Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Rita Xu and Version 1 by Songyuan Li.
Recent approaches for fast semantic video segmentation have reduced redundancy by warping feature maps across adjacent frames, greatly speeding up the inference phase. Researchers build a non-key-frame CNN, fusing warped context features with current spatial details. Based on the feature fusion, ourthe context feature rectification (CFR) module learns the model’s difference from a per-frame model to correct the warped features.
- semantic video segmentation
- warping
1. Introduction
Semantic video segmentation, an important task in the field of computer vision, aims to predict pixel-wise class labels for each frame in a video. It has been widely used for a variety of applications, e.g., autonomous driving [1], robot navigation [2], and video surveillance [3]. Since the seminal work of fully convolutional networks (FCNs) [4] was proposed, the accuracy of semantic segmentation has been significantly improved [5,6,7][5][6][7]. However, the computational cost and memory footprint of these high-quality methods are usually impractical to deploy in the aforementioned real-world applications, where only limited computational resources are available. Therefore, a fast solution to this dense prediction task is challenging and attracting more and more interest.
Prevailing fast methods for semantic video segmentation can be grouped into two major categories: per-frame and warping-based. Per-frame methods treat the video task as a stream of mutually independent image tasks and performs it frame by frame. This line of work takes several approaches to trade off accuracy for speed.
- (1)
- (2)
- (3)
In general, per-frame methods adapt image models to video models with ease but do not utilize the inherent coherence of video frames.
In light of the visual continuity between adjacent video frames, warping-based methods [30,31,32,33,34][30][31][32][33][34] employ inter-frame motion estimation [31,33,34][31][33][34] to reduce temporal redundancy. Technically, this line of work treats a video clip as sequential groups of frames. Each group of frames consists of a key frame followed by multiple non-key frames. When the coming frame is a key frame, the warping-based model performs image segmentation as usual; otherwise, the model keeps the results of the preceding frame, warps the preceding results with the help of motion estimation, and uses the warped results as the results of the current frame. Since the warping operation is much faster than the inference of a CNN, the inference speed can be boosted significantly.
In spite of achieving fast speed, warping-based methods suffer a sharp drop in accuracy due to warping itself. As shown in Figure 1a, non-rigid moving objects such as walking people can change their shapes dramatically during walking. It is so difficult to estimate their motions that these objects become severely deformed after several non-key frames. Figure 1b shows a car occupying the central space at the beginning key frame (t = 0), but as the car moves to the right, another car, which was occluded at the key frame, appears at the later non-key frames. In this case, it is impossible to obtain the originally occluded car at later non-key frames by warping. Based on the above observations, the motion estimation that warping uses inevitably introduces errors, and errors accumulate along succeeding non-key frames, making the results almost unusable. Warping turns out to behave like a runaway fierce creature; the key to the issue is to tame it—to take advantage of its acceleration and to keep it under control.
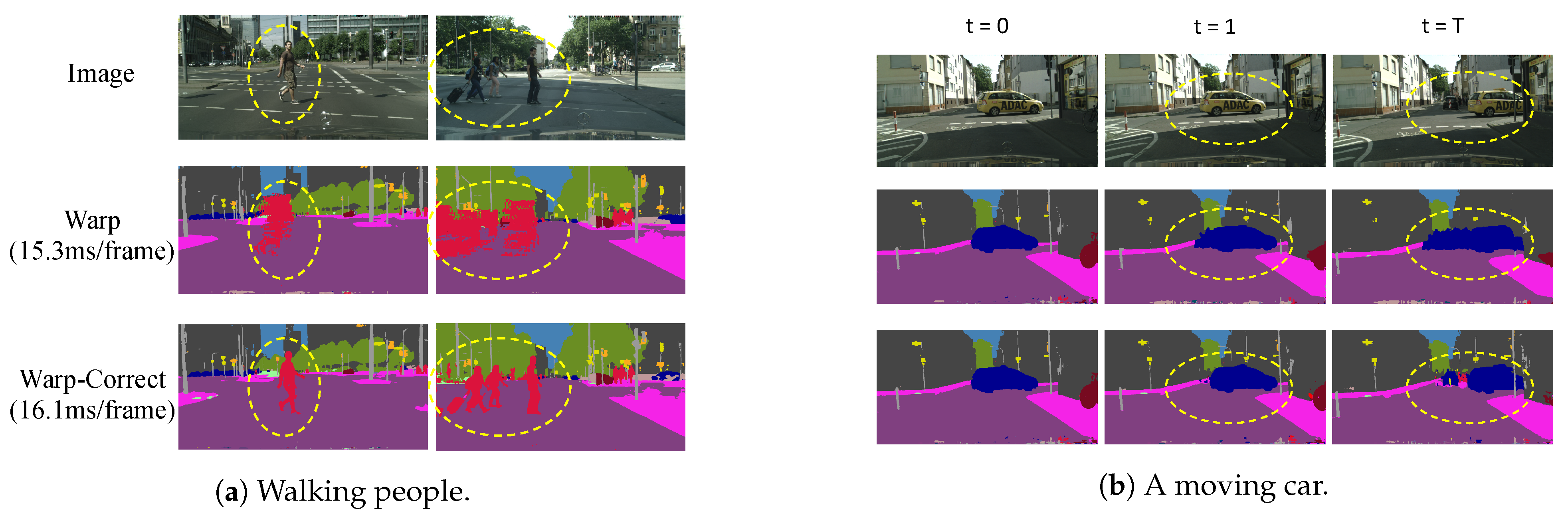
Figure 1. Comparison between warping only and warping with correction. (a) The walking people’s limbs can be occluded by their own bodies a few frames prior but appear later, thus becoming severely deformed in later warped frames. (b) A moving car occludes distant objects that cannot be warped from previous frames. By adding a correction stage, errors can be significantly alleviated.
To this end, wresearchers propose a novel “warp-and-correct” fast framework called the tamed warping network (TWNet) for high-resolution semantic video segmentation, adding a correction stage after warping. The “warp-and-correct” idea is the basic mechanism used in the compressed domain, where video codecs warp frames by motion vectors and correct small differences by residuals. Inspired by this, weresearchers propose to learn the residuals in the feature space. Technically, TWNet contains two core models: a key frame CNN (KFC) and a non-key-frame CNN (NKFC). KFC processes key frames in the same way as per-frame models do except that KFC also sends the features of the current key frame to the next frame (a non-key frame). NKFC extracts spatial features of the current non-key frame and warps context features from the preceding frame. Then, these features are fed into our two correction modules, context feature rectification (CFR) and residual-guided attention (RGA). CFR fuses warped context features with the spatial details of the current frame to learn feature space residuals under the guidance of KFC. Furthermore, RGA utilizes the compressed-domain residuals to correct features learned from CFR. At the end, the corrected features are also sent to the next non-key frame. Experiments show that TWNet is generic to backbone choices and significantly increases the mIoU of the baseline from to . For non-rigid categories, such as human, the improvements are even higher than 18 percentage points, which is important for the safety of autonomous driving.
2. Per-Frame Semantic Video Segmentation
Technically, most per-frame methods adopt either the encoder–decoder architecture or the two-pathway architecture. The encoder–decoder architecture features repeated down-sampling in the encoder, which reduces the computational cost significantly [19,27,40,41,42][19][27][35][36][37]. Although ourthe method is a warping-based method instead of a per-frame method, weresearchers also adopt the encoder–decoder architecture. The decoder of the encoder–decoder architecture is responsible for restoring the spatial information but the down-sampling makes it difficult. To deal with the problem, the two-pathway architecture has a deep pathway to extract high-level features and a shallow pathway to extract low-level features. The combination of features from different levels improves the accuracy [10,43,44,45,46][10][38][39][40][41]. Feature fusion in ourthe proposed non-key-frame CNN (NKFC) is similar to those in [35,47,48][42][43][44], where lateral connections are used to fuse the low-level (spatial) and high-level (context) features. In comparison, ourthe NKFC only retains a few layers of the encoder to extract low-level features and obtains high-level features by feature warping. Thus, NKFC saves the heavy computations of context feature extraction.3. Warping-Based Semantic Video Segmentation
Researchers have proposed many warping-based approaches [30,31,33,34][30][31][33][34]. Some works adopt warping as a temporal constraint to enhance features for the sake of accuracy [23,25,30][23][25][30]. For acceleration, Zhu et al. [34], Xu et al. [33], and Jain et al. [31] proposed to use feature warping to speed up their models. They divided frames into two types: key frames and non-key frames. Key frames are sent to the CNN for segmentation, while non-key frame results are obtained by warping. Recently, Hu et al. [25] proposed to approximate high-level features by composing features from several shallower layers. These approaches speed up the inference phase since the computational cost of warping is much less than that of CNN. However, both the accuracy and robustness of these methods deteriorate due to the following reasons. First, neither optical flows nor motion vectors can estimate the precise motion of all pixels. There always exist unavoidable biases (errors) between the warped features and the expected ones. Second, in the case of consecutive non-key frames, cumulative errors lead to unusable results. To address error accumulation, Li et al. [32] and Xu et al. [33] proposed to adaptively select key frames by predicting the confidence score for each frame. Jain et al. [31] introduced bi-directional features warping to improve accuracy. However, all these approaches lack the ability to correct warped features.References
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223.
- Bovcon, B.; Perš, J.; Perš, J.; Kristan, M. Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation. Robot. Auton. Syst. 2018, 104, 1–13.
- Zeng, D.; Chen, X.; Zhu, M.; Goesele, M.; Kuijper, A. Background subtraction with real-time semantic segmentation. IEEE Access 2019, 7, 153869–153884.
- Long, J.; Shelhamer, E.; Darrell, T. fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440.
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890.
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587.
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. encoder–decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder–decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495.
- Li, H.; Xiong, P.; Fan, H.; Sun, J. DFANet: Deep feature aggregation for real-time semantic segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 9522–9531.
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 325–341.
- Li, G.; Li, L.; Zhang, J. BiAttnNet: Bilateral Attention for Improving Real-Time Semantic Segmentation. IEEE Signal Process. Lett. 2022, 29, 46–50.
- Li, Y.; Li, X.; Xiao, C.; Li, H.; Zhang, W. EACNet: Enhanced Asymmetric Convolution for Real-Time Semantic Segmentation. IEEE Signal Process. Lett. 2021, 28, 234–238.
- Zhang, X.; Du, B.; Wu, Z.; Wan, T. LAANet: Lightweight attention-guided asymmetric network for real-time semantic segmentation. Neural Comput. Appl. 2022, 34, 3573–3587.
- Zhang, X.L.; Du, B.C.; Luo, Z.C.; Ma, K. Lightweight and efficient asymmetric network design for real-time semantic segmentation. Appl. Intell. 2022, 52, 564–579.
- Hu, X.; Jing, L.; Sehar, U. Joint pyramid attention network for real-time semantic segmentation of urban scenes. Appl. Intell. 2022, 52, 580–594.
- Fan, J.; Wang, F.; Chu, H.; Hu, X.; Cheng, Y.; Gao, B. MLFNet: Multi-Level Fusion Network for Real-Time Semantic Segmentation of Autonomous Driving. IEEE Trans. Intell. Veh. 2022, 8, 756–767.
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861.
- Li, X.; Zhou, Y.; Pan, Z.; Feng, J. Partial order pruning: For best speed/accuracy trade-off in neural architecture search. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 9145–9153.
- Orsic, M.; Kreso, I.; Bevandic, P.; Segvic, S. In Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 12607–12616.
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520.
- Zhang, Y.; Qiu, Z.; Liu, J.; Yao, T.; Liu, D.; Mei, T. Customizable Architecture Search for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019; pp. 11641–11650.
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for real-time semantic segmentation on high-resolution images. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 405–420.
- Liu, Y.; Shen, C.; Yu, C.; Wang, J. Efficient semantic video segmentation with per-frame inference. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 352–368.
- Xiao, C.; Hao, X.; Li, H.; Li, Y.; Zhang, W. Real-time semantic segmentation with local spatial pixel adjustment. Image Vis. Comput. 2022, 123, 104470.
- Hu, P.; Caba, F.; Wang, O.; Lin, Z.; Sclaroff, S.; Perazzi, F. Temporally Distributed Networks for Fast Video Semantic Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8818–8827.
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147.
- Romera, E.; Alvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 2017, 19, 263–272.
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856.
- Li, G.; Yun, I.; Kim, J.; Kim, J. Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. arXiv 2019, arXiv:1907.11357.
- Gadde, R.; Jampani, V.; Gehler, P.V. Semantic video cnns through representation warping. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4453–4462.
- Jain, S.; Gonzalez, J.E. Fast Semantic Segmentation on Video Using Block Motion-Based Feature Interpolation. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–6.
- Li, Y.; Shi, J.; Lin, D. Low-latency video semantic segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5997–6005.
- Xu, Y.S.; Fu, T.J.; Yang, H.K.; Lee, C.Y. Dynamic video segmentation network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6556–6565.
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358.
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 552–568.
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.; Saenko, K.; Sclaroff, S. Real-time semantic segmentation with fast attention. IEEE Robot. Autom. Lett. 2020, 6, 263–270.
- Li, X.; You, A.; Zhu, Z.; Zhao, H.; Yang, M.; Yang, K.; Tan, S.; Tong, Y. Semantic flow for fast and accurate scene parsing. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 775–793.
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068.
- Poudel, R.P.; Liwicki, S.; Cipolla, R. Fast-scnn: Fast semantic segmentation network. arXiv 2019, arXiv:1902.04502.
- Kumaar, S.; Lyu, Y.; Nex, F.; Yang, M.Y. Cabinet: Efficient context aggregation network for low-latency semantic segmentation. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13517–13524.
- Pan, H.; Hong, Y.; Sun, W.; Jia, Y. Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes. IEEE Trans. Intell. Transp. Syst. 2022, 24, 3448–3460.
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241.
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125.
- Lin, D.; Li, Y.; Nwe, T.L.; Dong, S.; Oo, Z.M. RefineU-Net: Improved U-Net with progressive global feedbacks and residual attention guided local refinement for medical image segmentation. Pattern Recognit. Lett. 2020, 138, 267–275.
More