Utilizing machine learning (ML) based methodologies for Network Intrusion Detection Systems (NIDSs) engenders valid concerns, primarily stemming from the inherent vulnerabilities of current ML models to various security threats. Predominantly, our focus centers on two paramount threats intrinsic to ML-based NIDS: adversarial attacks and distribution shifts. We advocate for the comprehensive establishment and sustained maintenance of the robustness of ML-based NIDS throughout its entire lifecycle, enabling it to effectively adress unforeseen exigenciets.
- network intrusion detection systems
- robustness
- machine learning
1. Introduction
2. Vulnerabilities of Machine Learning for Network Security
2.1. The Concepts Related to ML Robustness
Robustness is a term that has become encompassed in a spectrum of interpretations and even overloaded [14]. For instance, robustness encompasses a wide range of aspects, including but not limited to raw task performance on test sets, the ability to sustain task performance on manipulated or modified inputs, generalization within and across domains, and resilience against adversarial attacks.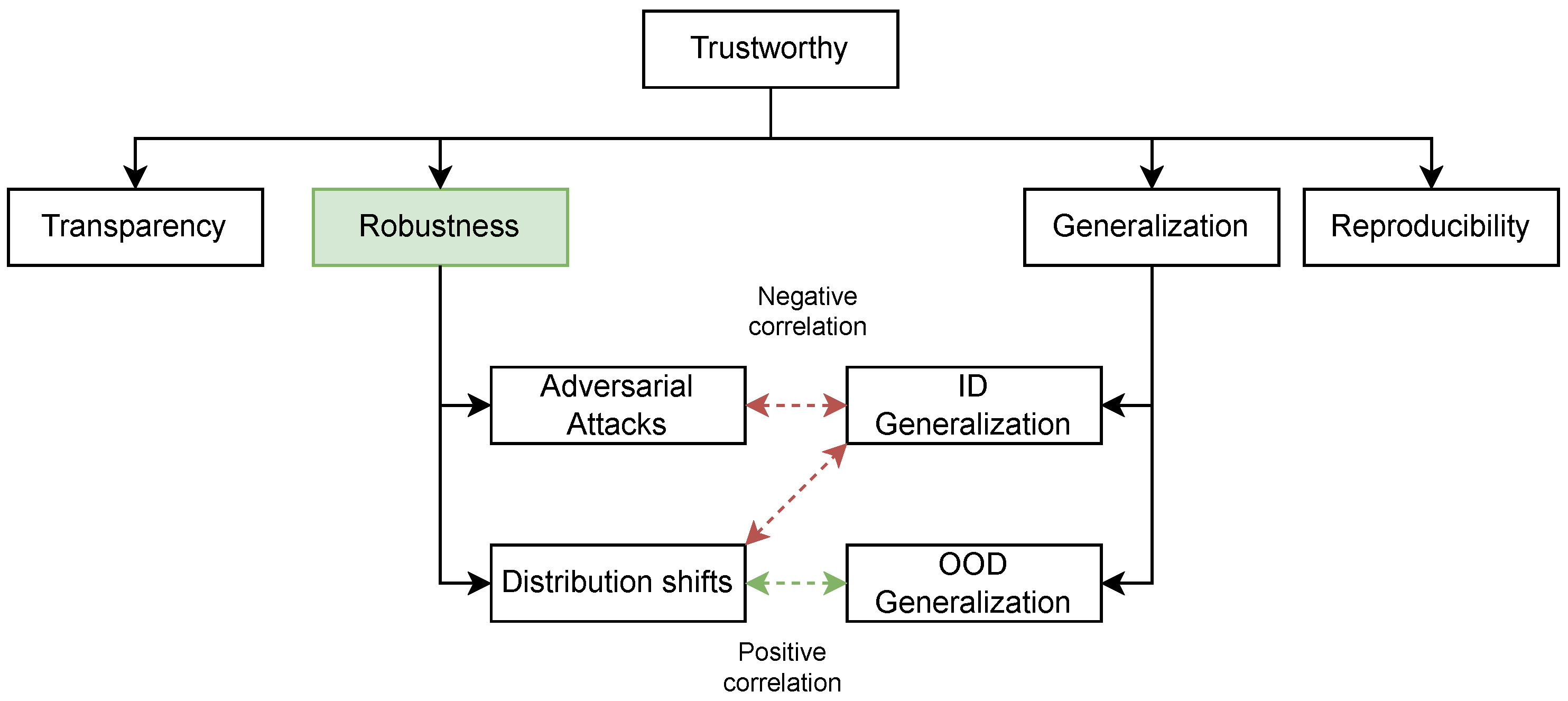
2.2. The Threats against ML-Based NIDSs
Adversarial attacks aim to fool the ML model by perturbing the data [16]. Based on the different stages when the perturbed data is used, adversarial attacks can be classified into different types as follows.- Poisoning Attacks: In the training stage of ML workflow, poisoning attacks aim to perturb the training dataset by changing the inputs or flitting the labels so that they influence the trained model's future capability. If the attacker adds a trigger to training data so that they can force the ML model to execute particular behaviors in the inference stage, those attacks are known as backdoor attacks.
- Evasion Attacks: In the inference stage, evasion attacks refer to a type of attack that attempts to manipulate or exploit a machine learning model by perturbing input data in such a way that it confuses or misleads the model's predictions.
- White-box Attacks: The attackers know everything about the target ML models, such as the decision boundary. In this case, attackers can modify the inputs with the minimum perturbation but with a very high success rate [17].
- Gray-box Attacks: The attackers only have a part of the knowledge of target ML models and can access target models and observe their behaviors [18].
- Black-box Attacks: The attackers do not have any information about the target ML models and cannot access the target models' responses.
Regarding ML-based NIDSs, adversarial attacks can be categorized into two types based on the level of input perturbation applied:
- Feature-based Attacks: This type of adversarial attack against ML-based NIDSs focuses on perturbing the extracted features that represent a network traffic flow.
- Traffic-based Attacks: Given the feature extraction component is included in NIDSs, it is impractical to directly modify the extracted features in real-world scenarios. Traffic-based attacks refer to those attack methods that focus on modifying the original network traffic [19].
Distribution shifts will cause ML models to fail, such as being less accurate. Since the data is different from the source distribution, another term normally used to represent the robustness against distribution shifts is out-of-distribution (OOD) generalization. For varying data types, distribution shifts are normally classified into different subtypes [20] based on the causes.
Many factors can cause distribution shifts in network traffic data, such as changing network environments, user behavior changing over time, and new advanced protocol versions. Additionally, given current ML-based NIDS methods work on varying types of data, including tabular [21], images [22], and sequences [23], the distribution shifts in network data have a complex composition. Although varying types of distribution shifts challenge the robustness of ML-based NIDSs, the studies related to the distribution shifts in ML-based NIDSs or network traffic analysis have not received enough attention. Existing works [24] only focus on one type of shifting cause, such as temporal drift.
3. Fostering Robustness in the Whole Design Lifecycle
Improving robustness necessitates coordinated efforts across multiple stages in the ML application lifecycle, encompassing data sanitization, robust model development, anomaly monitoring, and risk auditing. Conversely, the breakdown of trust in any individual link or aspect can significantly compromise the overall trustworthiness of the entire system. Thus, a holistic approach to maintaining trust throughout all stages of the AI system's lifecycle is essential to ensure its reliability and integrity [25].
Considering that ML model robustness is not a one-time achievement but an ongoing process that requires vigilance, updates, and evaluation, we investigate the robustness of the ML-based NIDS model by following the sequential stages in ML workflow. In the ML workflow, there are six main stages: (1) Data collection and processing; (2) Model structure design; (3) Training and optimization; (4) Fine-tuning (which is an optional stage); (5) Evaluation; (6) Application inference. From the view of model robustness, we consider obtaining the weights of models as a split point because once the training is finished, the robustness of the model is roughly settled down. Hence, we group the first three stages together for the reason that during those stages, robustness is built into the learning model. Furthermore, we group the rest three stages together because the model robustness can still be patched up in those stages.
3.1. Robustness Building-in Techniques
Considering that ML-based NIDSs heavily rely on data, improving the data quality will improve the robustness of ML models. A lot of research in the field of CV [26][27][28] and NLP [29][30] reports that data augmentation can improve out-of-distribution robustness. However, due to the huge difference between network traffic and images or text, those methods may not be able to be directly applied to ML-based NIDS or other network security tasks. In the training stage, the optimization methods also affect the robustness of the trained ML model. To glean information from the data itself, Contrastive learning (CL) creates pairings of positive and negative samples. Building a contrastive loss function is the fundamental concept behind contrastive learning. The model can compare similar and different data, draw on comparable samples, and draw out distinct samples. The performance of contrastive learning models depends critically on the design of positive and negative sampling strategies, and the robustness of the model will be greatly influenced by the difficulty of the suggested sample pairs. Similarly, some adversarial learning methods combine data augmentation and contrastive learning. Such as self-supervised adversarial learning, unlike traditional CL, uses adversarial augmentation to make hard sample mining easier.
3.2. Robustness Patching-up Techniques
For the fine-tuning, evaluation, and application inference stages, manipulating or measuring the distance can improve or evaluate ML models' robustness. Fine-tuning models with adversarial samples can improve robustness against adversarial attacks. Meanwhile, using fine-tuning methods with data from other domains can help a trained model adapt to a new domain, which can be used for solving the concept drift issue in some cases. The evaluation stage is important for verifying a trained ML model's robustness degree. Robustness certification studies aim to certify the robustness of an ML-based classifier against adversarial attacks/perturbations. One line of those works focuses on using the randomized smoothing technique to solve the problem [31]. Randomized smoothing-based robustness certification methods utilize a large amount of noised data samples to estimate the model's robustness against adversarial attacks. Recently, Wang et al. [32 ]propose a robustness certification framework, named BARS, for DL-based traffic analysis, which can be considered as an upstream task of NIDSs. To evaluate the robustness against distribution shifts, cross-dataset evaluation methods [33][34] are proposed to show the importance of improving the OOD generalization.
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NA, USA, 3–6 December 2012; Volume 25.
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567.
- Li, X.; Chen, W.; Zhang, Q.; Wu, L. Building auto-encoder intrusion detection system based on random forest feature selection. Comput. Secur. 2020, 95, 101851.
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An Ensemble of Autoencoders for Online Network Intrusion Detection. In Proceedings of the 25th Annual Network and Distributed System Security Symposium, NDSS 2018, San Diego, CA, USA, 18–21 February 2018.
- Tocchetti, A.; Corti, L.; Balayn, A.; Yurrita, M.; Lippmann, P.; Brambilla, M.; Yang, J. AI Robustness: A Human-Centered Perspective on Technological Challenges and Opportunities. 2022. Available online: http://xxx.lanl.gov/abs/2210.08906 (accessed on 18 August 2023).
- Floridi, L. Establishing the rules for building trustworthy AI. Nat. Mach. Intell. 2019, 1, 261–262.
- Hoffman, W. Making AI Work for Cyber Defense; Center for Security and Emerging Technology: Georgetown, DC, USA, 2021.
- Viegas, E.K.; Santin, A.O.; Tedeschi, P. Toward a Reliable Evaluation of Machine Learning Schemes for Network-Based Intrusion Detection. IEEE Internet Things Mag. 2023, 6, 70–75.
- Wei, F.; Li, H.; Zhao, Z.; Hu, H. XNIDS: Explaining Deep Learning-Based Network Intrusion Detection Systems for Active Intrusion Responses. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023.
- Benzaïd, C.; Taleb, T. AI for beyond 5G networks: A cyber-security defense or offense enabler? IEEE Netw. 2020, 34, 140–147.
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160.
- Xiong, P.; Buffett, S.; Iqbal, S.; Lamontagne, P.; Mamun, M.; Molyneaux, H. Towards a robust and trustworthy machine learning system development: An engineering perspective. J. Inf. Secur. Appl. 2022, 65, 103121.
- Chen, P.Y.; Das, P. AI Maintenance: A Robustness Perspective. Computer 2023, 56, 48–56.
- Drenkow, N.; Sani, N.; Shpitser, I.; Unberath, M. A systematic review of robustness in deep learning for computer vision: Mind the gap? arXiv 2021, arXiv:2112.00639.
- Teney, D.; Lin, Y.; Oh, S.J.; Abbasnejad, E. Id and ood performance are sometimes inversely correlated on real-world datasets. arXiv 2022, arXiv:2209.00613.
- Kloft, M.; Laskov, P. Online Anomaly Detection under Adversarial Impact. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Conference Proceedings, Sardinia, Italy, 13–15 May 2010; pp. 405–412.
- Clements, J.; Yang, Y.; Sharma, A.A.; Hu, H.; Lao, Y. Rallying Adversarial Techniques against Deep Learning for Network Security. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 4–7 December 2021; IEEE: New York, NY, USA, 2021; pp. 1–8.
- Wu, D.; Fang, B.; Wang, J.; Liu, Q.; Cui, X. Evading Machine Learning Botnet Detection Models via Deep Reinforcement Learning. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–6.
- Sharon, Y.; Berend, D.; Liu, Y.; Shabtai, A.; Elovici, Y. Tantra: Timing-based adversarial network traffic reshaping attack. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3225–3237.
- Storkey, A. When training and test sets are different: Characterizing learning transfer. Dataset Shift Mach. Learn. 2009, 30, 6.
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning hierarchical spatial-temporal features using deep neural networks to improve intrusion detection. IEEE Access 2017, 6, 1792–1806.
- Doriguzzi-Corin, R.; Millar, S.; Scott-Hayward, S.; Martinez-del Rincon, J.; Siracusa, D. LUCID: A practical, lightweight deep learning solution for DDoS attack detection. IEEE Trans. Netw. Serv. Manag. 2020, 17, 876–889.
- Dragoi, M.; Burceanu, E.; Haller, E.; Manolache, A.; Brad, F. AnoShift: A distribution shift benchmark for unsupervised anomaly detection. Adv. Neural Inf. Process. Syst. 2022, 35, 32854–32867.
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 19–35.
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From Principles to Practices. arXiv 2022, arXiv:2110.01167.
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. Augmix: A simple data processing method to improve robustness and uncertainty. arXiv 2019, arXiv:1912.02781.
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The Many Faces of Robustness: A Critical Analysis of Uut-of-Distribution Generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 8340–8349.
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196.
- Chen, J.; Yang, Z.; Yang, D. Mixtext: Linguistically-informed interpolation of hidden space for semi-supervised text classification. arXiv 2020, arXiv:2004.12239.
- Xie, R.; Cao, J.; Dong, E.; Xu, M.; Sun, K.; Li, Q.; Shen, L.; Zhang, M. Rosetta: Enabling Robust TLS Encrypted Traffic Classification in Diverse Network Environments with TCP-Aware Traffic Augmentation. In Proceedings of the ACM Turing Award Celebration Conference, Wuhan, China, 28–30 July 2023.
- Yang, G.; Duan, T.; Hu, J.E.; Salman, H.; Razenshteyn, I.; Li, J. Randomized Smoothing of All Shapes and Sizes. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual Event, 13–18 July 2020; pp. 10693–10705.
- Pal, A.; Sulam, J. Understanding Noise-Augmented Training for Randomized Smoothing. arXiv 2023, arXiv:2305.04746.
- Al-Riyami, S.; Coenen, F.; Lisitsa, A. A Re-Evaluation of Intrusion Detection Accuracy: Alternative Evaluation Strategy. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 2195–2197.
- Layeghy, S.; Portmann, M. Explainable Cross-domain Evaluation of ML-based Network Intrusion Detection Systems. Comput. Electr. Eng. 2023, 108, 108692.