Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 2 by Peter Tang and Version 1 by zihang su.
Remote sensing image object detection holds signifificant research value in resources and the environment. Nevertheless, complex background information and considerable size differences between objects in remote sensing images make it challenging.
- object detection
- remote sensing images
- attention mechanism
1. Introduction
High-resolution remote sensing images are now more accessible with the continuous advancements in remote sensing and drone technology. Remote sensing image object detection is identifying and locating objects in high-resolution remote sensing images through remote sensing technology. It is a crucial task in remote sensing and satellite image analysis. The broad applicability and significant research value of remote sensing image object detection are evident in fields such as military reconnaissance, urban planning, and agricultural surveying [1][2].
Object detection includes traditional methods and deep learning-based methods. Although traditional detection methods show good interpretability, they require manual feature design, which might lead to sensitivity to changes in the shape and size of the object, making them difficult to adapt to complex scenes. Deep learning-based methods can automatically learn features from raw data, notably enhancing the accuracy and robustness of detection. Among deep learning-based methods, the algorithm based on Region Proposal appeared earliest, such as Faster R-CNN [3], Cascade R-CNN [4], and Mask R-CNN [5]. The detection task is partitioned into two stages in this type of algorithm. The Region Proposal Network (RPN) generates region proposals in the first stage, whereas the second stage performs object classification and location regression; although this two-stage detection algorithm can attain high detection results, its low detection speed can limit its applications in real-time detection scenarios. In contrast, a one-stage detection algorithm directly regresses and predicts each object without the Region Proposal stage, which leads to a much faster detection speed. RetinaNet [6], Single Shot MultiBox Detector (SSD) [7], and YOLO [8][9][10][11][12] series are representatives of one-stage detection algorithms. Meanwhile, anchor-free object detection methods without predefined anchors have become increasingly popular, with examples such as Fully Convolutional One-Stage Object Detection (FCOS) [13] and YOLOX [14]. Recently, object detectors based on transformers have attracted attention in object detection. DETR [15] is the first application of transformers in object detection, which does not require anchor boxes or region extraction networks, but directly predicts the position and category of objects from images using transformer networks. Deformable DETR [16] was improved on DETR, which uses deformable convolution to improve object feature extraction and position representation. Deformable DETR performs better than DETR in multiple object detection tasks. These object detection methods based on deep learning have gained widespread use across various natural-scene object detection tasks, where they have demonstrated excellent performance.
Remote sensing image object detection presents a significant challenge due to pronounced dissimilarities between remote sensing images and natural images. Specifically, natural images are typically taken horizontally from the ground, whereas remote sensing images are captured from a high altitude and are perpendicular to the ground. The difference in imaging angles will induce variations in the characteristics of the same kind of objects. In addition, remote sensing images offer a vast field of view, often resulting in the inclusion of many complex background information. The background noise will interfere with the recognition and extraction of object features, negatively impacting detection outcomes. Further, the size of different objects in remote sensing images varies greatly, and the size of the same object will also change according to the shooting height. The drastic size differences and variations can lead to degradation of detection performance. Figure 1 illustrates remote sensing image samples that exemplify differences between remote sensing and natural images. Consequently, the detection performance of the generic object detection methods will decrease when they are directly applied to the remote sensing image object detection task.
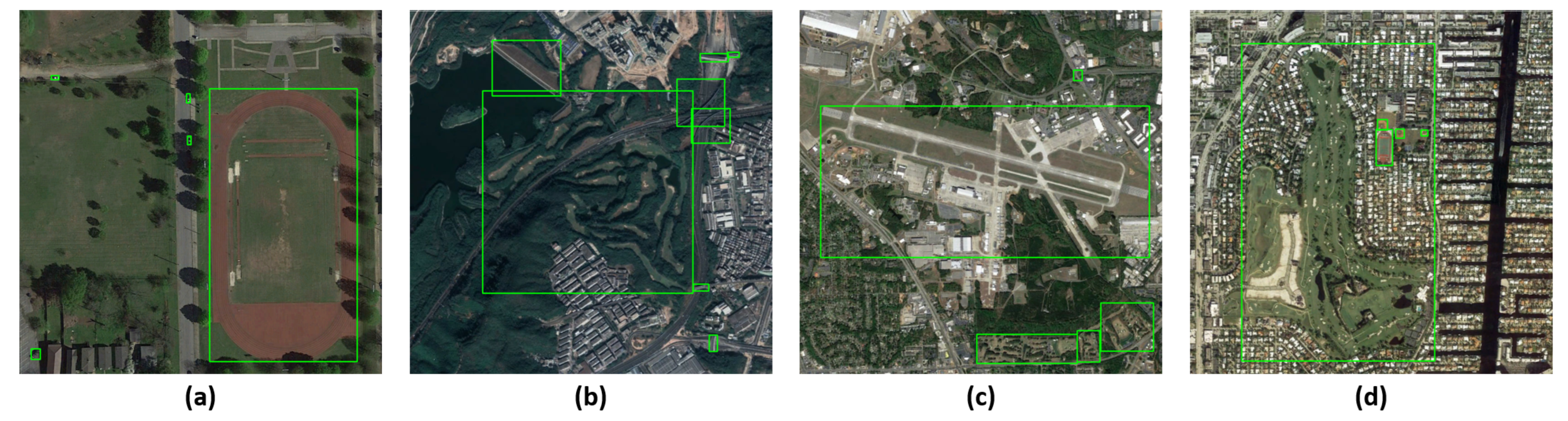
Figure 1.
Image samples in the DIOR dataset: (
a
,
b
) show the problem of significant differences in object size; (
c
,
d
) show the complexity of background noise.
2. Object Detection for Remote Sensing Images
Before deep learning was applied to object detection, traditional remote sensing image object detection methods mainly included threshold-based clustering, template matching, and feature extraction. The authors of [17] proposed a method for object detection based on mean shift segmentation and non-parametric clustering, which uses prior knowledge of the object shape and a hierarchical clustering method for object extraction and clustering. The authors of [18] proposed a remote sensing image object detection method based on feature extraction, which proposes an improved SIFT (Scale-Invariant Feature Transform) algorithm to extract uniformly distributed matching features, then refines the initial matching by binary histogram and random sample consensus. Traditional remote sensing image detection methods usually require prior knowledge to design features manually, which are then poorly robust to complex scene changes and noise disturbances, resulting in low detection performance.
With the widespread application of deep learning in object detection, many researchers have improved the general detectors applied to remote sensing image object detection tasks. The authors of [19] proposed a contextual refinement module for remote sensing images based on Faster R-CNN to extract and refine the contextual information and improve the Region Proposal Network (RPN) to obtain more positive samples. However, it did not consider the problem of background noise. L-SNR-YOLO [20] constructs a network backbone by a swin-transformer and convolutional neural network (CNN) to obtain multi-scale global and local information. Moreover, a feature enhancement module is proposed to make image features salient. However, this approach should have considered the lightweight of the model, which leads to the introduction of a large number of parameters. LOCO [21] proposes a variant of YOLO that uses the spatial characteristics of the object to design the layer structure of the model and uses constrained regression modeling to improve the robustness of the predictions, which allows for better detection of small and dense building footprints. TPH-YOLOv5 [22] adds a detection layer for small objects based on YOLOv5 and introduces a spatial attention mechanism and transformer encoder module, significantly improving the detection accuracy for small objects in UAV images, but it neglected the large variations of object scale in remote sensing images. DFPH-YOLO [23] proposes a dense feature pyramid network for remote sensing images based on YOLOv3, which enables four detection layers to combine semantic information before and after sampling to improve object detection performance at different scales. However, the introduction of irrelevant background information was not avoided.
Recently, some studies have proposed new strategies and methods for remote sensing image object detection. LAG [24] proposes a hierarchical anchor generation algorithm that generates anchors in different layers based on the diagonal and aspect ratio of the object, making the anchors in each layer match better with the detection range of that layer. The authors of [25] proposed a new multi-scale deformable attention module and a multi-level feature aggregation module and inserts them into the feature pyramid network (FPN) to improve the detection performance of various shapes and sizes of remote sensing objects. RSADet [26] considers the spatial distribution, scale, and orientation changes of the objects in remote sensing images by introducing deformable convolution and a new bounding box confidence prediction branch. The authors of [27] proposed to cast the bounding box regression in the aerial images as a center probability map prediction problem, thus largely eliminating the ambiguities on the object definitions and the background pixels. Although these above studies provide optimization schemes for remote sensing image detection, they neglect the problem of background noise introduction when the model performs feature extraction on elongated objects in remote sensing images. In addition, the problem of weight allocation of different quality samples in images to the regression process and the lightweight design of the model also need to be considered.
3. Attention Mechanism
Currently, attention mechanisms have been widely applied in the field of image processing. The attention mechanisms can adaptively select essential parts the network should focus on, thereby improving its feature extraction ability. The attention mechanisms can be divided into spatial and channel attention mechanisms. The spatial attention mechanism guides the model to focus on critical spatial regions in a weighted manner, thereby improving the perception ability of the network for image details. The channel attention mechanism learns the weights of each channel, allowing the network to pay more attention to the critical channels in the image during the training process, thereby improving the ability of the network to extract image features.
The Squeeze-and-Excitation Network (SENet) [28] is a classic channel attention method. It first compresses the features on the channel by global average pooling, then learns the weight of each channel through two fully connected layers, thus weighting the channel importance of the input feature map to learn the relationship between global channel information. Efficient Channel Attention (ECA) [29] improves on SENet by using one-dimensional convolution with adaptive convolution kernel size instead of global connections, learning more practical information in a more efficient way but ignoring the relationship between global channel information. The Convolutional Block Attention Module (CBAM) [30] is a mixed attention method in both channel and spatial domains, which combines channel and spatial attention by performing average pooling and max pooling operations on the input feature map. Coordinate Attention (CA) [31] is a spatial position-based attention mechanism. It extracts information through horizontal and vertical direction average pooling operations, encodes the spatial position information of the input feature map into two-dimensional coordinates, fuses coordinate information into channel information, and then pays attention, and is a very effective attention mechanism. Triplet Attention Module (TAM) [32] is a rotation attention mechanism that rotates the feature map so that the model can focus on different parts of the object in different directions, thereby improving the accuracy of object detection and image classification. Non-Local [33], Self-Calibrated Convolutions (SC) [34], and Bi-Level Routing Attention (BRA) [35] are all self-attention mechanisms used for computer vision tasks. This method establishes a relationship between pixels in the image and weights them semantically, but often introduces a large number of additional parameters.
These attention mechanisms perform well in images in natural scenes by adaptively calibrating and directing the network to focus more on the foreground of the feature map, thus slightly mitigating the interference of background noise in the image. However, for remote sensing images, none of the above attention methods adopts an effective strategy to reduce the introduction of background noise and ignores the problem of scale differences of remote sensing objects. Hence, the performance improvement in the object detection task of remote sensing images is lower than in natural scenes.
4. GSConv
In order to improve the performance and efficiency of networks, the study of lightweight models has also received widespread attention. Models such as MobileNet [36], ShuffleNet [37], and EfficientNet [38] achieve lightweight design through different techniques. Among them, Depthwise Separable Convolution is a common lightweight convolution technique consisting of two steps: Depthwise Convolution (DWConv) and Pointwise Convolution (PWConv). Figure 2a shows the framework of DWConv. It applies a separate convolution kernel to each channel of the input tensor, for example, using C convolution kernels to perform convolution operations on an input tensor with C channels. The size of each convolution kernel is usually small, such as 3 × 3 or 5 × 5. PWConv, as shown in Figure 2b, applies a 1 × 1 convolution kernel for dense calculation, which can fuse information between channels and reduce dimensionality.
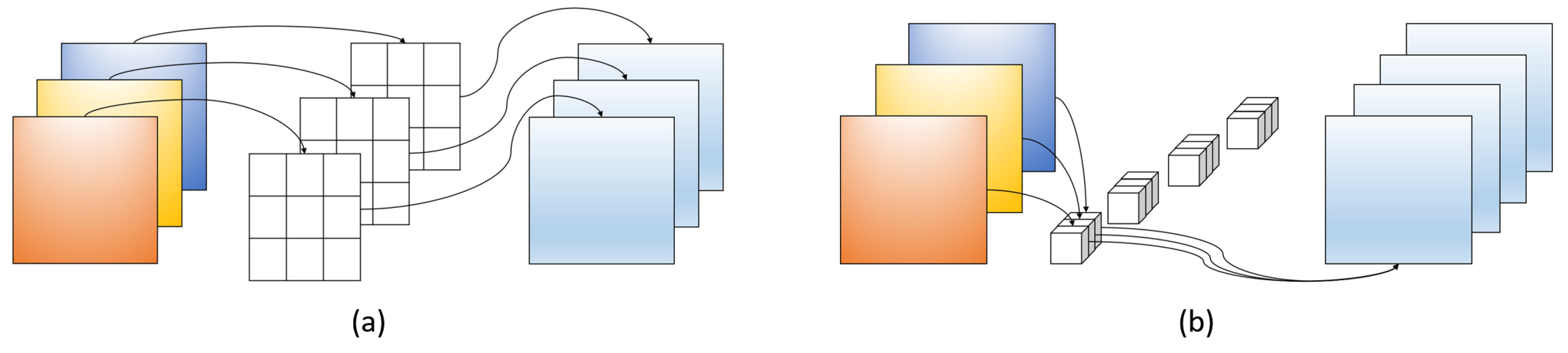
Figure 2.
Illustration of two types of convolution: (
a
) Depthwise Convolution; (
b
) Pointwise Convolution.
DWConv is equivalent to a grouped convolution with the number of groups equal to the number of channels in the input tensor. Each channel is calculated using a separate convolution kernel. Although this method can significantly reduce the number of parameters and computation costs, there is no interaction between channels, and the information between channels is separated during the calculation. It is an important reason for the low accuracy of DWConv calculation. PWConv fuses channel information through dense convolution operations of 1 × 1, which has higher calculation accuracy. However, this dense convolution also brings more parameters and computational costs. Depthwise Separable Convolution uses DWConv and PWConv but simply connects them in series, and the dense calculation results between channels are separated. Compared with ordinary convolution, although the number of parameters is reduced, the calculation accuracy is lower, which will affect the detection performance of the model.
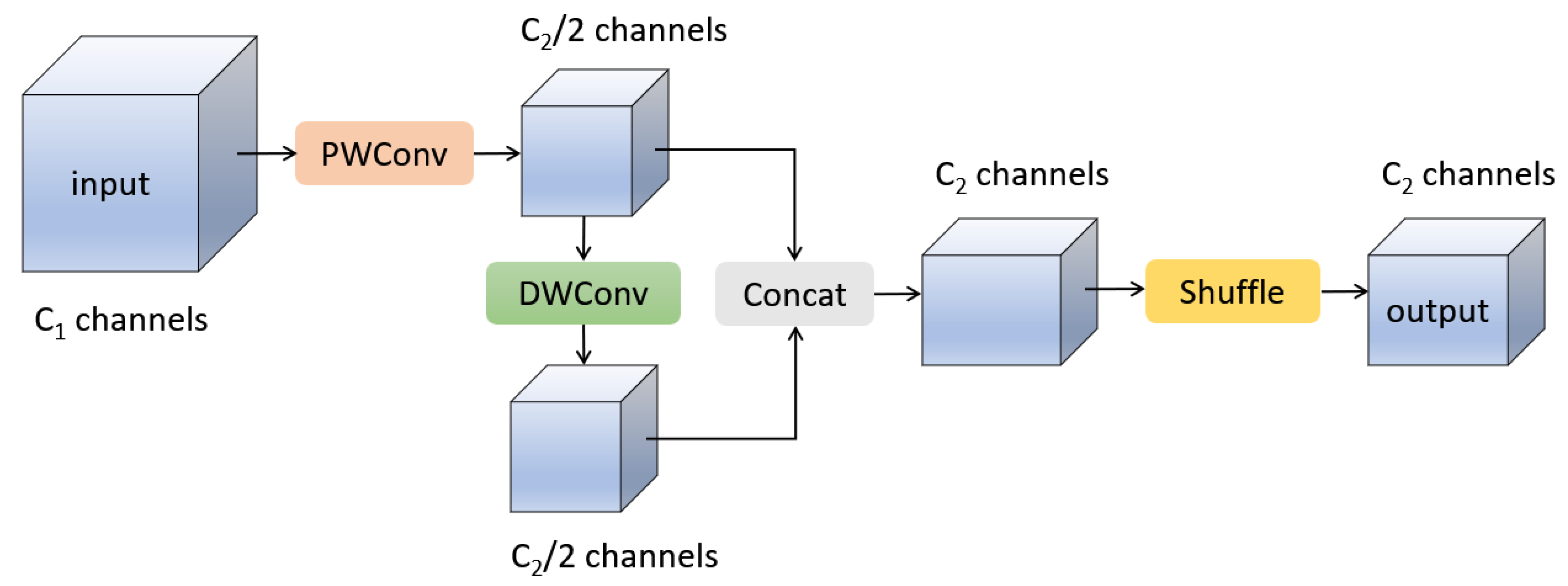
To solve the abovementioned problem, Li et al. proposed GSConv [39], a new lightweight convolution technique. The structure of the GSConv module is shown in Figure 3, where PWConv and DWConv represent Pointwise Convolution and Depthwise Convolution in depth-separable convolution, respectively. They are combined in a more efficient way in GSConv. Assuming that the number of channels in the input tensor is C1 and the number of channels in the output tensor is C2, first, to obtain more accurate dense calculation results, the module uses a PWConv to calculate the input tensor and compresses the channels to 1/2 of the output channels. Then, to ensure lightweight computation, a depth-wise DWConv operation is performed on the dense computation result of PWConv to obtain a result with C2/2 channels. These two calculation results obtained above are then stacked along the channel dimension to obtain a tensor with C2 channels. Finally, to mix the calculation results of PWConv and DWConv, a shuffle operation is applied along the channel dimension, allowing the information generated by PWConv to permeate into different parts of the computation result of DWConv. GSConv combines the accuracy of dense computation and the lightweight characteristics of depth-wise computation, making it an efficient, lightweight convolution method.
Figure 3.
Structure of GSConv module.
References
- Cheng, G.; Han, J. A Survey on Object Detection in Optical Remote Sensing Images. arXiv 2016, arXiv:1603.06201.
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. Isprs J. Photogramm. Remote Sens. 2020, 159, 296–307.
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99.
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2017; pp. 6154–6162.
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 386–397.
- Lin, T.Y.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 318–327.
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Santiago, Chile, 7–13 December 2015.
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2015; pp. 779–788.
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the Computer Vision and Pattern Recognition, San Juan, PR, USA, 17–19 June 1997; Springer: Berlin/Heidelberg, Germany, 2018; pp. 1804–2767.
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934.
- Jocher, G.; Stoken, G.; Borovec, A.; Chaurasia, J.; Changyu, A.; Hogan, L.; Hajek, A.; Diaconu, J.; Kwon, L.; Defretin, Y.; et al. Ultralytics/yolov5: V5.0—YOLOv5-P6 1280 Models, AWS, Supervise.ly and YouTube Integrations. Zenodo 2021.
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696.
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9626–9635.
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430.
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872.
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159.
- SushmaLeela, T.; Chandrakanth, R.; Saibaba, J.; Varadan, G.; Mohan, S.S. Mean-shift based object detection and clustering from high resolution remote sensing imagery. In Proceedings of the 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Jodhpur, India, 18–21 December 2013; pp. 1–4.
- Paul, S.B.; Pati, U.C. Remote Sensing Optical Image Registration Using Modified Uniform Robust SIFT. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1300–1304.
- Wang, Y.; Xu, C.; Liu, C.; Li, Z. Context Information Refinement for Few-Shot Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 3255.
- Niu, R.; Zhi, X.; Jiang, S.; Gong, J.; Zhang, W.; Yu, L. Aircraft Target Detection in Low Signal-to-Noise Ratio Visible Remote Sensing Images. Remote Sens. 2023, 15, 1971.
- Xie, Y.; Cai, J.; Bhojwani, R.; Shekhar, S.; Knight, J.F. A locally-constrained YOLO framework for detecting small and densely-distributed building footprints. Int. J. Geogr. Inf. Sci. 2020, 34, 777–801.
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, QC, Canada, 11–17 October 2021; pp. 2778–2788.
- Sun, Y.; Liu, W.; Gao, Y.; Hou, X.; Bi, F. A Dense Feature Pyramid Network for Remote Sensing Object Detection. Appl. Sci. 2022, 12, 4997.
- Wan, X.; Yu, J.; Tan, H.; Wang, J. LAG: Layered Objects to Generate Better Anchors for Object Detection in Aerial Images. Sensors 2022, 22, 3891.
- Dong, X.; Qin, Y.; Fu, R.; Gao, Y.; Liu, S.; Ye, Y.; Li, B. Multiscale Deformable Attention and Multilevel Features Aggregation for Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5.
- Yu, D.; Ji, S. A new spatial-oriented object detection framework for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–16.
- Wang, J.; Yang, W.; Li, H.; Zhang, H.; Xia, G. Learning Center Probability Map for Detecting Objects in Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4307–4323.
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2011–2023.
- Wang, Q.; Wu, B.; Zhu, P.F.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2019; pp. 11531–11539.
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19.
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021; pp. 13708–13717.
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2020; pp. 3138–3147.
- Wang, X.; Girshick, R.B.; Gupta, A.K.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2017; pp. 7794–7803.
- Liu, J.; Hou, Q.; Cheng, M.M.; Wang, C.; Feng, J. Improving Convolutional Networks With Self-Calibrated Convolutions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10093–10102.
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W.H. BiFormer: Vision Transformer with Bi-Level Routing Attention. arXiv 2023, arXiv:2303.08810.
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861.
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2017; pp. 6848–6856.
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946.
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424.
More