Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Rita Xu and Version 1 by Leah Mutanu.
The last two years have seen a rapid rise in the duration of time that both adults and children spend on screens, driven by the recent COVID-19 health pandemic. A key adverse effect is digital eye strain (DES). Recent trends in human-computer interaction and user experience have proposed voice or gesture-guided designs that present more effective and less intrusive automated solutions. These approaches inspired the design of a solution that uses facial expression recognition (FER) techniques to detect DES and autonomously adapt the application to enhance the user’s experience.
- digital eye strain
- facial expression recognition
- software self-adaptation
1. Introduction
Globally, media outlets have highlighted the increased duration of time that adults and children are spending on digital screens. For example, in the United Kingdom, it was reported that people spend up to three and a half hours each day looking at TV screens, four hours staring at laptops, and two hours on mobile phones [1]. This figure almost doubled when stay-at-home measures were enforced due to the COVID-19 health pandemic, with adults spending an average of six and a half hours each day in front of a screen [2,3][2][3]. The average American teen spends 7 h and 22 min on a screen outside of their regular schoolwork [4]. Today many learning and work-related activities have gone online, forcing people to spend more and more time on the screen. Staring at your screen for long hours each day can often result in dry eyes or eye strain, gradually contributing to permanent eye problems such as Myopia [3].
The increased internet use for research requires users to navigate through web pages designed using different fonts, font sizes, font colors, and background colors. These websites do not always meet the basic requirements for visual ergonomics. The online eLearning trend requires teachers to post materials on learning management systems (LMS) without paying much attention to the content’s appearance. Content developers use their discretion to identify fonts and backgrounds. This freedom often leads to the publishing of content that is difficult to read, even for users with no visual disabilities. As a user navigates through online content, the difference in content presentation introduces temporary visual challenges. Users strain their eyes as they try to adjust to different display settings. Similarly, the user’s environment can temporarily influence their ability to read the information on a screen, for example, where the lighting in a room is poor or in a scenario where the screen is too close or too far.
A popular approach for ensuring that technology addresses user disabilities is assistive technologies, which calls for specialized products that aim at partly compensating for the loss of autonomy experienced by disabled users. Here the user is required to acquire new technology or adapt existing technology using available tools before using the technology. Where user requirements are not known a priori or dynamically change, the approach is ineffective because it forces redeployment or reconstruction of the system [5]. Additionally, the degree of disabilities varies widely in severity, and often mild or undiagnosed disabilities go unsupported. Further, persons with mild disabilities tend to shun assistive technology because it underlines the disability, is associated with dependence, and degrades the user’s image [6], thus impairing social acceptance. The net result is that many users have become accustomed to squinting or glaring their eyes to change the focus of items on the screen. Some users will move closer or further from the screen depending on whether they are myopic or hyperopic. In such cases, the burden of adapting to the technology resides with the user’s behavior. This approach can present further health challenges to the user, such as damaging their posture.
2. Facial Expression Recognition
Recent advances in image-recognition algorithms have made it possible to detect facial expressions such as happiness, sadness, anger, or fear [13[7][8],14], with several reviews also touching on the subject [15,16][9][10]. Such initiatives find applications in detecting consumer satisfaction of a product [17,18,19][11][12][13] or in healthcare to diagnose certain health issues [20,21][14][15] such as autism or stroke. Recently, FER has found applications in detecting fatigue, which can be dangerous, especially for drivers [22,23,24][16][17][18]. One of the few studies identified used the blink rate and sclera area color to detect DES using a raspberry-pi camera [25][19]. The research, however, noted poor results with certain skin tones or where limited light-intensity difference between the sclera and skin region existed. Additionally, users with spectacles also generated reflections that interfered with color detection. Therefore, an approach that does not rely on color would address these limitations. Eye tracking is increasingly becoming one of the most used sensor modalities in affective computing recently for monitoring fatigue. The eye tracker for such experiments also detects additional information, such as blink frequency and pupil diameter changes [26][20]. A typical eye tracker (such as video-oculography) consists of a video camera that records the movements of the eyes and a computer that saves and analyzes the gaze data [27][21]. The monitoring of fatigue using this approach differs from the monitoring of basic facial emotions (anger, contempt, disgust, fear, happiness, sadness, surprise) because specific facial points are monitored, such as the percentage eye closure (PERCLOS), head nodding, head orientation, eye blink rate, eye gaze direction, saccadic movement, or eye color. However, fatigue is expressed using a combination of other facial expressions, such as yawning or hands on the face.3. Machine Learning Techniques for FER
Recent studies on facial expression recognition [28][22] acknowledge that machine learning plays a big role in automated facial expression recognition, with deep learning algorithms achieving state-of-the-art performance for a variety of FER.3.1. FER Datasets
Studies using relatively limited datasets are constrained by poor representation of certain facial expressions, age groups, or ethnic backgrounds. To address this, the authors in [29][23] recommend using large datasets. In their review of FER studies, they note that the Cohn–Kanade AU-Coded Face Expression Database (Cohn–Kanade) [30][24] is the most used database for FER. A more recent review [15][9] introduced newer datasets such as the Extended Cohn–Kanade (CK+) [31][25] database, which they noted was still the most extensively used laboratory-controlled database for evaluating FER systems. It has 593 images compared to the original version, which only had 210 images. Another notable dataset introduced was the FER2013 [32][26], a large-scale and unconstrained database collected automatically by the Google image search API. The dataset contains 35,887 images extracted from real-life scenarios. The review [15][9] noted that data bias and inconsistent annotations are common in different facial expression datasets due to different collecting conditions and the subjectiveness of annotating. Because researchers evaluate algorithms using specific datasets, the same results cannot be replicated with unseen test data. Therefore, using a large dataset on its own is not sufficient. It is helpful to merge data from several datasets to ensure generalizability. Additionally, when some datasets exhibit class imbalance, the class balance should be addressed during preprocessing by augmenting the data with data from other datasets. These findings motivated ouresearchers' decision to use more than one dataset as well as the use of large datasets. WeResearchers used images from the CK+ and FER2013 datasets and conducted class balancing during preprocessing. Notably, most FER datasets had images labeled using the seven basic emotions (disgust, fear, joy, surprise, sadness, anger, and neutral). Therefore, preprocessing this study’s data called for re-labeling the images to represent digital eye strain expressions such as squint, glare, and fatigue. This exercise called for manually reviewing the images and identifying those that fell in each class. WeResearchers assigned the images a new label representing the digital eye strain expressions. For instance, fatigue was labeled 1, whereas glare was labeled 2. To do this, the original images were rebuilt from the FER2013 dataset of pixels to enable the researchers to see the expressions. Once the labeling process was complete, a new dataset of pixels was generated with the new labels. By automatically detecting these facial expressions and autonomously adjusting font sizes or screen contrast, the user does not need to glare or squint to accommodate the screen settings. This also creates awareness for the user when an alert occurs, and they can take a break to address fatigue.3.2. Image Processing and Feature Extraction
Image processing refers to the enhancement of pictures for ease of interpretation [33][27]. Common image processing activities include adjusting pixel values, image colors, and binarizing [34][28]. Several image-processing libraries that support these processes exist, such as OpenCV [35][29] and scikit-image [36][30]. They easily integrate with popular open-source machine-learning tools such as Python and R. After the image is preprocessed, feature extraction reduces the initial set of raw image data to more manageable sizes for classification purposes. Previous FER reviews [37][31] describe action unit (AU) and facial points (FP) analysis as two key methods used for feature extraction of classic facial emotion. Action units find applications when analyzing the entire face.3.3. FER Algorithms
When our eyes squint, several things occur: the pupils get smaller as they converge, the eyelids pull together, and the edges of the eyelids fold to contract the cornea [9][32]. Sometimes the eyebrows could bend inwards, and the nose bridge moves upwards to enhance the eyes’ focus. FER techniques can detect these expressions and alert the user or adjust text sizes and color contrasts in an application to relieve eye strain. The FER process generally involves the acquisition of a facial image, extracting features useful in detecting the expression, and analyzing the image to recognize the expression [29][23]. Machine learning algorithms such as deep learning neural network algorithms successfully perform FER. A popular algorithm, according to recent FER reviews [15[9][10],16], is the convolutional neural network (CNN), which achieves better accuracy with big data [38][33]. It has better effects on feature extraction than deep belief networks, especially for expressions of classic emotions such as contempt, fear, and sadness [15][9]. The results of these studies inspired the choice of CNN as the algorithm for implementing FER in this study [5][5]. However, it is worth noting that these results depend on the specific dataset used. For instance, the models that yielded the best accuracy in the FER2013 dataset are Ensemble CNNs with an accuracy of 76.82% [32][26], Local learning Deep+BOW with an accuracy of 75.42% [39][34], and LHC-Net with an accuracy of 74.42% [40][35]. The models that yielded the best accuracy in the CK+ dataset include ViT + SE with an accuracy of 99.8% [41][36], FAN with an accuracy of 99.7% [42][37], and Nonlinear eval on SL + SSL puzzling with an accuracy of 98.23% [43][38]. Sequential forward selection yielded the best accuracy on the CK dataset, with 88.7% accuracy [44][39]. The highest performing models on the AffectNet dataset are EmotionGCN with an accuracy of 66.46% [45][40], EmoAffectNet with an accuracy of 66.36 [46][41], and Multi-task EfficientNet-B2 with an accuracy of 66.29% [47][42]. Although numerous datasets exist for facial expression recognition, this study sought to detect expressions outside of the classic emotions. The absence of labeled datasets in this area called for relabeling of images. The choice of the dataset for relabeling the images was not crucial. Future research should seek to relabel images from larger datasets such as AffectNet. With CNN, deeper networks with a larger width, depth, or resolution tend to achieve higher accuracy, but the accuracy gain quickly saturates [48][43]. Adding dropout layers increases accuracy by preventing weights from converging at the same position. The key idea is randomly dropping units (along with their connections) from the neural network during training. This prevents units from co-adapting too much [49][44]. Adding batch normalization layers increases the test accuracy by normalizing the network input weights between 0 and 1 to address the internal covariate shift that occurs when inputs change during training [50][45]. Pooling layers included in models decrease each frame’s spatial size, reducing the computational cost of deep learning frameworks. The pooling operation usually picks the maximum value for each slice of the image [51][46]. A summary of this process is depicted in Figure 1.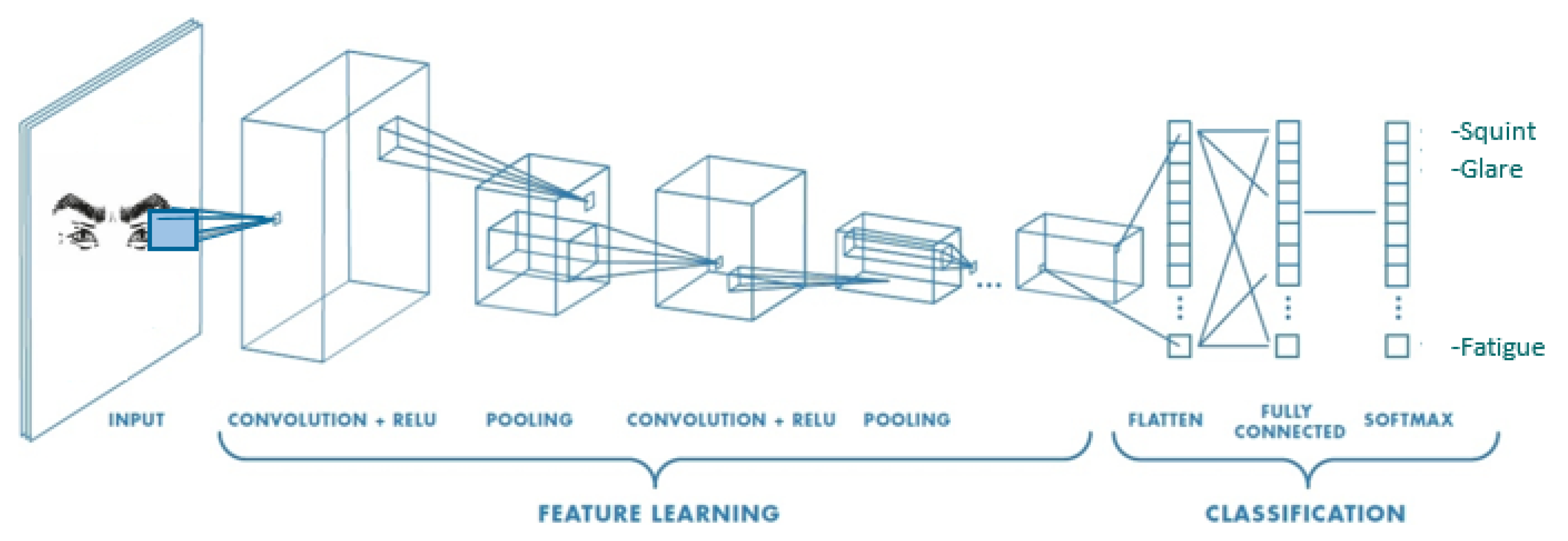
Figure 1. Distribution of facial expressions.
References
- Elsworthy, E. Average Adult Will Spend 34 Years of Their Life Looking at Screens, Poll Claims. Independent 2020. Available online: https://www.independent.co.uk/life-style/fashion/news/screen-time-average-lifetime-years-phone-laptop-tv-a9508751.html (accessed on 10 March 2023).
- Nugent, A. UK adults spend 40% of their waking hours in front of a screen. Independent 2020.
- Bhattacharya, S.; Saleem, S.M.; Singh, A. Digital eye strain in the era of COVID-19 pandemic: An emerging public health threat. Indian J. Ophthalmol. 2020, 68, 1709.
- Siegel, R. Tweens, Teens and Screens: The Average Time Kids Spend Watching Online Videos Has Doubled in 4 Years. The Washington Post, 29 October 2019.
- Hussain, J.; Ul Hassan, A.; Muhammad Bilal, H.S.; Ali, R.; Afzal, M.; Hussain, S.; Bang, J.; Banos, O.; Lee, S. Model-based adaptive user interface based on context and user experience evaluation. J. Multimodal User Interfaces 2018, 12, 1–16.
- Plos, O.; Buisine, S.; Aoussat, A.; Mantelet, F.; Dumas, C. A Universalist strategy for the design of Assistive Technology. Int. J. Ind. Ergon. 2012, 42, 533–541.
- Dachapally, P.R. Facial emotion detection using convolutional neural networks and representational autoencoder units. arXiv 2017, arXiv:1706.01509.
- Joseph, A.; Geetha, P. Facial emotion detection using modified eyemap–mouthmap algorithm on an enhanced image and classification with tensorflow. Vis. Comput. 2020, 36, 529–539.
- Li, K.; Jin, Y.; Akram, M.W.; Han, R.; Chen, J. Facial expression recognition with convolutional neural networks via a new face cropping and rotation strategy. Vis. Comput. 2020, 36, 391–404.
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial expression recognition: A survey. Symmetry 2019, 11, 1189.
- González-Rodríguez, M.R.; Díaz-Fernández, M.C.; Gómez, C.P. Facial-expression recognition: An emergent approach to the measurement of tourist satisfaction through emotions. Telemat. Inform. 2020, 51, 101404.
- Generosi, A.; Ceccacci, S.; Mengoni, M. A deep learning-based system to track and analyze customer behavior in retail store. In Proceedings of the 2018 IEEE 8th International Conference on Consumer Electronics-Berlin (ICCE-Berlin), Berlin, Germany, 2–5 September 2018; pp. 1–6.
- Bouzakraoui, M.S.; Sadiq, A.; Enneya, N. Towards a framework for customer emotion detection. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–6.
- Baggio, H.C.; Segura, B.; Ibarretxe-Bilbao, N.; Valldeoriola, F.; Marti, M.; Compta, Y.; Tolosa, E.; Junqué, C. Structural correlates of facial emotion recognition deficits in Parkinson’s disease patients. Neuropsychologia 2012, 50, 2121–2128.
- Norton, D.; McBain, R.; Holt, D.J.; Ongur, D.; Chen, Y. Association of impaired facial affect recognition with basic facial and visual processing deficits in schizophrenia. Biol. Psychiatry 2009, 65, 1094–1098.
- Khan, S.A.; Hussain, S.; Xiaoming, S.; Yang, S. An effective framework for driver fatigue recognition based on intelligent facial expressions analysis. IEEE Access 2018, 6, 67459–67468.
- Xiao, Z.; Hu, Z.; Geng, L.; Zhang, F.; Wu, J.; Li, Y. Fatigue driving recognition network: Fatigue driving recognition via convolutional neural network and long short-term memory units. IET Intell. Transp. Syst. 2019, 13, 1410–1416.
- Munasinghe, M. Facial expression recognition using facial landmarks and random forest classifier. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 423–427.
- Reddy, A.P.C.; Sandilya, B.; Annis Fathima, A. Detection of eye strain through blink rate and sclera area using raspberry-pi. Imaging Sci. J. 2019, 67, 90–99.
- Lim, J.Z.; Mountstephens, J.; Teo, J. Emotion recognition using eye-tracking: Taxonomy, review and current challenges. Sensors 2020, 20, 2384.
- Klaib, A.F.; Alsrehin, N.O.; Melhem, W.Y.; Bashtawi, H.O.; Magableh, A.A. Eye tracking algorithms, techniques, tools, and applications with an emphasis on machine learning and Internet of Things technologies. Expert Syst. Appl. 2021, 166, 114037.
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215.
- Tian, Y.; Kanade, T.; Cohn, J. Handbook of Face Recognition; Li, S.Z., Jain, A.K., Eds.; Springer: London, UK, 2011.
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the fourth IEEE International Conference on Automatic Face and Gesture Recognition (cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 46–53.
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101.
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the Neural Information Processing: 20th International Conference, ICONIP 2013, Daegu, Korea, 3–7 November 2013; Proceedings, Part III 20. Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124.
- Petrou, M.M.; Petrou, C. Image Processing: The Fundamentals; John Wiley & Sons: Hoboken, NJ, USA, 2010.
- Russ, J.C. The Image Processing Handbook; CRC Press: Boca Raton, FL, USA, 2006.
- Joshi, P. OpenCV with Python by Example; Packt Publishing Ltd.: Birmingham, UK, 2015.
- Van der Walt, S.; Schönberger, J.L.; Nunez-Iglesias, J.; Boulogne, F.; Warner, J.D.; Yager, N.; Gouillart, E.; Yu, T. scikit-image: Image processing in Python. PeerJ 2014, 2, e453.
- Liliana, D.Y.; Basaruddin, T. Review of automatic emotion recognition through facial expression analysis. In Proceedings of the 2018 International Conference on Electrical Engineering and Computer Science (ICECOS), Pangkal, Indonesia, 2–4 October 2018; pp. 231–236.
- Sheedy, J.E. The physiology of eyestrain. J. Mod. Opt. 2007, 54, 1333–1341.
- Lopes, A.T.; De Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628.
- Georgescu, M.I.; Ionescu, R.T.; Popescu, M. Local learning with deep and handcrafted features for facial expression recognition. IEEE Access 2019, 7, 64827–64836.
- Pecoraro, R.; Basile, V.; Bono, V. Local multi-head channel self-attention for facial expression recognition. Information 2022, 13, 419.
- Aouayeb, M.; Hamidouche, W.; Soladie, C.; Kpalma, K.; Seguier, R. Learning vision transformer with squeeze and excitation for facial expression recognition. arXiv 2021, arXiv:2107.03107.
- Meng, D.; Peng, X.; Wang, K.; Qiao, Y. Frame attention networks for facial expression recognition in videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3866–3870.
- Pourmirzaei, M.; Montazer, G.A.; Esmaili, F. Using self-supervised auxiliary tasks to improve fine-grained facial representation. arXiv 2021, arXiv:2105.06421.
- Gacav, C.; Benligiray, B.; Topal, C. Greedy search for descriptive spatial face features. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 1497–1501.
- Antoniadis, P.; Filntisis, P.P.; Maragos, P. Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition. In Proceedings of the 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), Jodhpur, India, 15–18 December 2021; Available online: http://xxx.lanl.gov/abs/2106.03487 (accessed on 12 January 2023).
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450.
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143.
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 15 June 2019; pp. 6105–6114.
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958.
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456.
- Minhas, R.A.; Javed, A.; Irtaza, A.; Mahmood, M.T.; Joo, Y.B. Shot classification of field sports videos using AlexNet Convolutional Neural Network. Appl. Sci. 2019, 9, 483.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90.
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778.
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734.
- Chen, X.; Xie, L.; Wu, J.; Tian, Q. Progressive darts: Bridging the optimization gap for nas in the wild. Int. J. Comput. Vis. 2021, 129, 638–655.
- Al-Sabaawi, A.; Ibrahim, H.M.; Arkah, Z.M.; Al-Amidie, M.; Alzubaidi, L. Amended convolutional neural network with global average pooling for image classification. In Intelligent Systems Design and Applications. ISDA 2020. Advances in Intelligent Systems and Computing; Abraham, A., Piuri, V., Gandhi, N., Siarry, P., Kaklauskas, A., Madureira, A., Eds.; Springer: Cham, Switzerland, 2020; Volume 1351, pp. 171–180.
- Liu, D.; Liu, Y.; Dong, L. G-ResNet: Improved ResNet for brain tumor classification. In Neural Information Processing. ICONIP 2019. Lecture Notes in Computer Science; Gedeon, T., Wong, K., Lee, M., Eds.; Springer: Cham, Switzerland, 2019; Volume 11953, pp. 535–545.
More