurate model predictions. These observations collectively indicate a possible ‘fidelity’ issue in the explanations yielded by attention mechanisms, questioning the reliability and interpretability of attention mechanisms in models. Furthermore, ref. [3] argue that the complexity of these attention-based explanations can pose substantial challenges for people lacking an in-depth understanding of the model architecture, compromising readability and overall comprehension. This scrutiny of the limitations inherent to attention-based explainability methods highlights the pressing need to reevaluate their applicability and reliability within the realm of AFV.2.2.4. Counterfactual Approach
Counterfactual explanations, also known as inverse classifications, describe minimal changes to input variables that would lead to an opposite prediction, offering the potential for recourse in decision-making processes [18][30]. These explanations allow users to understand what modifications are needed to reverse a prediction made by a model. In the context of AFV, counterfactual explanations have been explored. The study in [39][31], for example, explicitly focuses on the interpretability aspect of counterfactual explanations in order to help users understand why a specific piece of news was identified as fake. The comprehensive method introduced in that work involves question answering and entailment reasoning to generate counterfactual explanations, which could enhance users’ understanding of model predictions in AFV. In a recent study [40][32] exploring debiasing for fact verification, researchers propose a method called CLEVER that operates from a counterfactual perspective to mitigate biases in predicting the veracity. CLEVER stands out by training separate models for claim–evidence fusion and claim-only prediction, allowing the unbiased aspects of predictions to be highlighted. This method could be explored further in the context of explainability in AFV, as it allows users to discern the factors that lead to specific predictions, even if the main emphasis of the cited work was on bias mitigation.2.3. Data Perspective
The potential of data explainability lies in its ability to provide deep insights that enhance the explainability of AI systems (which rely heavily on data for knowledge acquisition) [2,9][2][9]. Data explainability methods encompass a collection of techniques aimed at better comprehending the datasets used in the training and design of AI models [2]. The importance of a training dataset in shaping the behavior of AI models highlights the need to achieve a high level of data explainability. Therefore, it is crucial to note that constructing a high-performing and explainable model requires a high-quality training dataset. In AFV, the nature of this dataset, also known as the source of evidence, has evolved over time. Initially, the evidence was primarily based on claims, where information directly related to the claim was used for verification. Subsequently, knowledge-base-based approaches were introduced, utilizing structured knowledge sources to support the verification process. Further advances led to the adoption of text-based evidence, where relevant textual sources were used for verification. In recent developments, there has been a shift towards dynamically retrieved sentences, where the system dynamically retrieves and selects sentences that are most relevant to the claim for verification purposes. The subsequent text examines the implications of these changes through the lens of explainability. Systems such as [41][33] that process the claim itself, using no other source of information as evidence, can be termed as ‘knowledge-free’ or ‘retrieval-free’ systems. In these systems, the linguistic characteristics of the claim are considered as the deciding factor. For example, claims that contain a misleading phrase are labeled ‘Mostly False’. In [42][34], a similar approach is also employed, focusing on linguistic patterns, but a hybrid methodology is incorporated by including claim-related metadata with the input text to the deep learning model. These additional data include information such as the claim reporter’s profile and the media source where the claim is published. These knowledge-free systems face limitations in their performance, as they depend only on the information inherent in the claim and do not consider the current state of affairs [43][35]. The absence of contextual understanding and the inability to incorporate external information make dataset-level explainability infeasible in these systems. In knowledge-base-based fact verification systems [44[36][37][38],45,46], a claim is verified against the RDF triples present in a knowledge graph. The veracity of the claim is calculated by assessing the error between the claim and the triples based on different approaches such as rule-based, subgraph-based, or embedding-based methods. The drawback of such systems is the likelihood of a claim being verified as false, based on the assumption that the supporting facts of a true claim are already present in the graph, which is not always feasible. This limited scalability and the inability to capture nuanced information hinder the achievement of explainability in these types of fact verification models. Unlike the latter two approaches, in the evidence retrieval approach, supporting pieces of evidence for the claim verdict have to be fetched from a relevant source using an information retrieval method. Although the benefits of such systems outweigh the limitations of static approaches mentioned earlier, there are certain significant constraints that can also affect the explainability of these models. While the quality of the source (biased or unreliable), availability of the source (geographical or language restrictions), and resources for the retrieval process (time-consuming and expensive human and computational resources) can have a significant impact on the evidence retrieval and limit the scope of evidence, a deep understanding of the claim’s context is critical to avoid misinterpreted and incomplete evidence which leads to erroneous verdicts. Nevertheless, these limitations suggest that the evidence retrieval approach might not be entirely consistent with key XAI principles such as ‘Accuracy’ and ‘Fidelity’. This, in turn, casts doubt on the effectiveness of any post hoc explainability measures attempted within this data aspect. An alternative approach is using text from verified sources of information as evidence; encyclopedia articles, journals, Wikipedia, and fact-checked databases are some examples. Since Wikipedia is an open-source web-based encyclopedia and contains articles on a wide range of topics, it is consistently considered an important source of information for many applications, including economic development [47][39], education [48][40], data mining [49][41], and AFV. For example, the FEVER task [26][14], an application in AFV, relies on the retrieval of evidence from Wikipedia pages. In the FEVER dataset, each SUPPORTED/REFUTED claim is annotated with evidence from Wikipedia. This evidence could be a single sentence, multiple sentences, or a composition of evidence from multiple sentences sourced from the same page or multiple pages of Wikipedia. This approach aligns well with the XAI principle of ‘Interpretability’, as Wikipedia is a widely accessible and easily understandable source of information. However, it is crucial to note that Wikipedia also comes with limitations that could impact the ‘Accuracy’ and ‘Fidelity’ principles of XAI, which can potentially impact the interpretability of models relying on Wikipedia as a primary data source. Firstly, like any other source, Wikipedia pages can contain biased and inaccurate content, and these can remain undetected for a longer period (the same goes for outdated information); this compromises the ‘Accuracy’ of any AFV model trained on these data. Secondly, despite covering a wide range of topics, Wikipedia suffers deficiencies in comprehensiveness (https://en.wikipedia.org/wiki/Reliability_of_Wikipedia#Coverage, accessed on 15 September 2023), limiting a model’s ability to understand contextual information fully, thereby affecting ‘Interpretability’. Lastly, models trained predominantly on Wikipedia’s textual content can develop biases and limitations inherent to the nature and scope of Wikipedia’s content, impacting both ‘Fidelity’ and ‘Interpretability’ when applied to diverse real-world scenarios and varied types of unstructured data. Given these considerations and their misalignment with the XAI objectives of ‘Interpretability’, ‘Accuracy’, and ’Fidelity’, it becomes evident that relying solely on Wikipedia as a training dataset may not be the most effective pathway toward explainable AFV. Alternatively, Wikipedia can be used as an elementary corpus to train the AI model to achieve a general understanding of various knowledge domains for AFV, and this background or prior knowledge can then be harnessed further with additional domain data to gain a deeper context (which helps the model to attain information on global relationships and thus increase explainability). As the largest Wikipedia-based benchmark dataset for fact verification [28,50][16][42], the FEVER dataset can unarguably be considered as this elementary corpus for AFV tasks, and transformers and transfer learning is the most pragmatic technology choice for AFV according to state-of-the-art systems [31,32,51][19][20][43]. The quality of the dataset used or created for an application is a major factor in determining the explainability of a transformer-based AFV model and its ability to comprehend the underlying context. For example, ref. [52][44] developed the SCIFACT dataset in order to expand the ideas of FEVER to COVID-19 applications. SCIFACT comprises 1.4 K expert-written scientific claims along with 5K+ abstracts (from different scientific articles) that either support or refute each claim and are annotated with rationales, which consist of a minimal collection of sentences from the abstract that imply the claim. This study demonstrated the obvious advantages of using such a domain-specific dataset (it can also be called a subdomain here as scientific claim verification is a sub task of claim verification) as opposed to just using a Wikipedia-based evidence dataset. In [52][44], it is argued that the inclusion of rationales in the training dataset “facilitates the development of interpretable models” that not only label predictions but also identify the specific sentences necessary to support the decisions. However, the limited scale of the dataset, consisting of only 1.4 K claims, necessitates caution in interpreting assessments of system performance and underscores the need for more expansive datasets to propel advancements in explainable fact checking research. Building on this perspective of improving the quality and diversity of the dataset, ref. [53][45] critically evaluated the FEVER corpus, emphasizing its reliance on synthetic claims from Wikipedia and advocating for a corpus that incorporates natural claims from a variety of web sources. In response to this identified need, they introduced a new, mixed-domain corpus, which includes domains like blogs, news, and social media—the mediums often responsible for the spread of unreliable information. This corpus, which encompasses 6422 validated claims and over 14,000 documents annotated with evidence, addresses the prevalent limitations in existing corpora, including restricted sizes, lack of detailed annotations, and domain confinement. However, through a meticulous error analysis, ref. [53][45] discovered inherent challenges and biases in claim classification attributed to the heterogeneous nature of the data and the incorporation of fine-grained evidence (FGE) from unreliable sources. These findings illustrate substantial barriers to realizing the fundamental goals of XAI, particularly accuracy and fidelity. Moreover, ref. [53][45]’s focus on diligently modeling meta-information related to evidence and claims could be understood as their implicit recognition of the crucial role of explainability in the realm of automated fact checking. By suggesting the integration of diverse forms of contextual information and reliability assessments of sources, they highlight the necessity of developing models that are not only more accurate but also capable of providing reasoned and understandable decisions, a pivotal step towards fostering explainability in automated fact checking systems.References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 2017-Decem, pp. 5999–6009.
- Ali, S.; Abuhmed, T.; El-Sappagh, S.; Muhammad, K.; Alonso-Moral, J.M.; Confalonieri, R.; Guidotti, R.; Del Ser, J.; Díaz-Rodríguez, N.; Herrera, F. Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Inf. Fusion 2023, 99, 101805.
- Guo, Z.; Schlichtkrull, M.; Vlachos, A. A Survey on Automated Fact-Checking. Trans. Assoc. Comput. Linguist. 2022, 10, 178–206.
- Du, Y.; Bosselut, A.; Manning, C.D. Synthetic Disinformation Attacks on Automated Fact Verification Systems. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI-22), Virtually, 22 February–1 March 2022.
- Hassan, N.; Zhang, G.; Arslan, F.; Caraballo, J.; Jimenez, D.; Gawsane, S.; Hasan, S.; Joseph, M.; Kulkarni, A.; Nayak, A.K.; et al. ClaimBuster: The First-Ever End-to-End Fact-Checking System. Proc. VLDB Endow. 2017, 10, 1945–1948.
- Chen, J.; Bao, Q.; Sun, C.; Zhang, X.; Chen, J.; Zhou, H.; Xiao, Y.; Li, L. Loren: Logic-regularized reasoning for interpretable fact verification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 10482–10491.
- Kotonya, N.; Toni, F. Explainable Automated Fact-Checking: A Survey. In Proceedings of the COLING 2020—28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 5430–5443.
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 0210–0215.
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42.
- Kim, T.W. Explainable artificial intelligence (XAI), the goodness criteria and the grasp-ability test. arXiv 2018, arXiv:1810.09598.
- Das, A.; Liu, H.; Kovatchev, V.; Lease, M. The state of human-centered NLP technology for fact-checking. Inf. Process. Manag. 2023, 60, 103219.
- Olivares, D.G.; Quijano, L.; Liberatore, F. Enhancing Information Retrieval in Fact Extraction and Verification. In Proceedings of the Sixth Fact Extraction and VERification Workshop (FEVER), Dubrovnik, Croatia, 5 May 2023; pp. 38–48.
- Rani, A.; Tonmoy, S.M.T.I.; Dalal, D.; Gautam, S.; Chakraborty, M.; Chadha, A.; Sheth, A.; Das, A. FACTIFY-5WQA: 5W Aspect-based Fact Verification through Question Answering. arXiv 2023, arXiv:2305.04329.
- Thorne, J.; Vlachos, A.; Cocarascu, O.; Christodoulopoulos, C.; Mittal, A. The Fact Extraction and VERification (FEVER) Shared Task. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER), Brussels, Belgium, 1 November 2018; pp. 1–9.
- Soleimani, A.; Monz, C.; Worring, M. BERT for evidence retrieval and claim verification. In Advances in Information Retrieval, Proceedings of the 42nd European Conference on IR Research, ECIR 2020, Lisbon, Portugal, 14–17 April 2020, Proceedings, Part II; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 12036 LNCS, pp. 359–366.
- Zhong, W.; Xu, J.; Tang, D.; Xu, Z.; Duan, N.; Zhou, M.; Wang, J.; Yin, J. Reasoning over semantic-level graph for fact checking. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6170–6180.
- Jiang, K.; Pradeep, R.; Lin, J. Exploring Listwise Evidence Reasoning with T5 for Fact Verification. In Proceedings of the ACL-IJCNLP 2021—59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Proceedings of the Conference, Virtual, 1–6 August 2021; Volume 2, pp. 402–410.
- Chen, J.; Zhang, R.; Guo, J.; Fan, Y.; Cheng, X. GERE: Generative Evidence Retrieval for Fact Verification. In Proceedings of the SIGIR 2022—45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2184–2189.
- DeHaven, M.; Scott, S. BEVERS: A General, Simple, and Performant Framework for Automatic Fact Verification. In Proceedings of the Sixth Fact Extraction and VERification Workshop (FEVER), Dubrovnik, Croatia, 5 May 2023; pp. 58–65.
- Krishna, A.; Riedel, S.; Vlachos, A. ProoFVer: Natural Logic Theorem Proving for Fact Verification. Trans. Assoc. Comput. Linguist. 2022, 10, 1013–1030.
- Huang, Y.; Gao, M.; Wang, J.; Shu, K. DAFD: Domain Adaptation Framework for Fake News Detection. In Proceedings of the Neural Information Processing; Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 305–316.
- Wiegreffe, S.; Marasovic, A. Teach Me to Explain: A Review of Datasets for Explainable Natural Language Processing. In Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1), Virtual, 6–14 December 2021.
- Atanasova, P.; Simonsen, J.G.; Lioma, C.; Augenstein, I. Generating Fact Checking Explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7352–7364.
- Kotonya, N.; Toni, F. Explainable automated fact-checking for public health claims. In Proceedings of the EMNLP 2020—2020 Conference on Empirical Methods in Natural Language Processing; Online, 19–20 November 2020, pp. 7740–7754.
- Shu, K.; Cui, L.; Wang, S.; Lee, D.; Liu, H. dEFEND: Explainable fake news detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 395–405.
- Popat, K.; Mukherjee, S.; Yates, A.; Weikum, G. Declare: Debunking fake news and false claims using evidence-aware deep learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, EMNLP 2018, Brussels, Belgium, 31 October–4 November 2018; pp. 22–32.
- Jain, S.; Wallace, B.C. Attention is not Explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 3543–3556.
- Serrano, S.; Smith, N.A. Is attention interpretable? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2931–2951.
- Pruthi, D.; Gupta, M.; Dhingra, B.; Neubig, G.; Lipton, Z.C. Learning to deceive with attention-based explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4782–4793.
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215.
- Dai, S.C.; Hsu, Y.L.; Xiong, A.; Ku, L.W. Ask to Know More: Generating Counterfactual Explanations for Fake Claims. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2800–2810.
- Xu, W.; Liu, Q.; Wu, S.; Wang, L. Counterfactual Debiasing for Fact Verification. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 6777–6789.
- Rashkin, H.; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2931–2937.
- Wang, W.Y. “Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 422–426.
- Thorne, J.; Vlachos, A. Automated Fact Checking: Task Formulations, Methods and Future Directions. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3346–3359.
- Shi, B.; Weninger, T. Discriminative predicate path mining for fact checking in knowledge graphs. Knowl.-Based Syst. 2016, 104, 123–133.
- Gardner, M.; Mitchell, T. Efficient and expressive knowledge base completion using subgraph feature extraction. In Proceedings of the Conference Proceedings—EMNLP 2015: Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1488–1498.
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems, Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013.
- Sheehan, E.; Meng, C.; Tan, M.; Uzkent, B.; Jean, N.; Burke, M.; Lobell, D.; Ermon, S. Predicting economic development using geolocated wikipedia articles. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2698–2706.
- Brailas, A.; Koskinas, K.; Dafermos, M.; Alexias, G. Wikipedia in Education: Acculturation and learning in virtual communities. Learn. Cult. Soc. Interact. 2015, 7, 59–70.
- Schwenk, H.; Chaudhary, V.; Sun, S.; Gong, H.; Guzmán, F. WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 1351–1361.
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Deep Learning applications for COVID-19. J. Big Data 2021, 8, 1–54.
- Stammbach, D. Evidence Selection as a Token-Level Prediction Task. In Proceedings of the FEVER 2021—Fact Extraction and VERification, Proceedings of the 4th Workshop, Online, 10 November 2021; pp. 14–20.
- Wadden, D.; Lin, S.; Lo, K.; Wang, L.L.; van Zuylen, M.; Cohan, A.; Hajishirzi, H. Fact or Fiction: Verifying Scientific Claims. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 7534–7550.
- Hanselowski, A.; Stab, C.; Schulz, C.; Li, Z.; Gurevych, I. A richly annotated corpus for different tasks in automated fact-checking. In Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL), Hong Kong, China, 3–4 November 2019; pp. 493–503.
More