Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Mohammad Abrar and Version 2 by Peter Tang.
Brain tumor segmentation in medical imaging is a critical task for diagnosis and treatment while preserving patient data privacy and security. Traditional centralized approaches often encounter obstacles in data sharing due to privacy regulations and security concerns, hindering the development of advanced AI-based medical imaging applications.
- brain tumor segmentation
- computation cost
- data leakage
- data privacy
- deep learning
- federated learning
- medical imaging
1. Introduction
Brain tumors are irregular growths of cells developing within the brain. These tumors can be benign or malignant and can cause severe health complications including neurological deficits and death [1]. It is very important to correctly identify and define the boundaries of brain tumors so that doctors can diagnose them accurately, plan effective treatment strategies, and keep track of how effective the treatments are [2]. To obtain a better view of brain tumors and the structures surrounding them, medical professionals often rely on imaging methods like magnetic resonance imaging (MRI) and computed tomography (CT) scans. These techniques are regularly employed to help diagnose brain tumors and figure out the most effective treatment plan for the patient [3]. To better understand MRI and CT scans, these are divided into distinct segments, which is a practice known as brain tumor segmentation. This segmentation process corresponds to different parts of a tumor, including its necrotic core, the edema, and the enhancing tumor. This segmentation is crucial for accurate diagnosis and treatment planning as it involves the process of separating unhealthy tissues from healthy ones [4]. For many years, manual segmentation has been practiced by radiotherapists to perform these procedures. However, there was a high chance of the variability in the results between different observers and even in same observer. The process is time-consuming and can be affected by the expertise of the radiologist [5]. To overcome these limitations, automated and semi-automated segmentation algorithms have been developed.
The accurate and precise outlining of brain tumors in medical images is important for several reasons. It is a crucial part of diagnosing and determining the stage of the tumor. It helps doctors to understand how big the tumor is, where it is located, and how much it is affecting nearby tissues [6]. This information is critical for determining the prognosis and guiding personalized treatment strategies such as surgery, radiotherapy, and chemotherapy [7]. Accurate segmentation enables an unbiased and measurable evaluation of how tumors respond to treatment, reducing the subjective factors associated with manual evaluation [8]. This can help clinicians to make informed decisions about the efficacy of a particular treatment, and whether adjustments to the therapeutic plan are necessary. Precise segmentation can facilitate the development of computational models that predict tumor growth and its reaction to therapy, thus enhancing personalized medicine [9]. Such models can help to identify potential treatment targets, optimize treatment schedules, and identify patients at risk of tumor recurrence or progression. The increasing availability of medical imaging data and advancement in the technology has resulted in the development of robust and accurate computational segmentation algorithms [10]. However, the need for large amounts of annotated data brings its own challenges, i.e., the security and privacy concerns that limit the access to such data [11]. Additionally, in the context of deep learning models, the key challenge is the centralized nature of these approaches, which requires data from multiple institutions to be combined in a central repository. However, this process can present significant logistical difficulties and may also face limitations due to regulatory constraints.
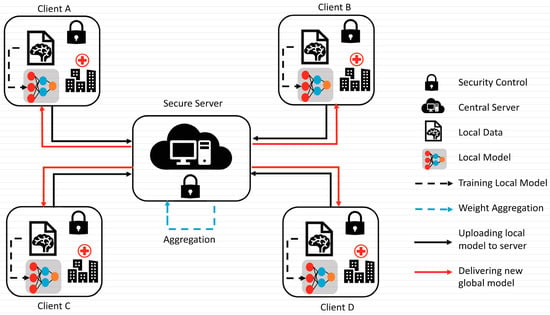
To overcome the challenge of the centralized nature of deep learning (DL) and data security, the idea of federated learning (FL) is introduced that works via decentralized processing units which have their own data and model [12]. In FL, a unit does not share its data with other units, but instead, it shares the weights of the model with the centralized controller for the refinement of the overall model’s performance. Figure 1a,b show the working flow of federated learning. Such privacy and security assurance resulted in the popularity of FL in areas with significant data privacy concerns such as healthcare and medical imaging [13]. Since its inception, FL has largely been applied to such tasks, i.e., segmentation, reconstruction, and classification, with significantly reliable performance and results [14][15][14,15].
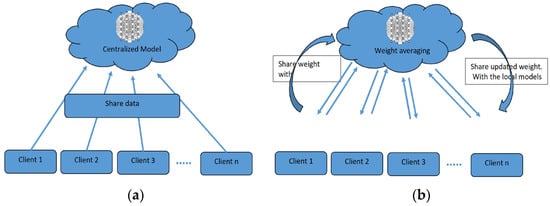
Figure 1.
(
a
) Centralized model of FL; (
b
) client server model of FL.
In brain tumor segmentation, FL can utilize data from multiple institutions, enhancing the performance and generalizability of segmentation algorithms. This is accomplished while maintaining the utmost data privacy and security. FL is crucial in addressing the heterogeneity of the brain tumor, which varies in location, shape, size, and intensity across patients. By leveraging data from multiple institutions, FL improves segmentation algorithms while preserving data privacy and security [16]. By allowing institutions to collaborate without sharing raw data, FL can enable the development of more robust and accurate segmentation algorithms that can better account for this variability.
2. Traditional Brain Tumor Segmentation
Several conventional techniques have been proposed for brain tumor segmentation, including region-focused, edge-focused, and model-focused approaches [17][19]. While conventional brain tumor segmentation techniques have been widely used in medical imaging, they have several limitations, including sensitivity to image noise, lack of robustness to variations in image intensity and texture, and dependence on expert knowledge for parameter tuning. The accuracy of conventional techniques depends on the specific application and available resources [18][20]. Thus, the choice of the most appropriate segmentation technique depends on various factors, including the image quality, the type and location of the tumor, and the clinical objectives. In recent years, deep-learning-based methods, such as CNNs, RNNs, and their variants, have emerged as powerful alternatives to conventional techniques, achieving state-of-the-art performance on various medical imaging tasks, including brain tumor segmentation. The accuracy of these techniques depends on the specific application and available resources. However, these methods require large and diverse datasets for training and the careful selection of appropriate network architectures and hyperparameters.2.1. Region-Focused Approaches
Region-focused approaches have been widely used in brain tumor segmentation due to their simplicity and computational efficiency. These methods aim to segment brain tumors based on the intensity or texture differences between the tumor and its surrounding tissue. Several region-based approaches have been proposed for brain tumor segmentation, including thresholding, clustering, and region growing methods [19][21]. Thresholding-based methods involve setting a fixed threshold value to separate the tumor and non-tumor regions [20][22]. These methods are simple and fast, but may be affected by image noise and variations in image intensity and texture. Clustering-based methods use statistical clustering algorithms, such as fuzzy C-means, k-means, and expectation-maximization algorithms, to partition the image into tumor and non-tumor regions. Clustering-based methods can achieve better segmentation accuracy than thresholding-based methods, but they require the careful selection of clustering parameters. Region growing methods start with a seed point within the tumor region and expand the region by incorporating adjacent pixels that meet specific criteria. Region growing methods can produce accurate and smooth segmentation results, but may be affected by variations in image intensity and texture, and they are sensitive to the selection of seed points. Several studies have compared the performance of region-based approaches for brain tumor segmentation. Jaglan et al. [21][23] compared the performance of various thresholding- and clustering-based methods and found that the Otsu thresholding method and the fuzzy C-means clustering method achieved the highest segmentation accuracy. Charutha et al. [22][24] compared the performance of various region growing methods and found that a fast-marching method with an adaptive threshold achieved the best segmentation results. Region-focused approaches have been widely used in brain tumor segmentation due to their simplicity and computational efficiency. While these methods have their strengths, they may be negatively affected by variations in image intensity and texture. Thus, they require the careful selection of parameters and domain knowledge. Advances in deep-learning-based methods have shown promising results in overcoming some of the limitations of region-focused approaches.2.2. Edge-Focused Approaches
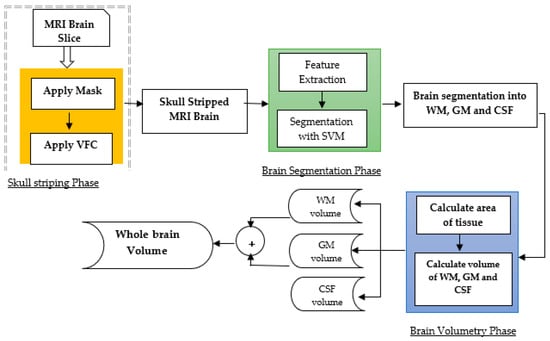
Edge-focused approaches aim to identify the boundary between the tumor and surrounding tissue by detecting edges in the image. These methods often use edge detection techniques, such as Canny or Sobel filters, to highlight the edges and then apply a segmentation algorithm to separate the tumor from the background. Edge-focused approaches can achieve better segmentation accuracy than region-based approaches, but may be sensitive to image noise and produce fragmented results. Rajan and Sundar [23][25] combined K-means clustering, fuzzy C-means, and active contour techniques to enhance segmentation. Similarly, Sheela and Suganthi [24][26] used an approach to improve accuracy, reduce processing time, and compute tumor volume for effective diagnosis and treatment. The process involves collecting images, calculating tumor area and volume, preprocessing and enhancing the images, adjusting the image intensities, clustering the images, classifying the images, extracting features, and segmenting the images. Each step in the process is important and contributes to the overall quality of the enhanced images. The process has strengths such as its ability to improve the quality of MRI images in several ways, i.e., identifying tumors, providing quantitative information about tumors, and segmenting tumors from the surrounding tissue. However, the process also has weaknesses, such as its complexity, time-consuming nature, reliance on specialized software and hardware, difficulty in automation, and sensitivity to noise in the images. Several studies have compared the performance of edge-focused approaches for brain tumor segmentation. The performance of various edge detection methods, including Canny, Sobel, and Laplacian filters, showed that the Sobel filter achieved the highest segmentation accuracy. Und et al. [25][27] compared the performance of edge detection methods combined with different segmentation algorithms, such as region growing and active contour methods, and found that the Sobel filter combined with the active contour method achieved the best segmentation results. Edge-focused approaches can be computationally intensive due to the need to detect edges in the image. Moreover, it may be affected by variations in image intensity and texture and produce fragmented segmentation results. Deep-learning-based methods, such as CNNs, have shown promising results in overcoming some of these limitations. They can also achieve better segmentation accuracy than region-based approaches, but they may be sensitive to image noise and produce fragmented results. The choice of the most appropriate edge detection method depends on the specific application and available resources. Deep-learning-based techniques have reported very significant results in improving segmentation accuracy and robustness.2.3. Model-Focused Approaches
Model-focused approaches aim to model the shape, texture, and intensity-based characteristics of brain tumors and their surrounding tissue to improve segmentation accuracy. These methods often use traditional machine learning algorithms, such as random forests, decision trees, and support vector machines, to learn those features that distinguish between tumorous and non-tumorous regions [23][25]. Model-focused approaches can achieve high segmentation accuracy and robustness subject to the availability of high-quality large datasets for training and may be affected by overfitting, as presented in Figure 2.