Your browser does not fully support modern features. Please upgrade for a smoother experience.
Please note this is a comparison between Version 1 by Satish Srinivasan and Version 2 by Camila Xu.
Advances in Artificial Intelligence (AI) technology have contributed to the enhancement of cybersecurity capabilities of traditional systems with applications that include detection of intrusion, malware, code vulnerabilities and anomalies. However, these systems with embedded machine learning models have opened themselves to a new set of vulnerabilities, commonly known as AI attacks.
- machine learning
- cybersecurity
- AI attacks
1. Introduction
Advances in Artificial Intelligence (AI) technology have contributed to the enhancement of cybersecurity capabilities of traditional systems with applications that include detection of intrusion, malware, code vulnerabilities and anomalies. However, these systems with embedded machine learning models have opened themselves to a new set of vulnerabilities, commonly known as AI attacks. Currently, these systems are prime targets for cyberattacks, thus compromising the security and safety of larger systems that encompass them. Modern day AI attacks are not only limited to just coding bugs and errors. They manifest due to the inherent limitations or vulnerabilities of systems [1]. By exploiting the vulnerabilities in the AI system, attackers aim at either manipulating its behavior or obtaining its internal details by tampering with its input, training data, or the machine learning (ML) model. McGraw et al. [2] have classified AI attacks broadly as manipulation and extraction attacks. Based on the inputs given to the system, the training dataset used for learning, and manipulation of the model hyperparameters, attacks on AI systems can manifest in different types, with different degrees of severity.
2. AI Attacks and Defense Mechanisms
Research has been carried out to identify new threats and attacks on different levels of design and implementation of AI systems. Kaloudi and Li [3][56], stressed the dearth of proper understanding of the malicious intention of the attacks on AI-based systems. The authors introduced 11 use cases divided into five categories: (1) next generation malware, (2) void synthesis, (3) password-based attacks, (4) social bots, and (5) adversarial training. They developed a threat framework to categorize the attacks. Turchin [4][57] pointed out the lack of desired behaviors of AI systems that could be exploited to design attacks in different phases of system development. The research lists the following modes of failure of AI systems:-
The need for better resources for self-upgradation of AI systems can be exploited by adversaries
-
Implementation of malicious goals make the AI systems unfriendly
-
Flaws in the user-friendly features
-
Use of different techniques to make different stages of AI free from the boundaries of actions expose the AI systems to adversaries
2.1. Types of Failures
Shiva Kemar et al. [7][60] discussed two modes of failures of machine learning (ML) systems. They claimed that AI systems can fail either due to the inherent design of the systems (unintentional failures) or by the hand of an adversary (intentional failures). Unintentional Failures: The unintentional failure mode leads to the failure of an AI/ML system when the AI/ML system generates formally correct, but completely unsafe, behavior. Intentional failures: Intentional failures are caused by the attackers attempting to destabilize the system either by (a) misclassifying the results, by introducing private training data, or b) by stealing the foundational algorithmic framework. Depending on the accessibility of information about the system components (i.e., knowledge), intentional failures can be further subdivided into different subcategories.2.1.1. Categories of Unintentional Failures
Unintentional failures happen when AI/ML systems produce an unwanted or unforeseen outcome from a determined action. It happens mainly due to system failures.-
Reward Hacking: Reward hacking is a failure mode that an AI/ML system experiences when the underlying framework is a reinforcement learning algorithm. Reward hacking appears when an agent has more return as reward in an unexpected manner in a game environment [8][61]. This unexpected behavior unsettles the safety of the system. Yuan et al. [9][62] proposed a new multi-step reinforcement learning framework, where the reward function generates a discounted future reward and, thus, reduces the influence of immediate reward on the current state action pair. The proposed algorithm creates the defense mechanism to mitigate the effect of reward hacking in AI/ML systems.
-
Distributed Shift: This type of mode appears when an AI/ML model that once performed well in an environment generates dismal performance when deployed to perform in a different environment. One such example is when the training and test data come from two different probability distributions [10][63]. The distribution shift is further subdivided into three types [11][64]:
- 1.
-
Covariate Shift: The shifting problem arises due to the change in input features (covariates) over time, while the distribution of the conditional labeling function remains the same.
- 2.
-
Label Shift: This mode of failure is complementary to covariate shift, such that the distribution of class conditional probability does not change but the label marginal probability distribution changes.
- 3.
-
Concept Shift: Concept shift is a failure related to the label shift problem where the definitions of the label (i.e., the posteriori probability) experience spatial or temporal changes.
-
Natural Adversarial Examples: The natural adversarial examples are real-world examples that are not intentionally modified. Rather, they occur naturally, and result in considerable loss of performance of the machine learning algorithms [15][68]. The instances are semantically similar to the input, legible and facilitate interpretation (e.g., image data) of the outcome [16][69]. Deep neural networks are susceptible to natural adversarial examples.
2.1.2. Categories of Intentional Failures
The goal of the adversary is deduced from the type of failure of the model. Chakraborty et al. [17][70] identify four different classes of adversarial goals, based on the machine learning classifier output, which are the following: (1) confidence reduction, where the target model prediction confidence is reduced to a lower probability of classification, (2) misclassification, where the output class is altered from the original class, (3) output misclassification, which deals with input generation to fix the classifier output into a particular class, and (4) input/output misclassification, where the label of a particular input is forced to have a specific class. Shiv Kumar et al. [7][60] identified the taxonomy of intentional failures/attacks, based on the knowledge of the adversary. It deals with the extent of knowledge needed to trigger an attack for the AI/ML systems to fail. The adversary is better equipped with more knowledge [17][70] to perform the attack. There are three types of classified attacks based on the adversary’s access to knowledge about the system.- 1
-
Whiteb ox Attack: In this type of attack, the adversary has access to the parameters of the underlying architecture of the model, the algorithm used for training, weights, training data distribution, and biases [18][19][71,72]. The adversary uses this information to find the model’s vulnerable feature space. Later, the model is manipulated by modifying an input using adversarial crafting methods. An example of the whitebox attack and adversarial crafting methods are discussed in later sections. The researchers in [20][21][73,74] showed that adversarial training of the data, filled with some adversarial instances, actually helps the model/system become robust against whitebox attacks.
- 2
-
Blackbox Attack: In blackbox attacks the attacker does not know anything about the ML system. The attacker has access to only two types of information. The first is the hard label, where the adversary obtained only the classifier’s predicted label, and the second is confidence, where the adversary obtained the predicted label along with the confidence score. The attacker uses information about the inputs from the past to understand vulnerabilities of the model [17][70]. Some blackbox attacks are discussed in later sections. Blackbox attacks can further be divided into three categories:
- Non-Adaptive Blackbox Attack:
- In this category of blackbox attack, the adversary has the knowledge of distribution of training data for a model, T. The adversary chooses a procedure, P, for a selected local model, T’, and trains the model on known data distribution using P for T’ to approximate the already learned T in order to trigger misclassification using whitebox strategies
- [
- ]
- [
- ]
- [
- ,
- 75].
-
Adaptive Blackbox Attack: In adaptive blackbox attack the adversary has no knowledge of the training data distribution or the model architecture. Rather, the attacker approaches the target model, T, as an oracle. The attacker generates a selected dataset with a label accessed from adaptive querying of the oracle. A training process, P, is chosen with a model, T’, to be trained on the labeled dataset generated by the adversary. The model T’ introduces the adversarial instances using whitebox attacks to trigger misclassification by the target model T [17][24][70,76].
-
Strict Blackbox Attack: In this blackbox attack category, the adversary does not have access to the training data distribution but could have the labeled dataset (x, y) collected from the target model, T. The adversary can perturb the input to identify the changes in the output. This attack would be successful if the adversary has a large set of dataset (x, y) [17][18][70,71].
2.2. Anatomy of Cyberattacks
To build any machine learning model, the data needs to be collected, processed, trained, and tested and can be used to classify new data. The system that takes care of the sequence of data collection, processing, training and testing can be thought of as a generic AI/ML pipeline, termed the attack surface [17][70]. An attack surface subjected to adversarial intrusion may face poisoning attack, evasion attack, and exploratory attack. These attacks exploit three pillars of the information security, i.e., Confidentiality, Integrity, and Availability, known as the CIA triad [26][78]. Integrity of a system is compromised by the poisoning and evasion attacks, confidentiality is subject to intrusion by extraction, while availabilty is vulnerable to poisoning attacks. The entire AI pipeline, along with the possible attacks at each step, are shown in Figure 1.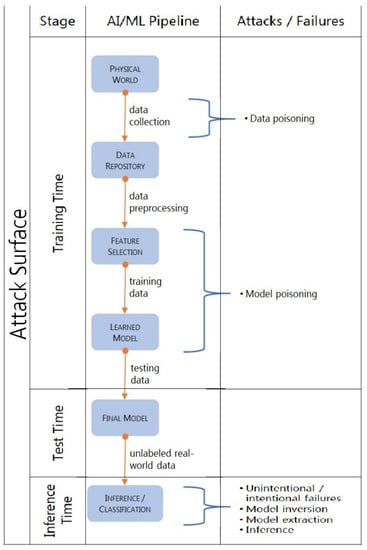 Figure 1.ML Pipeline with Cyberattacks Layout.
Figure 1.ML Pipeline with Cyberattacks Layout.2.3. Poisoning Attack
Poisoning attack occurs when the adversary contaminates the training data. Often ML algorithms, such as intrusion detection systems, are retrained on the training dataset. In this type of attack, the adversary cannot access the training dataset, but poisons the data by injecting new data instances [27][28][29][35,37,40] during the model training time. In general, the objective of the adversary is to compromise the AI system to result in the misclassification of objects. Poisoning attacks can be a result of poisoning the training dataset or the trained model [1]. Adversaries can attack either at the data source, a platform from which a defender extracts its data, or can compromise the database of the defender. They can substitute a genuine model with a tainted model. Poisoning attacks can also exploit the limitations of the underlying learning algorithms. This attack happens in federated learning scenarios where the privacy on individual users’ dataset is maintained [30][47]. The adversary takes advantage of the weakness of federated learning and may take control of both the data and algorithm on an individual user’s device to deteriorate the performance of the model on that device [31][48].2.4. Model Inversion Attack
The model inversion attack is a way to reconstruct the training data, given the model parameters. This type of attack is a concern for privacy, because there are a growing number of online model repositories. Several studies related to this attack hve been under both the blackbox and whitebox settings. Yang et al. [32][121] discussed the model inversion attack in the blackbox setting, where the attacker wants to reconstruct an input sample from the confidence score vector determined by the target model. In their study, they demonstrated that it is possible to reconstruct specific input samples from a given model. They trained a model (inversion) on an auxiliary dataset, which functioned as the inverse of the given target model. Their model then took the confidence scores of the target model as input and tried to reconstruct the original input data. In their study, they also demonstrated that their inversion model showed substantial improvement over previously proposed models. On the other hand, in a whitebox setting, Fredrikson et al. [33][122] proposed a model inversion attack that produces only a representative sample of a training data sample, instead of reconstructing a specific input sample, using the confidence score vector determined by the target model. Several related studies were proposed to infer sensitive attributes [33][34][35][36][122,123,124,125] or statistical information [37][126] about the training data by developing an inversion model. Hitaj et al. [18][71] explored inversion attacks in federated learning where the attacker had whitebox access to the model. Several defense strategies against the model inversion attack have been explored that include L2 Regularizer [38][49], Dropout and Model Staking [39][50], MemGuard [40][51], and Differential privacy [41][52]. These defense mechanisms are also well-known for reducing overfitting in the training of deep neural network models.2.5. Model Extraction Attack
A machine learning model extraction attack arises when an attacker obtains blackbox access to the target model and is successful in learning another model that closely resembles. or is exactly the same as, the target model. Reith et al. [42][54] discussed model extraction against the support vector regression model. Juuti et al. [43][127] explored neural networks and showed an attack, in which an adversary generates queries for DNNs with simple architectures. Wang et al., in [44][128], proposed model extraction attacks for stealing hyperparameters against a simple architecture similar to a neural network with three layers. The most elegant attack, in comparison to the others, was shown in [45][129]. They showed that it is possible to extract a model with higher accuracy than the original model. Using distillation, which is a technique for model compression, the authors in [46][47][130,131], executed model extraction attacks against DNNs and CNNs for image classification. To defend against model extraction attacks, the authors in [22][48][49][53,132,133] proposed either hiding or adding noises to the output probabilities, while keeping the class label of the instances intact. However, such approaches are not very effective in label-based extraction attacks. Several others have proposed monitoring the queries and differentiating suspicious queries from others by analyzing the input distribution or the output entropy [43][50][127,134].2.6. Inference Attack
Machine learning models have a tendency to leak information about the individual data records on which they were trained. Shokri et al. [38][49] discussed the membership inference attack, where one can determine if the data record is part of the model’s training dataset or not, given the data record and blackbox access to the model. According to them, this is a concern for privacy breach. If the advisory can learn if the record was used as part of the training, from the model, then such a model is considered to be leaking information. The concern is paramount, as such a privacy beach not only affects a single observation, but the entire population, due to high correlation between the covered and the uncovered dataset [51][135]. This happens particularly when the model is based on statistical facts about the population. Studies in [52][53][54][136,137,138] focused on attribute inference attacks. Here an attacker gets access to a set of data about a target user, which is mostly public in nature, and aims to infer the private information of the target user. In this case, the attacker first collects information from users who are willing to disclose it in public, and then uses the information as a training dataset to learn a machine learning classifier which can take a user’s public data as input and predict the user’s private attribute values. In terms of potential defense mechanisms, methods proposed in [55][56][55,139] leveraged heuristic correlations between the records of the public data and attribute values to defend against attribute inference attacks. They proposed modifying the identified k entries that have large correlations with the attribute values to any given target users. Here k is used to control the privacy–utility trade off. This addresses the membership inference attack.