Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Muhammad Usman and Version 2 by Camila Xu.
Automatic modulation classification (AMC) is a vital process in wireless communication systems that is fundamentally a classification problem. It is employed to automatically determine the type of modulation of a received signal. Deep learning (DL) methods have gained popularity in addressing the problem of modulation classification, as they automatically learn the features without needing technical expertise.
- automatic modulation classification
- deep neural network
- residual learning
1. Introduction
In wireless communication, the complexity of the environment and the signals is rapidly increasing. A vital phenomenon in ad-hoc networks such as cognitive radio (CR) and software-defined radio (SDR) is automatic modulation classification (AMC) [1]. In modulation, information is typically communicated between the transmitter and receiver in a standard communication environment [2], whereas devices in CR transmitters autonomously choose modulation schemes based on external contexts, and CR receivers should independently verify signal modulation patterns [3]. AMC assists the CR receivers in identifying the type of modulation selected by the transmitter. In SDR, AMC is applied to quickly respond to diverse and evolving communication networks whilst avoiding protocols overhead. The current technology in a cognitive jamming scenario involves the automatic discovery of the modulation schemes utilized by both favorable and adversarial signals [1].
While military technology has always been a driving force behind the advancement of AMC, commercial applications such as interference detection and spectrum sensing are also widespread [4]. The development of the 5th generation of telecommunication networks (5G), which is predicted to result in the proliferation of end devices in use and congestion of the electromagnetic spectrum, has sparked renewed interest in AMC. Without knowing the system parameters, AMC is used to determine the transmitter’s modulation configuration from the received signal as shown in Figure 1.
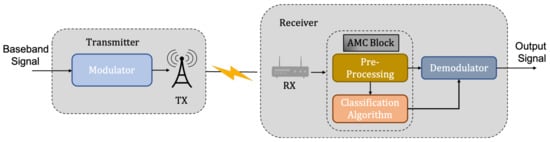
Figure 1.
Block diagram of a communication link with automatic modulation classification.
Signal, noise, and channel models have a significant effect on the classification result. Therefore, they are all used to develop AMC techniques. When the expected signal model or noise model does not fit the actual signal or noise, the corresponding classification model fails to perform adequately. A more sophisticated model may be expected to mostly reduce the gap with the real scenario. There are many unspecified parameters to evaluate, which leads to greater estimation mistakes, and the additional computing complexity cannot be overlooked. Furthermore, certain situations, such as molecular communications may not have manageable predictive methods, severely decreasing the classification accuracy of the typical design classifier [5]. Due to computing complexity, they have been restricted in their relevancy to a wider range of fields. Data-driven AMC methods have been designed to address these complexities [6].
2. A Lightweight Deep Learning Model for Automatic Modulation Classification Using Residual Learning and Squeeze–Excitation Blocks
2.1. Likelihood-Based (LB) Method
AMC is treated as a hypothesis-testing problem in the LB method. The algorithm based on the LB method can be efficient from a Bayesian perspective, and it is beneficial for reducing the likelihood of a hypothesis problem occurring. High computational complexity often affects accurate decisions, which can be difficult to obtain in actual systems. The LB method can reduce the probability of misclassification and can obtain the best classification accuracy, as such methods maximize the chance of correct classification with perfect channel situations. Furthermore, in real-world scenarios, uncertainty factors must be considered, and the likelihood function is ineffective in handling any unknown parameters. The unknown parameters problem is replaced with the essential component of their probability density function (PDF) in the average-likelihood ratio test (ALRT) [7][8]. However, as the number of missing factors grow, the likelihood function in ALRT becomes more sophisticated, resulting in a significant processing cost. To solve the complexity, the generalized likelihood ratio test (GLRT) was developed. The parameters in GLRT are estimated by using a maximum likelihood (ML) estimator [8][9]. This biased classifier affects the performance of nested modulations such as 16-quadrature amplitude modulation (QAM) and 64-QAM. The hybrid likelihood ratio test (HLRT) improves the performance of the likelihood function with respect to the unknown function. It first evaluates the likelihood of the data symbols as discrete random variables, consistently allocated across the alphabet set, and considers the carrier phase as a predetermined variable [9][10]. Since this method requires prior information about the signal, including its carrier frequency and other channel parameters, its implementation becomes difficult in the presence of complex and unknown parameters. Despite their ability to provide optimal solutions, they may not be appropriate in practical scenarios [10][11].2.2. Feature-Based (FB) Method
FB methods, which are widely used for AMC, extract features from the received signal and feed them into a classification system [11][12]. They are found to outperform LB techniques in terms of reliability and computational overhead. To detect the modulation type of a signal, FB methods have been employed on a set of data description features, which assist in formulating decisions [6]. There are two steps to the creation of FB modulation classification method: preprocessing and a classification algorithm.-
Preprocessing: This stage is responsible for extracting features from the received signal. Different features can be chosen based on various circumstances and predictions. Certain immediate aspects of the signal, such as instantaneous signal power, frequency, phase, amplitude, and so on, are retrieved during the feature extraction phase [12][13]. As a result, these characteristics transform the raw data into patterns that must be learned by the classifier for the purpose of recognition.
-
Classification Algorithm: The classification algorithm utilizes the features from the preprocessor as an input, and outputs the modulation type of the signal for each received signal.