This aHerticle presents a comprehensive review of Active Simultaneous Localization and Mapping (A-SLAM) research conducted over the past decade. It explores the formulation, applications, and methodologies employed in A-SLAM, particularly in trajectory generation and control action selection, drawing on concepts from Information Theory (IT) and the Theory of Optimal Experimental Design (TOED). The reviewentry includes both qualitative and quantitative analyses of various approaches, deployment scenarios, configurations, path planning methods, and utility functions within A-SLAM research. Furthermore, this article introduces a novel analysis of Active Collaborative SLAM (AC-SLAM), focusing on collaborative aspects within SLAM systems. It includes a thorough examination of collaborative parameters and approaches, supported by both qualitative and statistical assessments. The study also identifies limitations in the existing literature and suggests potential avenues for future research. This survey serves as a valuable resource for researchers seeking insights into A-SLAM methods and techniques, offering a current overview of A-SLAM formulation.
- SLAM
- active SLAM
- information theory
1. Introduction
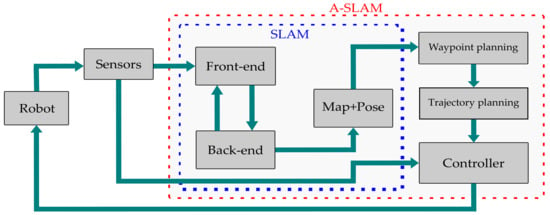
2. A-SLAM Formulation
, where 𝑋∈ℝ represents the robot state space and is represented as the current state 𝑥∈𝑋 and the next state 𝑥′∈𝑋; 𝐴∈ℝ is the action space and can be expressed as 𝑎∈𝐴; O represents the observations where 𝑜∈𝑂; T is the state-transition function between an action (a), present state (x), and next state (𝑥′); T accounts for the robot control uncertainty in reaching the new state 𝑥′; 𝜌𝑜 accounts for sensing uncertainty; 𝛽 is the reward associated with the action taken in state x; and 𝛾∈(0,1) takes into account the discount factor ensuring a finite reward even if the planning task has an infinite horizon. Both T and 𝜌𝑜 can be expressed by using conditional probabilities as Equations (2) and (3):
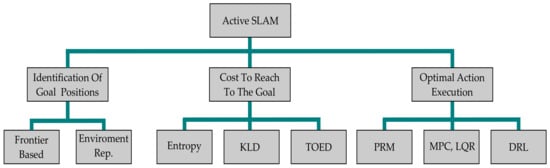
where 𝑥𝑡, 𝑎𝑡, and 𝛾𝑡 are the state, action, and discount factor evolution at time t, respectively. Although the POMDP formulation of A-SLAM is the most widely used approach, it is considered computationally expensive as it considers planning and decision making under uncertainty. For computational convenience, A-SLAM formulation is divided into three main submodules which identify the potential goal positions/waypoints, compute the cost to reach them, and then select actions based on utility criterion, which decreases the map uncertainty and increases the robot’s localization.
3. A-SLAM Components
is the covariance matrix. The map entropy is defined as Equation (7), where the map M is represented as an occupancy grid and each cell 𝑚𝑖,𝑗 is associated with a Bernoulli distribution 𝑃(𝑚𝑖,𝑗). The objective is to reduce both the robot pose and map entropy. Relative entropy is also be used as a utility function that measures the probability distribution along with its deviation from its mean. This relative entropy is measured as the Kullback–Leibler divergence (KLD). The KLD for two discrete distributions A and B on probability space X can be defined as Equation (8):
-
Probabilistic Road Map (PRM) approaches discretize the environment representation and formulate a network graph representing the possible paths for the robot to select to reach the goal position. These approaches work in a heuristic manner and may not give the optimal path; additionally, the robot model is not incorporated in the planning phase, which may result in unexpected movements. Rapidly exploring Random Trees (RRT) [12], D* [13], and A* [14] are the widely used PRM methods.
-
Linear Quadratic Regulator (LQR) and Model Predictive Control (MPC) formulate the robot path-planning problem as an Optimal Control Problem (OCP) and are used to compute the robot trajectory over a finite time horizon in a continuous-planning domain. Consider a robot with the state-transition equation given by 𝑥(𝑘+1)=𝑓(𝑥(𝑘),𝑢(𝑘))
, where x, u, and k are the state, control, and time, respectively. The MPC controller finds the optimal control action 𝑢∗(𝑥(𝑘)) for a finite horizon N, as shown in Equation (12), which minimizes the relative error between the desired state 𝑥𝑟 and desired control effort 𝑢𝑟, weighted by matrices Q and P for the penalization of state and control errors, respectively, as shown in Equation (13). The MPC is formulated as minimizing the objective function 𝐽𝑁 as defined in (14), which takes into account the costs related to control effort and robot state evolution over the entire prediction horizon. MPC provides an optimal trajectory incorporating the robot state model and control and state constraints, making it suitable for path planning in dynamic environments:
4. Geometric Approaches
4.1. IT-Based Approaches
-
Joint entropy: The information gained at the target is evaluated by using the entropy of both the robot trajectory and map carried by each particle weighted by each trajectory’s importance weight. The best exploration target is selected, which maximizes the joint-entropy reduction and hence corresponds to higher information gain.
-
Expected Map Mean: An expected mean can be defined as the mathematical expectation of the map hypotheses of a particle set. The expected map mean can be applied to detect already-traversed loops on the map. Since the computation of the gain is developing, the complexity of this method increases.
-
Expected information from a policy: Kullback–Leibler divergence [17] is used to drive an upper bound on the divergence between the true posterior and the approximated pose belief. Apart from the information consistency of the particle filter, this method also considers the information loss due to inconsistent mapping.
4.2. Frontier-Based Exploration
4.3. Path-Planning Optimization
4.4. Optimization in Robot Trajectory
4.5. Optimal Policy Selection
5. Dynamic Approaches
6. Hybrid Approaches
7. Reasoning over Spectral Graph Connectivity
References
- Gratton, S.; Lawless, A.S.; Nichols, N.K. Approximate Gauss–Newton Methods for Nonlinear Least Squares Problems. SIAM J. Optim. 2007, 18, 106–132.
- Watson, G.A. Lecture Notes in Mathematics. In Proceedings of the 7th Dundee Biennial Conference on Numerical Analysis, Dundee, UK, 28 June–1 July 1977; Springer: Berlin/Heidelberg, Germany, 1978. ISBN 978-3-540-08538-6.
- Placed, J.A.; Strader, J.; Carrillo, H.; Atanasov, N.; Indelman, V.; Carlone, L.; Castellanos, J.A. A survey on active simultaneous localization and mapping: State of the art and new frontiers. IEEE Trans. Robot. 2023, 39, 1686–1705.
- Fox, D.; Burgard, W.; Thrun, S. Active Markov Localization for Mobile Robots. Robot. Auton. Syst. 1998, 25, 195–207.
- Placed, J.A.; Castellanos, J.A. A Deep Reinforcement Learning Approach for Active SLAM. Appl. Sci. 2020, 10, 8386.
- Dhiman, N.K.; Deodhare, D.; Khemani, D. Where Am I? Creating Spatial Awareness in Unmanned Ground Robots Using SLAM: A Survey. Sadhana 2015, 40, 1385–1433.
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332.
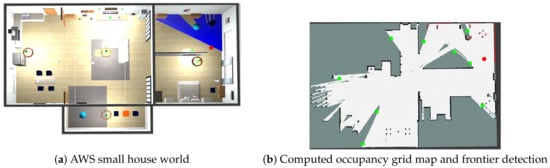
- Yamauchi, B. A frontier-based approach for autonomous exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97, ‘Towards New Computational Principles for Robotics and Automation’, Monterey, CA, USA, 10–11 July 1997; pp. 146–151.
- Available online: https://github.com/aws-robotics/aws-robomaker-small-house-world (accessed on 10 January 2023).
- Pázman, A. Foundations of Optimum Experimantal Design; Springer: Berlin/Heidelberg, Germany, 1996; Volume 14.
- Stachniss, C.; Grisetti, G.; Burgard, W. Information Gain-Based Exploration Using Rao-Blackwellized Particle Filters. In Proceedings of the Robotics: Science and Systems I, Massachusetts Institute of Technology, Cambridge, MA, USA, 8 June 2005; pp. 65–72.
- Naderi, K.; Rajamäki, J.; Hämäläinen, P. RT-RRT*: A real-time path planning algorithm based on RRT*. In Proceedings of the 8th ACM SIGGRAPH Conference on Motion in Games, Paris, France, 16–18 November 2015; pp. 113–118.
- Stentz, A. The D* Algorithm for Real-Time Planning of Optimal Traverses; Technical Report; CMU-RI-TR-94-37; Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 1994.
- Liu, X.; Gong, D. A comparative study of A-star algorithms for search and rescue in perfect maze. In Proceedings of the 2011 International Conference on Electric Information and Control Engineering, Wuhan, China, 15–17 April 2011.
- Vallve, J.; Andrade-Cetto, J. Active pose slam with RRT. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015.
- Du, J.; Carlone, L.; Kaouk, N.M.; Bona, B.; Indri, M. A comparative study on A-SLAM and autonomous exploration with particle filters. In Proceedings of the 2011 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Budapest, Hungary, 3–7 July 2011; pp. 916–923.
- Carlone, L.; Du, J.; Kaouk, N.M.; Bona, B.; Indri, M. A-SLAM and exploration with particle filters using Kullback-Leibler divergence. J. Intell. Robot. Syst. 2013, 75, 291–311.
- Mu, B.; Giamou, M.; Paull, L.; Agha-Mohammadi, A.; Leonard, J.; How, J. Information-based A-SLAM via topological feature graphs. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016.
- Trivun, D.; Salaka, E.; Osmankovic, D.; Velagic, J.; Osmic, N. A-SLAM-based algorithm for autonomous exploration with Mobile Robot. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015.
- Mammolo, D. A-SLAM in Crowded Environments. Master’s Thesis, Autonomous Systems Lab, ETH Zurich, Zurich, Switzerland, 2019.
- Kaess, M.; Ranganathan, A.; Dellaert, F. ISAM: Incremental Smoothing and Mapping. IEEE Trans. Robot. 2008, 24, 1365–1378.
- Chaves, S.M.; Eustice, R.M. Efficient planning with the Bayes Tree for A-SLAM. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016.
- Suresh, S.; Sodhi, P.; Mangelson, J.G.; Wettergreen, D.; Kaess, M. A-SLAM using 3D SUBMAP saliency for underwater volumetric exploration. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020.
- Maurovic, I.; Seder, M.; Lenac, K.; Petrovic, I. Path Planning for Active SLAM Based on the D* Algorithm with Negative Edge Weights. IEEE Trans. Syst. Man Cybern Syst. 2018, 48, 1321–1331.
- Hsiao, M.; Mangelson, J.G.; Suresh, S.; Debrunner, C.; Kaess, M. ARAS: Ambiguity-aware robust A-SLAM based on multi-hypothesis state and map estimations. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021.
- Lenac, K.; Kitanov, A.; Maurović, I.; Dakulović, M.; Petrović, I. Fast Active SLAM for Accurate and Complete Coverage Mapping of Unknown Environments. In Intelligent Autonomous Systems 13; Menegatti, E., Michael, N., Berns, K., Yamaguchi, H., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2016; Volume 302, pp. 415–428. ISBN 978-3-319-08337-7.
- Ekman, A.; Torne, A.; Stromberg, D. Exploration of polygonal environments using range data. IEEE Trans. Syst. Man, Cybern. Part B 1997, 27, 250–255.
- Eustice, R.M.; Singh, H.; Leonard, J.J. Exactly Sparse Delayed-State Filters for View-Based SLAM. IEEE Trans. Robot. 2006, 22, 1100–1114.
- Sökmen, Ö.; Emeç, Ş.; Yilmaz, M.; Akkaya, G. An Overview of Chinese Postman Problem. In Proceedings of the 3rd International Conference on Advanced Engineering Technologies, Turkey, 19–20 September 2019.
- Li, G.; Geng, Y.; Zhang, W. Autonomous Planetary Rover Navigation via A-SLAM. Aircr. Eng. Aerosp. Technol. 2018, 91, 60–68.
- He, Y.; Liang, B.; Yang, J.; Li, S.; He, J. An iterative closest points algorithm for registration of 3D laser scanner point clouds with geometric features. Sensors 2017, 17, 1862.
- Carrillo, H.; Reid, I.; Castellanos, J.A. On the comparison of uncertainty criteria for A-SLAM. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012.
- Rodriguez-Arevalo, M.L.; Neira, J.; Castellanos, J.A. On the importance of uncertainty representation in A-SLAM. IEEE Trans. Robot. 2018, 34, 829–834.
- Carrillo, H.; Latif, Y.; Rodriguez-Arevalo, M.L.; Neira, J.; Castellanos, J.A. On the Monotonicity of optimality criteria during exploration in A-SLAM. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015.
- Bemporad, A. Model predictive control design: New trends and tools. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 6678–6683.
- Jayaweera, S.K. Markov decision processes. In Signal Processing for Cognitive Radios; Wiley: Hoboken, NJ, USA, 2015; pp. 207–268.
- Qiang, W.; Zhongli, Z. Reinforcement learning model, algorithms and its application. In Proceedings of the 2011 International Conference on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, 19–22 August 2011; pp. 1143–1146.
- Martinez-Marin, T.; Lopez, E.; De Bernardis, C. An unified framework for A-SLAM and Online Optimal Motion Planning. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011.
- Wen, S.; Zhao, Y.; Yuan, X.; Wang, Z.; Zhang, D.; Manfredi, L. Path planning for A-SLAM based on deep reinforcement learning under unknown environments. Intell. Serv. Robot. 2020, 13, 263–272.
- Andrade, F.; LLofriu, M.; Tanco, M.M.; Barnech, G.T.; Tejera, G. Active localization for mobile service robots in symmetrical and Open Environments. In Proceedings of the 2021 Latin American Robotics Symposium (LARS), 2021 Brazilian Symposium on Robotics (SBR), and 2021 Workshop on Robotics in Education (WRE), Natal, Brazil, 11–15 October 2021.
- Liu, Y.; Zhu, D.; Peng, J.; Wang, X.; Wang, L.; Chen, L.; Li, J.; Zhang, X. Robust active visual slam system based on Bionic Eyes. In Proceedings of the 2019 IEEE International Conference on Cyborg and Bionic Systems (CBS), Munich, Germany, 18–20 September 2019.
- Bonetto, E.; Goldschmid, P.; Pabst, M.; Black, M.J.; Ahmad, A. iRotate: Active visual slam for Omnidirectional Robots. Robot. Auton. Syst. 2022, 154, 104102.
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 623–656.
- Findeisen, R.; Allgöwer, F. An introduction to nonlinear model predictive control. In Proceedings of the 21st Benelux Meeting on Systems and Control, Veldhoven, The Netherlands, 19–21 March 2002.
- Chen, Y.; Huang, S.; Fitch, R. A-SLAM for mobile robots with area coverage and obstacle avoidance. IEEE/ASME Trans. Mechatronics 2020, 25, 1182–1192.
- Chen, Y.; Huang, S.; Fitch, R.; Yu, J. Efficient A-SLAM based on submap joining, graph topology and convex optimization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018.
- Khosoussi, K.; Sukhatme, G.S.; Huang, S.; Dissanayake, G. Maximizing the Weighted Number of Spanning Trees: Near-t-Optimal Graphs. arXiv 2016, arXiv:1604.01116.
- Khosoussi, K.; Giamou, M.; Sukhatme, G.S.; Huang, S.; Dissanayake, G.; How, J.P. Reliable Graphs for SLAM. Int. J. Robot. Res. 2019, 38, 260–298.
- Placed, J.A.; Castellanos, J.A. A General Relationship Between Optimality Criteria and Connectivity Indices for Active Graph-SLAM. IEEE Robot. Autom. Lett. 2023, 8, 816–823.
- Placed, J.A.; Rodríguez, J.J.G.; Tardós, J.D.; Castellanos, J.A. ExplORB-SLAM: Active Visual SLAM Exploiting the Pose-graph Topology. In Proceedings of the Fifth Iberian Robotics Conference. ROBOT 2022. Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2023; Volume 589.
- Placed, J.A.; Castellanos, J.A. Fast Autonomous Robotic Exploration Using the Underlying Graph Structure. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September 2021; pp. 6672–6679.
- Deray, J.; Solà, J. Manif: A micro Lie theory library for state estimation in robotics applications. J. Open Source Softw. 2020, 5, 1371.