Reliable functionality in anomaly detection in thermal image datasets is crucial for defect detection of industrial products. Nevertheless, achieving reliable functionality is challenging, especially when datasets are image sequences captured during equipment runtime with a smooth transition from healthy to defective images. This causes contamination of healthy training data with defective samples. Anomaly detection methods based on autoencoders are susceptible to a slight violation of a clean training dataset and lead to challenging threshold determination for sample classification. This paper indicates that combining anomaly scores leads to better threshold determination that effectively separates healthy and defective data. Our research results show that our approach helps to overcome these challenges. The autoencoder models in our research are trained with healthy images optimizing two loss functions: mean squared error (MSE) and structural similarity index measure (SSIM). Anomaly score outputs are used for classification. Three anomaly scores are applied: MSE, SSIM, and kernel density estimation (KDE). The proposed method is trained and tested on the 32 × 32-sized thermal images, including one contaminated dataset. The model achieved the following average accuracies across the datasets: MSE, 95.33%; SSIM, 88.37%; and KDE, 92.81%. Using a combination of anomaly scores could assist in solving a low classification accuracy. The use of KDE improves performance when healthy training data are contaminated. The MSE+ and SSIM+ methods, as well as two parameters to control quantitative anomaly localization using SSIM, are introduced.
- anomaly detection
- deep learning
- novelty detection
- autoencoder
- industrial image
1. Introduction
2. Methodology
After the characteristics of the datasets and used data pipeline are introduced, the research method is discussed in detail. The approach consists of two phases. First, the proposed autoencoder models are developed and trained in the training phase. Then, in the test phase, anomaly score outputs are used for classification performance analyses.
2.1. Dataset and Pipeline
To evaluate theour anomaly detection approaches, researcherswe used 32 × 32-sized thermal images of switchgear equipment. The images were captured using four infrared cameras monitoring low-voltage switchgear busbar cable connections . The cameras recorded a healthy baseline for a period of time; then, several faults were introduced to the switchgear. The faults were simply different loose cable connections that create notable intense hotspots on the thermal images.-
In the training phase, a model was trained with 𝑋𝑡𝑟𝑎𝑖𝑛with its respective loss functions.
-
In the test phase, the anomaly score distributions for 𝑋𝑡𝑟𝑎𝑖𝑛 and 𝑋𝑑𝑒𝑓𝑒𝑐𝑡−𝑡𝑒𝑠𝑡 were visualized and the threshold for classification was determined 𝑇ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑=𝑚𝑎𝑥(𝐴(𝑋𝑡𝑟𝑎𝑖𝑛)).
-
𝑋ℎ𝑒𝑎𝑙𝑡ℎ𝑦−𝑐𝑙𝑎𝑠𝑠 and 𝑋𝑑𝑒𝑓𝑒𝑐𝑡−𝑐𝑙𝑎𝑠𝑠 were combined and used for supervised classification using the data labels 𝑦ℎ𝑒𝑎𝑙𝑡ℎ𝑦−𝑐𝑙𝑎𝑠 and 𝑦𝑑𝑒𝑓𝑒𝑐𝑡−𝑐𝑙𝑎𝑠𝑠.
-
The classification performance measures with 𝑇ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑=𝑚𝑎𝑥(𝐴(𝑋𝑡𝑟𝑎𝑖𝑛)) were calculated.
-
The false-positive rate and the true-positive rate for 30 thresholds were determined; a receiver operating characteristic (ROC) curve was drawn; and accordingly, the area under the curve (AUC) was calculated.
-
Result tables were prepared with the performance measures, ROC, and the AUC results.
-
A visualization of the healthy and defective samples was created, along with residual maps for quantitative analysis.
3. Results
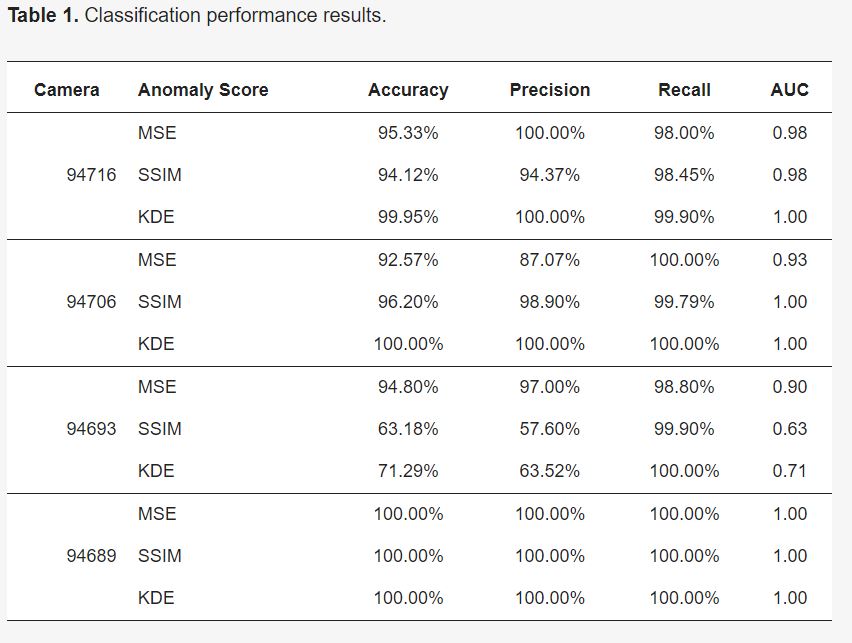
Table 1 presents the classification performance results based on the determined T on the anomaly scores generated using the autoencoder. The classification measures indicate high performances in all the datasets, except the contaminated dataset (camera 94693). This high accuracy is due to the nature of thermal images and can be reduced depending on the texture of the input images. Nevertheless, the SSIM outperforms the MSE anomaly score in all cases.
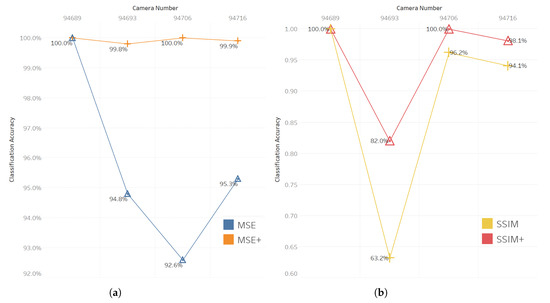
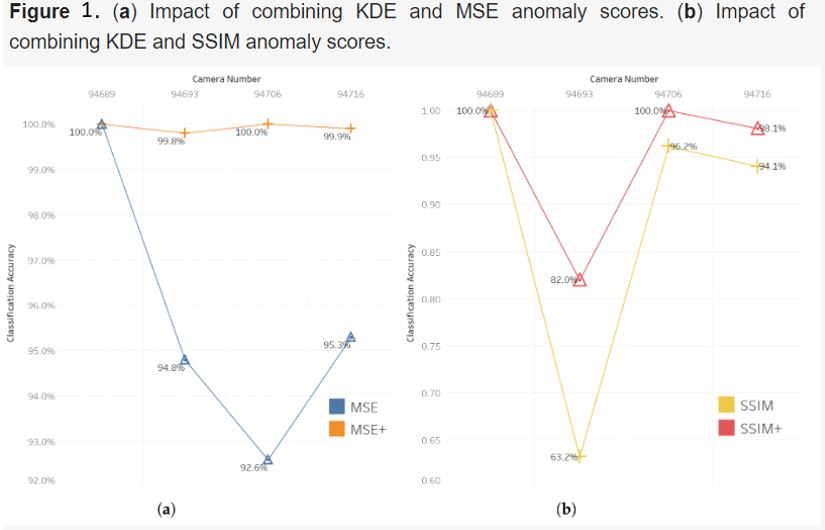
 For performance improvement, rwesearchers c combined the MSE and SSIM thresholds with KDE thresholds MSE+ and SSIM+. To conduct a comparative analysis, researchers cwe compared the results of MSE and SSIM as the baseline approaches and further evaluated the enhanced performance achieved using the MSE+ and SSIM+ thresholds. Figure 1 displays the amount of improvement in accuracy.
For performance improvement, rwesearchers c combined the MSE and SSIM thresholds with KDE thresholds MSE+ and SSIM+. To conduct a comparative analysis, researchers cwe compared the results of MSE and SSIM as the baseline approaches and further evaluated the enhanced performance achieved using the MSE+ and SSIM+ thresholds. Figure 1 displays the amount of improvement in accuracy.