Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Jayasurya Arasur Subramanian and Version 2 by Rita Xu.
The advancement of autonomous technology in Unmanned Aerial Vehicles (UAVs) has piloted a new era in aviation. While UAVs were initially utilized only for the military, rescue, and disaster response, they are now being utilized for domestic and civilian purposes as well. In order to deal with its expanded applications and to increase autonomy, the ability for UAVs to perform autonomous landing will be a crucial component.
- autonomous landing
- unmanned aerial vehicle
- computer vision
1. Introduction
Drones, or Unmanned Aerial Vehicles (UAV), have a wide range of uses, from military applications to domestic uses, due to their ease of control, maneuverability, cost-effectiveness, and lack of pilot involvement. Certain drone operations, such as resource exploration and extraction, surveillance, and disaster management, demand autonomous landing as human involvement in these operations may be dangerous, particularly if communication is lost. As a result, recent developments in drone technology have focused on replacing human involvement with autonomous controllers that can make their own decisions.
Launching a drone autonomously is relatively straightforward; the challenging aspect is landing it in a specific location with precision in case of emergency situations. For an autonomous landing to be successful, the drone must have accurate information regarding its landing position, altitude, wind speed, and wind direction. Armed with these data, the UAV can make adjustments to its landing approach, such as reducing speed or altering its altitude, to ensure a safe and successful landing. The landing area can be classified into three categories: static, dynamic, and complex. Static locations are those that are firmly fixed to the ground, such as helipads, airports, and roads. Dynamic locations, on the other hand, are landing areas that are positioned on moving objects, such as a helipad on a ship or drone landing areas on trucks or cars. Complex landing areas are those that have no markings on the surface and can pose a challenge, such as areas near water bodies, hilly regions, rocky terrain, and areas affected by natural disasters such as earthquakes and floods. Figure 1 gives a view of these types of landing areas.
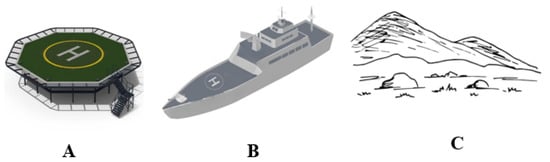
Figure 1. Type of Landing Area: (A) Static. (B) Dynamic. (C) Complex.
2. Type of Landing Areas
The categorization of target locations is divided into three types: Static, Dynamic, and Complex, with Static locations further subdivided into cooperative target-based, and Dynamic locations being classified into vehicle-based and ship-based locations. Xin et al. [1][27] discuss cooperative target-based autonomous landing, which is further classified into classical machine learning solutions such as Hough transformation, template matching, Edge detection, line mapping, and sliding window approaches. The author begins with basic clustering algorithms and progresses through deep learning algorithms to address the static location.
Cooperative-based landing pertains to landing sites that are clearly defined and labeled with identifiable patterns, such as the letter “T” or “H”, a circle, a rectangle, or a combination of these shapes, based on specific geometric principles, as described in Xin (2022) [1][27]. The different types of landing area markings are depicted in Figure 2.

Figure 2. Commonly used Landing Signs/Markings.
2.1. Static Landing Area
The localization of different types of markings relies on a range of techniques, from image processing to advanced machine learning. Localization of the “T” marking helipad achieves the maximum precision at specific poses using Canny Edge detection, Hough Transform, Hu invariant, Affine moments, and adaptive threshold selection [2][3][28,29]. Localization of the “H” marking achieves a success rate of 97.3% using image segmentation, depth-first search, and adaptive threshold selection in [4][30], while it achieves the maximum precision at pose 0.56∘ using image extraction and Zernike moments obtained in [5][31].
The “Circle” marking’s localization is addressed in two studies, namely [6][7][32,33]. Through the implementation of solvePnPRansac and Kalman filters, Benini et al. [6][32] were able to achieve a position error that is less than 8% of the diameter of the landing area, while maximum precision at pose 0.08∘ using an Extended Kalman filter was achieved by [7][33]. Detecting combined marking types is discussed in [8][9][10][11][34,35,36,37]. The maximum precision at specific poses using template matching, Kalman filter, and a profile-checker algorithm was achieved in [8][34]. Meanwhile, the other combined detection method predicts the maximum precision at pose 0.5∘ using tag boundary segmentation, image gradients, and adaptive threshold [9][35]. Ref. [10][36] achieves maximum precision at a position of less than 10 cm using Canny Edge detection, adaptive thresholding, and Levenberg–Marquardt. Lastly, the final combined detection approach obtains maximum precision at a position of less than 1% using HOG, NCC, and AprilTags [11][37].
Forster et al. [12][38] designed a system to detect and track a target mounted on the vehicle using computer vision algorithms and hardware. The system used in the Mohamed Bin Zayed International Robotics Challenge 2017 (MBZIRC) employed a precise RTK-DGPS to determine the target location, followed by a circle Hough transform to accurately detect the center of the target. By tracking the target, the UAV adjusted its trajectory to match the movement of the vehicle. The system successfully met the requirements of the task and was ranked as the best solution, considering various constraints. There are some limitations in the system, such as weather conditions and vehicle speed, which may affect its performance. Overall, this respapearchr provides an interesting approach to solving an important problem in robotics research, which has potential applications in various fields such as aerial monitoring and humanitarian demining operations.
2.2. Dynamic Landing Area
Two categories of dynamic landing areas exist based on the motion of the platform, namely ship-based and vehicle-based landings. Due to the complexity of landing on a moving platform, LiDAR sensors are used in conjunction with computer vision techniques. The landing process is facilitated using a model predictive feedback linear Kalman filter, resulting in a landing time of 25 s and a position error of less than 10 cm [13][39]. Another algorithm uses nonlinear controllers, state estimation, convolutional neural network (CNN), and velocity observer to achieve maximum precision at positions less than (10, 10) cm [14][40], while the algorithm employs a deep deterministic policy gradient with Gazebo-based reinforcement learning and achieves a landing time of 17.5 s with a position error of less than 6 cm [15][41]. Lastly, the algorithm proposed in [16][42] uses extended Kalman, extended H∞, perspective-n-point (PnP), and visual–inertial data fusion to achieve maximum precision at positions less than 13 cm.
The algorithm presented in [17][43] utilizes extended Kalman and visual–inertial data fusion techniques to achieve a landing time of 40 s for ship-based landing area detection. Meanwhile, another algorithm employs a Kalman filter, artificial neural network (ANN), feature matching, and Hu moments to achieve a position error of (4.33, 1.42) cm [18][44]. The approach outlined in [19][45] utilizes the EPnP algorithm and a Kalman filter, but no experimental results are presented. Battiato et al. [20][46] have introduced a system that enables real-time 3D terrain reconstruction and detection of landing spots for micro aerial vehicles. The system is designed to run on an onboard smartphone processor and uses only a single down-looking camera and an inertial measurement unit. A probabilistic two-dimensional elevation map, centered around the robot, is generated and continuously updated at a rate of 1 Hz using probabilistic depth maps computed from multiple monocular views. This mapping framework is shown to be useful for the autonomous navigation of micro aerial vehicles, as demonstrated through successful fully autonomous landing. The proposed system is efficient in terms of resources, computation, and the accumulation of measurements from different observations. It is also less susceptible to drifting pose estimates.
2.3. Complex Landing Area
The complex landing area is a challenging task for autonomous landing systems. The terrain in these areas can have various obstacles and hazards, and it is not always possible to find a suitable landing area. Researchers have explored different methods for identifying safe landing areas in complex terrain, but the research in this area is limited. Fitzgerald and Mejia’s research on a UAV critical landing place selection system is one such effort [17][18][43,44]. To locate a good landing spot, a monocular camera and a digital elevation model (DEM) are used. This system has multiple stages, including primary landing location selection, candidate landing area identification, DEM flatness analysis, and decision-making. The method’s limitations stemmed from the fact that it only used the Canny operator to remove edges and that the flat estimation stage’s DEM computation lacked resilience.
Research on unstructured emergency autonomous UAV landings using SLAM was conducted during the year 2018, where the use of DEM and LiDAR in their approach are evaluated and their advantages and limitations are discussed [21][47]. The research was conducted by using monocular vision SLAM and a point cloud map to identify the UAV and split the grid into different heights to locate a safe landing zone. After denoising and filtering the map using a mid-pass filter and 3D attributes, the landing process lasted 52 s, starting at a height of 20 m. The experimental validation was conducted in challenging environments, demonstrating the system’s adaptability. In order to fulfill the demands of a self-governing landing, the sparse point cloud was partitioned based on different elevations. Furthermore, Lin et al. [22][48] deliberated landing scenarios in low illumination settings.
To account for the constantly changing terrain in complex landing areas, it is advisable to identify multiple suitable landing sites to ensure the safety of the UAV. Once landing coordinates have been identified, the optimal landing spot and approach path should be determined. Cui, et al. [23][49] proposed a way that calculates the landing area’s criteria based on energy consumption, the safety of the terrain, and the craft’s performance. A clearer comprehension of landing point selection is provided in Figure 3, which displays the identification of two landing targets—Target A and Target B—along with the corresponding trajectories to reach them. It is advisable to determine the shortest trajectory to the alternative target in the event of a last-minute change.
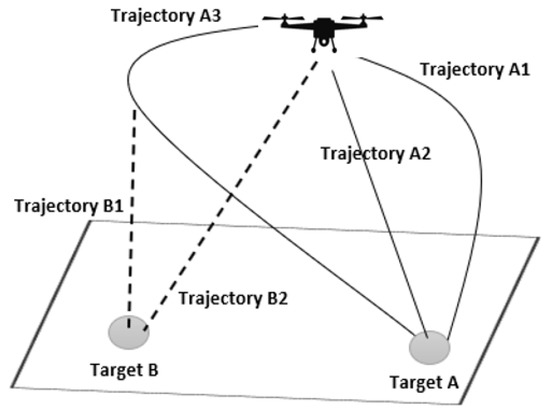
Figure 3. Landing Spot and Trajectory Selection.
3. Landing on Extra-Terrestrial Bodies
For the above-said problem, rwesearchers can also consider adopting the landing approach utilized by spacecraft on other extra-terrestrial bodies [24][50]. Precise Landing and Hazard Avoidance (PL&HA) [25][26][27][28][29][30][51,52,53,54,55,56] and the Safe and Precise Landing Integrated Capabilities Evolution (SPLICE) are two projects that NASA has been working on [31][57]. Moreover, NASA is working on a project called ALHAT, which stands for Autonomous Landing Hazard Avoidance Technology [32][33][34][35][36][37][38][39][40][41][42][58,59,60,61,62,63,64,65,66,67,68]. However, a significant limitation of ALHAT is that it relies solely on static information such as slopes and roughness to select a landing area, making the maneuvering of the craft more challenging. S.R. Ploen et al. [43][69] proposed an algorithm that uses Bayesian networks to calculate approximate landing footprints and make it feasible. Researchers are currently working on similar aspects. In that case, the classical method of object classification can be employed to simplify the process of identifying objects in space. However, prior to delving into object classification, it is essential to determine the angle and pose of the spacecraft for greater accuracy.
3.1. Pose Estimation Techniques
Determining the spacecraft’s pose requires an estimation based on the camera’s angle with respect to the ground view. Deep learning models are mainly used for pose estimation. The previously available pose estimation techniques are studied by Uma et al. [44][70], which has been summarized as follows.
In their respective studies, Sharma et al. (2018) [45][71], Harvard et al. (2020) [46][72], and Proencca et al. (2020) [47][73] employed different techniques to analyze the PRISMA dataset. Sharma et al. [45][71] utilized the Sobel operator, the Hough transform, and a WGW approach to detect features of the target, regardless of their size. On the other hand, Harvard et al. [46][72] utilized landmark locations as key point detectors to address the challenge of high relative dynamics between the object and the camera. They also employed the 2010 ImageNet ILSVRC dataset in their approach. A deep learning framework that utilizes soft classification and orientation and outperformed straightforward regression is presented by Proencca et al. [47][73]. The Dataset used in the study was the URSO, an Unreal Engine 4 simulator. According to Sharma et al. (2018) [48][74], their approach demonstrated higher feature identification accuracy compared to traditional methods, even when dealing with high levels of Gaussian white noise in the images. The SA-LMPE method used by Chen et al. [49][75] improves posture refinement and removes erroneous predictions, while the HRNet model correctly predicted two-dimensional landmarks, using the SPEED Dataset. Zeng et al. (2017) [50][76] utilized deep learning methods to identify and efficiently represent significant features from a simulated space target dataset generated by the Systems Tool Kit (STK). Wu et al. (2019) [51][77] used a T-SCNN model trained on images from a public database to successfully identify and detect space targets in deep space photos. Finally, Tao et al. (2018) [52][78] used a DCNN model trained on the Apollo spacecraft simulation Dataset from TERRIER, which showed resistance to variations in brightness, rotation, and reflections, as well as efficacy in learning and detecting high-level characteristics.
3.2. Object Classification
The objects of interest in this scenario are craters and boulders found on a particular extraterrestrial body. A crater is a concave structure that typically forms as a result of a meteoroid, asteroid, or comet’s impact on a planet or moon’s surface. Craters can vary greatly in size, ranging from small to very large. Conversely, a boulder is a large rock that usually has a diameter exceeding 25 cm. The emergence of boulders on the surfaces of planets, moons, and asteroids can be attributed to several factors including impact events, volcanic activity, and erosion.
3.2.1. Deep-Learning Approach
Once the spacecraft’s pose has been determined, the objective is to land the spacecraft safely by avoiding craters and boulders. To achieve this objective, several algorithms have been developed. Li et al. (2021) [53][8] suggest a novel approach to detect and classify planetary craters using deep learning. The approach involves three main steps: extracting candidate regions, detecting edges, and recognizing craters. The first stage of the proposed method involves extracting candidate regions that are likely to contain craters, which is done using a structure random forest algorithm. In the second stage: the edge detection stage, the edges of craters are extracted from the candidate regions through the application of morphological techniques. Lastly, in the recognition stage, the extracted features are classified as craters or non-craters using a deep learning model based on the AlexNet architecture. Wang, Song et al. [54][9] propose a new architecture called “ERU-Net” (Effective Residual U-Net) for lunar crater recognition. ERU-Net is an improvement over the standard U-Net architecture, which is commonly used in image segmentation tasks. The ERU-Net architecture employs residual connections between its encoder and decoder blocks, along with an attention mechanism that aids the network in prioritizing significant features while being trained.
3.2.2. Supervised Learning Approach
Supervised detection approaches utilize machine learning techniques and a labeled training dataset in the relevant domain to create classifiers, such as neural networks (Li & Hsu, 2020) [55][79], support vector machines (Kang et al., 2019) [56][22], and the AdaBoost method (Xin et al., 2017) [57][23]. Kang et al. (2018) [56][22] presented a method for automatically detecting small-scale impact craters from charge-coupled device (CCD) images using a coarse-to-fine resolution approach. The proposed method involves two stages. Firstly, large-scale craters are extracted as samples from Chang’E-1 images with a spatial resolution of 120 m. Then, the histogram of oriented gradient (HOG) features and a support vector machine (SVM) classifier are used to establish the criteria for distinguishing craters and non-craters. Finally, the established criteria are used to extract small-scale craters from higher-resolution Chang’E-2 CCD images with spatial resolutions of 1.4 m, 7 m, and 50 m. Apart from that Xin et al. [57][23] propose an automated approach to identify fresh impact sites on the Martian surface using images captured by the High-Resolution Imaging Science Experiment (HiRISE) camera aboard the Mars Reconnaissance Orbiter. The method being proposed comprises three primary stages: the pre-processing of the HiRISE images, the detection of potential impact sites, and the validation of the detected sites using the AdaBoost method. The potential impact sites are detected using a machine-learning-based approach that uses multiple features, such as intensity, texture, and shape information. The validation of the detected sites is done by comparing them with a database of known impact sites on Mars.
An automated approach for detecting small craters with diameters less than 1 km on planetary surfaces using high-resolution images is presented by Urbach and Stepinski [58][24]. The three primary stages of the suggested technique include pre-processing, candidate selection, and crater recognition, with the pre-processing stage transforming the input image to improve features and minimize noise. In the candidate selection step, a Gaussian filter and adaptive thresholding are used to detect potential crater candidates. In the crater recognition step, a shape-based method is employed to differentiate between craters and non-craters. It is shown that the suggested technique works well for finding tiny craters on the Moon and Mars.
3.2.3. Unsupervised Learning Approach
The unsupervised detection approach utilizes image processing and target identification theories to identify craters by estimating their boundaries based on the circular or elliptical properties of the image [59][80]. The Hough transform and its improved algorithms (Emami et al., 2019) [60][17], the genetic algorithm (Hong et al., 2012) [61][18], the radial consistency approach (Earl et al., 2005) [62][19], and the template matching method (Cadogan, 2020; Lee et al., 2020) [63][20] are among the common techniques utilized for this method. The morphological image processing-based approach for identifying craters involves three primary steps: firstly, the morphological method is used to identify candidate regions, followed by the removal of noise to pinpoint potential crater areas; secondly, fast Fourier transform-based template matching is used to establish the association between candidate regions and templates; and finally, a probability analysis is utilized to identify the crater areas [64][21]. The advantage of the unsupervised approach is that it can train an accurate classifier without requiring the labeling of a sizable number of samples. This strategy can be used when an autonomous navigation system’s processing power is constrained. Nevertheless, it struggles to recognize challenging terrain.
3.2.4. Combined Learning Approach
To detect craters, a combined detection methodology employs both unsupervised and supervised detection methods. For example, consider the KLT detector, which is a combination detection technique, to extract probable crater regions [65][25]. In this approach, supervised detection methodology was used, and image blocks were used as inputs, while the detection accuracy was significantly influenced by the KLT detector’s parameters. Li and Hsu’s (2020) [66][26] study employed template matching and neural networks for crater identification. However, this approach has the drawback of being unable to significantly decrease the number of craters in rocky areas, leading to weak crater recognition in mountainous regions. Li et al. [53][8] propose a three-stage approach for combined crater detection and recognition. In the first stage, a structured random forest algorithm is utilized for extracting the crater edges. The second stage involves candidate area determination through edge detection techniques based on morphological methods. The third stage involves the recognition of candidate regions using the AlexNet deep learning model. Experimental results demonstrate that the recommended crater edge detection technique outperforms other edge detection methods. Additionally, the proposed approach shows relatively high detection accuracy and accurate detection rate when compared to other crater detection approaches.