Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Alfred Zheng and Version 3 by Alfred Zheng.
Visual question answering (VQA) is a task that generates or predicts an answer to a question in human language about visual images. VQA is an active field combining two AI branches: Natural language processing (NLP) and computer vision. VQA usually has four components: vision featurization, text featurization, fusion model, and classifier. Vision featurization is a part of the multi-model responsible for extracting the vision features. Text featurization is another part of the VQA multi-model responsible for extracting text features. The combination of both features and their processes is the fusion component. The last component is the classifier that classifies the queries about the images and generates the answer.
- VQA
- medical
- Vision and Language
- transformer
- greedy soup
- model soup
- swin
- electra
- classification
- visual question answering
1. Introduction
Visual question answering (VQA) is a process that provides meaningful information from images to a user based on a given question. With the rapid advancements in computer vision (CV) and natural language processing (NLP), medical visual question answering (Med-VQA) has attracted much attention. The Med-VQA model seeks to retrieve accurate answers by fusing clinical visuals and inquiries. The Med-VQA model can aid in medical diagnosis, automatically extract data from medical images, andower medical professionals’ training costs. Additionally, the Med-VQA system has many benefits for the medical industry. Here are a few illustrations:
-
Diagnosis and treatment: By offering a quick and precise method for analyzing medical images, Med-VQA can help medical practitioners diagnose and treat medical disorders. Healthcare experts can learn more about the patient’s condition by inquiring about medical imaging (such as X-rays, CT scans, and MRI scans), which can aid in making a diagnosis and selecting the best course of therapy. In addition, it would reduce the doctors’ efforts by letting the patients obtain answers to the most frequent questions about their images.
-
Medical education: By giving users a way to learn from medical images, Med-VQA can be used to instruct medical students and healthcare workers. Students can learn how to assess and understand medical images—a crucial ability in the area of medicine—by posing questions about them.
-
Patient education: By allowing patients to ask questions about their medical photos, Med-VQA can help them better comprehend their medical issues. Healthcare practitioners can improve patient outcomes by assisting patients in understanding their problems and available treatments by responding to their inquiries regarding their medical photos.
-
Research: Large collections of medical photos can be analyzed using Med-VQA to glean insights that can be applied to medical research. Researchers can better comprehend medical issues and create new remedies by posing questions regarding medical imaging and examining the results.
Although much Med-VQA research has been accomplished, it requires much enhancement due to public data and data size imitations to achieve practical usage. There are a few public data available: the VQA-RAD [1], VQA-Med 2019 [2], VQA-MED 2020 [3], SLAKE dataset [4], and Diabetic Macular Edema (DME) dataset [5]. Only the VQA-RAD and SLAKE datasets are manually generated and validated by clinicians. In addition, they have more question diversity among all medical VQA datasets. The DME dataset is manually generated but not validated by specialists.
Several models have been developed to solve this problem. These models rely on four types of methods: joint embedding approaches [6][7][8], attention mechanisms [9][10][11][12][13], composition models [12][14][15][16][17][18], and knowledge base-enhanced approaches [1][19][20][21]. In Med-VQA, VGGNet [22], ResNet [23], and the ensemble of vision pre-trained models [24][25] are the vision features extraction methods widely used, while LSTM [26], Bi-LSTM [27], and BERT [28] are the text features extraction mainly utilized. Lately, most models have aimed to use attention mechanisms to align between the text and image features [10][29][30][31]. In addition, vision and language (V + L) pre-trained models, such as visualBERT [32], VilBERT [33], UNITER [34], and CLIP [35]. Researchers claimed that Med-VQA requires more text information about images to facilitate the classification task for the model. Therefore, they utilize image captioning generation to give the model extra information about the image [36].
2. Visual Question Answering
VQA usually has four components: vision featurization, text featurization, fusion model, and classifier. Vision featurization is a part of the multi-model responsible for extracting the vision features. Text featurization is another part of the VQA multi-model responsible for extracting text features. The combination of both features and their processes is the fusion component. The last component is the classifier that classifies the queries about the images and generates the answer.2.1. Vision Featurization
Applying mathematical operations to an image requires representing it as a numerical vector, called image featurization. There are several techniques to extract the features of the image, such as scale-invariant feature transform (SIFT) [37], simple RGB vector, a histogram of oriented gradients (HOG) [38], Haar transforms [39], and deep learning. In deep learning, such as CNNs, visual feature extraction learns using a neural network. Using deep learning can be accomplished by training the model from scratch, which requires a large data size, or using transfer learning, which behaves significantly with a limited data size. Since medical VQA datasets are limited, most researchers aim to use per-trained models, such as AlexNet [40], VGGNet [22][41][42][43][44], GoogLeNet [45], ResNet [5][23][46][47][48][49][50], and DenseNet-121 [51]. Ensemble models can be stronger than single models, so there is a direction to use it as vision feature extraction [25][52][53][54][55].2.2. Text Featurization
As a vision featurization, a question has to be converted into a numeric vector using word-embedding methods for mathematical computations. A suitable text embedding method is based on trial and error [56]. Various text embedding methods are used in the SOTA to impact the multi-model significantly. The most common methods used in question models are LSTM [5][51][54][55][57], GRU [57], RNNs [42][58][59][60], Faster-RNN [57], and the encoder-decoder method [43][46][47][48][61][62]. In addition to the previous methods, pre-trained models have been used, such as Generalized Auto-regressive Pre-training for language Understanding (XLNet) [63] and the BERT model [28][43][49][50]. Some models have ignored text featurization and converted the problem into an image classification problem [53][64][65].2.3. Fusion
Extracting the features of text and images is processed independently. Therefore, those features are fused using the fusion method. Manmadhan et al. [56] classified fusion into three types: baseline fusion models, end-to-end neural network models, and joint attention models. In baseline fusions, various methods are used, such as element-wise addition [7], element-wise multiplication, concatenation [66], all of them combined [67], or a hybrid of these methods with a polynomial function [68]. End-to-end neural network models can be used to fuse image and text featurization. Various methods are currently used, including neural module networks (NMNs) [12], multimodal, MCB [46], dynamic parameter prediction networks (DPPNs) [69], multimodal residual network (MRNs) [70], cross-modal multistep fusion (CMF) networks [71], basic MCB model with a deep attention neural tensor network (DA-NTN) module [72], multi-layer perceptron (MLP) [73], and the encoder-decoder method [32][74]. The main reason for using the joint attention model is to address the semantic relationship between text attention and question attention [56]. There are various joint attention models, such as the word-to-region attention network (WRAN) [29], co-attention [30], the question-guided attention map (QAM) [10], and question type-guided attention (QTA) [31]. Neural network methods, such as LSTM and encoder-decoder, are also used in the fusion phase. Verma and Ramachandran [43] designed a multi-model that used encoder-decoder, STM, and GloVe. Furthermore, vision + language pre-trained models are also utilized, such as in [50]. In the VQA system, the question and image are embedded separately using one or a hybrid of text and vision featurization techniques mentioned above. Then, the textual and visual feature victors are combined with a fusion technique, such as concatenation, element-wise multiplication, or attention. The obtained victor from the fusion phase is classified using a classification technique, or it can be used to generate an answer as a VQA generation problem. Figure 1 shows the overall VQA system.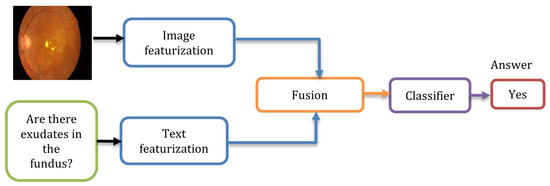
Figure 1. The Overall VQA Structure.
References
- Jason J. Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman: Data descriptor: A dataset of clinically generated visual questions and answers about radiology images. In Scientific Data, 5(1):1–10, Nov 2018
- Abacha, A.B.; Hasan, S.A.; Datla, V.V.; Liu, J.; Demner-Fushman, D.; Müller, H. VQA-Med: Overview of the Medical Visual Question Answering Task at ImageCLEF 2019. In proceeding of Working Notes of CLEF 2019, Lugano, Switzerland, 9–12 September 2019.
- Abacha, A.B.; Datla, V.V.; Hasan, S.A.; Demner-Fushman, D.; Müller, H. Overview of the VQA-Med Task at ImageCLEF 2020: Visual Question Answering and Generation in the Medical Domain. In Proceedings of the CLEF 2020—Conference and Labs of the Evaluation Forum, Thessaloniki, Greece, 22–25 September 2020; pp. 1–9.
- Liu, B.; Zhan, L.M.; Xu, L.; Ma, L.; Yang, Y.; Wu, X.M. SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 1650–1654.
- Tascon-Morales, S.; Márquez-Neila, P.; Sznitman, R. Consistency-Preserving Visual Question Answering in Medical Imaging. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022, Proceedings of the 25th International Conference, Singapore, 18–22 September 2022; Part VIII; Springer: Cham, Switzerland, 2022; pp. 386–395.
- Ren, M.; Kiros, R.; Zemel, R. Image question answering: A visual semantic embedding model and a new dataset. Proc. Adv. Neural Inf. Process. Syst. 2015, 1, 5.
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433.
- Malinowski, M.; Rohrbach, M.; Fritz, M. Ask your neurons: A neural-based approach to answering questions about images. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1–9.
- Jiang, A.; Wang, F.; Porikli, F.; Li, Y. Compositional memory for visual question answering. arXiv 2015, arXiv:1511.05676.
- Chen, K.; Wang, J.; Chen, L.C.; Gao, H.; Xu, W.; Nevatia, R. ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering. arXiv 2015, arXiv:1511.05960v2.
- Ilievski, I.; Yan, S.; Feng, J. A focused dynamic attention model for visual question answering. arXiv 2016, arXiv:1604.01485.
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Neural module networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–28 June 2016; pp. 39–48.
- Song, J.; Zeng, P.; Gao, L.; Shen, H.T. From pixels to objects: Cubic visual attention for visual question answering. arXiv 2022, arXiv:2206.01923.
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Learning to compose neural networks for question answering. arXiv 2016, arXiv:1601.01705.
- Xiong, C.; Merity, S.; Socher, R. Dynamic memory networks for visual and textual question answering. In Proceedings of the International Conference on Machine Learning, PMLR, New York City, NY, USA, 20–22 June 2016; pp. 2397–2406.
- Kumar, A.; Irsoy, O.; Ondruska, P.; Iyyer, M.; Bradbury, J.; Gulrajani, I.; Zhong, V.; Paulus, R.; Socher, R. Ask me anything: Dynamic memory networks for natural language processing. In Proceedings of the International Conference on Machine Learning, PMLR, New York City, NY, USA, 20–22 June 2016; pp. 1378–1387.
- Noh, H.; Han, B. Training recurrent answering units with joint loss minimization for VQA. arXiv 2016, arXiv:1606.03647.
- Gao, L.; Zeng, P.; Song, J.; Li, Y.F.; Liu, W.; Mei, T.; Shen, H.T. Structured two-stream attention network for video question answering. Proc. AAAI Conf. Artif. Intell. 2019, 33, 6391–6398.
- Wang, P.; Wu, Q.; Shen, C.; Hengel, A.v.d.; Dick, A. Explicit knowledge-based reasoning for visual question answering. arXiv 2015, arXiv:1511.02570.
- Wang, P.; Wu, Q.; Shen, C.; Dick, A.; Van Den Hengel, A. FVQA: Fact-based visual question answering. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2413–2427.
- Wu, Q.; Wang, P.; Shen, C.; Dick, A.; Van Den Hengel, A. Ask me anything: Free-form visual question answering based on knowledge from external sources. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–28 June 2016; pp. 4622–4630.
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556v6.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR 2016, Las Vegas, NV, USA, 27–28 June 2016; pp. 770–778.
- Nguyen, B.D.; Do, T.T.; Nguyen, B.X.; Do, T.; Tjiputra, E.; Tran, Q.D. Overcoming Data Limitation in Medical Visual Question Answering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2019; pp. 522–530.
- Do, T.; Nguyen, B.X.; Tjiputra, E.; Tran, M.; Tran, Q.D.; Nguyen, A. Multiple Meta-model Quantifying for Medical Visual Question Answering. arXiv 2021, arXiv:2105.08913.
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780.
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805.
- Peng, Y.; Liu, F.; Rosen, M.P. UMass at ImageCLEF Medical Visual Question Answering (Med-VQA) 2018 Task. In Proceedings of the CEUR Workshop, Avignon, France, 10–14 September 2018.
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. Adv. Neural Inf. Process. Syst. 2016, 29, 289–297.
- Shi, Y.; Furlanello, T.; Zha, S.; Anandkumar, A. Question Type Guided Attention in Visual Question Answering. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 151–166.
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557.
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11.
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the Computer Vision—ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 104–120.
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual only, 18–24 July 2021; pp. 8748–8763.
- Cong, F.; Xu, S.; Guo, L.; Tian, Y. Caption-Aware Medical VQA via Semantic Focusing and Progressive Cross-Modality Comprehension. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 3569–3577.
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Piscataway, NJ, USA of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157.
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893.
- Lienhart, R.; Maydt, J. An extended set of Haar-like features for rapid object detection. In Proceedings of the IEEE International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; pp. 900–903.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90.
- Zhang, D.; Cao, R.; Wu, S. Information fusion in visual question answering: A Survey. Inf. Fusion 2019, 52, 268–280.
- Abacha, A.B.; Gayen, S.; Lau, J.J.; Rajaraman, S.; Demner-Fushman, D. NLM at ImageCLEF 2018 Visual Question Answering in the Medical Domain; In Proceedings of Working Notes of CLEF 2018, Avignon, France, 10–14 September 2018.
- Verma, H.; Ramachandran, S. HARENDRAKV at VQA-Med 2020: Sequential VQA with Attention for Medical Visual Question Answering. In Proceedings of the Working Notes of CLEF 2018, Thessaloniki, Greece, 22–25 September 2020.
- Bounaama, R.; Abderrahim, M.E.A. Tlemcen University at ImageCLEF 2019 Visual Question Answering Task. In Proceedings of the Working Notes of CLEF 2018, Thessaloniki, Lugano, Switzerland, 9–12 September 2019.
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 5–12 June 2015; pp. 1–9.
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TC, USA, 1–5 November 2016; pp. 457–468.
- Kim, J.H.; On, K.W.; Lim, W.; Kim, J.; Ha, J.W.; Zhang, B.T. Hadamard Product for Low-rank Bilinear Pooling. In Proceedings of the 5th International Conference on Learning Representations, ICLR Toulon, France, 24–26 April 2017.
- Ben-Younes, H.; Cadene, R.; Cord, M.; Thome, N. MUTAN: Multimodal Tucker Fusion for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2612–2620.
- Huang, J.; Chen, Y.; Li, Y.; Yang, Z.; Gong, X.; Wang, F.L.; Xu, X.; Liu, W. Medical knowledge-based network for Patient-oriented Visual Question Answering. Inf. Process. Manag. 2023, 60, 103241.
- Haridas, H.T.; Fouda, M.M.; Fadlullah, Z.M.; Mahmoud, M.; ElHalawany, B.M.; Guizani, M. MED-GPVS: A Deep Learning-Based Joint Biomedical Image Classification and Visual Question Answering System for Precision e-Health. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 15–18 August 2022; pp. 3838–3843.
- Kovaleva, O.; Shivade, C.; Kashyap, S.; Kanjaria, K.; Wu, J.; Ballah, D.; Coy, A.; Karargyris, A.; Guo, Y.; Beymer, D.B.; et al. Towards Visual Dialog for Radiology. In Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing, Online, 9 July 2020; pp. 60–69.
- Liao, Z.; Wu, Q.; Shen, C.; van den Hengel, A.; Verjans, J. AIML at VQA-Med 2020: Knowledge Inference via a Skeleton-based Sentence Mapping Approach for Medical Domain Visual Question Answering. In Proceedings of the Working Notes of CLEF 2020, Thessaloniki, Greece, 22–25 September 2020.
- Gong, H.; Huang, R.; Chen, G.; Li, G. SYSU-Hcp at VQA-MED 2021: A data-centric model with efficient training methodology for medical visual question answering. In Proceedings of the Working Notes of CLEF 2021, Bucharest, Romania, 21–24 September 2021; Volume 201.
- Wang, H.; Pan, H.; Zhang, K.; He, S.; Chen, C. M2FNet: Multi-granularity Feature Fusion Network for Medical Visual Question Answering. In Proceedings of the PRICAI 2022: Trends in Artificial Intelligence, 19th Pacific Rim International Conference on Artificial Intelligence, PRICAI 2022, Shanghai, China, 10–13 November 2022; Part II. Springer: Cham, Switzerland, 2022; pp. 141–154.
- Wang, M.; He, X.; Liu, L.; Qing, L.; Chen, H.; Liu, Y.; Ren, C. Medical visual question answering based on question-type reasoning and semantic space constraint. Artif. Intell. Med. 2022, 131, 102346.
- Manmadhan, S.; Kovoor, B.C. Visual question answering: A state-of-the-art review. Artif. Intell. Rev. 2020, 53, 5705–5745.
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. PathVQA: 30.000+ questions for medical visual question answering. arXiv 2020, arXiv:2003.10286.
- Allaouzi, I.; Benamrou, B.; Benamrou, M.; Ahmed, M.B. Deep Neural Networks and Decision Tree Classifier for Visual Question Answering in the Medical Domain. In Proceedings of the Working Notes of CLEF 2018, Avignon, France, 10–14 September 2018.
- Zhou, Y.; Kang, X.; Ren, F. Employing Inception-Resnet-v2 and Bi-LSTM for Medical Domain Visual Question Answering. In Proceedings of the Working Notes of CLEF 2018, Avignon, France, 10–14 September 2018.
- Talafha, B.; Al-Ayyoub, M. JUST at VQA-Med: A VGG-Seq2Seq Model. In Proceedings of the Working Notes of CLEF 2018, Avignon, France, 10–14 September 2018.
- Vu, M.H.; Lofstedt, T.; Nyholm, T.; Sznitman, R. A Question-Centric Model for Visual Question Answering in Medical Imaging. IEEE Trans. Med. Imaging 2020, 39, 2856–2868.
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-Thought Vectors. Adv. Neural Inf. Process. Syst. 2015, 28, 3294–3302.
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the 33rd Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 5753–5763.
- Eslami, S.; de Melo, G.; Meinel, C. Teams at VQA-MED 2021: BBN-orchestra for long-tailed medical visual question answering. In Proceedings of the Working Notes of CLEF 2021, Bucharest, Romania, 21–24 September 2021; pp. 1211–1217.
- Schilling, R.; Messina, P.; Parra, D.; Lobel, H. Puc Chile team at VQA-MED 2021: Approaching VQA as a classfication task via fine-tuning a pretrained CNN. In Proceedings of the Working Notes of CLEF 2021, Bucharest, Romania, 21–24 September 2021; pp. 346–351.
- Zhou, Y.; Jun, Y.; Chenchao, X.; Jianping, F.; Dacheng, T. Beyond Bilinear: Generalized Multimodal Factorized High-Order Pooling for Visual Question Answering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5947–5959.
- Malinowski, M.; Rohrbach, M.; Fritz, M. Ask Your Neurons: A Deep Learning Approach to Visual Question Answering. Int. J. Comput. Vis. 2017, 125, 110–135.
- Kuniaki, S.; Andrew, S.; Yoshitaka, U.; Tatsuya, H. Dualnet: Domain-invariant network for visual question answering. In Proceedings of the the IEEE International Conference on Multimedia and Expo (ICME) 2017, Hong Kong, 10–14 July 2017; pp. 829–834.
- Noh, H.; Seo, P.H.; Han, B. Image Question Answering Using Convolutional Neural Network with Dynamic Parameter Prediction. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 30–38.
- Kim, J.H.; Lee, S.W.; Kwak, D.; Heo, M.O.; Kim, J.; Ha, J.W.; Zhang, B.T. Multimodal residual learning for visual QA. Adv. Neural Inf. Process. Syst. 2016, 29, 361–369.
- Mingrui, L.; Yanming, G.; Hui, W.; Xin, Z. Cross-modal multistep fusion network with co-attention for visual question answering. IEEE Access 2018, 6, 31516–31524.
- Bai, Y.; Fu, J.; Zhao, T.; Mei, T. Deep Attention Neural Tensor Network for Visual Question Answering. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 20–35.
- Narasimhan, M.; Schwing, A.G. Straight to the Facts: Learning Knowledge Base Retrieval for Factual Visual Question Answering. In Proceedings of the ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 451–468.
- Chen, L.; Yan, X.; Xiao, J.; Zhang, H.; Pu, S.; Zhuang, Y. Counterfactual Samples Synthesizing for Robust Visual Question Answering. In Proceedings of the Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 14–19 June 2020; pp. 10800–10809.
More