Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Songyuan Li and Version 2 by Rita Xu.
Recent approaches for fast semantic video segmentation have reduced redundancy by warping feature maps across adjacent frames, greatly speeding up the inference phase. Researchers build a non-key-frame CNN, fusing warped context features with current spatial details. Based on the feature fusion, theour context feature rectification (CFR) module learns the model’s difference from a per-frame model to correct the warped features.
- semantic video segmentation
- warping
1. Introduction
Semantic video segmentation, an important task in the field of computer vision, aims to predict pixel-wise class labels for each frame in a video. It has been widely used for a variety of applications, e.g., autonomous driving [1], robot navigation [2], and video surveillance [3]. Since the seminal work of fully convolutional networks (FCNs) [4] was proposed, the accuracy of semantic segmentation has been significantly improved [5][6][7][5,6,7]. However, the computational cost and memory footprint of these high-quality methods are usually impractical to deploy in the aforementioned real-world applications, where only limited computational resources are available. Therefore, a fast solution to this dense prediction task is challenging and attracting more and more interest.
Prevailing fast methods for semantic video segmentation can be grouped into two major categories: per-frame and warping-based. Per-frame methods treat the video task as a stream of mutually independent image tasks and performs it frame by frame. This line of work takes several approaches to trade off accuracy for speed.
- (1)
- (2)
- (3)
In general, per-frame methods adapt image models to video models with ease but do not utilize the inherent coherence of video frames.
In light of the visual continuity between adjacent video frames, warping-based methods [30][31][32][33][34][30,31,32,33,34] employ inter-frame motion estimation [31][33][34][31,33,34] to reduce temporal redundancy. Technically, this line of work treats a video clip as sequential groups of frames. Each group of frames consists of a key frame followed by multiple non-key frames. When the coming frame is a key frame, the warping-based model performs image segmentation as usual; otherwise, the model keeps the results of the preceding frame, warps the preceding results with the help of motion estimation, and uses the warped results as the results of the current frame. Since the warping operation is much faster than the inference of a CNN, the inference speed can be boosted significantly.
In spite of achieving fast speed, warping-based methods suffer a sharp drop in accuracy due to warping itself. As shown in Figure 1a, non-rigid moving objects such as walking people can change their shapes dramatically during walking. It is so difficult to estimate their motions that these objects become severely deformed after several non-key frames. Figure 1b shows a car occupying the central space at the beginning key frame (t = 0), but as the car moves to the right, another car, which was occluded at the key frame, appears at the later non-key frames. In this case, it is impossible to obtain the originally occluded car at later non-key frames by warping. Based on the above observations, the motion estimation that warping uses inevitably introduces errors, and errors accumulate along succeeding non-key frames, making the results almost unusable. Warping turns out to behave like a runaway fierce creature; the key to the issue is to tame it—to take advantage of its acceleration and to keep it under control.
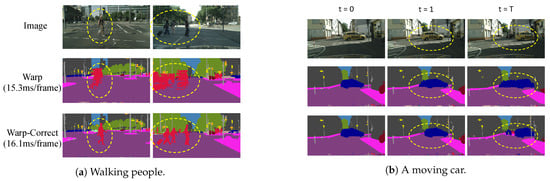
Figure 1. Comparison between warping only and warping with correction. (a) The walking people’s limbs can be occluded by their own bodies a few frames prior but appear later, thus becoming severely deformed in later warped frames. (b) A moving car occludes distant objects that cannot be warped from previous frames. By adding a correction stage, errors can be significantly alleviated.
To this end, rwesearchers propose a novel “warp-and-correct” fast framework called the tamed warping network (TWNet) for high-resolution semantic video segmentation, adding a correction stage after warping. The “warp-and-correct” idea is the basic mechanism used in the compressed domain, where video codecs warp frames by motion vectors and correct small differences by residuals. Inspired by this, researcherswe propose to learn the residuals in the feature space. Technically, TWNet contains two core models: a key frame CNN (KFC) and a non-key-frame CNN (NKFC). KFC processes key frames in the same way as per-frame models do except that KFC also sends the features of the current key frame to the next frame (a non-key frame). NKFC extracts spatial features of the current non-key frame and warps context features from the preceding frame. Then, these features are fed into our two correction modules, context feature rectification (CFR) and residual-guided attention (RGA). CFR fuses warped context features with the spatial details of the current frame to learn feature space residuals under the guidance of KFC. Furthermore, RGA utilizes the compressed-domain residuals to correct features learned from CFR. At the end, the corrected features are also sent to the next non-key frame. Experiments show that TWNet is generic to backbone choices and significantly increases the mIoU of the baseline from to . For non-rigid categories, such as human, the improvements are even higher than 18 percentage points, which is important for the safety of autonomous driving.