Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 3 by Jessie Wu and Version 2 by Jessie Wu.
Skull stripping removes non-brain tissues from magnetic resonance (MR) images, but it is hard because of brain variability, noise, artifacts, and pathologies. The existing methods are slower and limited to a single orientation, mostly axial. Researchers' proposed and experimented method uses the modern and robust architecture of deep learning neural networks, viz., Mask–region convolutional neural network (RCNN) to learn, detect, segment, and to apply the mask on brain features and patterns from many thousands of brain MR images.
- deep learning
- fully automated skull stripping
- brain magnetic resonance images
- MRI
1. Traditional Techniques
Traditional techniques of skull stripping, include Brain Extraction Tools, Brain Sur-face Extraction, and Robust Brain Extraction (ROBEX) [1][2]. Brain ET xtraction Tools (BET) is a widely used method for skull stripping based on intensity thresholding and morphological operations [3]. BSE is a semi-automated method that uses a deformable surface model to segment the brain from non-brain tissue [4]. The Robust Brain Extraction (ROBEX) algorithm uses intensity thresholding, mathematical morphology, and a multi-scale watershed transform to extract the brain tissue from non-brain tissue [1]. Otsu’s method is a non-parametric approach for image segmentation and is an attractive alternative to the Bayes decision rule [5].
2. Artificial Intelligence-Based Techniques
The first quarter of the 21st century has been the era of artificial intelligence (AI), and more is expected in the forthcoming decades. Contemporary techniques are more effective and efficient for skull stripping, especially in large lesions or with significant anatomical abnormalities [6][7]. Such methods can robustly deal with variations in image contrast and noise, but may require enormous amounts of training data and therefore greater computational cost [8]. Machine learning (ML)-based AI models of skull stripping have evolved through Deep Learning Neural Networks (DLNN) such as Convolutional Neural Networks (CNN). AI experts have utilized the cutting-edge technology of DLNN to train models for medical image processing using chest X-ray images for the detection of COVID-19 [8]. CNN has revolutionized the field of image processing based on the principle of feature extraction. The CNN-based models progress through Region-based Neural Networks (RCNN) followed by Faster RCNN to today’s state-of-the-art neural networks, viz., Mask–RCNN [9][10].
3. Machine Learning
Machine learning has contributed significantly to the processing of brain magnetic resonance (MR) images by segmenting and contouring different brain structures and regions of interest [11]. There are at least four types of ML-based brain MR image processing techniques, viz., supervised, unsupervised, semi-supervised, and deep learning. Supervised ML algorithms establish learning from annotated images, where MRI experts manually delineate the brain regions [12]. Support Vector Machines (SVMs) and Convolutional Neural Networks (CNNs) are popular ML-based supervised techniques. Unsupervised ML algorithms discover hidden patterns within brain MR images by identifying similarities and differences in intensity, texture, or shape, and grouping similar voxels or regions [13]. K-means and Gaussian Mixture Models (GMMs) are popular ML-based unsupervised techniques. Semi-supervised ML algorithms use a small amount of annotated data to guide the segmentation process while taking unlabeled data to learn more generalizable features. Deep learning models such as CNNs can automatically learn hierarchical features from raw image data [14][15]. Popular deep learning architectures include U-Net, Fully Convolutional Networks (FCNs), and U-Net.
4. Deep Learning
Deep learning has revolutionized the processing, segmentation, and identification of regions in brain MR images [11]. ResNet and U-Net are the most popular models of deep learning. ResNet is known for its residual connections and achieves high accuracy in tasks such as brain tumor segmentation [16]. U-Net precise localization has been extensively applied to segment brain MR images [17]. Many researchers have combined ResNet and U-Net to leverage their respective strengths for enhanced accuracy and precision [18]. In contrast, the challenges related to such architectures include class imbalance and limited training data [19]. Their application has advanced brain MR image analysis including anatomical structure identification [20].
5. Convolutional Neural Networks and Region-Based Neural Networks
Convolutional Neural Network (CNN) consists of convolutional layers that apply filters to input images and generate feature maps [21]. Non-linear activation functions and pooling layers follow the CNN for down sampling. RCNN combines CNN with recurrent layers such as LSTM or GRU to capture temporal dependencies in sequential data [22]. RCNN effectively models both spatial and temporal information, making them valuable for tasks involving sequential or spatiotemporal understanding.
6. Mask–Region-Based Neural Network
Region-based Neural Network (RCNN) uses selective searching to identify regions of interest (ROIs) and applies a convolutional neural network to classify ROIs as foreground or background [23]. Faster RCNN, an extended version of RCNN, uses a Region Proposal Network (RPN) to generate ROIs by adding more CNNs [24][25].
Nonetheless, Mask–RCNN is the most modern type of DLNN, an extended version of Faster RCNN by adding a mask branch, which generates binary masks for each ROI. Mask–RCNN masks the detected object [22][26][27]. Mask–RCNN applies Residual Neural Network (ResNet) [28] architecture for feature extraction from the input image, which comprises cerebral cortex pyramidal cells and uses jumps over applied layers [29]. ResNet works as the backbone architecture of the Mask–RCNN [30]. It also applies Region Proposal Network (RPN) to predict the presence or absence of the targeted object [22][31]. It forwards feature maps having target objects. Pooling layers make uniform shapes of received featured maps to connect layers for further processing [32][33]. Eventually, the fully connected convolutional layers receive feature maps to predict class labels and coordinates of bounding boxes [26][29]. Mask–RCNN computes Regions of Interest (RoIs) with a benchmark value = 0.5 [34] for declaring the regions as RoIs, followed by the addition of the mask branch to apply a mask on established RoI [35].
The application of Mask–RCNN contours object detection, segmentation, image captioning, and instance segmentation [22][36]. It has achieved state-of-the-art performance in various benchmark datasets [37]. In object detection, Mask–RCNN has shown excellent performance in detecting multiple objects with high accuracy. Instance segmentation uses individual instances of objects in an image and provides a more detailed understanding of the scene. In image captioning, Mask–RCNN generates captions to describe target objects and their locations.
Mask–RCNN offers more precise and accurate results [38]; however, in some cases, it takes around 48 h to train the system. Numerous public databases such as Common Objects in Context (COCO) are available with training weights to train systems using the transfer learning approach [39][40]. Overall, Mask–RCNN is an effective tool for image analyses and has the potential for further advancements in computer vision. Figure 1 depicts the structure of Mask–RCNN.
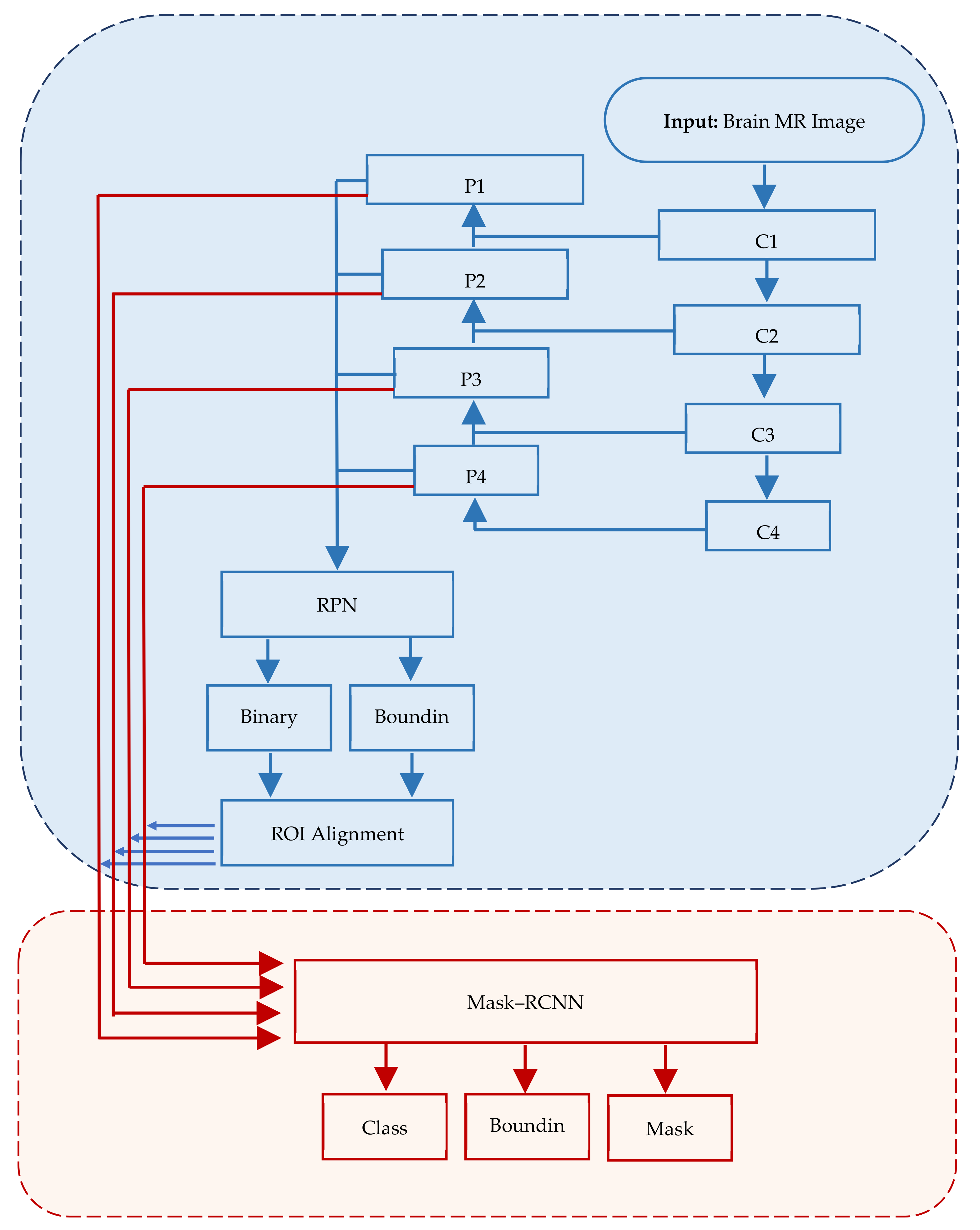
Figure 1. Mask–RCNN architecture comprising three major segments, viz., input, regions of interest and application of mask.
In Mask–RCNN architecture, the input image passes through convolutional layers (C1, C2, …, Cn) while extracting feature maps (P1, P2, …, Pn) at each layer. RPN is applied on each ex-traced feature map.
References
- Roy, S.; Maji, P. A simple skull stripping algorithm for brain MRI. In Proceedings of the 2015 Eighth International Conference on Advances in Pattern Recognition (ICAPR), Kolkata, India, 4–7 January 2015.
- Fatima, A.; Shahid, A.R.; Raza, B.; Madni, T.M.; Janjua, U.I. State-of-the-art traditional to the machine-and deep-learning-based skull stripping techniques, models, and algorithms. J. Digit. Imaging 2020, 33, 1443–1464.
- Smith, S.M. Fast robust automated brain extraction. Hum. Brain Mapp. 2002, 17, 143–155.
- Tohka, J.; Kivimaki, A.; Reilhac, A.; Mykkanen, J.; Ruotsalainen, U. Assessment of brain surface extraction from PET images using Monte Carlo Simulations. IEEE Trans. Nucl. Sci. 2004, 51, 2641–2648.
- Tariq, H.; Muqeet, A.; Burney, A.; Hamid, M.A.; Azam, H. Otsu’s segmentation: Review, visualization, and analysis in context of axial brain MR slices. J. Theor. Appl. Inf. Technol. 2017, 95, 22.
- Albattah, W.; Nawaz, M.; Javed, A.; Masood, M.; Albahli, S. A novel deep learning method for detection and classification of plant diseases. Complex Intell. Syst. 2022, 8, 507–524.
- Abdou, M.A. Literature review: Efficient deep neural networks techniques for medical image analysis. Neural Comput. Appl. 2022, 34, 5791–5812.
- Akbar, S.; Tariq, H.; Fahad, M.; Ahmed, G.; Syed, H.J. Contemporary Study on Deep Neural Networks to Diagnose COVID-19 Using Digital Posteroanterior X-ray Images. Electronics 2022, 11, 3113.
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.J.; Kim, N. Deep learning in medical imaging. Neurospine 2019, 14, 657.
- Nadeem, M.W.; Goh, H.G.; Hussain, M.; Liew, S.Y.; Andonovic, I.; Khan, M.A. Deep learning for diabetic retinopathy analysis: A review, research challenges, and future directions. Sensors 2022, 2, 6780.
- Bento, M.; Fantini, I.; Park, J.; Rittner, L.; Frayne, R. Deep learning in large and multi-site structural brain MR imaging datasets. Front. Neuroinform. 2022, 15, 805669.
- Shang, M.; Li, H.; Ahmad, A.; Ahmad, W.; Ostrowski, K.A.; Aslam, F.; Joyklad, P.; Majka, T.M. Predicting the mechanical properties of RCA-based concrete using supervised machine learning algorithms. Materials 2022, 15, 647.
- Jabbarpour, A.; Mahdavi, S.R.; Sadr, A.V.; Esmaili, G.; Shiri, I.; Zaidi, H. Unsupervised pseudo CT generation using heterogenous multicentric CT/MR images and CycleGAN: Dosimetric assessment for 3D conformal radiotherapy. Comput. Biol. Med. 2022, 143, 105277.
- Gaur, L.; Bhandari, M.; Razdan, T.; Mallik, S.; Zhao, Z. Explanation-driven deep learning model for prediction of brain tumour status using mri image data. Front. Genet. 2022, 13, 822666.
- Senan, E.M.; Jadhav, M.E.; Rassem, T.H.; Aljaloud, A.S.; Mohammed, B.A.; Al-Mekhlafi, Z.G. Early diagnosis of brain tumour mri images using hybrid techniques between deep and machine learning. Comput. Math. Methods Med. 2022, 2022, 8330833.
- Behera, T.K.; Khan, M.A.; Bakshi, S. Brain MR image classification using superpixel-based deep transfer learning. IEEE J. Biomed. Health Inform. 2022.
- Rajaragavi, R.; Rajan, S.P. Optimized U-Net Segmentation and Hybrid Res-Net for Brain Tumor MRI Images Classification. Intell. Autom. Soft Comput. 2022, 32, 1–14.
- Chen, T.; Son, Y.; Park, A.; Baek, S.-J. Baseline correction using a deep-learning model combining ResNet and UNet. Analyst 2022, 147, 4285–4292.
- Lin, L.; Zhang, J.; Gao, X.; Shi, J.; Chen, C.; Huang, N. Power fingerprint identification based on the improved VI trajectory with color encoding and transferred CBAM-ResNet. PLoS ONE 2023, 18, e0281482.
- Li, M.; Punithakumar, K.; Major, P.W.; Le, L.H.; Nguyen, K.-C.T.; Pacheco-Pereira, C.; Kaipatur, N.R.; Nebbe, B.; Jaremko, J.L.; Almeida, F.T. Temporomandibular joint segmentation in MRI images using deep learning. J. Dent. 2022, 127, 104345.
- Ketkar, N.; Moolayil, J.; Ketkar, N.; Moolayil, J. Convolutional neural networks. In Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorch; Apress: New York, NY, USA, 2021; pp. 197–242.
- Xu, X.; Zhao, M.; Shi, P.; Ren, R.; He, X.; Wei, X.; Yang, H. Crack detection and comparison study based on faster R-CNN and mask R-CNN. Sensors 2022, 22, 1215.
- Chiu, M.-C.; Tsai, H.-Y.; Chiu, J.-E. A novel directional object detection method for piled objects using a hybrid region-based convolutional neural network. Adv. Eng. Inform. 2022, 51, 101448.
- Guo, Z.; Tian, Y.; Mao, W. A Robust Faster R-CNN Model with Feature Enhancement for Rust Detection of Transmission Line Fitting. Sensors 2022, 22, 7961.
- Khasawneh, N.; Fraiwan, M.; Fraiwan, L. Detection of K-complexes in EEG waveform images using faster R-CNN and deep transfer learning. BMC Med. Inform. Decis. Mak. 2022, 22, 297.
- Vuola, A.O.; Akram, S.U.; Kannala, J. Mask-RCNN and U-net ensembled for nuclei segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019.
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017.
- Kasinathan, T.; Uyyala, S.R. Detection of fall armyworm (Spodoptera frugiperda) in field crops based on mask R-CNN. Signal Image Video Process. 2023, 17, 2689–2695.
- Baltruschat, I.M.; Nickisch, H.; Grass, M.; Knopp, T.; Saalbach, A. Comparison of deep learning approaches for multi-label chest X-ray classification. Sci. Rep. 2019, 9, 6381.
- Patekar, R.; Kumar, P.S.; Gan, H.-S.; Ramlee, M.H. Automated Knee Bone Segmentation and Visualisation Using Mask RCNN and Marching Cube: Data from The Osteoarthritis Initiative. ASM Sci. J. 2022, 17, 1–7.
- Wang, H.; Li, M.; Wan, Z. Rail surface defect detection based on improved Mask R-CNN. Comput. Electr. Eng. 2022, 102, 108269.
- Guo, L. SAR image classification based on multi-feature fusion decision convolutional neural network. IET Image Process. 2021, 16, 1–10.
- Nirthika, R.; Manivannan, S.; Ramanan, A.; Wang, R. Pooling in convolutional neural networks for medical image analysis: A survey and an empirical study. Neural Comput. Appl. 2022, 34, 5321–5347.
- Gao, Y.; Qi, Z.; Zhao, D. Edge-enhanced instance segmentation by grid regions of interest. Vis. Comput. 2022, 39, 1137–1148.
- Johnson, J.W. Automatic nucleus segmentation with Mask-RCNN. In Proceedings of the Science and Information Conference, Las Vegas, NV, USA, 25–26 April 2019.
- Gupta, P.; Sharma, V.; Varma, S. A novel algorithm for mask detection and recognizing actions of human. Expert Syst. Appl. 2022, 198, 116823.
- Thomas, C.; Byra, M.; Marti, R.; Yap, M.H.; Zwiggelaar, R. BUS-Set: A benchmark for quantitative evaluation of breast ultrasound segmentation networks with public datasets. Med. Phys. 2023, 50, 3223.
- Storey, G.; Meng, Q.; Li, B. Leaf disease segmentation and detection in apple orchards for precise smart spraying in sustainable agriculture. Sustainability 2022, 14, 1458.
- Chowdhury, A.M.; Moon, S. Generating integrated bill of materials using mask R-CNN artificial intelligence model. Autom. Constr. 2023, 145, 104644.
- Kadam, K.D.; Ahirrao, S.; Kotecha, K. Efficient approach towards detection and identification of copy move and image splicing forgeries using mask R-CNN with MobileNet V1. Comput. Intell. Neurosci. 2022, 2022, 6845326.
More