Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Rita Xu and Version 1 by LI Xin.
Scene matching plays a vital role in the visual positioning of aircraft. The position and orientation of aircraft can be determined by comparing acquired real-time imagery with reference imagery. To enhance precise scene matching during flight, it is imperative to conduct a comprehensive analysis of the reference imagery’s matchability beforehand. Conventional approaches to image matchability analysis rely heavily on features that are manually designed.
- aircraft navigation
- scene matching
- saliency
1. Introduction
Scene matching technique refers to the real-time matching of imagery captured by aircraft with pre-prepared reference imagery, providing precise positioning for high-accuracy autonomous navigation of the aircraft [1,2][1][2]. The utilization of scene matching in assisted navigation is widely applied in both military and civilian domains, particularly in the military sector where it serves as a dependable technological assurance for accurate weapon guidance. The emergence of various image matching operators in the field of vision has overcome the technical bottleneck that previously constrained scene matching algorithms [3[3][4][5],4,5], as shown in Figure 1. Currently, addressing the challenge of matchability analysis for reference imagery as a supportive technical measure is crucial [6].
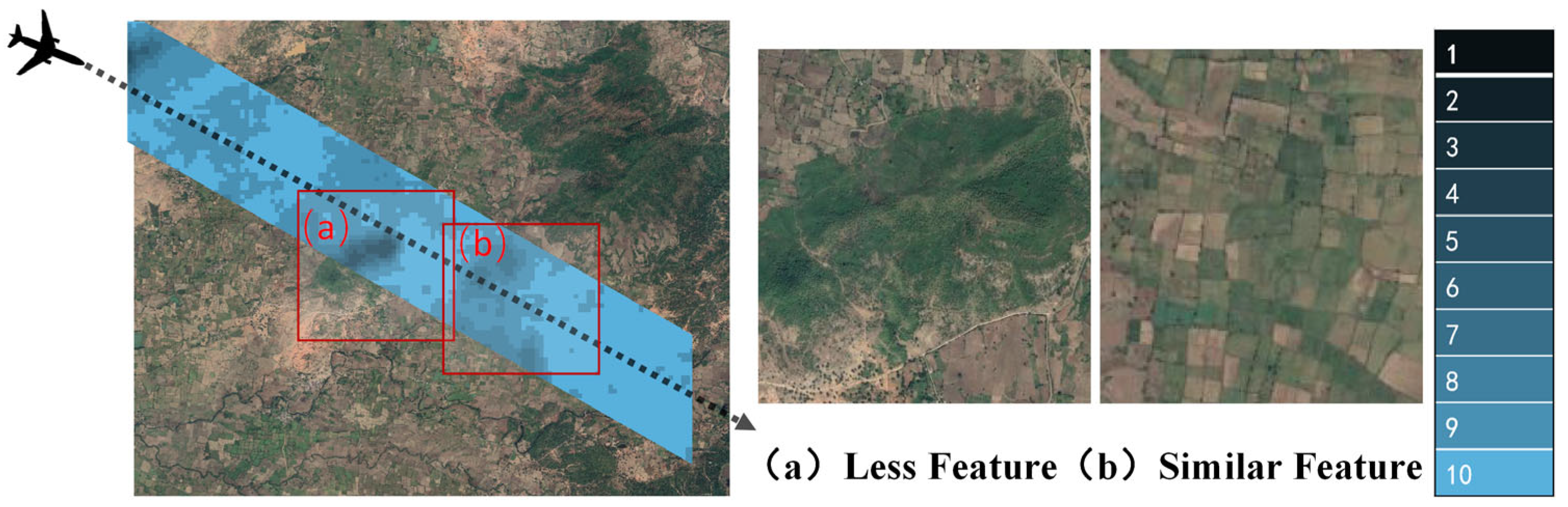
Figure 1. Illustration of the analysis of matchability in reference imagery for aircraft. (a) indicates areas with fewer features; (b) indicates areas with similar features. Both (a,b) are examples of areas that are not applicable to scene matching navigation. The blue legend from 1 to 10 on the right side of the figure represents the matchability rating of the reference image, with a high score indicating the level of matchability of the image.
Matchability analysis is the process of extracting multi-source feature parameters from images and establishing a mapping model between feature parameters and the matching probability. The matchability performance of the reference imagery directly determines the accuracy of aircraft positioning. Consequently, it is important to adhere to principles [6] such as prominent object features, abundant information content in the image regions, exceptional uniqueness, and fulfillment of size requisites when selecting scene matching reference imagery.
The classic methods for matchability analysis typically involve constructing mapping models using manually designed features. However, they often lack consideration for the scene matching process. Different design principles for features and threshold parameter settings can yield varying results in terms of matchable regions. Therefore, traditional methods suffer from poor generality, high computational complexity, and low efficiency, leading to subpar application performance.
As one of the most important foundational technologies in artificial intelligence, deep learning has gradually extended its reach to the field of image analysis in recent years. Its applications in image classification, object recognition, and detection have become increasingly widespread. Representing the matchability of imagery solely with local shallow features is challenging due to the complex nature of this region-based feature, which lacks specific morphological characteristics. Deep learning models, on the other hand, overcome the limitations of traditional matchability analysis algorithms by automatically learning complex and latent features in images through training neural networks. They exhibit stronger adaptability and generalization capabilities [7].
Currently, research on matchability analysis based on deep learning is relatively lacking. There are two main challenges in matchability analysis: (1) Lack of reliable open-source datasets. Deep learning techniques require a significant amount of specialized analysis and experimentation to support high-dimensional abstraction of matchability features in different scenarios. (2) Lack of feature extraction networks suitable for matchability analysis. Existing feature extraction networks lack research on the application scenarios and characteristics of matchability analysis. Unlike other feature extraction applications, matchable regions have low feature distinctiveness and an abundant amount of information in atypical structures that do not possess specific morphological characteristics, such as regions with obvious inflection points. Conventional neural networks (CNN) have low accuracy in feature extraction and selection, making it difficult to characterize and extract common features from matchable regions compared to highly discriminative and recognizable objects such as vehicles or ships.
2. Classical Methods
Classic matchability analysis methods are based on measuring the complexity of image information. They can generally be categorized into two types: hierarchical filtering-based and global analysis-based methods. The first type of method employs feature metrics to iteratively filter out regions that do not meet the threshold conditions based on template size, ultimately determining the final matchable region. However, it is important to note that this method may lead to the matchable region not being the best possible match for the entire image. The second method thoroughly evaluates all pixels in the image by utilizing feature evaluations. It accurately detects the region with the highest number of matchable points or the most effective matchable region. Despite its high computational cost, this method is capable of identifying the globally optimal matchable region. Overall, classic matchability analysis methods typically involve two steps: defining features and feature assessments [8]. Defining features refers to defining feature indicators that reflect the matchability performance of the input image by reducing the dimensionality of the data or restructuring its structure. In 1972, Johnson [9] first proposed the theory and method of selecting matchable regions. Since then, researchers have proposed using image descriptive feature parameters such as grayscale variance, edge density, number of independent pixels, information entropy, and self-repeating patterns to differentiate regions suitable for matching from those unsuitable for matching through hierarchical filtering [10,11,12,13][10][11][12][13]. Wei [14] proposed a matchability estimation method by establishing a correlation model between signal-to-noise ratio and matching accuracy. Giusti [15] used non-downsampling to extract local extrema points as interest points and filtered the matching region based on the amplitude and structural characteristics of the interest points. However, a single feature cannot reflect global characteristics, and this limitation can lead to significant errors in matching under certain circumstances. Therefore, multiple feature indicators need to be combined to comprehensively evaluate the performance of image matching. Yang [16] proposed a matchable region selection method based on pattern recognition, which selected six image features to construct an image feature descriptor and used support vector machines to establish a classification decision function for selecting matchable regions. However, this method requires calculating unique features for each candidate image, which is time-consuming. In addition, if new image categories need to be processed, it is necessary to remake training data and retrain the model. Zhang [17] proposed a method for selecting SAR matchable regions using a combination weighting method that combines four traditional feature indicators, including edge density, number of independent pixels, information entropy, and main-to-secondary peak ratio, as weights to achieve a more comprehensive and accurate selection of matchable regions. Feature assessment refers to the process of selecting matchable regions based on threshold values of feature indicators. Xu et al. [18] first select different candidate regions and then evaluate these regions based on feature comparisons to obtain matchable regions. Cai [19] uses the Analytic Hierarchy Process to comprehensively evaluate the matchable regions and divide them into matchable and non-matchable regions. Luo [20] first calculates feature indicators for each pixel and then formulates a matchable region selection strategy based on the number of points exceeding the threshold and the distance interval in the matchable region. These methods employ various criteria and techniques to assess the suitability of regions for matching based on feature indicators. By comparing and evaluating these indicators, the methods determine the matchable regions and separate them from non-matchable regions. The selection strategies may vary depending on the specific thresholds and criteria applied in each method. Indeed, the mentioned methods heavily rely on domain knowledge for statistical analysis of image grayscale values to design feature extractors, making the handcrafted features specific to certain scenarios. Furthermore, these methods only consider the requirements of matchable regions and overlook the demands of matching algorithms. However, matchability is often influenced by imaging conditions, and handcrafted features are not robust and general enough to adapt to real-time geometric distortion and color variations in images.3. Matchability Analysis Based on Deep Learning
The field of image classification has been greatly impacted by deep learning, prompting several researchers to suggest matchability analysis methods utilizing deep learning models. With massive volumes of data, these methods imitate the feature representations of reference and target images in the matching process by leveraging the tremendous data fitting capabilities of CNN. By training the network, they obtain a mapping function that can assess the degree of matchability. In the work by Wang [21], CNN features were first applied to matchability analysis of images. However, this method only considered the intrinsic features of the images and ignored the influence of the matching process on matchability, resulting in limited generalizability. Sun [22] proposed a method to generate a reference image sample library by simulating real-time images and then utilized a ResNet network for matchable region classification. Similarly, Yang Jiao [23] constructed a dataset using a similar approach and performed matchability regression analysis using both ResNet-50 and AlexNet. The fixed receptive field of convolutional operations limits the integration of global features, making it challenging to describe the global information of features. ResNet [24,25,26][24][25][26] was proposed to address this issue and has been applied in various fields such as model mapping estimation, target area feature recognition, and land object segmentation. It further optimizes the ResNet architecture by introducing a multi-branch structure and improving the feature representation capability. In addition, the introduction and widespread use of Transformer [27] and self-attention mechanisms [28] have greatly improved the utilization of global information in images. By reallocating the weights of image feature extraction, these methods achieve multi-dimensional feature extraction capabilities for scene matching. Sun et al. [29] proposed an F3-Net network suitable for constructing the mapping relationship between unmanned aircraft scene images and reference imagery. The network leverages the self-attention mechanism and generates the probability distribution of features in the scene image based on semantic consistency. Similarly, the study by Arjovsky et al. [30] also achieved the probability distribution of high-level semantic features between scene images and reference imagery. By considering the global information and semantic coherence, these methods aim to enhance the matchability analysis and improve the accuracy and robustness of scene matching. Directly applying feature extraction networks from the computer vision field to matchability analysis is challenging due to the unique evaluation criteria and requirements of the analysis. Currently, there is a shortage of deep learning techniques that are tailored for matchability analysis of reference imagery. To effectively analyze matchability of aircraft reference imagery based on region-level scene perception, it is crucial to design specialized network architectures. This design is intended to provide reliable information about the reference imagery for scene matching.References
- Wang, J.Z. Research on Key Technologies of Scene Matching Areas Selection of Cruise Missile. Master’s Thesis, National University of Defense Technology, Changsha, China, 2015.
- Lu, Y.; Xue, Z.; Xia, G.-S.; Zhang, L. A survey on vision-based UAV navigation. Geo-Spat. Inf. Sci. 2018, 21, 21–32.
- Leng, X.F. Research on the Key Technology for Scene Matching Aided Navigation System Based on Image Features. Ph.D. Thesis, Nanjing University of Aeronautics and Astronautics, Nanjing, China, 2007.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90.
- Watts, A.C.; Ambrosia, V.G.; Hinkley, E.A. Unmanned Aircraft Systems in Remote Sensing and Scientific Research: Classification and Considerations of Use. Remote Sens. 2012, 4, 1671–1692.
- Shen, L.; Bu, Y. Research on Matching-Area Suitability for Scene Matching Aided Navigation. Acta Aeronaut. Astronaut. Sin. 2010, 31, 553–563.
- Jia, D.; Zhu, N.D.; Yang, N.H.; Wu, S.; Li, Y.X.; Zhao, M.Y. Image matching methods. J. Image Graph. 2019, 24, 677–699.
- Zhao, C.H.; Zhou, Z.H. Review of scene matching visual navigation for unmanned aerial vehicles. Sci. Sin. Inf. 2019, 49, 507–519.
- Johnson, M. Analytical development and test results of acquisition probability for terrain correlation devices used in navigation systems. In Proceedings of the 10th Aerospace Sciences Meeting, San Diego, CA, USA, 17–19 January 1972; p. 122.
- Zhang, X.; He, Z.; Liang, Y.; Zeng, P. Selection method for scene matching area based on information entropy. In Proceedings of the 2012 Fifth International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 28–29 October 2012; Volume 1, pp. 364–368.
- Cao, F.; Yang, X.G.; Miao, D.; Zhang, Y.P. Study on reference image selection roles for scene matching guidance. Appl. Res. Comput. 2005, 5, 137–139.
- Yang, X.; Cao, F.; Huang, X. Reference image preparation approach for scene matching simulation. J. Syst. Simul. 2010, 22, 850–852.
- Pang, S.N.; Kim, H.C.; Kim, D.; Bang, S.Y. Prediction of the suitability for image-matching based on self-similarity of vision contents. Image Vis. Comput. 2004, 22, 355–365.
- Wei, D. Research on SAR Image Matching. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2011.
- Ju, X.N.; Guo, W.P.; Sun, J.Y.; Gao, J. Matching probability metric for remote sensing image based on interest points. Opt. Precis. Eng. 2014, 22, 1071–1077.
- Yang, C.H.; Cheng, Y.Y. Support Vector Machine for Scene Matching Area Selection. J. Tongji Univ. Nat. Sci. 2009, 37, 690–695.
- Zhang, Y.Y.; Su, J. SAR Scene Matching Area Selection Based on Multi-Attribute Comprehensive Analysis. J. Proj. Rocket. Missiles Guid. 2016, 36, 104–108.
- Xu, X.; Tang, J. Selection for matching area in terrain aided navigation based on entropy-weighted grey correlation decision-making. J. Chin. Inert. Technol. 2015, 23, 201–206.
- Cai, T.; Chen, X. Selection criterion based on analytic hierarchy process for matching region in gravity aided INS. J. Chin. Inert. Technol. 2013, 21, 93–96.
- Luo, H.; Chang, Z.; Yu, X.; Ding, Q. Automatic suitable-matching area selection method based on multi-feature fusion. Infrared Laser Eng. 2011, 40, 2037–2041.
- Wang, J.Z. Research on Matching Area Selection of Remote Sensing Image Based on Convolutional Neural Networks. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2016.
- Sun, K. Scene Navigability Analysis Based on Deep Learning Model. Master’s Thesis, National University of Defense Technology, Changsha, China, 2019.
- Yang, J. Suitable Matching Area Selection Method Based on Deep Learning. Master’s Thesis, Huazhong University of Science and Technology, Wuhan, China, 2019.
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995.
- Kortylewski, A.; Liu, Q.; Wang, A.; Sun, Y.; Yuille, A. Compositional convolutional neural networks: A robust and interpretable model for object recognition under occlusion. Int. J. Comput. Vis. 2021, 129, 736–760.
- Cao, J.; Leng, H.; Lischinski, D.; Cohen-Or, D.; Tu, C.; Li, Y. ShapeConv: Shape-aware convolutional layer for indoor RGB-D semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7068–7077.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10073–10082.
- Sun, B.; Liu, G.; Yuan, Y. F3-Net: Multiview Scene Matching for Drone-Based Geo-Localization. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11.
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223.
More