Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Catherine Yang and Version 1 by Avinash Singh.
The growing sophistication of malware has resulted in diverse challenges, especially among security researchers who are expected to develop mechanisms to thwart these malicious attacks. While security researchers have turned to machine learning to combat this surge in malware attacks and enhance detection and prevention methods, they often encounter limitations when it comes to sourcing malware binaries and datasets.
- malware
- malware feature engineering
- malware datasets
- malware detection
1. MalFe Platform
The Malware Feature Engineering (MalFe) platform aims to simplify the difficulty of obtaining and creating custom datasets from a databank through a community-driven platform. To ensure a scientific process, the design approach leverages software engineering principles to develop the processes and features of the platform. On a high level, MalFe contains five key components: Reports, Categories, User Code, Dataset Generator, and Datasets, as depicted in Figure 1. The reports consist of raw Cuckoo Sandbox reports which, are uploaded by the community from experiments run to analyze malware samples. The categories help with organizing these reports, allowing more targeted datasets to be built. User code is used to parse through this data repository of reports and extract the relevant information required to generate a dataset. The user code is then fed into a dataset generator, which runs on a queue basis and executes the user code, based on the selected categories of reports, resulting in a dataset being generated. After being approved by their creator(s), these datasets are then made available for public viewing.
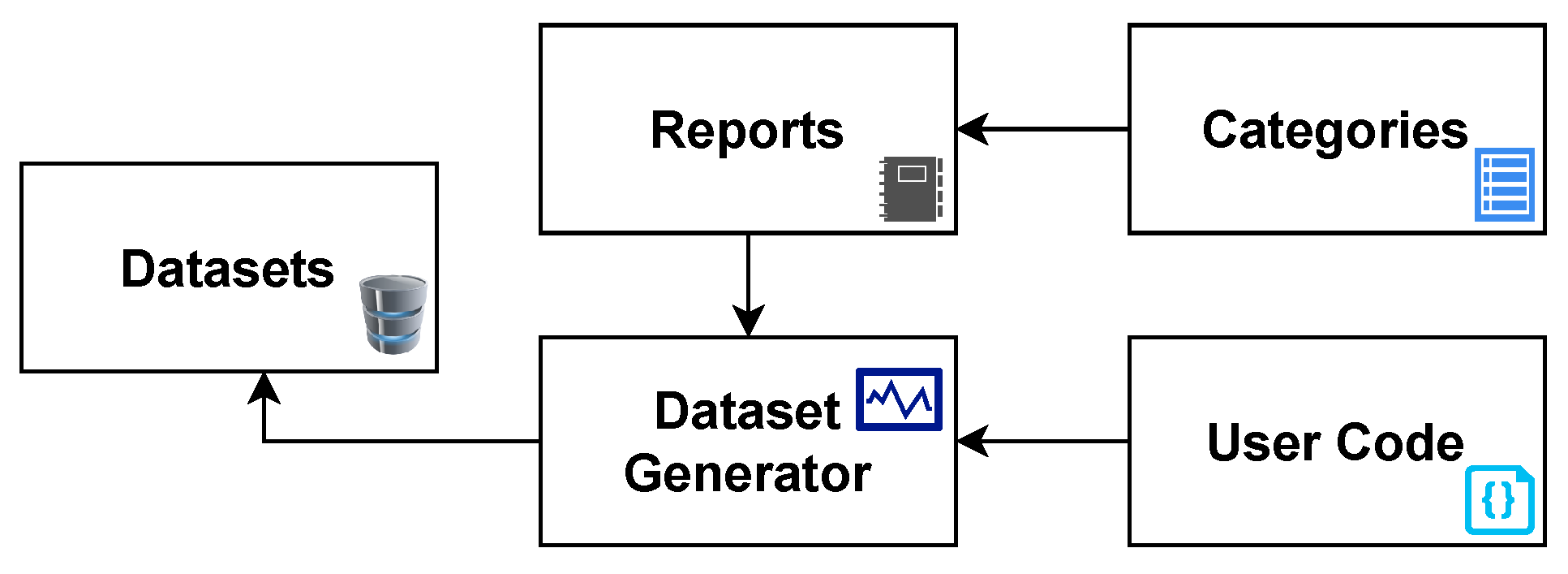
Figure 1.
MalFe high-level model.
The MalFe process model is shown in Figure 2; in order to prevent misuse and to grow trust on the platform, this process starts with account creation and verification. After successful authentication, a user is able to browse the existing datasets that have been generated by the community. Thereafter, a user can search for a dataset that matches their need. In the event that the dataset does not exist on the platform yet, the user has the option to browse the uploaded Cuckoo Sandbox reports to see whether the information needed to build the dataset is available. If the information is not sufficient, the user needs to source more reports, either through experimentation or by obtaining them from an external source. Due to the often substantial size of these reports, it can be challenging and often impractical to download all of them for the purpose of data investigation.
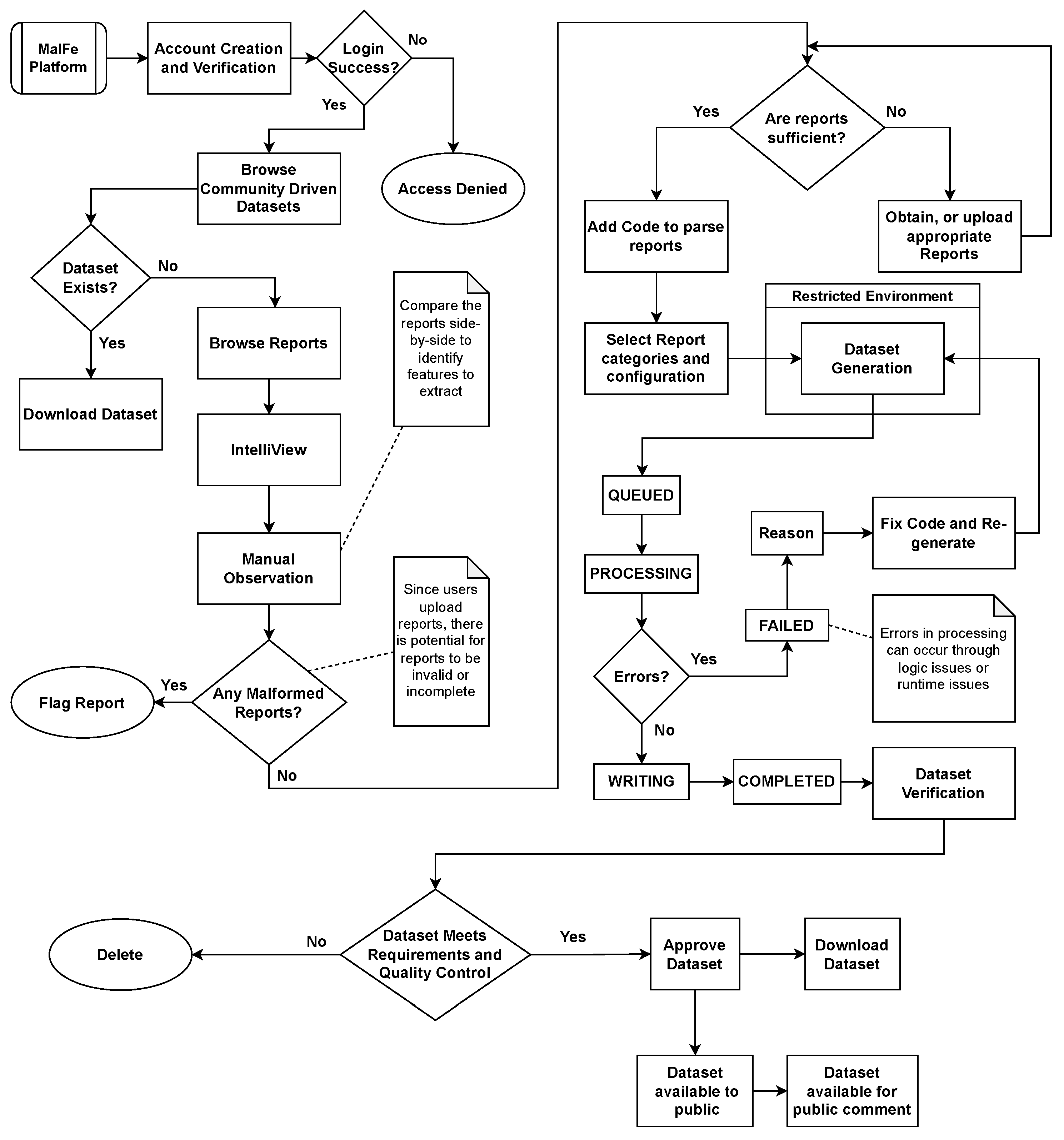
Figure 2.
MalFe process model.
To solve this problem, a lightweight comparison tool called IntelliView was created and added to the platform. It allows end users to browse sections of reports, making it easier to browse and compare reports. After manual observation conducted through IntelliView, if the user finds any malformed or erroneous reports they can flag these reports, ensuring that high-quality data are always available to the community and further enhancing the trust in the platform. At this stage, the reports are sufficient, and quality control has been conducted. The next step is for the user to add code to allow these reports to be parsed in order to extract the information needed to build the dataset. When this is complete, the metadata needed for the platform to build the dataset is requested from the user. This includes the category of reports for the dataset to be built off, as well as the name and description of the dataset. After the user code is checked for security vulnerabilities and syntax errors, the code is successfully queued on the platform to generate the dataset in a restricted environment. The process of dataset generation involves several status changes, keeping the user aware of what is happening. If the status is set to QUEUED, this means that the dataset has been added to a queue; the next generated dataset is taken from the queue when the previous dataset has been completed. This then sets the dataset generation status to PROCESSING. The processing stage of dataset generation is the core functionality of the platform, providing users with the ability to design the data according to their specific requirements. Error handling is integrated into the platform as well, providing an opportunity to understand any misconfiguration or other sources of errors during the data generation process. After dataset generation is completed, the data are written to a CSV file and saved on the platform, and the status is set to COMPLETE. The owner is then prompted to verify the dataset and perform quality checking. When approved by the owner, the dataset is made publicly available. Finally, the dataset is available to be downloaded, shared, and even commented on for further research and networking with security professionals. The next section discusses the technical details behind the implementation of the platform.
MalFe Implementation
The platform was developed following a modular approach and in line with agile principles to ensure adaptability and flexibility. Python, renowned for its versatility and wealth of built-in frameworks and libraries, was the language of choice for the implementation. To facilitate seamless web-based management, the Django web framework was chosen, which is a robust and widely respected choice in the field [33][1]. Security remains a paramount concern, and the platform integrates multiple layers of defense. Django’s default security middleware forms the first line of protection, followed by custom sanitization middleware. This custom middleware diligently scrubs metadata of any special characters and tags, further fortifying the security posture of the platform. The critical middleware components in play are SecurityMiddleware, SessionMiddleware, CsrfViewMiddleware, AuthenticationMiddleware, XFrameOptionsMiddleware, OTPMiddleware, and SessionSecurityMiddleware. In the realm of authentication, Two-Factor Authentication (2FA) was implemented to enhance security. This robust 2FA mechanism is mandatory for logging in and is integrated seamlessly into the user experience. Users have the convenience of utilizing either a token generator or physical keys. Token generators leverage the Time-Based One-Time Pin (TOTP) algorithm [34][2], producing 6–8 unique digits based on the current time and a secret key established during account registration. As a security measure, these tokens regenerate every 30 seconds, thwarting brute force and phishing attacks. Additionally, backup tokens are accessible in case the primary 2FA devices are unavailable, ensuring both recovery and security. The default Django password field was used, which is fortified with PBKDF2 utilizing robust SHA256-bit hashing and a random salt [33][1]. Furthermore, email verification is enforced, fostering trust and ensuring the integrity of user accounts.
The process of adding a Cuckoo report to the platform is simplified, as the report undergoes rigorous scrutiny, with essential metadata such as the SHA256 hash, name, and description being extracted and validated. A further layer of scrutiny involves an assessment for any analysis errors before the report is deemed suitable for upload, ensuring the preservation of raw data integrity. For added convenience, the platform seamlessly integrates with Cuckoo Sandbox, enabling users to upload samples directly. These samples are then enqueued for execution within the sandbox environment, and the report is subsequently automatically integrated into the platform. The IntelliView feature represents a unique and innovative approach to manual observation, and was achieved through the implementation of asynchronous calls, with data being clipped to enhance performance and usability.
The way datasets are created is a novel feature in which a user provides the code to process an individual report, thereby extracting the data and features needed for building the dataset. A portion of the code responsible for executing user-generated code can be seen in Figure 3.

Figure 3.
User code execution snippet.
This is achieved by users implementing a stub function that is fed the Cuckoo report, filename, SHA256 hash, and category, as well as whether or not it is a malicious sample. Since the platform doesn't impose limitations on features, users can have as many features as they need. Furthermore, because executing user code is a security risk, the code is first checked for syntactical errors using an abstract syntax tree. RestrictedPhyton [35][3], which acts as a Python environment with limited imports and functions, is used to execute the user code. Safe built-ins and safe globals are used to ensure additional security and usability. To improve speed, concurrency is utilized with thread pools, allowing faster processing of Cuckoo reports and feature generation. A cron job is used to create the datasets, resulting in a queue system that limits potential resource abuse. Furthermore, each dataset has a maximum execution time.
2. MalFe Validation
The NIST validation cycle is shown in Figure 4. The first step is to define requirements for the platform, followed by test assertions defining the behaviour of how the system should act. Next, the test cases which test the requirements are defined, and verification is performed to check whether the test assertions have been achieved. Finally, test methodology and validation are reached. The system requirements consist of two categories: Core Requirements (CR), which are listed in Table 1, and Optional Requirements (OR), which can be found in Table 2. For example, in Table 1, the label column provides a reference number that is used in the compliance matrix. The description, on the other hand, provides the requirements for the platform.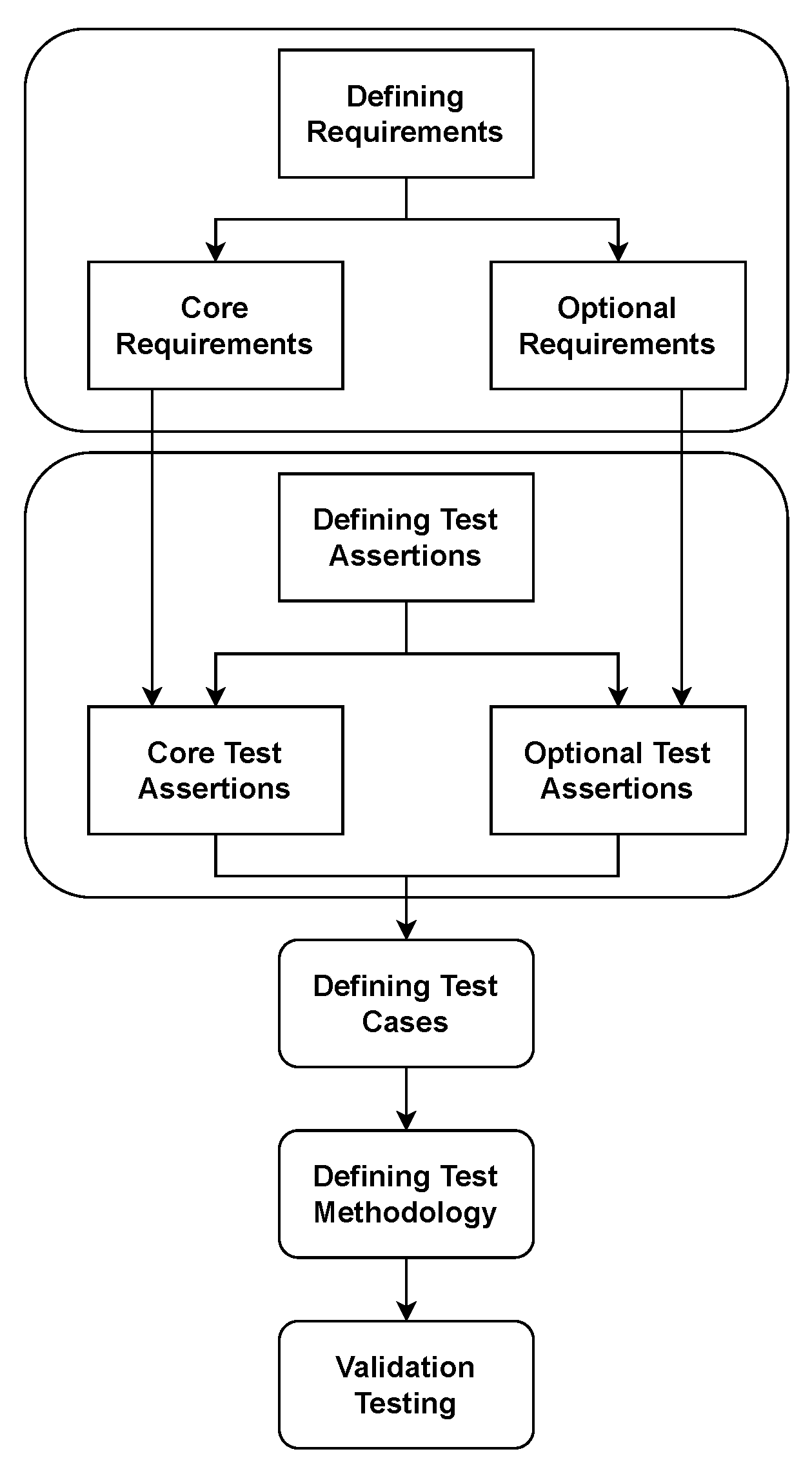
Table 1.
Core requirements.
| Label | Description |
|---|
Table 2.
Optional requirements.
| Label | Description |
|---|---|
| CR-01 | The system should allow for secure access through accounts. |
| TA-01 | Restricted and secure access. Justification: To preserve trust and integrity on the platform; only authorized parties who are verified should be able to use the platform. |
| CR-02 | Accounts should be verified and use 2-factor authentication for additional security. |
| TA-02 | |
Table 4.
Test cases.
| Label | Description |
|---|---|
| TC-01 | Create an account and perform the verification. |
| OR-02 | Users should be able to comment on datasets. |
Table 5.
Compliance matrix.
| No. | Requirement | Test Case | Result | ||||
|---|---|---|---|---|---|---|---|
| Hash digests of the reports and datasets should be computed. | Justification: To maintain integrity and eliminate any duplicates from occurring. |
||||||
| 1 | CR-01 | TC-01 | TA-01 | ||||
| TC-02 | Turn on 2-factor authentication and verify that it works as expected. | ||||||
| 2 | CR-02 | TC-02 | TA-01, –check– | CR-03 | Users should be able to upload Cuckoo Reports. | ||
| OR-03 | Users should be able to see the status of dataset generation. | TA-03 | Metadata sanitization of user data. |
CR-04 | Duplicate Cuckoo Reports and Datasets should not exist. | ||
| OR-04 | |||||||
| TC-03 | Justification: To ensure good security practices and prevent potential system attacks. This reduces the attack vectors from injection attacks like XSS, SQL injection, and parsing attacks. | ||||||
| View the reports on the platform. | Users should be informed why dataset generation failed and allowed to fix issues. | ||||||
| 3 | CR-03 | TC-03, TC-05 | TA-03, TA-05, –check– | TA-04 | The platform shall detect syntactical errors with the user code and/or malicious code. Justification: To eliminate any errors as well as improve the reliability and security of the system. |
||
| TC-04 | View the datasets on the platform. | ||||||
| 4 | CR-04 | CR-05 | |||||
| OR-05 | Users should be able to see the reports on the platform. | ||||||
| TC-06 | TA-05Users should be able to flag reports for quality control. | The platform shall log the activity of users. |
CR-06 | Users can choose to upload private reports. | |||
| OR-06 | Users should be able to download reports and view them on Virus Total. | CR-07 | Users can create datasets on the platform. | ||||
| TA-02 | TC-05Justification: To ensure security and prevent abuse. | Upload a report on the platform. | |||||
| 5 | CR-05 | TC-03 | –check– | OR-07 | Users should be able to search for reports and filter by category.CR-08 | Users can choose to create private datasets. | |
| TC-06 | |||||||
| 6 | Upload an existing report on the platform. | ||||||
| CR-06 | TC-05 | –check– | TC-07 | Create a dataset with syntax errors in the code and malicious code. | |||
| 7 | CR-07 | TC-07, TC-08 | TA-04, –check– | OR-08 | Users should be able to see the reports used in a dataset. | TC-08 | Create a dataset without errors. |
| 8 | CR-08, CR-09 | TC-08 | TA-04, –check– | CR-09 | Users should easily be able to select the report categories of reports for dataset generation. | ||
| OR-09 | Users should be able to create versions of a dataset with different report categories. | TC-09 | Download a dataset. | ||||
| 9 | CR-10 | TC-04, TC-10, TC-11 | –check– | CR-10 | Users should be able to view datasets on the platform. | ||
| TC-10 | CR-11 | User code should be checked for security vulnerabilities. | |||||
| CR-12 | User code should be executed in a restricted environment. | ||||||
| CR-13 | User code should be syntax-checked to minimize runtime errors. | ||||||
| CR-14 | Users should be able to download datasets. | ||||||
| CR-15 | Users should be able to view a sample of the dataset. |
| OR-01 | Users should be able to see which datasets are used in publications. |
| OR-10 | |
| Users can turn off comments on their dataset. | |
Table 3.
Test assertions.
| Label | Description | ||||
|---|---|---|---|---|---|
| View the code of the dataset. | |||||
| 10 | |||||
| CR-11, CR-12, CR-13 TC-07 | |||||
| TA-03, TA-04, –check– | |||||
| TC-11 | |||||
| 11 | View the reports used in a dataset. | ||||
| CR-14 | TC-09 | –check– | TC-12 | Comment on a dataset. | |
| 12 | CR-15 | TC-04 | –check– | TC-13 | Add a publication entry. |
| 13 | OR-01 | TC-13 | –check– | TC-14 | View user profile. |
| TC-15 | Search for reports with NotPetya. | ||||
| 14 | OR-02 | TC-12 | TA-03, –check– | ||
| 15 | OR-03, OR-04 | TC-08 –check– | TC-16 | Flag a report. | |
| 16 | |||||
| OR-05 | |||||
| TC-16 | |||||
| TA-05, –check– | |||||
| 17 | |||||
| OR-06 | |||||
| TC-03 | |||||
| –check– | |||||
| 18 | OR-07 | TC-15 | –check– | ||
| 19 | OR-08 | TC-11 | –check– | ||
| 20 | OR-09, OR-10 | TC-12 | –check– |
References
- Django Auth. Available online: https://docs.djangoproject.com/en/2.2/topics/auth/passwords/ (accessed on 4 October 2022).
- M’Raihi, D.; Machani, S.; Pei, M.; Rydell, J. TOTP: Time-Based One-Time Password Algorithm. Available online: https://www.rfc-editor.org/rfc/rfc6238.html (accessed on 4 October 2022).
- RestrictedPython. Available online: https://pypi.org/project/RestrictedPython/ (accessed on 25 February 2023).
- NIST. Computer Forensics Tool Testing Program. 2014. Available online: http://www.cftt.nist.gov/ (accessed on 12 October 2017).
More