Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 3 by Gavin Wang and Version 4 by Fanny Huang.
Robot arm motion control is a fundamental aspect of robot capabilities, with arm reaching ability serving as the foundation for complex arm manipulation tasks. The researchers propose a robot arm motion control method based on inner rehearsal. Inspired by the cognitive mechanism of inner rehearsal observed in humans, this approach allows the robot to predict or evaluate the outcomes of motion commands before execution. By enhancing the learning efficiency of models and reducing excessive physical executions, the method aims to improve robot arm reaching across different platforms.
- arm reaching
- motion planning
- inner rehearsal
- internal model
- human cognitive mechanism
1. Introduction
In recent years, robots have played important roles in many fields, especially for humanoid robots. As arm manipulation is one of the most basic abilities for human beings [1], arm motion control is also an indispensable ability for humanoid robots [2]. In modern factories, automation manufacturing and many other production activities are inseparable from robot arms [3]. Among various types of arm manipulation abilities, arm reaching is one of the most basic, and it is the first step in many complex arm motions, such as grasping and placing, and can also lay the foundation for subsequent motion, perception, and cognition [4][5][4,5].
The major goal of robot arm reaching is to choose a set of appropriate arm joint angles so that the end-effectors can reach the target position in Cartesian space with a certain posture, which is commonly referred to as internal model control (IMC) [6]. In 1998, Wolpert et al. [7] reviewed the necessity of such an internal model and the evidence in a neural loop. In the same year, Wolpert and Kawato [8] proposed a new architecture based on multiple pairs of inverse (controller) and forward (predictor) models, where the inverse and forward models are tightly coupled. ResWearchers usually implement robots’ motion control through kinematic or dynamic modeling [9]. However, since the control of force and torque is not involved in robot arm reaching tasks, only the kinematic method is considered. The internal kinematics model can be separated into the inverse kinematics (IK) model and forward kinematics (FK) model according to the input and output of the model.
In the task of reaching, the major problem is how to build an accurate IK model that maps a certain posture to a set of joint angles. There are mainly two types of approaches to robot arm reaching control: conventional IK-based approaches and learning-based approaches. Table 1 shows some related research.
we can unlock new possibilities for robotic capabilities and their seamless integration into various applications.
Table 1. Classification of robot arm reaching control approaches.
Abbreviations
The following abbreviations are used in this manuscript:
Abbreviations
The following abbreviations are used in this manuscript:
Classification of robot arm reaching control approaches.
| FK | Forward Kinematics |
| IK | Inverse Kinematics |
| IMC | Internal Model Controller |
| DIM | Divided Inverse Model |
| FM | Forward Kinematics Model |
| IM | Inverse Kinematics Model |
| Classification | Approaches |
|---|---|
| Numerical method [10] | |
| Conventional IK-based | Analytical method [11][12] |
| Geometric method [13] | |
| Learning-based | Supervised learning: deep neural networks [14], spiking neural networks [15] Unsupervised learning: self-organizing maps [16], reinforcement learning [17][18] |
The main contributions of this paper are as follows.
- The internal models are established based on the relative positioning method. RWesearchers limit the output of the inverse model to a small-scale displacement toward the target to smooth the reaching trajectory. The loss of the inverse model during training is defined as the distance in Cartesian space calculated by the forward model.
-
The models are pre-trained with an FK model and then fine-tuned in a real environment. The approach not only increases the learning efficiency of the internal models but also decreases the mechanical wear and tear of the robots.
-
The motion planning approach based on inner rehearsal improves the reaching performance via predictions of the motion command. During the whole reaching process, the planning procedure is divided into two stages, proprioception-based rough reaching planning and visual-feedback-based iterative adjustment planning.
2. PrRevious Studieslated Work
This parsection describes previous studies on visual servoing reaching, internal model establishment, and inner rehearsal.
To avoid the drawbacks of the conventional IK-based approach, rwesearchers implement the following.
| DoF |
| Degree of Freedom |
-
ResWearchers use image-based visual servoing to construct a closed-loop control so that the reaching process can be more robust than that without visual information.
-
ResWearchers build refined internal models for robots using deep neural networks. After coarse IK-based models generate commands, researcherswe adjust the commands with learning-based models to eliminate the influence of potential measurement errors.
-
Inner rehearsal is applied before the commands are actually executed. The original commands are adjusted and then executed according to the result of inner rehearsal.
3. Ov Merall Frameworkthodology
This parsection describes the proposed robot arm reaching approach in detail. The overall framework, the establishment of the internal models, and the inner-rehearsal-based motion planning approach are introduced.
3.1. Overall Framework
The overall framework of the proposed approach is shown in Figure 1. The proposed method comprises four blocks: (1) visual information processing, (2) target-driven planning, (3) inner rehearsal, and (4) command execution.
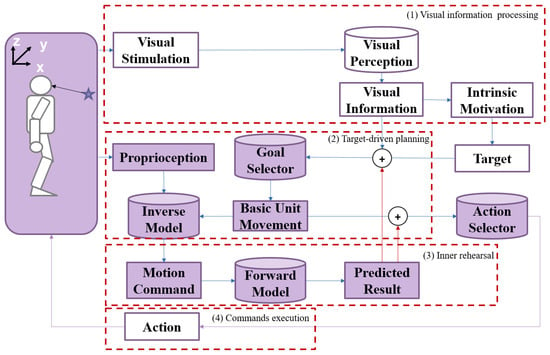
Figure 1. The overall framework of the robot arm reaching approach based on inner rehearsal. The purple shading in some boxes denotes “inner rehearsal”, different from “visual information processing”. The use of cylinders and rectangles is intended to represent different types of components in the system. Cylinders indicate “models”, while rectangles indicate “values”.
-
The target position in Cartesian space is generated after the robot sees the target object through the visual perception module. The visual stimulation is converted into the required visual information, and then the intrinsic motivation is stimulated to generate the target [1][19].
-
The aim of movement is generated by the relative position between the target and the end-effector. The inverse model generates the motion command based on the current arm state and the expected movement. Each movement is supposed to be a small-scale displacement of the end-effector toward the target.
-
The forward model will predict the result of the motion command without actual execution. The predictions of the current movement are considered to be the next state of the robot so that the robot can generate the next motion command accordingly. In this way, a sequence of motion commands will be generated. The robot conducts (2) and (3) repeatedly until the prediction of movements exactly reflects the target.
-
The robot executes these commands and reaches the target.
-
The target position in Cartesian space is generated after the robot sees the target object through the visual perception module. The visual stimulation is converted into the required visual information, and then the intrinsic motivation is stimulated to generate the target [1,48].
-
The aim of movement is generated by the relative position between the target and the end-effector. The inverse model generates the motion command based on the current arm state and the expected movement. Each movement is supposed to be a small-scale displacement of the end-effector toward the target.
-
The forward model will predict the result of the motion command without actual execution. The predictions of the current movement are considered to be the next state of the robot so that the robot can generate the next motion command accordingly. In this way, a sequence of motion commands will be generated. The robot conducts (2) and (3) repeatedly until the prediction of movements exactly reflects the target.
-
The robot executes these commands and reaches the target.
4. Experiments
To evaluate the effectiveness of the proposed reaching approach based on inner rehearsal, several experiments are conducted. Some experimental settings and analyses of the results are introduced in this section. In the visual part, because it is not the key research part, rwesearchers simply process the image in the HSV and depth space to extract the target information. It is encoded as a Cartesian (x,y,z) position.
The proposed approach is verified on the Baxter robot and the humanoid robot PKU-HR6.0 II. To confirm the position of the end of the robot arm, reswearchers add a red mark to the end-effector and the robot detects its position throughout the experiment.
5. Conclusions
AIn this paper, a robot arm reaching approach based on inner rehearsal is proposed. The internal models are pre-trained with a coarse FK model and fine-tuned in the real environment. The two-stage learning of the internal models helps to improve the learning efficiency and reduce mechanical wear and tear. The motion planning approach based on inner rehearsal improves the reaching performance by predicting the result of a motion command with the forward model. Based on the relative distance, the whole planning process is divided into proprioception-based rough reaching planning and visual-feedback-based iterative adjustment planning, which improves the reaching performance. The experimental results show that researchers'our method improves the effectiveness in robot arm reaching tasks. For the operation problem of the robotic arm, researchers'our work implements a relatively fixed two-stage framework. The human cognitive mechanism has great potential in enabling agents to learn to determine the strategic framework of grasping by themselves, so that robots can be more suitable for unknown, complex scenes. Furthermore, researcherswe can delve deeper into the cognitive mechanisms of humans and investigate how these insights can further enhance robot learning and decision making. In doing so, researchers