Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Alfred Zheng and Version 1 by GURWINDER SINGH.
In cyber-physical systems (CPS), micromachines are typically deployed across a wide range of applications, including smart industry, smart healthcare, and smart cities. Providing on-premises resources for the storage and processing of huge data collected by such CPS applications is crucial. The cloud provides scalable storage and computation resources, typically through a cluster of virtual machines (VMs) with big data tools such as Hadoop MapReduce.
- cyber-physical system
- data block placement
- data locality
- MapReduce
1. Introduction
A micromachine is a miniature version of a traditional device, typically on a micrometer or millimeter scale. Micromachines have a wide range of applications in CPS, as shown in Figure 1, including aerospace, automotive, healthcare, industry, consumer electronics, etc. A microsensor, for example, can measure physical, chemical, or biological properties such as temperature, pressure, or chemical composition. Because data is generated rapidly and in large quantities, for example, transportation management [1], it is not possible to store, analyze, and make decisions at the physical layer. Therefore, data is transferred via networking devices in the communication layer and processed by cloud-influenced data processing platforms [2], such as dew, edge, mist, and fog computing layer through stream/query processing using distributed processing tools such as Storm, S4, Kafka, etc. However, these layers are not capable of storing and batch processing such massive amounts of data. Thus, the collected data are stored in the cloud data center (CDC) and processed using the Hadoop framework [3], which provides Hadoop Distributed File Systems (HDFS) and MapReduce to store and process large datasets. Today, HDFS and MapReduce are offered as services [4] from the cloud on a pay-per-use basis on a cluster of VMs. However, heterogeneity in cloud execution environments [5] inhibits MapReduce performance significantly. Heterogeneity occurs in different ways in cloud virtual execution environments [6]: hardware heterogeneity, VM heterogeneity, performance heterogeneity, and workload heterogeneity. In recent work [5], one or more of these heterogeneities have been exploited to improve the job latency and makespan for a batch of workloads. As Hadoop 2.0 allows users to customize the map/reduce task container size for each job in a batch, schedule problems become more complicated. In particular, HDFS data block placement and locality aware map task scheduling play a crucial role in improving MapReduce job scheduler performance. Placement of data blocks in HDFS is carried out as follows. Data collected from the CPS environment are transferred over the Internet and stored on the cluster by HDFS in blocks of a predefined size. These data blocks are replicated [7] to ensure fault tolerance by taking advantage of rack awareness in the physical cluster. In contrast, when a cluster of VMs is hosted on different physical machines (PMs) across the CDC, ensuring fault tolerance with data replication for HDFS is not possible. Additionally, it has a significant impact on the execution of locality based map tasks. When all VMs are hosted within a rack, the network cost to perform non-local execution is negligible. There is, however, no guarantee of rack awareness [7]. In this case, once the data blocks are placed in the VMs, it is rarely expected to move them around the cluster again to perform non-local execution, which involves additional network costs. Therefore, distributing VMs across the CDC guarantees rack awareness with additional network costs for non-local executions. Hence, it is important to minimize the number of non-local executions when the VMs in the virtual cluster are distributed in the physical cluster.
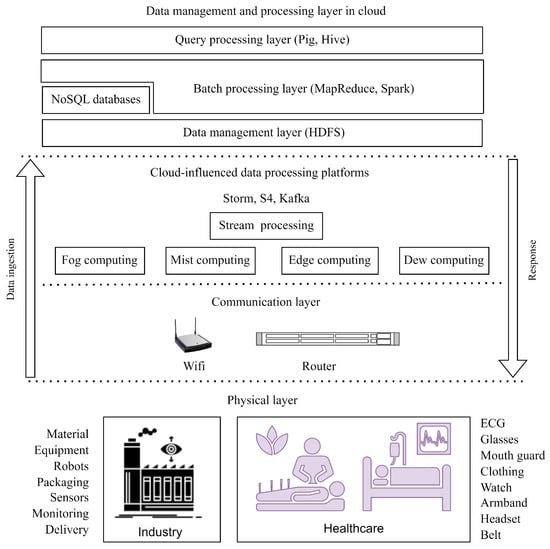
Figure 1.
Big data management for CPS applications.
Second, open source MapReduce schedulers [8,9][8][9] are mostly driven by resource availability in the virtual cluster. Due to the highly heterogeneous capacity and performance of PMs in the CDC, VMs also exhibit heterogeneous performance. It is possible for the storage of a set of VMs to be allocated to the same hard disk drive (HDD), even if multiple HDDs are available on the same PM. In the cloud system, there is no option by default to allocate storage space from specific HDDs to VMs. In the worst-case scenario, VMs share a single HDD. The result is varying latency for map tasks due to disk IO contention/races among VMs hosted on the PM. Due to this, data local execution is severely affected since disk IO is mostly used to serve data for other tasks from other VMs. At this moment, performing non-local execution obviously consumes additional network bandwidth and time. In addition, the nature and resource requirements of map tasks in MapReduce for different jobs are also highly heterogeneous. Sometimes, a map task could be CPU or memory intensive and the container size for map tasks from different jobs could also differ. Therefore, it is necessary to exploit the dynamic performance of VMs based on the map task requirements of different jobs to achieve data local execution.
Moreover, disk IO becomes a bottleneck when Hadoop/non-Hadoop VMs share a single HDD among them. In general, big data batch processing (MapReduce and Spark) jobs tend to be more disk-intensive, requiring constant disk bandwidth to bring input data blocks for map task execution. However, each VM hosted on a PM shares the disk bandwidth for different tasks. This causes map task latency to increase. Therefore, data blocks must be stored based on HDD performance, so map tasks receive input data blocks seamlessly. Moreover, as VMs in the hired virtual cluster could be of a different flavor, the number of data blocks processed per unit of time varies greatly. Hence, it is important to understand the capacity and processing performance of different VMs before loading data blocks.
2. Hadoop MapReduce
The Hadoop framework consists of two major components: HDFS and MapReduce. The HDFS manages huge data across multiple servers and feeds it to MapReduce for processing. MapReduce jobs consist of two phases: map and reduce, as shown in Figure 2. A map phase consists of a set of map tasks. A map task processes a set of data blocks from HDFS and produces an arbitrary size of intermediate output. A set of reduce tasks is launched during the reduce phase, depending on how much parallelism people intend to extract. Reduce tasks collect and consolidate portions of the map tasks’ output. Prior to executing the reduce function, the reduce tasks perform a series of steps (merge, sort, group). From the group function, the reduce function receives a list of inputs and writes the output to HDFS. As part of this execution sequence, the output of map tasks is moved to reduce tasks through the process of “shuffle/copy”. It is possible to start the reduce phase simultaneously with the map phase. However, the reduce function in the reduce phase can be executed only after the map phase is finished. Physical resources for MapReduce jobs are allocated by a component called YARN, which comprises two modules: resource manager (RM) and node manager (NM). RM distributes clustered server resources (CPU, RAM, storage) between different frameworks (such as Hadoop and Spark). The NM manages local resources on the server according to the size of each map and reduce task.
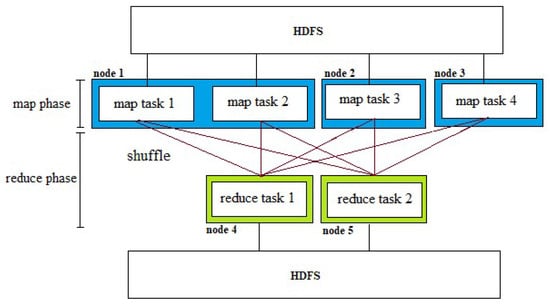
Figure 2.
MapReduce Phases.
3. Data Placement and MapReduce Job Scheduling Exploiting Heterogeneity in Cloud Environments
With the increasing use of cloud-based data processing services to support CPS applications, managing virtual resources to improve MapReduce job latency and makespan has become difficult. Therefore, big data processing with tools offered by the cloud is increasingly becoming a research hotspot. Different block placement and MapReduce job/tasks scheduling play a vital role in improving job latency and makespan. Over a decade, there have been many data block placement algorithms proposed to improve makespan and novel scheduling algorithms [10] to exploit dynamic performance to improve job latency in a cloud environment.
Distributed file systems, such as Google File System [11] and HDFS [12], divide input datasets into fixed-size blocks. The Modulo-based data block placement algorithm [13] is introduced for block placement to minimize energy consumption and improve makespan in a virtual cluster environment. It is performed in terms of CPU-intensive, IO-intensive, and interactive jobs. Roulette wheel scheme (RWS)-based data block placement and heuristic-based MapReduce job scheduler (HMJS) are proposed in [5] to enhance data local execution for map tasks, job latency, and makespan. In this work, the authors consider the computing capacity of VMs to place data blocks but not the heterogeneous performance of VMs. In addition, disk IO performance largely affects map phase latency, even though CPU and memory are available for map tasks. To handle this, constrained two-dimensional bin packing is proposed to place heterogeneous map/reduce tasks to minimize job latency and makespan. In [14], the authors propose a workflow level-based data block placement in a cloud environment to optimize the data sharing among multiple jobs in a batch. To manage geo-distributed workloads, the authors in [15] place the data based on the computing capacity of nodes in the CDC. These data blocks are typically stored based on rack awareness in case of a physical cluster. This leads to a varying number of data blocks on each physical machine in the cluster, as shown in Figure 2. However, in a cloud virtual environment, there is no rack awareness [16] as VMs might be hosted in the same PM or different PMs within a rack. This results in an unequal number of data blocks in each VM, regardless of its performance and location. A detailed description of different replication strategies in distributed file systems on the cloud is mentioned in [17,18][17][18].
To improve data local execution in a heterogeneous environment, a sampling-based randomized algorithm is proposed in [19]. In this work, the authors estimate the workload arrival at runtime for a set of candidate nodes in the cluster. The node that is estimated with the smallest workload in the future is chosen to place data blocks. A dynamic data replication strategy is proposed in [20] to minimize network bandwidth consumption and latency. The authors consider a set of characteristics, such as number of replicas, dependency between datasets, and the storage capacity to decide the lifetime of a replica. A similar approach is applied in [7] to retain the data blocks that are most wanted. Interestingly, the authors in [21] place data blocks based on the availability of cache memory in the server. A location-aware data block placement strategy for HDFS is devised in [22], by identifying virtual nodes’ processing capacities in the cloud. To take advantage of data local executions, data locality aware scheduling is performed in [23]. A similar approach is carried out in [24], with the focus of minimizing the total data transfer cost at the time of non-local execution. In an IoT environment, data blocks located on different decentralized nodes are processed and the results are combined. To achieve this, the authors in [25] proposed an edge-enabled block replica strategy that stores in-place, partition-based, and multi-homing block replicas on respective edge nodes. To estimate the workers’ and tasks’ future resource consumption, a Kernel Density Estimation and Fuzzy FCA techniques are used in [26] to cluster data partitions. Fuzzy FCA is also used to exclude partitions and jobs that require less resources, which will reduce needless migrations. In another work [27], the authors place data blocks based on the evaluation indicators, such as node’s disk space capacity, memory and CPU utilization, rack load rate, and network distance between racks.
In a production environment, a batch of jobs is periodically executed to extract insight from huge data in physical/virtual clusters at different times. The nature of jobs would not change much and reveal more information about workload behavior. Fair scheduler [8] equally shares the underlying resources to all the jobs in the batch, resulting in an equal chance for each job. However, if a job is idle and waiting for the resources, the resources allocated to that job are held idle until the job completion. To provide resources based on the job’s requirements, capacity scheduler [9] is introduced to define the resources required for each job in the batch. Like fair scheduler, capacity scheduler also holds resources unused when the job is waiting for other resources. In addition, both fair and capacity schedulers do not consider the heterogeneity in the underlying hardware resources. To adopt various dynamic parameters in big data applications to improve energy efficiency, workload analysis [28] is conducted to select the optimal configuration and system parameters. They used micro-benchmarks and real-world applications to demonstrate the idea proposed. In this study, a variety of processing elements, as well as system and Hadoop configuration parameters, are tested. These metrics emphasize the performance of the MapReduce scheduler. Identifying the right combination of these parameters is a challenging task that cannot be performed at the time of execution. Therefore, Metric Important Analysis (ensemble learning) was carried out by Zhibin Yu et al. [29] using MIA-based Kiviat Plot (MKP) and Benchmark Similarity Matrix (BSM). This produces more insight than traditional-based dendrograms to understand job behavior by using three different benchmarks: iBench, CloudRank-D, and SZTS.
Heterogeneity at different levels of the cloud environment is considered before data block distribution in the virtual cluster by using a framework, called MRA++ [30]. This method uses some sample map tasks to gather information on the capacity and performance of individual nodes in the cluster. If a node is underperforming, it does not attract compute-intensive tasks. Thus, stragglers are avoided. Balancing data load among the nodes in the Hadoop cluster is very difficult to determine in a heterogeneous environment as the performance of individual nodes varies significantly. A novel data placement technique was proposed by Vrushali Ubarhande et al. [31] to minimize makespan in a heterogeneous cloud environment. Computing performance is determined for each virtual node using some heuristics, and data blocks are placed accordingly. The authors claim that data locality and makespan are compared to classical methods. To balance optimal load across the virtual cluster, a topology-aware heuristic algorithm [32] was designed to minimize non-local execution for map tasks and minimize global data access during the shuffle phase. Here, the computation cost was minimized up to 32.2% compared to classical MapReduce schedulers.
References
- Rathore, M.M.U.; Shah, S.A.; Awad, A.; Shukla, D.; Vimal, S.; Paul, A. A cyber-physical system and graph-based approach for transportation management in smart cities. Sustainability 2021, 13, 7606.
- Jeyaraj, R.; Balasubramaniam, A.; Kumara, A.M.A.; Guizani, N.; Paul, A. Resource Management in Cloud and Cloud-Influenced Technologies for Internet of Things Applications. ACM Comput. Surv. 2022, 55, 1–35.
- Jeffrey Dean, S.G. MapReduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 2140–2144.
- Guo, Y.; Rao, J.; Jiang, C. Moving Hadoop into the Cloud with Flexible Slot Management and Speculative Execution. IEEE Trans. Parallel Distrib. Syst. 2014, 28, 798–812.
- Jeyaraj, R.; Ananthanarayana, V.S.; Paul, A. Improving MapReduce scheduler for heterogeneous workloads in a heterogeneous environment. Concurr. Comput. Pract. Exp. 2020, 32.
- Jeyaraj, R.; Ananthanarayana, V.S.; Paul, A. Dynamic ranking-based MapReduce job scheduler to exploit heterogeneous performance in a virtualized environment. J. Supercomput. 2019, 75, 7520–7549.
- Xiong, R.; Du, Y.; Jin, J.; Luo, J. HaDaap: A hotness-aware data placement strategy for improving storage efficiency in heterogeneous Hadoop clusters. Concurr. Comput. Pract. Exp. 2018, 30.
- Hadoop MapReduce Fair Scheduler. Available online: https://hadoop.apache.org/docs/r2.7.4/hadoop-yarn/hadoop-yarn-site/FairScheduler.html (accessed on 20 May 2023).
- Hadoop MapReduce Capacity Scheduler. Available online: https://hadoop.apache.org/docs/r2.7.4/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html (accessed on 20 May 2023).
- Hashem, I.A.T.; Anuar, N.B.; Marjani, M.; Ahmed, E.; Chiroma, H.; Firdaus, A.; Abdullah, M.T.; Alotaibi, F.; Mahmoud Ali, W.K.; Yaqoob, I.; et al. MapReduce scheduling algorithms: A review. J. Supercomput. 2020, 76, 4915–4945.
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google file system. ACM USA 2003, 37, 29–43.
- Hadoop Distributed File System (HDFS). Available online: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 20 May 2023).
- Song, J.; He, H.Y.; Wang, Z.; Yu, G.; Pierson, J.M. Modulo Based Data Placement Algorithm for Energy Consumption Optimization of MapReduce System. J. Grid Comput. 2018, 16, 409–424.
- Derouiche, R.; Brahmi, Z. A cooperative agents-based workflow-level distributed data placement strategy for scientific cloud workflows. In Proceedings of the 2nd International Conference on Digital Tools & Uses Congress, Virtual, 15–17 October 2020.
- Li, C.; Liu, J.; Li, W.; Luo, Y. Adaptive priority-based data placement and multi-task scheduling in geo-distributed cloud systems. Knowl.-Based Syst. 2021, 224, 107050.
- Du, Y.; Xiong, R.; Jin, J.; Luo, J. A Cost-Efficient Data Placement Algorithm with High Reliability in Hadoop. In Proceedings of the Fifth International Conference on Advanced Cloud and Big Data (CBD), Shanghai, China, 13–16 August 2017; pp. 100–105.
- Shakarami, A.; Ghobaei-Arani, M.; Shahidinejad, A.; Masdari, M.; Shakarami, H. Data replication schemes in cloud computing: A survey. Clust. Comput. 2021, 24, 2545–2579.
- Sabaghian, K.; Khamforoosh, K.; Ghaderzadeh, A. Data Replication and Placement Strategies in Distributed Systems: A State of the Art Survey. Wirel. Pers. Commun. 2023, 129, 2419–2453.
- Wang, T.; Wang, J.; Nguyen, S.N.; Yang, Z.; Mi, N.; Sheng, B. EA2S2: An efficient application-aware storage system for big data processing in heterogeneous clusters. In Proceedings of the 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017.
- Bouhouch, L.; Zbakh, M.; Tadonki, C. Dynamic data replication and placement strategy in geographically distributed data centers. Concurr. Comput. Pract. 2022, 35.
- Ahmadi, A.; Daliri, M.; Goharshady, A.K.; Pavlogiannis, A. Efficient approximations for cache-conscious data placement. In Proceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation, San Diego, CA, USA, 13–17 June 2022; pp. 857–871.
- Xu, H.; Liu, W.; Shu, G.; Li, J. LDBAS: Location-aware data block allocation strategy for HDFS-based applications in the cloud. KSII Trans. Internet Inf. Syst. 2018, 12, 204–226.
- Gandomi, A.; Reshadi, M.; Movaghar, A.; Khademzadeh, A. HybSMRP: A hybrid scheduling algorithm in Hadoop MapReduce framework. J. Big Data 2019, 6, 106.
- Jin, J.; An, Q.; Zhou, W.; Tang, J.; Xiong, R. DynDL: Scheduling data-locality-aware tasks with dynamic data transfer cost for multicore-server-based big data clusters. Appl. Sci. 2018, 8, 2216.
- Qureshi, N.M.F.; Siddiqui, I.F.; Unar, M.A.; Uqaili, M.A.; Nam, C.S.; Shin, D.R.; Kim, J.; Bashir, A.K.; Abbas, A. An Aggregate MapReduce Data Block Placement Strategy for Wireless IoT Edge Nodes in Smart Grid. Wirel. Pers. Commun. 2019, 106, 2225–2236.
- Sellami, M.; Mezni, H.; Hacid, M.S.; Gammoudi, M.M. Clustering-based data placement in cloud computing: A predictive approach. Clust. Comput. 2021, 24, 3311–3336.
- He, Q.; Zhang, F.; Bian, G.; Zhang, W.; Li, Z.; Yu, Z.; Feng, H. File block multi-replica management technology in cloud storage. Clust. Comput. 2023.
- Malik, M.; Neshatpour, K.; Rafatirad, S.; Homayoun, H. Hadoop workloads characterization for performance and energy efficiency optimizations on microservers. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 355–368.
- Yu, Z.; Xiong, W.; Eeckhout, L.; Bei, Z.; Mendelson, A.; Xu, C. MIA: Metric importance analysis for big data workload characterization. EEE Trans. Parallel Distrib. Syst. 2018, 29, 1371–1384.
- Anjos, J.C.S.; Carrera, I.; Kolberg, W.; Tibola, A.L.; Arantes, L.B.; Geyer, C.R. MRA++: Scheduling and data placement on MapReduce for heterogeneous environments. Future Gener. Comput. Syst. 2015, 42, 22–35.
- Ubarhande, V.; Popescu, A.M.; González-Vélez, H. Novel Data-Distribution Technique for Hadoop in Heterogeneous Cloud Environments. In Proceedings of the Ninth International Conference on Complex, Intelligent, and Software Intensive Systems, Santa Catarina, Brazil, 8–10 July 2015; pp. 217–224.
- Chen, W.; Paik, I.; Li, Z. Tology-Aware Optimal Data Placement Algorithm for Network Traffic Optimization. IEEE Trans. Comput. 2016, 65, 2603–2617.
More