Predicting protein stability changes upon genetic variations is still an open challenge. It is essential to understand the impact of the alterations in the amino acid sequence, mainly due to non-synonymous (or missense) DNA variations leading to the disruption or the enhancement of the protein activity, on human health and disease. In particular, protein stability perturbations have already been associated to pathogenic missense variants and they were shown to contribute to the loss of function in haploinsufficient genes.
1. Introduction
The protein stability changes upon variations of the amino acid sequence is usually expressed as the Gibbs free energy of unfolding (
), which is defined as the difference between the energy of the mutated structure of the protein and its wild-type form (
). Thermodynamics imposes an antisymmetry relationship on that can be summarized as follows: given the wild-type (W) and mutated (M) protein structures, differing by one residue in position X, the quantity represents the change in the protein stability caused by the amino acid substitution . Similarly, given the symmetry between the two molecular systems M and W, for the reverse variation the corresponding change in Gibbs free energy has the opposite sign:
2. Learning 3D Properties on Artificial Data
A proper training of a neural network requires a huge amount of experimental values that are not currently available; we addressed this problem by performing a pre-training phase on the artificial dataset IvankovDDGun and then applying a transfer learning on the experimental datasets S2648 and Varibench, as described in the Materials and Methods section.
In Table 1, we show the results on the IvankovDDGun test set. It is worth noticing that the DDGun3D values were computed using the protein structures, while the ACDC-NN-Seq predictions are only based on sequence information. Thus, this approach obtained a sequence-based method capable of internally encoding the 3D statistical potentials that maintain the antisymmetric property.
Table 1. Results on the IvankovDDGun test set: The performance of ACDC-NN-Seq in learning DDGun3D was measured in terms of Pearson correlation coefficient (r) and root mean square error (RMSE). The antisymmetry property was assessed in terms of Pearson correlation coefficient ( ) and the bias ( ) between the predicted values. RMSE and are expressed in kcal/mol. IvankovDDGun (Test) is the test set extracted from the IvankovDDGun artificial dataset.
| Dataset |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| IvankovDDGun (Test) |
0.97/0.06 |
0.97/0.06 |
−1.0 |
0.0 |
3. Prediction of the Experimental Values
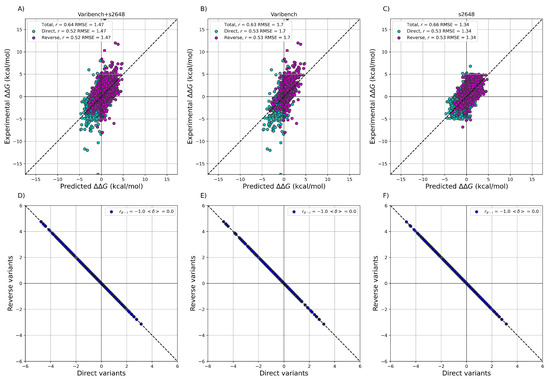
After training ACDC-NN-Seq on the IvankovDDGun set, we fine-tuned the network by retraining the last layers on the experimentally-derived values from S2648 and Varibench through 10-fold cross-validation. In Figure 1 we showed the experimental values versus the ACDC-NN-Seq predicted ones on Varibench and S2648 datasets both combined and alone, and for both direct and reverse variations. These results were obtained in cross-validation as explained in Benevenuta et al. . ADCD-NN-Seq achieved both consistent performance with the state-of-the-art methods (measured in terms of r and ) and perfect antisymmetry ( and ).
Figure 1. Performance of ACDC-NN-Seq on predicting for the direct and reverse variations on: (A) Varibench and S2648 ( , kcal/mol); (B) Varibench alone ( , kcal/mol); (C) S2648 alone ( , kcal/mol). Direct versus reverse values of (D) Varibench and S2648 variations, (E) Varibench variations alone, (F) S2648 variations alone, predicted by ACDC-NN-Seq, with a Pearson correlation of and kcal/mol for all three datasets. All the predictions reported in this figure were obtained through a 10-fold cross-validation with sequence identity <25% among all folds.
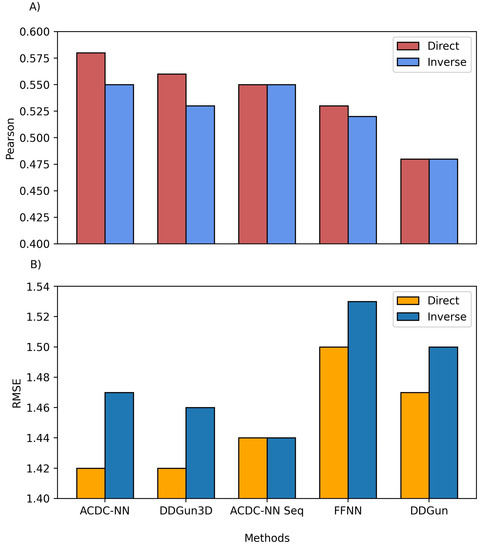
We also compared the predictions of both ACDC-NN-Seq and DDGun with their corresponding stucture-based versions, i.e., ACDC-NN and DDGun3D. Figure 2 reports the comparison performance (in cross-validation for ACDC-NN and ACDC-NN-Seq) on the Ssym dataset , which was specifically built to assess the antisymmetry and it contains experimental values for direct and reverse variants. The performance of ACDC-NN-Seq is balanced and close to those obtained using the protein structures. This makes ADCD-NN-Seq ideal for genome variant analyses.
Figure 2. Comparison between the structure and sequence-based versions of ACDC-NN, DDGun and a Feed-Forward Neural Network (FFNN) on the Ssym dataset. (A) Pearson correlation coefficient (r), where higher is better and (B) root mean squared error (RMSE), where lower is better.
In order to evaluate the effect of the neural network design, we compared ACDC-NN-Seq with a feed-forward neural network (FFNN) trained and optimized in the same conditions. The structure of the optimized FFNN consists of an input layer of 140 input neurons (window of 7 residues coded with 20-element vector profiles), a sequence of hidden layers consisting of (128,64,32,16) neurons, and an output neuron coding for the value. Thus the main difference is due to the anty-symmetric construction of ACDC-NN-Seq (FFNN Figure 2). FFNN performance is quite good, and the neural networks learned most of the antisymmetry from the data provided (direct and reverse variations). However, ACDC-NN-Seq outperforms FFNN both in the prediction task and antisymmetry reconstructions.
Regarding the results presented in Figure 1 and Figure 2, it is worth noticing that the maximum achievable Pearson’s correlation is not necessarily equal to 1, as usually thought. It may be far lower depending on the experimental uncertainty and the distributions . In particular, when considering the different experiments on the same variants included in the Protherm database or in manually-cleaned datasets, the expected Pearson upper bound is in the range of 0.70–0.85 . Significantly higher Pearson correlations can be obtained in small sets or might be indicative of overfitting issues .
4. Comparison with Other Sequence-Based Machine-Learning Methods
As mentioned above, few available methods can predict the effect of the variants on the protein stability starting from sequence only. We therefore compared ACDC-NN-Seq on three datasets with the following sequence-based methods: DDGun , INPS , I-Mutant2.0 , MUpro and the recent SAAFEC-SEQ .
The obtained results are reported in Table 2; ACDC-NN-Seq predicts equally well both direct and reverse variants with nearly perfect antisymmetry ( ). ACDC-NN-Seq performance is higher than the one obtained by INPS, which is the only machine-learning method proven to be antisymmetric in past tests .
Table 2. Results on Ssym: The performance on both direct and reverse variants was measured in terms of Pearson correlation coefficient (r) and root mean square error (RMSE). The antisymmetry was assessed using the correlation coefficient
(
2) and the bias
(
3). RMSE and
are expressed in kcal/mol. The results of INPS were taken from Montanucci et al. and Fariselli et al. ; the results of SAAFEC-SEQ and I-mutant2.0 were obtained using their stand-alone code, those of MUpro were obtained using the webserver available. Only Inps-NoSeqId and ACDN-NN-Seq were trained in cross-validation addressing the sequence identity issue (sequence similarity <25%).
| Method |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| ACDC-NN-Seq |
0.55/1.44 |
0.55/1.44 |
−0.99 |
−0.01 |
| INPS-NoSeqId |
0.48/1.42 |
0.47/1.45 |
−0.99 |
−0.06 |
| INPS |
0.51/1.42 |
0.50/1.44 |
−0.99 |
−0.04 |
| SAAFEC-SEQ |
0.71/1.09 |
−0.39/2.71 |
0.58 |
−1.84 |
| I-Mutant2.0 |
0.7/1.12 |
0.05/2.54 |
−0.17 |
−1.01 |
| MUpro |
0.79/0.94 |
0.07/2.51 |
−0.02 |
−0.97 |
I-Mutant2.0 and MUpro do not respect the antisymmetry property since this issue was not properly addressed or known at the time the two models were created. However, it must be noted that both I-Mutant2.0 and MUpro do not use evolutionary information making them extremely fast predictors, as compared to ACDC-NN-Seq, which requires a multiple sequence alignment.
Another significant point is that, looking at all the methods reported in Table 4, Table 5 and Table 4, only Inps-NoSeqId and all the versions of ACDN-NN were trained in cross-validation removing the sequence identity (i.e., sequence similarity <25%).
Table 3. Results on myoglobin: Comparison on myoglobin. The INPS, SAAFEC-SEQ and I-mutant2.0 results were obtained using their stand alone code, those of MUpro were obtained using the webserver available.
| Method |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| ACDC-NN-Seq |
0.56/0.97 |
0.56/0.97 |
−1.00 |
0.00 |
| INPS |
0.60/0.99 |
0.61/0.98 |
−1.00 |
0.01 |
| SAAFEC-SEQ |
0.63/0.89 |
0.30/1.63 |
−0.21 |
−1.50 |
| I-Mutant2.0 |
0.56/1.12 |
0.39/1.71 |
−0.45 |
−0.88 |
| MUpro |
0.51/0.99 |
0.35/1.75 |
−0.17 |
−0.79 |
Table 4. Results on p53: Comparison on p53. The INPS, SAAFEC-SEQ and I-mutant2.0 results were obtained using their stand alone code, those of MUpro were obtained using the webserver available.
| Method |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| ACDC-NN-Seq |
0.62/1.62 |
0.62/1.62 |
−1.00 |
0.00 |
| INPS |
0.72/1.49 |
0.70/1.54 |
−0.99 |
−0.01 |
| SAAFEC-SEQ |
0.52/1.64 |
−0.18/2.97 |
0.06 |
−1.79 |
| I-Mutant2.0 |
0.35/1.75 |
0.22/2.81 |
−0.24 |
−1.02 |
| MUpro |
0.23/1.78 |
0.04/2.87 |
0.12 |
−0.98 |
Table 5. Results on p53: Comparison on p53. The INPS, SAAFEC-SEQ and I-mutant2.0 results were obtained using their stand alone code, those of MUpro were obtained using the webserver available.
| Method |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| ACDC-NN-Seq |
0.62/1.62 |
0.62/1.62 |
−1.00 |
0.00 |
| INPS |
0.72/1.49 |
0.70/1.54 |
−0.99 |
−0.01 |
| SAAFEC-SEQ |
0.52/1.64 |
−0.18/2.97 |
0.06 |
−1.79 |
| I-Mutant2.0 |
0.35/1.75 |
0.22/2.81 |
−0.24 |
−1.02 |
| MUpro |
0.23/1.78 |
0.04/2.87 |
0.12 |
−0.98 |
5. Frataxin CAGI 5 Challenge
The Critical Assessment of Genome Interpretation (CAGI) is a community experiment aimed at fairly assessing the computational methods for genome interpretation . In CAGI 5, data providers measured unfolding free energy of a set of variants with far-UV circular dichroism and intrinsic fluorescence spectra on Frataxin (FXN), a highly conserved protein fundamental for the cellular iron homeostasis in both prokaryotes and eukaryotes. These measurements were used to calculate the change in unfolding free energy between the variant and wild-type proteins at zero denaturant concentrations ( ). In addition, the experimental dataset , including eight amino acid substitutions, was used to evaluate the performance of the web-only tools, based on protein structure information, for predicting the value of the associated . Here we compare the available machine-learning sequence-based predictors on the dataset (Table 6), showing the consistency of the prediction performance of ACDC-NN-Seq.
Table 6. Results on Frataxin Challenge in CAGI5 . The INPS, SAAFEC-SEQ and I-mutant2.0 results were obtained using their stand alone code, those of MUpro were obtained using the webserver available.
| Method |
Pearson/RMSE |
Antisymmetry |
| Direct |
Reverse |
|
|
| ACDC-NN-Seq |
0.88/2.83 |
0.88/2.83 |
−1.00 |
0.00 |
| INPS |
0.65/3.29 |
0.57/3.38 |
−0.99 |
−0.01 |
| SAAFEC-SEQ |
0.67/3.3 |
0.1/4.85 |
0.2 |
−1.94 |
| I-Mutant2.0 |
0.84/2.82 |
0.53/5.08 |
−0.74 |
−1.22 |
| MUpro |
0.33/3.6 |
0.13/4.97 |
−0.23 |
−0.45 |
 +1 point
+1 point