Glaucoma is characterized by increased intraocular pressure and damage to the optic nerve, which may result in irreversible blindness. The drastic effects of this disease can be avoided if it is detected at an early stage. However, the condition is frequently detected at an advanced stage in the elderly population. Therefore, early-stage detection may save patients from irreversible vision loss. The manual assessment of glaucoma by ophthalmologists includes various skill-oriented, costly, and time-consuming methods. Several techniques are in experimental stages to detect early-stage glaucoma, but a definite diagnostic technique remains elusive. We present an automatic method based on deep learning that can detect early-stage glaucoma with very high accuracy. The detection technique involves the identification of patterns from the retinal images that are often overlooked by clinicians. The proposed approach uses the gray channels of fundus images and applies the data augmentation technique to create a large dataset of versatile fundus images to train the convolutional neural network model. Using the ResNet-50 architecture, the proposed approach achieved excellent results for detecting glaucoma on the G1020, RIM-ONE, ORIGA, and DRISHTI-GS datasets. WeResearchers obtained a detection accuracy of 98.48%, a sensitivity of 99.30%, a specificity of 96.52%, an AUC of 97%, and an F1-score of 98% by using the proposed model on the G1020 dataset. The proposed model may help clinicians to diagnose early-stage glaucoma with very high accuracy for timely interventions.
- glaucoma
- fundus images
- deep learning
- early-stage detection
1. Introduction
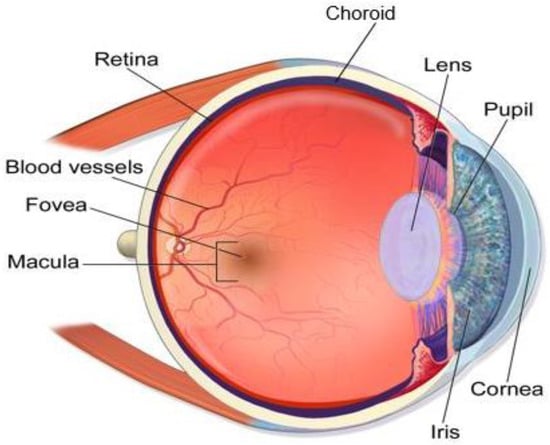
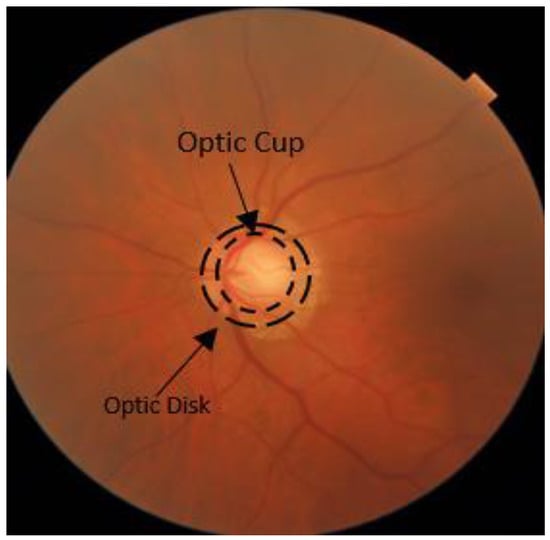
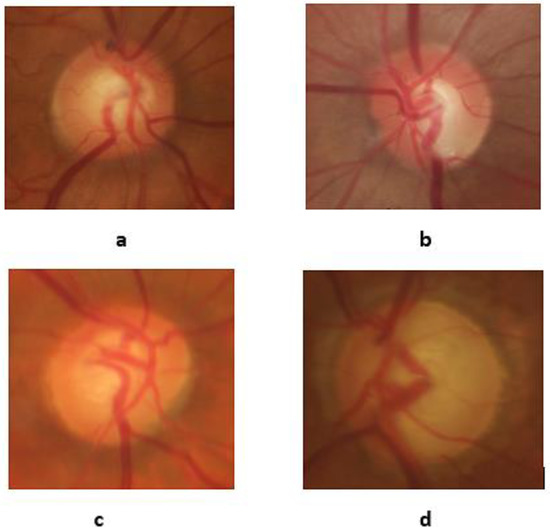
-
The most notable recent machine learning and deep learning-based glaucoma detection research is thoroughly reviewed to define the problem, focusing on various features that can support an efficient diagnosis.
-
For the diagnosis, a model is developed employing advanced deep learning methods along with transfer learning, and the model is tuned using various techniques to lower the likelihood of model overfitting.
-
Multiple datasets of glaucomatous retinal images are adopted to train and test the model to achieve higher diagnostic accuracy.
-
An end-to-end learning system that overcomes the drawbacks of current glaucoma screening methods is developed.
2. Techniques for the Detection of Glaucoma
Glaucoma detection through CNNs is performed by various researchers [21,22,23,24,25,26,27,28,29,30][20][21][22][23][24][25][26][27][28][29]. The CNN-based systems perform effective computation and provide robust results for disease classification. A CNN consists of different layers, such as convolutional, activation, pooling, and the fully connected layer (FCL). Each architecture consists of a different combination of these layers. The diagnosis and detection of other retinal diseases such as papilledema [23[22][30],31], diabetic retinopathy [23][22], central serous retinopathy (CSR) [32,33][31][32], and hypertensive retinopathy [22][21] can be performed through deep learning and machine learning methodologies using OCT and fundus images [5,30][5][29]. Diabetes and other eye diseases have been successfully diagnosed by DL techniques [23][22]. The application of the CAD system has widened the diagnostic horizon in several other disease diagnoses, such as CSR [33][32], lung tumor [34][33], brain tumor [35][34], skin tumor [17], and prostate cancer [18]. The fundus images provide a clear picture of the eye’s internal structure and are widely used for glaucoma diagnosis. The glaucoma classification using fundus images through DL models has shown encouraging results [36,37][35][36]. The fundus images clearly depict the optic nerve head and are readily available for training the glaucoma detection models [38][37]. Various models based on pre-trained CNN models [14[14][38],39], ensemble approaches [40,41,42][39][40][41] and CNN-based architectures are encountered in this article for the detection of glaucoma. Serte and Serener developed a glaucoma detection model using an ensemble approach based on a local dataset of 1542 fundus images [40][39]. The model cropped the OD by using a graph saliency region technique. Three CNN architectures, namely ResNet-50, ResNet-152, and AlexNet, were used as the ensemble classifiers in this model. All three methods, including without saliency map, with saliency map and single CNN model, and with saliency map and ensemble approach, were tested, and the best results were obtained for the ensemble approach with an AUC of 94% and accuracy of 88%. Chaudhary and Pachori developed a glaucoma detection model based on two methods, using RIM-ONE, ORIGA, and DRISHTI-GS datasets [41][40]. The 2D Fourier–Bessel series expansion-based empirical wavelet transform was used for the segmentation of the boundary. Two methods were used, one depending on the ML model and the other using the ensemble approach of the CNN architecture ResNet. The first model at full scale obtained the best results. The best results with the second method were obtained with the ensemble technique at a full scale with 91.1% accuracy, 91.1% sensitivity, 94.3% specificity, 83.3% AUC, and 96% ROC. GlaucomaNet [42][41] was proposed to identify POAG based on dataset images from different populations and settings. The model comprises two CNNs intended to mimic the human grading process. To this end, the first CNN learns the discriminative features, whereas the second fuses the features for grading. This simulation of the human grading process combined with an ensemble of network architectures greatly enhanced the diagnostic accuracy. Thakoor et al. developed a model based on different CNN architectures trained on OCT images and also used some pre-trained models to detect glaucoma [14]. The pre-trained ResNet, VGG, and InceptionNet were combined with random forest and compared with the CNN architectures trained on OCT images. A high accuracy of 96.27% was achieved with the CNN trained on the OCT images. Hemelings et al. proposed an approach for glaucoma detection using pre-trained ResNet-128 architecture with 7083 OD center fundus images [39][38]. The transfer and active learning approaches were used to enhance the diagnosis capability of the model. The use of a saliency map highlighted the affected region to provide evidence of the disease. The model achieved robust results with an AUC of 99.55%, a specificity of 93%, and a sensitivity of 99.2% for glaucoma detection. Yu et al. [4] developed a model using a modified version of U-Net architecture in fundal images for glaucoma diagnosis using multiple datasets. The U-Net used the pre-trained ResNet-34 as an encoder and the classical U-Net architecture as a decoder. The model showed good performance as 97.38% of disc dice values and 88.77% of cup dice values were aligned with the DRISHTI-GS test set. Other authors proposed an approach named AG-CNN, which detected glaucoma and localization of pathological areas using the fundus images [6]. The model is based on attention prediction, localization of the affected area, and glaucoma classification. The deep features predicted glaucoma through the visual maps of necrotic areas in the LAG and RIM-ONE datasets. The use of attention maps for localizing the pathological area demonstrated high efficacy. The model prediction for glaucoma was superior to previous models, with an accuracy of 95.3%. Phan et al. developed a model based on three CNN architectures, ResNet-152, VGG19, and DenseNet201, for diagnosing glaucoma on 3312 retinal fundus images [25][24]. The proposed model has also been tested on poor-quality images to examine its diagnostic accuracy in glaucoma. All the architectures achieved an AUC of 90% for detecting glaucoma. Liao et al. [43][42] proposed a novel CNN-based scheme that used ResBlock architecture to diagnose glaucoma using the ORIGA dataset. The model diagnosed glaucoma and provided a transparent interpretation based on visual evidence by highlighting the affected area. The model named EAMNet contained three parts: ResNet architecture extracted the features and aggregation, and the multiple-layer average pooling (M-LAP) linked the semantic detail and information of the localization, while the evidence activation map (EAP) was used for the evidence of the affected area the physician used for the final decision. The activation map was used to provide the clinical basis for glaucoma. The proposed scheme efficiently diagnosed glaucoma, with an AUC of 0.88. Researchers developed the G-Net model based on CNN to detect glaucoma in the DRISHTI-GS dataset [44][43]. The model used two neural networks (U-Net) to separate the disc and cup. The cropped fundus images in the red channel were fed to the model. The model contained 31 layers of convolutional, max-pooling, up-sampling, and merge layers. The filters applied were of sizes (3, 3), (1, 1), and (1, 32), and 64 filters were used on different layers. The model labeled the pixel as black on segmenting the OD in the real image and white otherwise. The output images were fed to the other model to segment the cup. The second model was like the first model, with a single difference in the size of the filters (4, 4). The output of this model was a segmented cup. These two outputs were used to calculate the CDR for the glaucoma prediction. This algorithm used two neural networks to obtain a high accuracy of 95.8% for OD and 93.0% for OC segmentation. Researchers developed a model based on CNN for glaucoma detection using 1110 OCT images and compared its performance with the ML algorithms [45][44]. A total of 22 features were extracted and fed to different machine learning classifiers such as NB, RF, SVM, LR, Gradient Adaboost, and Extra Trees. The CNN model classified and achieved better results with an AUC of 0.97 than other machine learning approaches, such as logistic regression, with an AUC of 0.89. Thakur et al. proposed a model capable of diagnosing glaucoma before the onset of the disease [46][45]. Three deep learning models were trained on 66,721 fundus images that can detect glaucoma, such as 1 to 3 years ago, 4 to 7 years ago, and before the onset of glaucoma. All three models achieved AUCs of 0.88, 0.77, and 0.97 in detecting glaucoma. Lima et al. developed a CNN model for the optic cup segmentation for the detection of glaucoma [47][46]. The modified U-Net architecture segmented the optic cup from the green channel image, and the optic disc mask was given as input. The model achieved a dice value of 94% on the DRISHTI dataset. Maheshwari et al. presented a model that converted the images into RGB channels after dividing the dataset images into training and testing images [15]. The LBP-based augmentation was applied to obtain the best results. The model achieved 98.90% accuracy, 100% sensitivity, and 97.50% specificity. Lima et al. used a genetic model based on CNN with 25 layers using the RIM-ONE dataset to diagnose glaucoma [12]. The model achieved an accuracy of 91% in detecting glaucoma. Saxena et al. developed a six-layer CNN model for glaucoma detection using the SCES and the ORIGA datasets [13]. The ROI was extracted using the ARGALI approach, and the data augmentation technique was used to avoid the overfitting problem. The model achieved excellent results, with an AUC of 0.882 on SCES and 0.822 on ORIGA datasets. Elangovan and Nath developed a CNN-based model consisting of 18 layers for glaucoma detection [48][47]. The model was based on DRISHTI–GS1, ORIGA, RIM–ONE2 (release 2), ACRIMA, and LAG datasets. The best results were obtained with the ACRIMA dataset, achieving 96.64% accuracy, 96.07% sensitivity, 97.39% specificity, and 97.74% precision. Aamir et al. [49][48] developed a multi-level CNN model for diagnosing glaucoma. The fundus images were preprocessed to reduce noise with the adaptive histogram equalizer technique. The model classified the fundus images for glaucoma detection into advanced, moderate, and early categories. The model achieved a sensitivity of 97.04%, a specificity of 98.99%, an accuracy of 99.39%, and a PRC of 98.2% on 1338 fundus images. Raja et al. [50][49] proposed a technique for diagnosing glaucoma using a dataset of 196 OCT images. The proposed model used CNN and calculated the CDR with 94% accuracy, 94.4% sensitivity, and 93.75% specificity in detecting glaucoma. Carvalho et al. [51][50] proposed a 3DCNN algorithm for diagnosing glaucoma through the fundus images of RIM-ONE and DRISHTI-GS datasets. The 2D fundus images were converted into 3D volumes for each RGB and gray channel. The CNN was trained on all four channels and showed the best results on a gray channel with 83.23% accuracy, 85.54% sensitivity, 80.95% specificity, 83.2% AUC, and 66.45 Kappa. Gheisari et al. developed a combined model based on a CNN and a recurrent neural network for diagnosing glaucoma using retinal fundus images [52][51]. The diagnostic results were achieved with an F-measure of 96.2% on 295 videos and 1810 fundus images. Veena et al. developed a CNN model for the detection of glaucoma [53][52]. The images were preprocessed to eliminate the noise using the Gaussian filter. The Sobel edge and the watershed algorithms extracted the features from the fundus images. The model achieved the OD and OC segmentation accuracies of 0.9845 and 0.9732, respectively, on the DRISHTI dataset. The achieved results are 98.48% accuracy, 99.3% sensitivity, 96.52% specificity, 97% AUC, and 98% of F1-score on the G1020 dataset. Fan et al. [54][53] assessed the diagnostic precision, generalizability, and explainability of a Vision Transformer deep learning method in diagnosing the primary open-angle glaucoma and identifying the salient areas found in the retinal images. A dual learning-based technique that combines deep learning and machine learning was proposed by Thanki [55][54]. For identifying distinctive retinal characteristics, a deep neural network extracts deep features. Following that, a hybrid classification algorithm is employed to accurately classify glaucomatous retinal images.References
- Vision. Available online: https://my.clevelandclinic.org/health/articles/21204-vision (accessed on 16 July 2021).
- Optic Nerve, Healthline. Available online: https://www.healthline.com/human-body-maps/optic-nerve#1 (accessed on 16 July 2021).
- Coiner, B.; Pan, H.; Bennett, M.L.; Bodien, Y.G.; Iyer, S.; O’Neil-Pirozzi, T.M.; Leung, L.; Giacino, J.T.; Stern, E. Functional neuroanatomy of the human eye movement network: A review and atlas. Brain Struct. Funct. 2019, 224, 2603–2617.
- Yu, S.; Xiao, D.; Frost, S.; Kanagasingam, Y. Robust optic disc and cup segmentation with deep learning for glaucoma detection. Comput. Med. Imaging Graph. 2019, 74, 61–71.
- Raja, H.; Akram, M.U.; Khawaja, S.G.; Arslan, M.; Ramzan, A.; Nazir, N. Data on OCT and fundus images for the detection of glaucoma. Data Brief 2020, 29, 105342.
- WikiJournal of Medicine. Available online: https://en.wikiversity.org/wiki/WikiJournal_of_Medicine/Medical_galery_of_Blausen_Medical_2014#/media/File:Blausen_0389_EyeAnatomy_02.png (accessed on 16 July 2021).
- Asano, S.; Asaoka, R.; Murata, H.; Hashimoto, Y.; Miki, A.; Mori, K.; Ikeda, Y.; Kanamoto, T.; Yamagami, J.; Inoue, K. Predicting the central 10 degrees visual field in glaucoma by applying a deep learning algorithm to optical coherence tomography images. Sci. Rep. 2021, 11, 2214.
- Li, L.; Xu, M.; Wang, X.; Jiang, L.; Liu, H. Attention based glaucoma detection: A large-scale database and CNN Model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10571–10580.
- World Report on Vision. Available online: https://www.google.com/url?sa=t&source=web&rct=j&url=https://apps.who.int/iris/rest/bitstreams/1257940/retrieve&ved=2ahUKEwjGy4js3pPrAhWMEBQKHWUQCFMQFjAAegQIARAB&usg=AOvVaw3DSQZJ6aFidsEgDH4nsz8X (accessed on 17 July 2021).
- Eyes on Eyecare. Available online: https://www.eyesoneyecare.com/resources/glaucoma-systemic-medications-friends508or-foes-with-cheat-sheet/. (accessed on 17 July 2021).
- Fumero, F.; Alayón, S.; Sanchez, J.L.; Sigut, J.; Gonzalez-Hernandez, M. RIM-ONE: An open retinal image database for optic nerve evaluation. In Proceedings of the 2011 24th International Symposium on Computer-Based Medical Systems (CBMS), Bristol, UK, 27–30 June 2011; pp. 1–6.
- de Moura Lima, A.C.; Maia, L.B.; dos Santos, P.T.C.; Junior, G.B.; de Almeida, J.D.; de Paiva, A.C. Evolving Convolutional Neural Networks for Glaucoma Diagnosis. Braz. J. Health Rev. 2020, 3, 9224–9234.
- Saxena, A.; Vyas, A.; Parashar, L.; Singh, U. A Glaucoma Detection using Convolutional Neural Network. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 815–820.
- Thakoor, K.A.; Li, X.; Tsamis, E.; Sajda, P.; Hood, D.C. Enhancing the Accuracy of Glaucoma Detection from OCT Probability Maps using Convolutional Neural Networks. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 2036–2040.
- Maheshwari, S.; Kanhangad, V.; Pachori, R.B. CNN-based approach for glaucoma diagnosis using transfer learning and LBP-based data augmentation. arXiv 2020, arXiv:2002.08013.
- Rehman, A.; Khan, M.A.; Saba, T.; Mehmood, Z.; Tariq, U.; Ayesha, N. Microscopic brain tumor detection and classification using 3D CNN and feature selection architecture. Microsc. Res. Technol. 2021, 84, 133–149.
- Saeed, J.; Zeebaree, S. Skin lesion classification based on deep convolutional neural networks architectures. J. Appl. Sci. Technol. Trends 2021, 2, 41–51.
- Sobecki, P.; Jóźwiak, R.; Sklinda, K.; Przelaskowski, A. Effect of domain knowledge encoding in CNN model architecture—A prostate cancer study using mpMRI images. PeerJ 2021, 9, 11006–11021.
- Medeiros, F.A.; Jammal, A.A.; Mariottoni, E.B. Detection of progressive glaucomatous optic nerve damage on fundus photographs with deep learning. Ophthalmology 2021, 128, 383–392.
- Akbar, S.; Akram, M.U.; Sharif, M.; Tariq, A.; ullah Yasin, U. Arteriovenous ratio and papilledema based hybrid decision support system for detection and grading of hypertensive retinopathy. Comput. Methods Programs Biomed. 2018, 154, 123–141.
- Akbar, S.; Akram, M.U.; Sharif, M.; Tariq, A.; Khan, S.A. Decision support system for detection of hypertensive retinopathy using arteriovenous ratio. Artif. Intell. Med. 2018, 90, 15–24.
- Akram, M.U.; Akbar, S.; Hassan, T.; Khawaja, S.G.; Yasin, U.; Basit, I. Data on fundus images for vessels segmentation, detection of hypertensive retinopathy, diabetic retinopathy and papilledema. Data Brief 2020, 29, 105282.
- Akbar, S.; Hassan, M.; Akram, U.; Yasin, U.U.; Basit, I. AVRDB: Annotated dataset for vessel segmentation and calculation of arteriovenous ratio. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV), Las Vegas, NV, USA, 17 July 2017; pp. 129–134.
- Phan, S.; Satoh, S.I.; Yoda, Y.; Kashiwagi, K.; Oshika, T.; Group, J.O.I.R.R. Evaluation of deep convolutional neural networks for glaucoma detection. Jpn. J. Ophthalmol. 2019, 63, 276–283.
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516.
- Sharma, R.; Sircar, P.; Pachori, R.; Bhandary, S.V.; Acharya, U.R. Automated glaucoma detection using center slice of higher order statistics. J. Mech. Med. Biol. 2019, 19, 1940011.
- Shibata, N.; Tanito, M.; Mitsuhashi, K.; Fujino, Y.; Matsuura, M.; Murata, H.; Asaoka, R. Development of a deep residual learning algorithm to screen for glaucoma from fundus photography. Sci. Rep. 2018, 8, 14665.
- Singh, A.; Dutta, M.K.; ParthaSarathi, M.; Uher, V.; Burget, R. Image processing based automatic diagnosis of glaucoma using wavelet features of segmented optic disc from fundus image. Comput. Methods Programs Biomed. 2016, 124, 108–120.
- Wang, X.; Chen, H.; Ran, A.R.; Luo, L.; Chan, P.P.; Tham, C.C.; Chang, R.T.; Mannil, S.S.; Cheung, C.Y.; Heng, P.A. Towards multi-center glaucoma OCT image screening with semi-supervised joint structure and function multi-task learning. Med. Image Anal. 2020, 63, 101695–101712.
- Saba, T.; Akbar, S.; Kolivand, H.; Ali Bahaj, S. Automatic detection of papilledema through fundus retinal images using deep learning. Microsc. Res. Technol. 2021, 84, 3066–3077.
- Hassan, S.A.; Akbar, S.; Rehman, A.; Saba, T.; Kolivand, H.; Bahaj, S.A. Recent Developments in Detection of Central Serous Retinopathy Through Imaging and Artificial Intelligence Techniques–A Review. IEEE Access 2021, 9, 168731–168748.
- Hassan, S.A.E.; Akbar, S.; Gull, S.; Rehman, A.; Alaska, H. Deep Learning-Based Automatic Detection of Central Serous Retinopathy using Optical Coherence Tomographic Images. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 206–211.
- Heuvelmans, M.A.; van Ooijen, P.M.; Ather, S.; Silva, C.F.; Han, D.; Heussel, C.P.; Hickes, W.; Kauczor, H.-U.; Novotny, P.; Peschl, H. Lung cancer prediction by Deep Learning to identify benign lung nodules. Lung Cancer 2021, 154, 1–4.
- Gull, S.; Akbar, S. Artificial Intelligence in Brain Tumor Detection through MRI Scans: Advancements and Challenges. In Artificial Intelligence and Internet of Things; CRC Press: Boca Raton, FL, USA, 2020; pp. 241–276.
- Mohamed, N.A.; Zulkifley, M.A.; Zaki, W.M.D.W.; Hussain, A. An automated glaucoma screening system using cup-to-disc ratio via Simple Linear Iterative Clustering superpixel approach. Biomed. Signal Process. Control 2019, 53, 101454–101461.
- Ramzan, A.; Akram, M.U.; Shaukat, A.; Khawaja, S.G.; Yasin, U.U.; Butt, W.H. Automated glaucoma detection using retinal layers segmentation and optic cup-to-disc ratio in optical coherence tomography images. IET Image Process. 2018, 13, 409–420.
- Sengupta, S.; Singh, A.; Leopold, H.A.; Gulati, T.; Lakshminarayanan, V. Ophthalmic diagnosis using deep learning with fundus images–A critical review. Artif. Intell. Med. 2020, 102, 101758.
- Hemelings, R.; Elen, B.; Barbosa-Breda, J.; Lemmens, S.; Meire, M.; Pourjavan, S.; Vandewalle, E.; Van de Veire, S.; Blaschko, M.B.; De Boever, P. Accurate prediction of glaucoma from colour fundus images with a convolutional neural network that relies on active and transfer learning. Acta Ophthalmol. 2020, 98, 94–100.
- Serte, S.; Serener, A. A Generalized Deep Learning Model for Glaucoma Detection. In Proceedings of the 2019 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 10–12 October 2019; pp. 1–5.
- Chaudhary, P.K.; Pachori, R.B. Automatic diagnosis of glaucoma using two-dimensional Fourier-Bessel series expansion based empirical wavelet transform. Biomed. Signal Process. Control 2021, 64, 102237–102248.
- Lin, M.; Hou, B.; Liu, L.; Gordon, M.; Kass, M.; Wang, F.; Van Tassel, S.H.; Peng, Y. Automated diagnosing primary open-angle glaucoma from fundus image by simulating human’s grading with deep learning. Sci. Rep. 2022, 12, 14080–14091.
- Liao, W.; Zou, B.; Zhao, R.; Chen, Y.; He, Z.; Zhou, M. Clinical Interpretable Deep Learning Model for Glaucoma Diagnosis. IEEE J. Biomed. Health Inform. 2019, 24, 1405–1412.
- Juneja, M.; Singh, S.; Agarwal, N.; Bali, S.; Gupta, S.; Thakur, N.; Jindal, P. Automated detection of Glaucoma using deep learning convolution network (G-net). Multimed. Tools Appl. 2020, 79, 15531–15553.
- Maetschke, S.; Antony, B.; Ishikawa, H.; Wollstein, G.; Schuman, J.; Garnavi, R. A feature agnostic approach for glaucoma detection in OCT volumes. PLoS ONE 2019, 14, 219126–219137.
- Thakur, A.; Goldbaum, M.; Yousefi, S. Predicting Glaucoma before Onset Using Deep Learning. Ophthalmol. Glaucoma 2020, 3, 262–268.
- Lima, A.A.; de Carvalho Araújo, A.C.; de Moura Lima, A.C.; de Sousa, J.A.; de Almeida, J.D.S.; de Paiva, A.C.; Júnior, G.B. Mask Overlaying: A Deep Learning Approach for Individual Optic Cup Segmentation from Fundus Image. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 99–104.
- Elangovan, P.; Nath, M.K. Glaucoma assessment from color fundus images using convolutional neural network. Int. J. Imaging Syst. Technol. 2021, 31, 955–971.
- Aamir, M.; Irfan, M.; Ali, T.; Ali, G.; Shaf, A.; Al-Beshri, A.; Alasbali, T.; Mahnashi, M.H. An adoptive threshold-based multi-level deep convolutional neural network for glaucoma eye disease detection and classification. Diagnostics 2020, 10, 602.
- Raja, H.; Akram, M.U.; Shaukat, A.; Khan, S.A.; Alghamdi, N.; Khawaja, S.G.; Nazir, N. Extraction of retinal layers through convolution neural network (CNN) in an OCT image for glaucoma diagnosis. J. Digit. Imaging 2020, 33, 1428–1442.
- de Sales Carvalho, N.R.; Rodrigues, M.d.C.L.C.; de Carvalho Filho, A.O.; Mathew, M.J. Automatic method for glaucoma diagnosis using a three-dimensional convoluted neural network. Neurocomputing 2021, 438, 72–83.
- Gheisari, S.; Shariflou, S.; Phu, J.; Kennedy, P.J.; Agar, A.; Kalloniatis, M.; Golzan, S.M. A combined convolutional and recurrent neural network for enhanced glaucoma detection. Sci. Rep. 2021, 11, 1945.
- Veena, H.N.; Muruganandham, A.; Senthil Kumaran, T. A novel optic disc and optic cup segmentation technique to diagnose glaucoma using deep learning convolutional neural network over retinal fundus images. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 6187–6198.
- Fan, R.; Alipour, K.; Bowd, C.; Christopher, M.; Brye, N.; Proudfoot, J.A.; Goldbaum, M.H.; Belghith, A.; Girkin, C.A.; Fazio, M.A.; et al. Detecting Glaucoma from Fundus Photographs Using Deep Learning without Convolutions: Transformer for Improved Generalization. Ophthalmol. Sci. 2023, 3, 100233–100243.
- Thanki, R. A deep neural network and machine learning approach for retinal fundus image classification. Healthc. Anal. 2023, 3, 100140.