Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Nagwa ALi Sabri and Version 2 by Lindsay Dong.
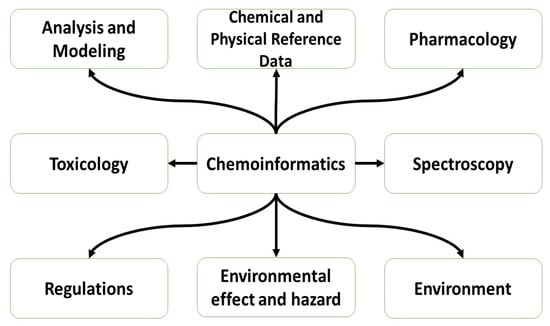
Chemoinformatics involves integrating the principles of physical chemistry with computer-based and information science methodologies, commonly referred to as “in silico techniques”, in order to address a wide range of descriptive and prescriptive chemistry issues, including applications to biology, drug discovery, and related molecular areas. On the other hand, the incorporation of machine learning has been considered of high importance in the field of drug design, enabling the extraction of chemical data from enormous compound databases to develop drugs endowed with significant biological features.
- chemoinformatics
- bioinformatics
- applications
- formulation
1. Introduction
Chemoinformatics, a new area of information technology, is primarily concerned with collecting, retaining, examining, and reorganizing chemical information. Small molecule formulae, structures, characteristics, spectra, and activities (biological or industrial) are typical examples of chemical data of interest. It began as an aiding tool in the process of drug discovery and development; however, presently, its significance has grown multifold, making it an essential component in numerous domains of chemistry, biochemistry, and biology [1].
The identification of hits is the first and most important stage in small-molecule drug discovery [2]. The employment of virtual chemical libraries in diverse virtual screening methods has become a promising approach to discovering novel hit chemicals. In this regard, several scholars are developing innovative de novo chemical and on-demand libraries using various in silico methodologies [3].
The chart (Figure 1) showed that chemoinformatics analysis involves a computational workflow utilizing machine learning. The process includes the following steps: The initial step involves extraction involving compound characterization by its substructure fragments or other chemical descriptors. Representation of the chemical features of the compound by chemical fingerprints, which are then used to compare the similarities between different compounds based on shared chemical features. Moreover, these chemical fingerprints can be utilized in various machine learning models, including instance- and/or model-based learning, to predict other chemical and physiochemical properties in QSAR/QSPR analysis. Such models can be trained using statistical models and then used to make inferences from the training data by comparison [4].
In general, virtual libraries address the requirement for increasing compound quality in order to discover promising compounds. In this context, the virtual libraries’ structural complexity, size, and variety are important factors in boosting the likelihood of favorable outcomes in drug discovery and development. Moreover, the establishment of virtual libraries is of immense advantage as the identified chemicals possess a certain degree of novelty and are synthetically viable [5].
It is worth mentioning that both metabolism and conveyance are important factors in determining a molecule’s bioavailability and biological activity. Keeping organized and reliable experimental data in a suitable repository as a relational database promotes straightforward computer processing and hence allows computational analyses to effectively infer high-quality information/knowledge. Metrabase is an exemplary database that combines both cheminformatics and bioinformatics resources, including thoroughly examined data on the transportation and metabolism of chemical substances in humans. Its major components consist of around 11,500 instances of interaction involving almost 3500 small molecule substrates and transport protein modulators, as well as CYP450 metabolic enzymes [6][7].
From the aforementioned, it is clear that bioinformatics and chemoinformatics are becoming essential with the continuous growth of both biological and chemical data, as these fields have the potential to revolutionize the life sciences and make a significant impact on human health. Understanding and developing new methods and tools that can be used to identify new drug targets, develop new diagnostic tests, and track the spread of diseases, as well as helping scientists better understand and manage biological and chemical data.
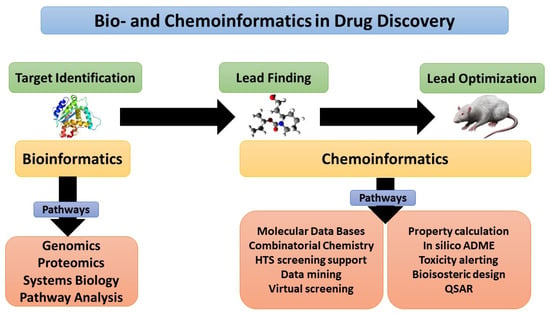
Figure 2 showed that bioinformatics and chemoinformatics tools are both complementary to each other in the drug discovery journey, where target identification represents the initial step in this journey, which can be done by various tools such as genomics and proteomics. The lead finding and optimization can be performed by several tools, such as data mining, QSAR, and insilico-ADME, where the resulting product is an active medicinal molecule that provides therapeutic response with low or minimal adverse effects [7][8].
3. Drug Discovery and Design
3.1. Chemoinformatics and New Tetracycline Analogue
Antimicrobial resistance to existing antibiotics indicates a critical global crossroads [8][9]. Unfortunately, widespread antibiotic use has resulted in the emergence of multi-drug-resistant pathogenic organisms and a reduction in the efficacy of many of otheur most potent antibiotics [9][10]. In addition, various harmful consequences of antibiotics, most notably the rising prevalence of Clostridium difficile-associated inflammatory bowel disease were investigated [10][11].
Tetracycline, a bacteriostatic agent, has the ability to inhibit the growth of a diverse array of microorganisms, encompassing Gram-negative and Gram-positive bacteria, mycoplasmas, chlamydiae, and rickettsiae [11][12]. The mechanism of bacterial resistance to tetracycline antibiotics includes mutations within the ribosome binding site or the acquisition of mobile genetic elements containing tetracycline-specific resistance genes [12][13]. The process of protein synthesis can be hindered by the binding of tetracycline to the 30S ribosomal subunit, which ultimately prevents aminoacyl transfer RNA (tRNA) from accessing the acceptor site on the ribosome [13][14].
3.2. Bio- and Chemoinformatics in Identification of Novel Pyrazole and Benzimidazole Based Derivatives as Penicillin-Binding Protein 2a Inhibitors
Methicillin-resistant Staph aureus’s (MRSA’s) extensive resistance to the lactam class is associated with the characteristics of its primary resistance mechanism, the “acquired” penicillin-binding protein 2a (PBP2a). The PBP2a’s innate reduced sensitivity towards β-lactam inactivation is attributed to its affinity for a closed active-site conformation, regulated by allostery [14][16]. PBP2a may cross-link the cell wall even when β-lactam antibiotics are present, whereas the other four native PBPs are restrained [15][17].3.3. Chemoinformatics Application in Phytochemistry
Natural products are thought to be a promising source of antifibrotic medicines; however, finding and isolating bioactive molecules remains difficult. The good news is that various computational approaches have emerged on this subject to save time and effort [16][19]. Eucalyptus globulus Labill., a perennial tree belonging to the family Myrtaceae, is widely cultivated across the globe. Eucalyptus species are commonly planted as line plantings in Egypt for multiple purposes, including shade provision, building timbers, poles, and fuelwood. One of the most significant byproducts in the Eucalyptus industry is its bark. Eucalyptus bark is thought to be an excellent source of phenolic chemicals with a variety of biological activities [17][18][20,21]. Polyphenols have a variety of uses in the cosmetics, food, and pharmaceutical sectors. This group of chemicals has been shown to have antioxidant, antimicrobial, antidiabetic, anti-inflammatory, antihyperlipidemic, hepatoprotective, nephroprotective, cardioprotective, and anticancer properties [19][22].4. Clinical Applications
4.1. Bioinformatics and Heart Disease Classification
For decades, heart disease has been regarded as the primary factor contributing to global death rates. In 2016, the World Health Organization reported that a sizable number of 17.9 million individuals had passed away due to cardiovascular disease [20][23]. Thus, data mining technologies have been investigated in recent decades to enhance heart disease prediction processes in the medical field [21][24]. The practice of discovering hidden patterns, information, and anomalies in massive data sets is known as data mining, which is regarded as the central component in the knowledge discovery in databases (KDD) process, which includes a number of phases such as data preparation, selection, transformation, and mining, which entails diverse activities such as prediction, clustering, and classification [22][23][25,26].4.2. Bioinformatics and Diagnosis of Coronavirus Disease 2019
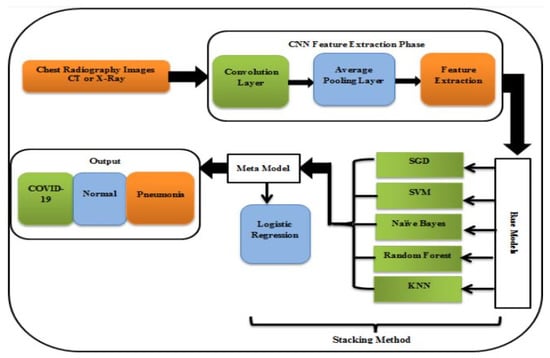
The outbreak of COVID-19 has posed a significant threat to the lives and well-being of many people, causing confusion in the global population’s public life. The escalating number of COVID-19 cases showed that all countries were faced with the daunting challenge of depleting resources for virus detection. The unprecedented spread of the virus has placed an immense strain on the limited resources available for the detection of this highly infectious disease. In order to effectively combat the spread of COVID-19, it is imperative to implement a COVID-19 detection system that is readily available, cost-effective, and capable of automation [24][28]. Due to the widespread presence of radiology imaging equipment in medical facilities, radiography-based detection techniques have emerged as a viable detection method to resolve the shortage of virus testing kits. With the advent of machines and deep learning, artificial intelligence has become highly advanced and thus fundamental in the field. Figure 34 represents the utilization of a COVID-19 detection stacking methodology that comprises two models as follows: The first (base) model is comprised of five classifiers: SGD, SVM, naive bayes, random forest, and KNN. The reason for selecting five classifiers is to ensure that there is always a majority identification, as opposed to using an even number of classifiers, which could result in an equal division of outcomes between two categories. The second model, referred to as the meta model, is logistic regression. This two-tiered approach to detecting COVID-19 is expected to yield more accurate results compared to using a single model alone [25][32].Figure 34. Model for COVID-19 detection [25].
4.3. Bioinformatics and Genomic Correlation with Clinical Information and Disease State
A PCR-based analysis has established a correlation between obesity and specific polymorphisms, including UCP2 G 866 A, LEPR Gln223Arg, and INSR exon 17, with the added observation that certain variations of risk are influenced by gender [26].
Model for COVID-19 detection [32].
4.3. Bioinformatics and Genomic Correlation with Clinical Information and Disease State
A PCR-based analysis has established a correlation between obesity and specific polymorphisms, including UCP2 G 866 A, LEPR Gln223Arg, and INSR exon 17, with the added observation that certain variations of risk are influenced by gender [33].
Additionally, a research study using an Illumina short-read sequencer-based investigation of the entire genomes of nine Egyptian women showed that 12 SNPs were shared by the majority of the participants related to obesity and were concordant with their clinical diagnosis using 30x sequencing coverage. Also, the presence of the mtDNA mutation A4282G in all samples was reported. [27][34]4.4. Bioinformatics and Multiple Drug Resistant Escherichia coli (E. coli) Isolation from Pediatric Cancer Patients
Escherichia coliis the primary etiological organism responsible for the incidence of bloodstream and urinary system infections globally. A steady growth inE. coli antibiotic resistance affects medical institutions worldwide by creating difficult-to-treat infections in patients [28]. Multiple drug resistance (MDR) genetic patterns are widely found in mobile elements like transposons, integrons, and plasmids that are passed on from foodborne pathogens to human pathogens, boosting their pathogenicity [29].The emergence of next-generation sequencing (NGS) has opened up new possibilities for efficient characterization of bacterial infections, enabling the identification of virulence-associated factors and genes that mediate resistance to antibiotics [30]. It is worth mentioning that NGS is a widely used technology for studying the evolutionary connections of MDRantibiotic resistance affects medical institutions worldwide by creating difficult-to-treat infections in patients [35]. Multiple drug resistance (MDR) genetic patterns are widely found in mobile elements like transposons, integrons, and plasmids that are passed on from foodborne pathogens to human pathogens, boosting their pathogenicity [36].The emergence of next-generation sequencing (NGS) has opened up new possibilities for efficient characterization of bacterial infections, enabling the identification of virulence-associated factors and genes that mediate resistance to antibiotics [37]. It is worth mentioning that NGS is a widely used technology for studying the evolutionary connections of MDRE. colistrains from various geographical locations; thus, through the analysis of genetic variations in diverseE. coli plasmids obtained from multiple sources, it is plausible to anticipate resistance traits from genomic sequences [31].plasmids obtained from multiple sources, it is plausible to anticipate resistance traits from genomic sequences [38].5. Optimization of Drug Delivery
5.1. Bio- and Chemoinformatics in Nose-To-Brain Formulation Targeting Meningitis
Meningitis is a serious medical condition caused by a diverse range of pathogens that can result in death. The meninges become infected or inflamed due to various infectious agents. This condition can be caused by a diverse range of pathogens [32][40]. It has been observed that viruses are responsible for nearly 50% of all cases, whereas fungi, usually cryptococci, are accountable for less than ten percent of all cases [33][41]. Bio- and chemoinformatics methods were used for comparative analysis of antimicrobial drugs to choose an effective nasal-to-brain delivery formulation that targets meningitis, where it was found that cephalosporin antibiotics, namely, cefotaxime and ceftriaxone, were comparable concerning formulation, biopharmaceutical, and therapeutic levels. An all-atom approach was employed for molecular dynamics simulations using the GROMACS v4.6.5 software, and the results showed that ceftriaxone has a higher affinity for the biopharmaceutical and therapeutic macromolecules studied than cefotaxime [34][43].5.2. Chemoinformatics Targeting Cancer Cell Therapy
Carcinogenesis is a complicated process involving the interplay of various elements that lead to an alteration in regular cellular functions and the eventual transformation of cells into a malignant state [35][44]. A comprehensive analysis of the various functions of the interacting components within the tumor microenvironment is crucial in the fight against cancer, which could lead to a better understanding of this unfavorable cell transformation and, as a result, the identification of potential molecular targets for early prognosis together with the discovery of chemotherapeutic drugs [36][45]. Epithelial cell transforming 2 (ECT2) is a putative oncogene that has been linked to the advancement of numerous human malignancies in recent investigations. Despite the increased interest in ECT2 in oncology-related papers, there has to be a thorough examination that consolidates and harmonizes the expression and oncogenic conduct of ECT2 across a range of human malignancies. Using numerous databases, ECT2 could potentially function as a valuable biomarker across an array of malignancies; thus, chemoinformatics was used to investigate which ECT2 inhibitors might be used as anticancer medicines r.5.3. Bio- and Chemoinformatics in Nose-To-Brain Formulation for Treatment of Alzheimer Disease
It is worthy of mention that delivering drugs to the brain for treatment of severe CNS illnesses such as Alzheimer’s has remained a significant issue for pharmaceutical formulation and development. This is primarily attributed to the numerous defense systems against drugs’ delivery to the brain. These systems present formidable barriers that most drugs are unable to overcome, making it difficult for them to cross the blood–brain barrier and penetrate the extracellular matrix of the brain to reach the targeted brain cells [37][48]. As a result, while directing medications to the brain poses a significant obstacle in the treatment of many CNS illnesses, a novel route of administration looked promising in tackling this problem. This is known as ‘Nose-to-Brain’ targeting.6. Some Advances in New Algorithms and Artificial Intelligence Worldwide
6.1. Chemoinformatics and Hybrid Harris Hawks Optimization with Cuckoo Search
One of the significant problems in cheminformatics is the large datasets containing a significant amount of redundant information. This redundancy can negatively impact similarity measurements with respect to drug design and discovery, which could be solved through a hybrid metaheuristic algorithm called CHHO–CS that combines the Harris–Hawks optimizer (HHO) with two operators, cuckoo search (CS), and chaotic maps to balance exploration and exploitation phases and avoid premature convergence. The experimental and statistical analyses demonstrate that the CHHO–CS method outperforms competitor algorithms such as HHO, CS, particle swarm optimization, etc. The proposed algorithm is expected to improve the efficiency and accuracy of similarity measurements for drug design and discovery [38][51].6.2. Chemoinformatics and Bioinformatics Integration with Artificial Intelligence (AI)
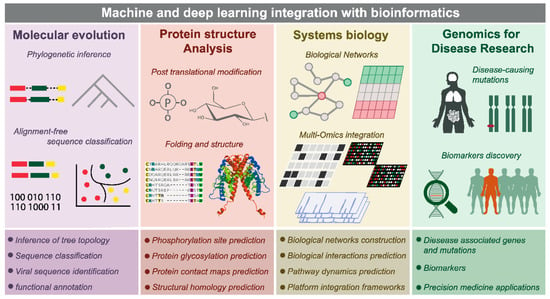
The insufficiency in effectiveness resulting from issues related to the availability of the drug in the body and unfavorable reactions to the drug are acknowledged as a primary reason for the termination of clinical trials. The vast array of potential factors that may lead to the failure or adverse effects of a compound is expansive. Additionally, the assessment of a compound’s characteristics through in vitro and in vivo methods can be a significant investment in terms of both time and resources. The application of AI models has made significant strides in enhancing the precision of early drug efficacy and safety predictions by leveraging the vast information provided by heterogeneous ADME-Tox data sets. In the domain of machine learning (ML), various models have been developed to derive hypothetical properties from limited experimental data or to characterize in vivo properties based on in vitro assay data. However, there are potential limitations to the accuracy of such models. In this regard, Rodríguez-Pérez et al. demonstrated the effectiveness of multitask learning based on graph neural networks (MT-GNN) in achieving superior performance compared to other ML approaches that rely solely on in vitro brain penetration data [39][55]. There are four areas in computational biology where ML and DL can be integrated with established bioinformatic methods, namely: molecular evolution, protein structure analysis, systems biology, and disease genomics. In addition, machine learning algorithms such as support vector machines (SVM), K-nearest neighbors (KNN), convolutional neural networks (CNN), recurrent neural networks (RNN), principal component analysis (PCA), t-distributed stochastic neighbor embedding (t-SNE), and non-negative matrix factorization (NMF) are frequently used in bioinformatics research [40][56]. Figure 46 shows that the utilization of integrated machine learning techniques in combination with bioinformatics has proven to be a valuable tool in various fields, namely molecular evolution, protein structure analysis, systems biology, and disease genomics. Molecular evolution includes alignment-free sequence classification and phylogenetic interference. Protein structure analysis includes post-translational modifications. Systems biology includes biological networks and multiomics integration. Disease genomics includes disease-causing mutations and biomarker discovery. The end goal of bioinformatics applications integrated with machine learning is to provide precision medicine applications for each individual case.Bioinformatics Applications of Integrated Machine Learning Techniques [56].7. Conclusions
Chemo- and bioinformatics showed different applications globally in research studies. The use of virtual chemical libraries and virtual screening methods can increase the probability of discovering novel hit chemicals. The outcomes include several benefits in drug discovery, disease diagnosis and classification, special pharmaceutical formulations for minorities and Alzheimer’s disease, and phytochemistry therapeutic discovery. Ensemble models and brute force feature selection methodology have resulted in high accuracy rates for heart disease and COVID-19 diagnosis. Other benefits of pharmaceutical research include targeted cancer cell therapy, the identification of novel molecules for antimicrobial resistance, genomic correlation with disease state, and the identification of multidrug-resistant organisms. Moreover, the use of AI in chemoinformatics can help in the prediction of drug properties and toxicity, while AI in bioinformatics can aid in the analysis of large-scale genomic and proteomic data. It is essential to extend the application of chemoinformatics in drug discovery, clinical pharmacy settings, and the formulation of targeted dosage forms for special diseases, as there is no broad use of chemoinformatics in these areas.