Fine-grained image recognition aims to classify fine subcategories belonging to the same parent category, such as vehicle model or bird species classification. This is an inherently challenging task because a classifier must capture subtle interclass differences under large intraclass variances. Most previous approaches are based on supervised learning, which requires a large-scale labeled dataset. However, such large-scale annotated datasets for fine-grained image recognition are difficult to collect because they generally require domain expertise during the labeling process. ReIn this searcherstudy, we propose a self-supervised transfer learning method based on Vision Transformer (ViT) to learn finer representations without human annotations. Interestingly, it is observed that existing self-supervised learning methods using ViT (e.g., DINO) show poor patch-level semantic consistency, which may be detrimental to learning finer representations. Motivated by this observation, researcherswe propose a consistency loss function that encourages patch embeddings of the overlapping area between two augmented views to be similar to each other during self-supervised learning on fine-grained datasets. In addition, we explore effective transfer learning strategies to fully leverage existing self-supervised models trained on large-scale labeled datasets. Contrary to the previous literature, our findings indicate that training only the last block of ViT is effective for self-supervised transfer learning. We demonstrate the effectiveness of our proposed approach through extensive experiments using six fine-grained image classification benchmark datasets, including FGVC Aircraft, CUB-200-2011, Food-101, Oxford 102 Flowers, Stanford Cars, and Stanford Dogs.
1. Introduction
Self-supervised learning (SSL) has recently made significant progress in various fields, including computer vision
[1][2][1,2], natural language processing
[3], and graph representation learning
[4]. SSL aims to learn generic feature representations by encouraging a model to solve auxiliary tasks that arise from the inherent properties of the data themselves. The predominant SSL approaches in computer vision seek to maximize the agreement between different views of an image
[1][2][5][6][1,2,5,6]. Thanks to its strong ability to learn visual representations in the absence of human annotations, SSL has emerged as a promising strategy to reduce the reliance on large-scale labeled datasets. Remarkably, SSL-learned visual representations perform better than supervised learning
[1] when transferred to several downstream vision tasks.
SSL can be especially useful for tasks requiring heavy annotation costs, such as fine-grained image recognition
[7], because it aims to learn discriminative representations without using human annotation. However, there are several limitations to the application of current SSL methods for fine-grained image recognition tasks
[8][9][10][8,9,10]. In contrast with ordinary computer vision tasks, fine-grained images share many visual characteristics across their classes. Therefore, a model should learn finer representations that capture subtle differences among classes. A model trained to classify bird species, for instance, should be able to learn local patterns, such as beak length, wing shape, and tail color. However, it is known that existing SSL methods tend to focus on background pixels and low-level features (e.g., texture and color)
[11], which might be detrimental to learning finer representations for foreground objects. In addition, SSL with fine-grained datasets may not be as effective as anticipated because the fine-grained image dataset is relatively small in scale, and SSL is known to benefit from large-scale datasets.
Researchers focus on SSL for fine-grained image recognition tasks based on the Vision Transformer (ViT)
[12] architecture, which has recently shown remarkable performance in image recognition tasks. In the ViT architecture, an image is divided into multiple patches, and these patches are converted into a sequence of linear embeddings. Additionally, a learnable embedding vector, named [CLS] token, is prepended to the embedded patches to form an input sequence. The final output feature that corresponds to the [CLS] token serves as the image representation, which is then passed to the classification head for prediction. ViT learns visual representations using self-attention between image patches rather than convolution operations, enabling the efficient encoding of patch-level representations. Nevertheless, most existing SSL methods force image-level representations to be invariant to different image augmentations and discard the final patch-level representations. However, such information may not be adequately encoded in image-level representation without explicit regularization because class-discriminative patterns for fine-grained images are likely to appear in the local area.
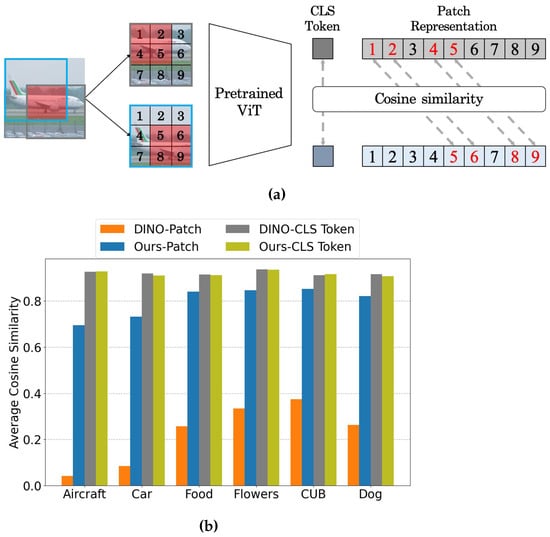
ReTo cons
earchersolidate our motivation, we empirically examined the consistency of the patch representation (i.e., the final output feature of each patch) from ViT pretrained by DINO
[1] on ImageNet, as shown in
Figure 1a. To this end, the two differently cropped views from an image were fed into the model, and the cosine similarity between the patch representations corresponding to the same patches in each view was measured. If local semantic information is well-encoded in the patch representation, the last features of the same patches will be consistent even with different adjacent patches and thus will show high similarity. However, DINO, a state-of-the-art SSL method with ViT, does not satisfy this consistency, as shown in
Figure 1b. On various public fine-grained visual classification (FGVC) datasets, DINO shows strong consistency between image-level representations (i.e., the final feature of the [CLS] token) but shows poor patch-level consistency.
ResWe
archers argue that a model can better attend to such local information to produce image-level representations if the semantic information of each patch is properly encoded in its patch-level representations and eventually can learn finer representations that are beneficial to fine-grained image recognition.
Figure 1. (a) Procedure of evaluating patch-level consistency. (b) Average cosine similarity of image and patch-level representations on various FGVC datasets. DINO shows low cosine similarity between patch representations corresponding to the overlapping area, which indicates poor patch-level consistency.
2. Self-Supervised Learning
Self-supervised learning (SSL) aims to learn useful representations from data, without human annotation. Contrastive learning
[2][5][13][14][2,5,17,18] has gained significant attention for SSL owing to its superior performance. Contrastive learning aims to maximize the agreement between different views from an image (i.e., a positive pair) while repelling those from other images (i.e., negative pairs) in the feature space. However, these approaches usually incur substantial memory costs because they require numerous negative samples during training, such as a large batch size
[2] or a large memory bank
[5]. Several alternatives have been proposed for effectively learning visual representations without using negative samples to address this problem. Grill et al.
[15][19] proposed training an online network by predicting the output of a momentum encoder with a stop-gradient operator. Zbontar et al.
[6] proposed optimizing the empirical cross-correlation matrix, which was obtained from a batch of feature embeddings, to be similar to the identity matrix.
Recently, several attempts have been made to apply SSL to ViT
[1][16][17][1,20,21]. For example, Caron et al.
[1] proposed an SSL framework based on the ViT architecture named self-distillation with no labels (DINO). DINO adopts knowledge distillation within an SSL framework. Specifically, the momentum encoder is treated as a teacher network and the student network is trained to match the output distribution of the teacher network, by minimizing the cross-entropy. However, the patch-level representation may not contain meaningful information, as shown in
Figure 1b, because DINO uses only the last feature of the [CLS] token for training.
3. Fine-Grained Visual Classification
Fine-grained visual classification (FGVC) is a computer vision task focused on distinguishing between objects that are visually similar and belong to closely related classes. In FGVC, a model should be able to capture subtle interclass differences under large intraclass variance, which presents intrinsic challenges. Most of the existing FGVC approaches fall into two categories: object-part-based methods and attention-based methods
[18][22].
Earlier works in object-part-based methods use detection or segmentation techniques to locate important regions, and then the localized information is used as a discriminative partial-level representation
[19][20][21][23,24,25]. While these methods have demonstrated their effectiveness, they require bounding-box and segmentation annotations, resulting in a significant effort to obtain supervised annotations.
In contrast, attention-based methods
[22][23][24][26,27,28] use attention mechanisms to improve feature learning and identify object details, thus eliminating the need for dense annotations. RA-CNN
[22][26] iteratively generates region attention maps in a coarse-to-fine manner, using previous predictions as a reference. PCA-Net
[23][27] uses image pairs of the same category to compute attention between feature maps to capture the common discriminative features. With the great success of ViT in computer vision, there have been several attempts to extend the use of ViT in FGVC, such as TransFG
[25][29], SIM-Trans
[26][30], and AFTrans
[27][31]. Similarly, these approaches utilize self-attention maps to enhance feature learning and capture object details. While these studies have achieved considerable success, the challenge posed by high annotation costs remains.
4. Transfer Learning
Transfer learning is a popular approach that aims to transfer pretrained knowledge to various domains and tasks
[28][32]. A widely used strategy is to fine-tune a large-scale pretrained model (e.g., ImageNet) to a downstream task or dataset. The effect of transfer learning can be interpreted as an expert in a specific field quickly adapting to similar fields. Accordingly, it can be expected to achieve high performance even with a small amount of training data
[29][30][33,34]. Thus,
rwe
searchers considered transferring the ImageNet pretrained model via SSL to FGVC tasks by setting the pretrained weight as the initial parameter.
Although numerous methods for effective transfer learning have been proposed, most of them consider supervised learning for downstream tasks
[31][32][35,36]. Contrary to previous approaches,
rwe
searchers study SSL for downstream tasks because
theour goal is to learn finer representations without label information. Similarly, hierarchical pretraining (HPT)
[33][13] transfers SSL-pretrained models by conducting SSL once again on the downstream dataset. While HPT is similar to
theour proposed method in assuming SSL for downstream tasks, they focus on CNN-based architectures and have shown that only updating normalization layers, such as batch normalization
[34][37] during transfer learning is effective.