The quality of drinking water is a critical factor for public health and the environment. Inland drinking water reservoirs are essential sources of freshwater supply for many communities around the world. However, these reservoirs are susceptible to various forms of contamination, including the presence of muddy water, which can pose significant challenges for water treatment facilities and lead to serious health risks for consumers. In addition, such reservoirs are also used for recreational purposes which supports the local economy.
- muddy waters
- machine learning
- water quality monitoring
1. Introduction
2. Impact
3. Detection with Remote Sensing
4. Atmospheric Corrections
A potential issue that is observed in the literature is the choice of atmospheric corrections. Atmospheric correction refers to the process of removing or compensating for the effects of the Earth’s atmosphere on optical satellite or airborne data. When electromagnetic radiation passes through the atmosphere before reaching the Earth’s surface, it interacts with various atmospheric components. These interactions can introduce errors and distortions in the data such as scattering and absorption, among others, making it challenging to accurately interpret and analyze the remote sensing imagery, thus making atmospheric correction a very important preprocessing step. Atmospheric correction algorithms can be divided into two categories, namely absolute and relative ones [23]. Absolute algorithms use several atmospheric and illumination parameters, as well as sensor viewing geometries to calculate the actual surface reflectance. On the other hand, relative algorithms make assumptions about the reflectance of specific objects (e.g., water bodies, desserts) or relationships between ground truths, resulting in a relative pixel value. There are several works dedicated to building benchmark datasets for classification or semantic segmentation where the respective authors do not always explicitly argue on the reasons behind choosing certain atmospheric correction algorithms [24] or not choosing any atmospheric correction algorithm at all [25]. However, there are other such datasets where the respective authors explain the absence of any atmospheric correction algorithm as an extra step in increasing the generalizability and skill of a deep learning model [26]. The above examples refer to land cover classification applications, although there are works such as [16] referring to water applications where the authors again do not provide any argumentation regarding the use of specific atmospheric correction algorithms. However, there are works such as [27] that are dedicated in the comparison among different atmospheric correction algorithms in the classification task, as well as others such as [28] that explicitly compare between absolute and relative atmospheric correction algorithms. In the context of water quality parameter retrieval, the importance of choosing an accurate atmospheric correction algorithm has been well-established [29][30][29,30]. However, for the classification or semantic segmentation task, the impact of various atmospheric corrections algorithms is not entirely clear. According to the computer vision and image analysis theory, irrespective of the field of application, the image property of contrast between objects plays a crucial role in the distinction capability, which is evident by research that develops/assesses image enhancement methods focusing specifically on contrast [31][32][33][34][31,32,33,34]. As a result, the latter implies that for the semantic segmentation/classification/object detection tasks, the need for an atmospheric correction algorithm specialized in water is not needed. What would be most important is the contrast (or relative brightness) among different objects/classes for each spectral band, instead of the absolute pixel values or surface reflectance. Three ACs (polymer (https://www.hygeos.com/polymer, accessed on 24 August 2023), ACOLITE (https://odnature.naturalsciences.be/remsem/software-and-data/acolite, accessed on 24 August 2023) and C2RCC (https://c2rcc.org/, accessed on 24 August 2023)) were performed on L1C products, while the fourth AC (sen2cor (https://step.esa.int/main/snap-supported-plugins/sen2cor/, accessed on 24 August 2023)) was already applied on the L2A product. The spectral response of muddy waters and clean waters were investigated qualitatively. It is noticeable that in the case of sen2cor, polymer and ACOLITE ACs the relative difference of the spectral response between muddy and clean waters is similar, while this is not the case for C2RCC. In addition, not all ACs give all spectral bands as a corrected output which thwe researchers cconsider as a drawback especially in the case that we would like to include different land and cloud classes in theour ML approach. Since this is a deep research problem on its own and based on the prior exploration the researchers shwe showed above, the researchers sewe selected the simplest AC algorithm—sen2cor—as applied in the L2A products.5. Annotation in Semantic Segmentation
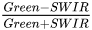
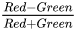
6. Model Development
For theour model development, the researchers sewe selected a Random Forest (RF) which is considered a powerful ML model and has been used in remote sensing extensively. It is recommended especially in tabular data formats, such as in the researchers'our case, not images or time series (despite that, there is also research on these types of data). Therefore, starting the model development workflow, the researcherswe selected 166,738 pixels in total which belong to all aforementioned AOIs, after undersampling the negative (non-muddy water) class in order to achieve a class balance between muddy and non-muddy water classes which is crucial for the ML model development. In turn, those were randomly split into training and test sets with 133,390 and 33,348 pixels, respectively. In the training samples the researchers we included several classes relevant to land such as bare soil, green vegetation, brown vegetation, different crops, bare rocks, as well as clean water and clouds. After selecting the training and test sets, the researchers we perform an optimization based on Grid Search to derive the best possible hyperparameters for theour RF model. The hyperparameters the researchers we try to find optimal values for are (a) number of trees (b) tree depth and (c) class balance. To find the optimal numbers, the researchers we performed a five-fold cross validation with 5 repeats based on the F1-score classification metric, which resulted in 7425 total model fits.7. Results
Concerning the model evaluation after optimizing it, in order to further assess the results, thwe researchers first examined the feature importances that are derived from the RF model which are inherently produced, and secondly the researchers awe applied the optimized model to other AOIs. This way the researchers are awe are able to assess the true performance of the model in the so-called unseen cases, which are data that have not been used in the training procedure. The unseen data include the test set also for which the researchers we derived several accuracy metrics along with the training set, such as Accuracy, Recall, Precision, F1-score and Receiver Operating Characteristic-Area Under Curve (ROC-AUC). All metrics achieved a performance of over 98%. After applying theour RF model to cases with similar muddy water characteristics such as in Prokopos (Greece), the researchers we notice an adequate performance. However, this does not seem to be the case when the researchers awe apply the model in regions with shallow waters and high chlorophyll content, where an overestimation can be observed. Therefore, the researchers cwe conclude there might be cases that the model would overestimate and probably underestimate in muddy water types that exist and have not been included in the training dataset from other AOIs and events. Regarding the feature importances, the researchers we notice the biggest contributions from 𝐵11, 𝐵12, 𝐵4, 𝐵8, and 𝐵5 bands. Especially, the contribution from 𝐵11 and 𝐵12 can be attributed to the presence of several land classes and clouds in the training dataset.
8. Prospect and Usability
The proposed approach of muddy water mapping which is based on semantic segmentation does not aim to substitute the the typical water quality parameter retrieval approaches. In an operational setting and depending on the purpose of use, it can have the advantages of low latency of product generation (e.g., no need for specialized time-consuming atmospheric correction), it can be sensor-independent and a model could be easily updated by exploiting transfer learning (assuming deep learning-based model usage). In the case of the RF approach and the non-variable enough dataset, the model can be retrained on a new AOI in order to deliver valid products to an end-user. Thus, such a product/service can be integrated in water management and decision support systems, as is the case for the proposed approach of the current work as a pilot (https://portal-wqems.opsi.lecce.it, accessed on 24 August 2023). An end-user may only need the information of whether such an extreme event occurs or not, the geometrical features and extent, and an indirect visual estimation of sediment content (derived by the prediction probabilities) which are essential for the emergency response. From a research perspective, unknown regions and water bodies of muddy water presence can be identified around the world (assuming a highly variable training dataset).
9. Suggestions
The potential that came with open and free Copernicus data is undeniable. Copernicus satellite missions such as Sentinel-2 and Sentinel-3 can provide both high spatial and temporal resolutions, although not at the same time, since Sentinel-3 comes with almost daily measurements but low spatial resolutions (∼300 m) (https://sentinels.copernicus.eu/web/sentinel/user-guides/sentinel-3-olci/resolutions/spatial, accessed on 24 August 2023) while Sentinel-2 comes with high spatial but lower temporal resolution. In addition, recent years have shown an emerging interest in the adaptation of deep learning (and especially CNN-based) approaches for the downscaling task by sensor fusion (e.g., [38][40]). Therefore, thwe researchers ssuggest that the monitoring of muddy waters in the context of this work could be improved by the wider adaptation and fusion of Sentinel-2 and Sentinel-3 missions, and the development of deep learning downscaling approaches to generate water quality products of high both temporal and spatial resolution.
10. Conclusions
In conclusion, thisour researchwork focuses on the mapping/detection of muddy waters through a machine learning-based semantic segmentation approach for inland drinking water reservoirs with a spatial resolution of 10 m using Sentinel-2 satellite data. The task at hand is fairly new and requires further research, especially in the part of generating annotations and a more variable training dataset. The model the researchers we developed is a Random Forest model used on data in a tabular format; based on the training dataset the researchers we used, it performs fairly well. This means that there is room for improvement from the proper dataset generation side which would offer maximal generalization capabilities. With increasing complexity there is demand for more complex models, thus, the researcherswe foresee a future utilization of image-based deep learning approaches such as CNNs.