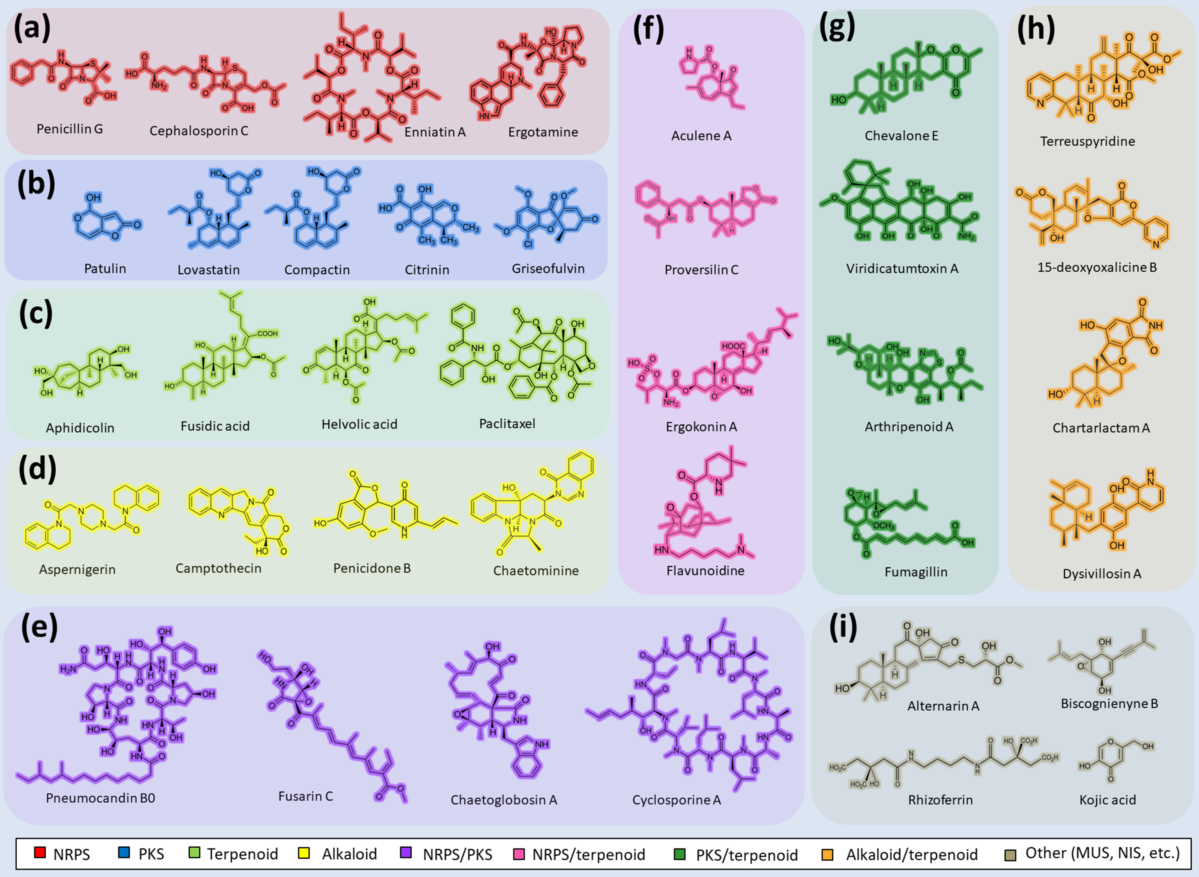
2. Main Types of Fungal Secondary Metabolites
Fungi are one of the most evolutionarily adapted organisms, which has allowed them to occupy the majority of ecological niches suitable for existence on Earth over the past billion years
[52][53][60,61]. According to existing estimates, global fungal diversity is about an order of magnitude greater than that of land plants
[54][55][62,63]. One of the paramount assistants to such adaptive expansion was the ability to produce wide-variable low-molecular compounds, the so-called secondary metabolites, in response to changes in the state of both the organism itself and the environment
[56][57][58][64,65,66]. These highly active molecules have begun to play a trigger function, and are selected as keys to the locks of various processes in the development of the organism itself, and its defense and/or attack against surrounding organisms and other species via within- and between-species interaction. More than 15,000 biologically active SMs are currently known to be produced by fungi (which is approximately 50% of all known biologically active SMs from microorganisms), some of which are used in pharmaceutical, agrochemical, and cosmetic products
[59][52]. The majority of these compounds belong to one of four classes obtained through the activity of: (i) nonribosomal peptide synthetase (NRPS), (ii) polyketide synthase (PKS), (iii) terpene cyclase (TC) for terpenoid production, or (iv) a number of enzymes for alkaloid production (
Figure 1).
Figure 1. Chemical structures of the main types of secondary metabolites (SMs) produced by filamentous fungi, based on the enzymatic activity of: (a) nonribosomal peptide synthetase (NRPS); (b) polyketide synthase (PKS); (c) terpene cyclase (TPC) for terpenoid production; (d) a number of enzymes for alkaloid production; (e) NRPS and PKS for production of NRPS/PKS hybrid; (f) NRPS and TPC for production of NRPS/terpenoid; (g) PKS and TPC for production of PKS/terpenoid; (h) enzymes for alkaloid production and TPC for production of alkaloid/terpenoid; (i) other enzymes for production meroterpenoid with unique structures (MUS), or NRPS-independent siderophore (NIS), or other types of molecules.
There are also a number of hybrid variants of fungal SMs, which are obtained due to combinations of the main four biosynthetic strategies, for example, the NRPS/PKS hybrid, or meroterpenoids, such as NRPS/terpenoid, PKS/terpenoid, and alkaloid/terpenoid
[60][67]. Finally, SMs of fungi are known that do not belong to any of the four major types, or their hybrid derivatives, for example, the NRPS-independent siderophore (NIS)
[61][68].
Typically, the molar mass of fungal SMs ranges from 140 to 1200 or more, with the vast majority ranging from 250 to 600. Perhaps it is precisely these molecular sizes that make it possible to create, on the one hand, a huge variety of chemical structures (based, for the most part, on the atoms of H, C, O, N, P, and S), which, on the other hand, can serve as small keys to the locks of macromolecular structures. These keys are uniquely sharpened for a specific task, for opening a particular lock, which must be unlocked at a strictly specific moment.
3. Biosynthesis of Fungal Secondary Metabolites in Response to Signals
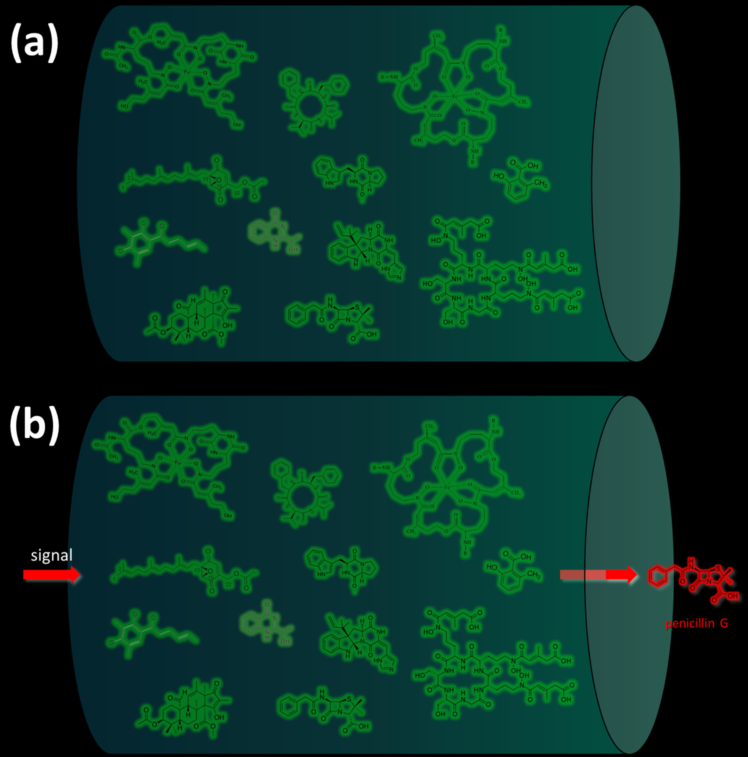
In most cases, under normal physiological conditions during the trophophase, fungal SMs are not synthesized (
Figure 2a)
[35]. However, under the influence of certain internal or external signals, cellular mechanisms are triggered, leading to the synthesis of one corresponding (target) SM or another (
Figure 2b)
[1][15][62][1,15,134].
Figure 2. Biosynthesis of secondary metabolites (SMs) in response to signal exposure. The arrival of a specific signal (from the external environment or the internal signal of the cell) leads to the production of corresponding SMs. As an example, changes in the production of SMs in Penicillium chrysogenum are given: (a) Under normal physiological conditions (in the absence of specific environmental signals) and at an early stage of fungal cell development (trophophase stage), most SMs are not produced. (b) In response to a specific signal, the corresponding SM is synthesized. The green color shows known SMs of P. chrysogenum, which, in principle, can be synthesized by the cell (representing its biosynthetic capacity), but are not produced at a particular moment. The red color shows the currently produced SMs in response to the signal; the antibiotic penicillin G, synthesized in response to an external signal, is given as an example.
Low-molecular-weight compounds, including SMs, are one of the main methods of communication between microorganisms
[63][64][65][135,136,137]. If a civilized person uses several thousand words for everyday communication, then microorganisms “speak” the language of several hundred low-molecular-weight compounds
[66][67][138,139]. Thus, in the composition of the microbiome, individual species can “carry on new conversations”, producing SMs that are not detected in the composition of a monoculture
[68][140].
The SMs of microorganisms play a significant ecological role
[36][69][36,141]. They can be used as weapons and armor in cases of a confrontation between microorganisms
[70][142]. On the other hand, the SMs of fungi can serve as important agents at the stages of infection in plant and animal cells
[71][72][73][74][75][76][143,144,145,146,147,148]. Furthermore, fungal SMs can serve as communication molecules
[77][78][79][149,150,151], playing a significant role in the fungal “communicome”
[80][81][152,153]. Fungi use other low-molecular-weight molecules than bacteria for quorum sensing, such as tyrosol, farnesol, and butyrolactone-I
[77][82][149,154]. Along with this, fungal SMs can inhibit the quorum sensing systems of competing microorganisms
[77][83][149,155].
In response to low levels of iron in the environment, fungi synthesize siderophores, special compounds with a high affinity for iron ions
[84][156]. They are secreted into the external environment to chelate trace amounts of iron; the resulting complexes of siderophores with iron have an increased affinity for special cellular receptors, as a result of which the necessary iron enters the cell
[85][157]. The synthesis of siderophores is also important in the pathogenesis of a number of fungi
[75][147].
Fungal SMs are capable of manipulating plant community (plant microbiome) dynamics by inhibiting or facilitating the establishment of co-habituating organisms and mediating fungal–bacterial, fungal–fungal, and fungal–animal interactions associated with the plant community
[86][158]. The production of SMs in fungi is influenced by environmental factors; for example, their production in fungi that have lived for hundreds and thousands of years in lichens is affected by light, UV radiation, altitude, temperature fluctuations, and seasonality
[87][159].
4. Biosynthetic Gene Clusters (BGCs) for the Production of Fungal Secondary Metabolites
One of the revolutionary discoveries in understanding the molecular basis of the biosynthesis of SMs was the identification of so-called biosynthetic gene clusters (BGCs)
[88][89][90][91][160,161,162,163]. It turned out that in order to create a particular natural product, microorganisms and plants have an appropriate set of genes that are in relative proximity in a particular region of the chromosome (clustered) and are jointly regulated
[92][164]. Thus, the genes responsible for the stages of biosynthesis of a particular SM are either “silent” together or jointly upregulated
[26]. The architecture of metabolism itself leads to the maximization of biosynthetic diversity in fungi
[93][165]. For example, a number of BGCs have biased ecological distributions, consistent with niche-specific selection
[93][165]. Several thousand BGCs are currently known in fungi; it is assumed that their numbers range from 100,000 to millions
[1][88][94][1,160,166].
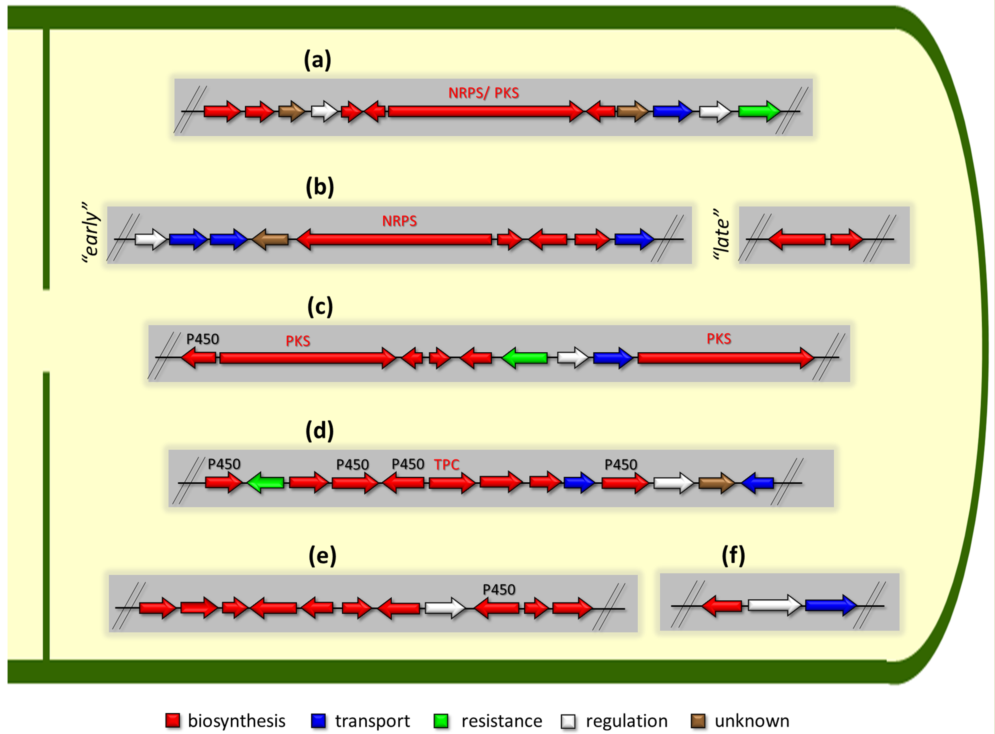
There are several main types of BGC organization responsible for the biosynthesis of the corresponding types of SMs in fungi (
Figure 1 and
Figure 3). In most cases, BGCs contain: (i) one or more genes for backbone, or core, enzymes (synthase or synthetase) responsible for the production of the core structure of SMs, and (ii) a number of genes that encode tailoring enzymes for modifying the core compound to obtain a variety of products
[1]. The type of core enzyme (or combination thereof) determines the type of secondary metabolite. The BGC can also assemble genes encoding: (iii) transporters, (iv) proteins that mitigate toxic properties, (v) pathway-specific transcription factors, and (vi) genes with as-yet unknown function (
Figure 3)
[95][167].
Figure 3. Some examples of the organization of biosynthetic gene clusters (BGCs) for the production of secondary metabolites (SMs) in fungi. (a) BGCs for production of SMs based on so-called “central” gene, which encodes one type of megasynthase or another: (i) NRPS (nonribosomal peptide synthetase), (ii) PKS (polyketide synthase), or (iii) NRPS-PKS hybrid. (b) “Early” and “late” BGCs for production of cephalosporin C in Acremonium chrysogenum. (c) BGCs for production of lovastatin in Aspergillus terreus: P450—cytochrome P450. (d) BGCs for production of terpenoid SM: TPC—terpene cyclase. (e) BGCs for production of meroterpenoid with unique structure. BGC for production of biscognienyne B is given as an example. (f) BGC for production of kojic acid in Aspergillus oryzae. Gene loci for enzymes of the biosynthetic pathways of the SMs are colored in red; gene loci for protein transporters of biosynthetic products are colored in blue; gene locus for protecting the microorganism from the produced secondary metabolite is colored in green; gene locus for the specific regulator of this biosynthetic pathway is colored in white; locus for gene with unknown function is colored in brown. Genes for backbone enzymes (NRPS, PKS, and TPC) responsible for the production of the core structure of SMs are colored in red.
4.1. BGCs with Backbone (or Core) Genes for Megasynthases NRPS or PKS
To create two among the four main types of secondary metabolites, fungi use megasynthases, large modular enzymes such as NRPS, nonribosomal peptide synthetase
[96][170], or PKS (polyketide synthase)
[97][171] (
Figure 1a,b and
Figure 3a). In these modular enzymes, catalytic domains with a number of functions, required for the polymerization of (i) amino acids, including non-proteinogenic acids (in the case of NRPS), or (ii) acyl groups, from acetyl-CoA to malonyl-CoA (in the case of PKS), are assembled into one huge polypeptide chain
[98][99][172,173]. As a result, individual megasynthases are responsible for 10–50 or more catalytic activities
[15]. In a number of bacteria (~10% of cases), polymerization units do not have a modular organization, and catalytic domains are mainly encoded by individual proteins
[100][174]. It is thought that such non-modular polymerization systems for the production of SMs in bacteria served as a prototype for the development of the modular megasynthases NRPS and PKS
[100][174].
Each module of NRPS is a functional building block responsible for incorporating and modifying a single amino acid unit, which can be either canonical proteinogenic (i.e., used in ribosomal synthesis) or non-canonical non-proteinogenic (i.e., never used in ribosomal synthesis)
[101][102][175,176]. A typical NRPS module consists of: (i) the adenylation (A) domain, for amino acid recognition and activation; (ii) the peptidyl carrier protein (PCP) domain, for transferring an activated amino acid from the A-domain to its cofactor, 4′-phosphopantetheine; and (iii) the condensation (C) domain, to catalyze peptide bond formation
[103][177]. Along with this, the module may contain a set of optional domains with catalytic functions of methyltransferase (MT), β-ketoacyl reductase (KR), epimerase (E), etc.
[104][178]. Specificity of the recognition of one amino acid or another is achieved due to the substrate-binding center of the adenylation domain of the corresponding module
[105][106][179,180]. In this regard, the term “nonribosomal” code was introduced, referring to the correspondence of 10 amino acid residues in the substrate binding site of the adenylation domain of a particular NRPS module with a specific proteinogenic or non-proteinogenic amino acid
[107][108][181,182]. More than 500 non-proteinogenic amino acids have now been found in fungi, many of which are used for non-ribosomal peptide synthesis
[109][110][183,184]. In addition, for the biosynthesis of a number of non-proteinogenic amino acids themselves, an additional BGC is required
[111][185]. Adding such a significant number of “building block” types to the canonical 20 proteinogenic amino acids (the number of which is strictly limited by genetic coding and the rigidly fixed roles of tRNA and aminoacyl-tRNA synthetizes) makes it possible to drastically expand the range of created low-molecular-weight structures
[109][183]. Fundamentally new structures emerging as a result of the use of new building materials on the NRPS platform provide an advantage to the organisms that produce them, and can also be applied to obtain medically significant natural products
[112][113][114][186,187,188].
PKS can have, as in the case of NRPS, a complex multi-module structure (type I noniterative PKS) where a single module from a huge enzyme with multiple modules is used to attach the next building block
[115][116][189,190]. Such enzymes function as a modular linear conveyor line, in which each active site is used only once
[117][191]. However, in fungi, the most common PKS is the iterative type (type I iterative PKS and type II PKS), which, instead of one large megaenzyme, consists of only one module that reuses necessary catalytic domains in a cyclic fashion
[118][192]. After attaching a building block, the polymerization product is transferred to the beginning of the module to attach the next building block, and so on
[119][193]. Such enzymes function as an iterative assembly line in which each active site of the core domains is used as many times as needed to attach the building blocks
[120][194].
Typically, a single PKS module contains three core (minimal) domains: (i) the acyl transferase (AT) domain selects the building blocks to add to the product and transfers them to (ii) the acyl transfer protein (ACP) domain, which loads them for the polymerization product, and (iii) the ketoacyl synthase (KS) domain, which is required for the decarboxylation condensation of the extendable unit (usually malonyl-CoA or methylmalonyl-CoA) with the acyl thioether
[121][195]. There is also iterative AT-less and ACP-less type III PKS in fungi, which is a homodimer with a molecular weight of about 40 kDa and combines all the activities from the essential type I and II PKS domains
[122][196]. Along with minimal domains, the module may contain a set of optional (or tailoring) domains with catalytic functions of thioesterase (TE), methyltransferase (MT), dehydratase (DH), enoyl reductase (ER), β-ketoacyl reductase (KR), etc.
[121][195]. Depending on the presence and number of reducing domains in PKS, they are subdivided into: (i) NR-PKS—non-reducing PKS, the products of which are true polyketides; (ii) PR-PKS—partially contracting PKS; and (iii) FR-PKS—fully reducing PKS, the products of which are fatty acid derivatives. As a result of this diversity of intramodular organization, PKS, along with NRPS, produce an enormously diverse array of natural products in fungi
[123][197].
There are also known cases when more than one corresponding megasynthase is used for the production of NRPS-driven (
Figure 1a) or PKS-driven (
Figure 1b) secondary metabolites by fungi. For example, two PKSs are used during lovastatin biosynthesis, one of which, LovB nonaketide synthase (EC:2.3.1.161), uses nine building blocks based on acetyl-CoA or manoyl-CoA, and the other, LovF diketide synthase (2-methylbutanoate polyketide synthase; EC: 2.3.1.244), uses two such building blocks
[124][198]. Accordingly, the lovastatin BGC encodes two PKS genes (
Figure 3c). There are also numerous examples of BGCs in fungi encoding both NRPS and PKS.
4.2. BGCs with Backbone (or Core) Gene for Terpene Cyclase
Terpene cyclase (TPC) is used as the core enzyme for the biosynthesis of the third among the four major types of fungal secondary metabolites, terpenoids (
Figure 1c and
Figure 3d)
[125][199]. In most cases, TPC clusters in the same BGC as its downstream modification enzymes (
Figure 3d)
[126][200].
TPCs form the hydrocarbon backbones of terpenoids, which are then modified by tailoring enzymes to produce final natural products
[127][201]. Depending on the initial generation of the carbocation, class I TPK and class II TPK are distinguished
[128][202]. TPC is a catalytic complex that produces cyclic terpenoids from their linear precursors
[129][203]. Terpenoid cyclization reactions are one of the most complex reactions found in nature
[130][204]. Due to the functional diversity of terpene cyclases, various types of cyclic terpenoids are formed from linear precursors, which, in turn, undergo various modifications. Currently, over 80,000 terpenoids are known, which represent about a third of the described natural products
[131][205]. In most cases, the gene for TPC clusters in the same BGC as the genes for its downstream modification enzymes
[126][200]. However, there are a number of examples, such as lanosterol-derived triterpenes/steroids, where the TPC gene is outside the gene cluster for its downstream modification enzymes
[132][206].
4.3. Hybrid BGCs with Genes for Different Backbone Enzymes
In addition to biosynthetic clusters encoding only one type of core enzyme, which leads, respectively, to the production of secondary metabolites of the NRPS type, PKS type, or TPC type (
Figure 1b–d), there are mixed-type BGCs that contain genes for different types of core enzymes
[88][160]. There are also BGCs with hybrid core genes, for example, for the production of NRPS/PKS hybrids, part of the gene may encode NRPS modules and the other part PKS modules
[101][175]. In such cases, specific interpolypeptide linkers exist at both the C- and N-termini of the NRPS and PKS proteins, which play a critical role in facilitating the transfer of the growing peptide or polyketide intermediate between NRPS and PKS modules in hybrid NRPS-PKS systems
[88][160].
Among the four basic types of SMs in fungi (NRPS, PKS, terpenes, and alkaloids), there are numerous chimeric variants. As a result, the production of such mixed (or hybrid) fungal BGCs results in chimeric secondary metabolites such as NRPS/PKS, NRPS/terpenoid, PKS/terpenoid, or alkaloid/terpenoid hybrids (
Figure 1e–h)
[60][88][133][67,160,207]. Some (but not all) alkaloids also use core enzymes for their construction
[134][135][208,209]; for example, ergot alkaloids use NRPS
[136][137][210,211]. In rare cases, secondary metabolites in fungi result from crosstalk between two separate BGCs
[138][212]. Such an interaction not only increases the structural diversity but also significantly expands the activity spectrum of the produced cross-cluster compounds
[138][212]. NRPS-PKS hybrids (
Figure 1e) are among the most common in nature
[139][102]. Such compounds benefit from the combinatorics of products resulting from NRPS and PKS synthesis
[101][175]. It has been shown that more than a third of the clusters encoding megasynthases carry NRPS-PKS hybrids
[100][174].
4.4. BGCs without Genes for Canonical Backbone Enzymes (“Wild BGCs”)
In addition to the main types of SMs, in the production of which relatively easily identifiable genes of core and tailoring enzymes are involved (
Figure 1a–h), fungi also produce highly active low-molecular-weight compounds that do not have characteristic elements for their “barcoding” (
Figure 1i)
[140][213]. BGCs for the production of such SMs do not contain genes encoding canonical “backbone” synthases/synthetases (e.g., NRPS, PKS, TPC); for example, clusters for the production of clavine alkaloids
[141][214], isocyanides
[142][215], NRPS-independent siderophores (NIS)
[143][127], and other
[144][133].
BGCs for the production of clavine alkaloids do not contain NRPS
[141][214], unlike ergot alkaloids, with four genes encoding NRPS
[145][216]. Isocyanides (also called isonitriles) have notable bioactivities that mediate pathogenesis, microbial competition, and metal homeostasis through metal-associated chemistry
[142][215]. For isocyanide production, fungi use non-canonical BGCs (containing the non-canonical core enzyme isocyanide synthase, ICS), which are not detected by standard genome-mining algorithms
[146][217]. However, a targeted bioinformatics study of 3300 fungal genomes allowed 3800 ICS BGCs to be characterized
[140][213]. Hydroxamic siderophores also use NRPS, but recently, an NRPS-independent siderophore (NIS) synthetase pathway has been established for the production of NRPS-independent siderophores
[147][116]. Five functional types of NIS enzymes are classified; all such clusters also lack the core canonical gene
[148][57]. The BGC for kojic acid production does not contain genes encoding both core enzymes and characteristic tailoring enzymes (
Figure 3f)
[144][133]. The lack of conserved signature sequences makes such BGCs almost impossible to detect as a result of genomic mining using current bioinformatic approaches
[149][218]. The only way to detect such clusters is through an experimental approach. For example, the BGC of kojic acid in
Aspergillus oryzae was identified as a result of a reverse genetic method combined with a DNA microarray technique
[144][133].
Currently, most of
theour knowledge about BGCs is formed in silico
[150][219]. As a result of the application of bioinformatics technologies, tens of thousands of BGCs have been found in fungal genomes, for most of which the products are still unknown
[88][160]. Along with this, for all secondary metabolites from bacteria, fungi, and plants, fewer than two thousand corresponding BGCs have been experimentally characterized
[151][152][220,221]. As a result,
theour knowledge of “wild” clusters (without characteristic core and tailoring enzymes) is much narrower than that of BGCs containing these elements.
There are also “canonical” BGCs without genes for core enzymes. This is due to the fact that genes encoding canonical core enzymes for such clusters are localized outside the cluster, in the other part of the genome. For example, the “late” beta-lactam BGC contains only genes for tailoring enzymes (CefEF and CefG), while the core enzyme for this biosynthetic pathway clusters in the “early” beta-lactam BGC, which is located on a different chromosome (
Figure 3b)
[153][154][222,223].
4.5. Tailoring Enzymes (Enzymes for Modifying the Core Structure)
The final products of biosynthetic secondary metabolism pathways are often significantly modified as a result of enzymatic activities such as heterocyclization, epimerization, oxidative hydroxylation, methylation, oxidative crosslinking, the addition of sugars, translocation, and other modifications
[155][224]. Some tailoring enzymes assemble as optional domains within megasynthase modules; other tailoring enzymes act in trans during megasynthase work, recognizing the modules required by protein–protein interactions
[155][224]. For example, the trans-acting polyketide enoyl reductase LovC (lovastatin enoyl reductase; EC: 2.3.1.161) specifically reduces three out of eight polyketide intermediates (triketides, tetraketides, and hexaketides) during nonaketide synthase LovB activity in lovastatin biosynthesis
[124][198]. As a result of such cis- and trans-activities, the core polymerization product may contain, after the release, a significant number of modifications. The release of the core scaffold process itself is quite complex; it can proceed using various mechanisms
[156][225], the implementation of which may also require special enzymes encoded in the corresponding BGC. For example, in the biosynthesis of lovastatin, thioester hydrolases LovG (dihydromonacolin L-[lovastatin nonaketide synthase] thioesterase; EC: 3.1.2.31) is required to release from nonaketide synthase LovB its final product, dihydromonacolin L
[157][226]. After the backbone, or core, enzymes create a core scaffold (with cis- and possibly trans-modifications), a third group of tailoring enzymes transform its structure, resulting in a variety of end products. Thus, in addition to the genes for core enzymes, BGCs contain genes for various biosynthetic enzymes, trans-acting with core enzymes, helping to release or modify the released core products (
Figure 3).
For example, in
A. chrysogenum, after NRPS, which is called PcbAB or ACV (δ-[L-α-Aminoadipoyl]-L-Cysteinyl-D-Valine) synthetase (EC: 6.3.2.26), polymerizes the LLD-ACV tripeptide δ-(L-α-aminoadipoyl)-L-cysteinyl-D-valine, a series of enzymatic reactions occur, catalyzed by enzymes from beta-lactam BGCs, resulting in the production of cephalosporin C (CPC). First, PcbC (isopenicillin N-synthase (EC: 1.21.3.1)), as a result of a dioxygenase reaction, cyclizes this tripeptide to isopenicillin N (IPN); then, cefD1 (isopenicillin N-CoA synthetase (EC: 5.1.1.17)), and cefD2 (isopenicillin N-CoA epimerase (EC: 5.1.1.17)) catalyze reactions leading to the epimerization of IPN to penicillin N (penN); finally, enzymes of the “late” beta-lactam BGC, CefEF (deacetoxycephalosporin C synthetase (penicillin N expandase, EC: 1.14.20.1)/deacetoxycephalosporin C hydroxylase (EC: 1.14.11.26)), and CefG (deacetylcephalosporin-C acetyltransferase (EC: 2.3. 1.175)), carry out reactions leading to the formation of CPC
[158][159][160][168,227,228].
A distinctive feature of BGC in terpenoid biosynthesis is the presence among the genes for tailoring enzymes of a significant number of genes for cytochrome P450 mono-oxygenases (CYP450), NAD(P)+, and flavin-dependent oxidoreductases that generate the final bioactive structures (
Figure 3d)
[55][63]. Individual members of the CYP450 superfamily catalyze various stereospecific modifications at various positions in the core structures of terpenoids, as a result of which their biological activity can significantly increase
[161][162][229,230]. The most important modification catalyzed by CYP450 is oxidative hydroxylation, which makes the compound more hydrophilic
[163][231]. Clustered NAD(P)+ and flavin-dependent oxidoreductases are required for CYP450 to function as partners in the electron transfer chain
[164][232].
In addition to terpenoids, CYP450s are also used to modify other types of fungal secondary metabolites based on NRPS, PKS, and NRPS-PKS activities and meroterpenoids
[165][233]. For example, LovA (CYP68R1, dihydromonacolin L/monacolin L hydroxylase; EC: 1.14.14.124, EC: 1.14.14.125) from the lovastatin biosynthetic pathway sequentially introduces two hydroxyl groups into the backbone (dihydromonacolin L), which leads to: (i) the introduction of the 4a,5-double bond and obtaining monacolin L, which, in turn, (ii) is hydroxylated at C-8 to form monacolin J
[166][234]. The hydroxyl inserted at the C-8 position is then used to incorporate the independently synthesized diketide via a transferase reaction involving LovD (monacolin-J-acid methylbutanoate transferase; EC: 2.3.1.238) to form the final product, lovastatin
[167][235]. However, CYP450s localized separately (without association with any core enzyme of VM biosynthesis) are not always good indicators for the search for biosynthetic clusters of secondary metabolism, since they are used not only to build secondary metabolism, but also for the biosynthesis of structural components and in signaling networks, and are instrumental in xenobiotic detoxification
[161][168][169][170][229,236,237,238]. There are currently about 400 CYP families (namely, CYP51-CYP69, CYP501-CYP699, and CYP5001-CYP6999)
[171][239], which exceeds the diversity in the number of families of representatives of this protein superfamily in bacteria (333 CYP families), plants (127 CYP families), vertebrates (19 CYP families), and insects (67 CYP families)
[161][229]. Due to this variety in the most important enzymatic components of fungi, as well as the lack of data on structural and functional relationships for the vast majority of CYP450, the presence of their genes is only a signal for a possible search for BGCs.
4.6. Transporter Genes of BGCs
It also turns out that, together with the genes for the biosynthesis of a secondary metabolite, the genes necessary for the transport of the final product or its intermediates can be clustered
[26][158][172][173][26,168,240,241]. Such transport can occur both for the removal of the end product from the cell, and for the transport of metabolic intermediates between different compartments of the cell, where the stages of biosynthesis take place
[158][174][175][176][168,169,242,243]. For example, in
A. chrysogenum, the first steps in the biosynthesis of cephalosporin C (CPC), leading to the biosynthesis of IPN, occur in the cytoplasm; then, in the peroxisome, epimerization of IPN to penicillin N (penN) occurs; the final conversion of penN into the target SM, CPC, occurs again in the cytoplasm
[177][244]. For this purpose, in the “early” BGC of beta-lactams, there are special genes for transporter proteins that carry out active transport of the corresponding intermediates: first, as a result of the activity of the CefP transporter, IPN enters peroxisome from the cytoplasm
[178][245]; then reactions occur in the peroxisome, leading to the epimerization of IPN to PenG
[159][227], which then, as a result of the activity of the CefM transporter
[179][246], moves from the peroxisome to the cytoplasm, where it undergoes further transformations.
4.7. Gene for Resistance of BGCs
Another important class of genes found in BGCs are resistance genes against the directly synthesized compound (
Figure 3). The physiological basis of this strategy is that many high-yielding natural products, such as antibiotics or statins, can harm the host organism by acting on microorganisms with similar biochemistry
[1]. This is why it is necessary to “defend” against a number of compounds created by the microorganism itself
[174][180][169,247]. Currently, three main defense strategies for BGC resistance genes have been classified. They are associated with: (i) placement in the BGC of an additional copy of the gene encoding the target protein, which is inhibited by the produced metabolite; (ii) the active transport of a “hazardous” substance from the cell; and (iii) the coding of an enzyme that detoxifies the final highly active antimicrobial product
[70][142]. For example, the “early” beta-lactam BGC also contains the gene for the CefT transporter, which serves in the active transport of CPC and its intermediates, such as IPN, PenN, deacetoxycephalosporin C (DAOC), and deacetylcephalosporin C (DAC), out of the cell
[158][181][168,248]. In the BGC for the production of lovastatin (LOV), a compound that affects the ergosterol biosynthesis of competing fungi (and potentially affects endogenous ergosterol biosynthesis),
lovR is clustered, representing an additional copy of the gene encoding 3-hydroxy-3-methyl glutaryl coenzyme A reductase (EC: 1.1.1.34), which is inactivated by LOV as a result of irreversible binding.
4.8. Pathway-Specific and Cross-Cluster Regulators of BGCs
Finally, in addition to genes for biosynthesis, transport, and resistance, there is a fourth class of genes, often, but not always, found in BGCs, that are responsible for pathway-specific regulation of the BGC itself and/or of other BGCs, in the case of cross-regulation
[94][166]. Such genes encode transcription factors that are able to modulate the effect of signals perceived and reproduced by global regulators and occur in more than half of the currently known BGCs
[182][249]. These factors can act as positive regulators during the signal amplification stage
[94][166]. There are also negative pathway-specific regulators leading to downregulation of the BGC; they are more common if genes for two regulators are clustered in the same BGC and one regulator is positive while the other is negative
[94][166]. However, there are regulators that can be positive for some BGC genes and negative for others. For example, in
A. chrysogenum, the early BGC beta-lactam cluster contains a gene for the CefR regulator, which is both a negative regulator for the
cefT transporter gene from the early BGC and a positive regulator for the
cefEF biosynthetic gene from the late BGC
[183][250]. Thus, CefR from the early BGC beta-lactam cluster is a pathway-specific regulator for
cefT, and a cross-cluster regulator for
cefEF. Such a differential effect of CefR on the expression of beta-lactam BGCs in
A. chrysogenum allows, on the one hand, the biosynthesis of CPC to be intensified (as a result of upregulation of one of the key biosynthetic genes), and on the other hand, for a reduction in the “leakage” of intermediates from the cell (such as IPN, PenN, DAOC, and DAC) and their redirection toward producing the target metabolite, CPC.