Developers of resource-allocation and scheduling algorithms share test datasets (i.e., benchmarks) to enable others to compare the performance of newly developed algorithms. However, mostly it is hard to acquire real cloud datasets due to the users’ data confidentiality issues and policies maintained by Cloud Service Providers (CSP). Accessibility of large-scale test datasets, depicting the realistic high-performance computing requirements of cloud users, is very limited. Therefore, the publicly available real cloud dataset will significantly encourage other researchers to compare and benchmark their applications using an open-source benchmark. To meet these objectives, the contemporary state of the art has been scrutinized to explore a real workload behavior in Google cluster traces. Starting from smaller- to moderate-size cloud computing infrastructures, the dataset generation process is demonstrated using the Monte Carlo simulation method to produce a Google Cloud Jobs (GoCJ) dataset based on the analysis of Google cluster traces. With this article, the dataset is made publicly available to enable other researchers in the field to investigate and benchmark their scheduling and resource-allocation schemes for the cloud. The GoCJ dataset is archived and available on the Mendeley Data repository.
1. Summary
Datasets are becoming increasingly more pertinent when executing the performance assessment of cloud-scheduling, resource-allocation, and load-balancing algorithms used for eagle-eyed examination of efficiency and performance in a real-world cloud. A minor change in the behavior and nature of the dataset is reflected in the performance of scheduling and resource-allocation policies. Assessing the scheduling and allocation policies on cloud infrastructures under a varying load and system size is a challenging problem. Real cloud workload is hard to acquire for performance analysis and investigation due to the users’ data confidentiality and policies maintained by Cloud Service Providers (CSPs). In addition, using real testbeds limits the experiments to the scale of the testbed. Hence, testing the accuracy performance with real-world datasets is crucial in the field of research, and synthetic data does not realistically represent an actual dataset [
1]. The most appropriate alternative is to make the investigation in a simulation environment with a load of varying behavior in the cloud environment. For cloud computing research, it is valuable to formulate and ensure a widespread availability of realistic datasets that show how resourcefully the cloud addresses the user requirements.
Distributed computing is comprised of a potentially large number of heterogeneous computing resources interconnected over recurrent network architecture to meet the computing requirements of varying high-performance computing (HPC) applications [
2]. Cloud computing is a paradigm of distributed computing promised to deliver on-demand utility computing over the Internet. The resources are provisioned in the form of
Virtual Machines (VMs) deployed within cloud datacenters consisting of physical host machines. These datacenters are generally over-provisioned to guarantee high service availability and Quality of Service (QoS) computing [
3]. The QoS contracts are formally negotiated and self-proclaimed in the users’ Service-Level Agreements (SLA) providing confidence to customers in outsourcing and executing HPC applications in cloud [
4,
5]. Cloud computing is a unique platform that offers solutions to small business users of computation-hungry large scientific applications. The cloud offers dynamically scalable access to the benefits of technology instead of worrying about involved deployment, building, investment, maintenance, and operation of physical infrastructure [
6]. It is evident that several researchers and even different businesses are keenly interested in using the cloud infrastructure for executing scientific applications in remote datacenters [
7]. The cloud provides its services in the form of a platform or infrastructure to real-time deployment, execution, or simulation of different computation-greedy applications i.e., big network traffic data visualizations [
8], multi-threaded learning control mechanisms for neural networks [
9], performance tests on merge sorts, recursive merge sorts for big data processing [
10], and parallelization of modified merge sort algorithms [
11] etc. Some parallel applications result in the degradation of resource use in cloud computing, undesirably affecting the performance of the computing environment. Thus, adopting an efficient and appropriate scheduling mechanism to achieve required scheduling objectives becomes a challenging research issue. Parenthetically, researchers need to archive scientific datasets that exhibit behaviors of realistic cloud workloads to enable other researchers to evaluate the scheduling mechanisms with desired performances.
Some datasets (i.e., Heterogeneous Computing Scheduling Problems (HCSP) Instances [
12], and Task Execution Time Modeling (TETM) [
13]) are publicly available for research purposes and these datasets are based on varying task and machine heterogeneity. However, the compositions of the job sizes in these datasets are not derived from any real cluster or cloud workload. Furthermore, there are some publicly available real workload traces (such as Google cluster traces [
14], Yahoo cluster traces [
15], Facebook Hadoop workload [
16], OpenCloud Hadoop workload [
17], Eucalyptus IaaS cloud Workload [
18], and the Grid Workload Archiver TuDelft (GWA-T) traces [
19], etc.); however, most of these require preprocessing and in-depth low-level details to be regenerated and used for experimentation.
The main contribution of this data descriptor is to introduce a realistic Google Cloud Jobs (GoCJ) dataset based on Google cloud infrastructure as a benchmark for cloud-scheduling researchers. This data descriptor is presented to address the research issue of ensuring the public availability of a realistic dataset that satisfies the need for researchers in performance analysis of cloud infrastructure. The GoCJ dataset generator is presented in the form of an Excel sheet generator and a Java-based tool. A sample dataset (with a small number of jobs) based on jobs trend behavior in Google cluster traces is formulated and provided to the GoCJ dataset generator, which simulates the desired dataset comprised of any required number of jobs. The proposed GoCJ is used in [
20] for performance analysis of several load-balancing Cloud schedulers. The value and importance of the GoCJ dataset can be enumerated as follows:
The rest of the paper is organized as follows.
Section 2 discusses some existing datasets in the research domain, presents the description of the proposed GoCJ dataset, the composition of jobs in GoCJ dataset and its comparison with the exiting datasets in the literature. The assumption and approach toward generating the GoCJ dataset, and the complexity of GoCJ generator tool, is presented in
Section 3. The last section concludes the paper and identifies future directions for the GoCJ dataset.
2. Data Description
The GoCJ dataset is provided as a supplementary data in text and Excel file formats in amalgamation with the two dataset generator files: (1) an Excel worksheet generator, and (2) a Java tool generator. Each row in the text file describes the size of a specific job in terms of Millions of Instructions (MI). The Monte Carlo simulation method [
2] is employed to generate the dataset comprised of any required number of jobs. The specification of the GoCJ dataset is presented in .
Table 1. Description of GoCJ dataset.
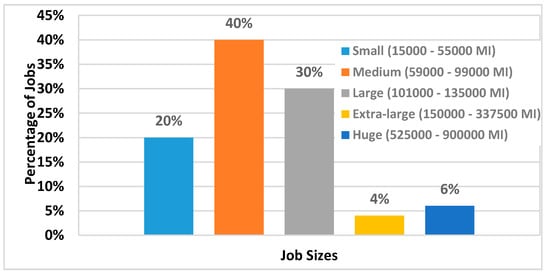
The GoCJ dataset, stored in a Mendeley Data repository, is comprised of 21 text files. Each dataset file is named as “GoCJ_Dataset_XXX.txt”, where XXX is the number of jobs in the file i.e., “GoCJ_Dataset_100.txt” has the sizes of 100 jobs. Each text file consists of a set of rows, where each row has a numeric value presenting the size of a job in terms of MI. Job completion time for GoCJ dataset follows a long-tailed distribution (with 90% of the jobs completing on average within 1.6 min). The longest-executing job witnessed in the dataset lasts up to 15 min (i.e., 6% of the jobs execute for less than 5 min and 4% of the jobs execute for 15 min). The average size of a job in the GoCJ dataset is 5 min. displays ratios and sizes of jobs distribution in GoCJ dataset in terms of percentage and MIs, respectively.
Figure 1. The composition of the GoCJ dataset.
Some existing datasets (i.e., HCSP, TETM, and GWA-T instances) are discussed and compared with the GoCJ dataset. The HCSP instances and TETM dataset are used in research work [
24,
25,
26]. However, HCSP and TETM datasets are not based on compute-traces of any real Grid or Cloud system. On the other hand, GWA-T traces are based on distributed datacenters of Bitbrains and relates to a research work in [
27]. Similarly, GWA-T traces exhibit the performance metrics of VMs in the datacenters instead of jobs behavior. The comparison of existing datasets with the proposed GoCJ dataset is presented in .
Table 2. Comparison of the proposed and existing Cloud datasets.
3. Methods
In this section, the data acquisition for original dataset, and the process of generating the GoCJ dataset, is described in detail. In addition, the complexity of and data distribution in GoCJ dataset is also presented.
3.1. Data Acquisition for Original Dataset
The Monte Carlo simulation method is used to generate the GoCJ dataset. A sample original dataset is formulated based on workload behavior in Google cluster traces, which is input into the Monte Carlo simulation. The composition of jobs in the simulated GoCJ dataset is generated based on the job sizes in the original dataset.
The contemporary state of the art has been scrutinized to explore a real workload behavior in Google cluster traces [
21,
22,
23,
24,
26] and MapReduce logs from the M45 supercomputing cluster [
25]. Liu and Cho analyzed large-scale Google cluster traces of 29-days to examine the machine properties, workload behavior and resource use [
21]. The analysis affirms that the majority of the jobs execute for fairly a short duration of fewer than 15 min, while a few jobs execute over 300 min. The median length of a job in Google cluster traces is witnessed as approximately 3 min. Furthermore, it establishes the fact that approximately two-thirds of the jobs execute for less than 5 min and approximately 20% of the jobs execute for less than one minute. It is found that most jobs in Google cluster traces are shorter length. The shorter jobs are generally used for test runs on Google cluster [
21]. Likewise, the MapReduce logs of the M45 supercomputing cluster presented in [
7] is also scrutinized. The MapReduce logs for the duration of 10 months (i.e., Hadoop logs from 25 April 2008, to 24 April 2009, except logs from 12 Nov 2008, to 18 Jan 2009) have been released by the Yahoo. It is shown that most of jobs (i.e., 95% of the jobs) complete the execution within 20 min, and approximately 4% of jobs take up to 30 min [
7] to execute.
Based on the analysis of [
21,
22,
23,
24,
25,
26], a GoCJ realistic data set is generated using the bootstrapped Monte Carlo (MC) simulation method [
28]. Instead of Random Number Generation (RNG), the original dataset is repeatedly sampled by selecting one of the data points from the original dataset in bootstrapping [
28]. A list of 50 different-size jobs (i.e., presented in ) are identified and input into MC bootstrapping as the original dataset. Each job size in the dataset is treated with equal probability in repeated sampling by bootstrapping. The average power of machine in the distributed computing environment for finding job sizes is assumed as 1000 Million Instructions Per Second (MIPS). The majority of the smaller jobs in Google-like realistic dataset (i.e., 90% of jobs) execute for up to 1.6 min. However, the longest-executing jobs in the GoCJ dataset execute for up to 15 min (i.e., 900,000 MIs/1000 MIPS = 900 s = 15 min). The sizes of jobs in the GoCJ dataset is presented in terms of MIs instead of ETC as used in other available datasets [
12,
13]. The job size is calculated from the ETC of the job, using the following relationship, where
[Math Processing Error] presents the size of job in MIs,
[Math Processing Error]is the power of computing machine in MIPS, and ETC is the expected time to complete a job in seconds [
20]. The job size can be calculated using Equation (1).
Table 3. Sizes of jobs in original dataset for GoCJ (in MIs).
The converse of Equation (1) is to determine the ETC of a job, which is presented [
20] as:
The job sizes in HCSP instances, GWA-T traces, ETM datasets, Facebook Hadoop workload [
16], and Yahoo cluster traces [
15] are presented in terms of ETC. On the other hand, the composition of the original dataset is presented in (which is derived using Equation (1)). Fifty different job sizes are identified based on the analysis of Google cluster traces with an equal probability of occurrences in the desired GoCJ dataset. Using Equation (1) by considering the computing power of machine as 1000 MIPS and the ETC of jobs (derived from workload behavior studied in Google cloud infrastructure [
21,
22,
23,
24,
26]), the original dataset is created and presented in .
3.2. Reproduction of GoCJ Realistic Dataset
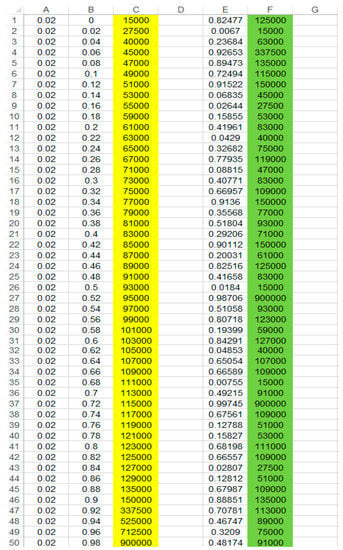
The dataset is generated by bootstrapped MC simulation using an Excel worksheet (as shown in ). The original dataset is input in column C from cell C1 through C50, highlighted with a yellow background in . The individual probability of occurrence of each job is placed in the corresponding row of column A (i.e., from cell A1 through A50). Congruently, the cumulative probability of each job is placed in column B from cell B1 through B50. Therefore, a data table (i.e., from cell B1 through C50) is generated where each job size in column C is referenced by a cumulative probability in column B. As presented in column I in the worksheet, uniform RNG is used to generate a random number among the indices of job sizes in the data table. Now, a built-in function VLOOKUP in Excel is used to create the GoCJ dataset based on the original dataset provided in column C. The VLOOKUP function inputs the generated random number (i.e., in the corresponding row of column E), and the data table (i.e., from cells B1 through C50). Then, VLOOKUP searches for the entry in the data table based on the input random number (i.e., search in cumulative probabilities in column B) and returns the corresponding job-size entry to store it in column F, highlighted with a green background as shown in . The VLOOKUP-based formula used to find a job size is as follows:
Figure 2. GoCJ Excel worksheet generator.
The GoCJ dataset with the specified number of jobs can be created by extending the formulas in cells E1 and F1 by copy/paste to the row equal to the desired number of jobs in the dataset.
One Excel file, named “GoCJ_Dataset_Monte_Carlo.xlsx”, is also placed along with the text files in the dataset. This Excel file can be used to generate a GoCJ dataset comprised of the desired number of jobs. A new dataset can be generated by copying any of the worksheets in the “GoCJ_Dataset_Monte_Carlo.xlsx” Excel file, and then extending the formulas in column E and F by copy/paste, as discussed.
3.3. GoCJ Dataset Generator Tool
Alternatively to the Excel sheet generator, an automated dataset generator program is provided using Java programming. The algorithm is presented as Algorithm 1, which presents the formal algorithm for creating a dataset as discussed in
Section 3.1. The GoCJ generator performs the necessary initialization (lines 1–4). cPer variable presents the cumulative percentage of probability for each job in the original dataset to occur in the simulated dataset, jobSize is the size of the job to occur in the simulated dataset, and jList is the list of jobs finally produced in the simulated dataset. Afterward, the original dataset from a text file named “Original_Dataset” is read and resided in bufferReader (in lines 5–6). Line 5 reads all the job sizes in the original dataset derived from the Google cluster traces. A while-loop is used to copy the sample job sizes from bufferReader to fill the dataTable. The dataTable contains the job sizes in original dataset along with its cumulative probability (i.e., lines 7–10 of Algorithm 1). Line 9 maps the cumulative probability of each job in the dataTable. The second while-loop is used to produce the GoCJ dataset with the desired number of jobs. The job size produced in each iteration of the loop (i.e., lines 12–15) is stored in a job list (i.e., jList variable). The source code of the given algorithm in Java program is available on Mendeley along with the GoCJ dataset files and provided with the supplementary files as well.
| Algorithm 1: GoCJ Generator |
| Input: num — desired number of jobs in dataset, |
| Original_DataSet — file of original dataset sample |
| Output: jList — list of job sizes in the desired dataset |
| 1 cP er = 0 |
| 2 jobSize = 0 |
| 3 jList = N ull |
| 4 dataT able < cP er, jobSize ≥ N ull |
| 5 fileReader = readFile(Original_DataSet) |
| 6 buf f erReader = read(f ileReader) |
| 7 while buf f erReader is Not Empty do |
| 8 jobSize = long.parseLong(bufferRedear.readLine()) |
| 9 dataT able.add(cPer,jobSize) |
| 10 cP er = cP er + 2 |
| 11 a=1 |
| 12 while num ≥ a do |
| 13 rand = Random.nextInt(100) |
| 14 jList.add((rand Mod 2)?dataT able.get(rand): getJobSize(rand)) |
| 15 a++ |
| 16 return jList |
3.4. Data Distribution and Complexity of GoCJ Generator
To scrutinize the complexity and efficiency of the GoCJ generator, N number of desired jobs are considered in the GoCJ dataset. As mentioned in
Section 3, the average computing power of a machine that is used to generate job sizes in the original dataset is 1000 MIPS. Algorithm 1 inputs two parameters; first num is desired number of jobs in the simulated dataset and second is the Original_Dataset with a fixed number of jobs (i.e., 50 jobs). Therefore, the first while-loop in Algorithm 1 iterates for a fixed number of times (i.e., equal to the number of job sizes in the original dataset). On the other hand, the second while-loop iterates till N that is the desired number of jobs in the simulated dataset. The computational complexity of GoCJ generator is linear or O(N) depending only on the desired number of jobs in the simulated dataset. Due to the linear complexity of GoCJ generator, it will not create any overhead even for a dataset creation with a large number (N) of jobs.
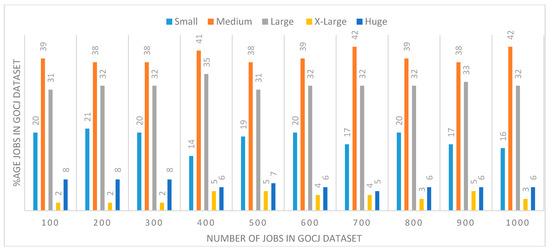
To test the compliance of the data distribution trend in the original dataset to the simulated dataset produced by the GoCJ generator, the covariance statistical test is performed. The average data distribution of 19 GoCJ dataset files is determined and its covariance with the original dataset is calculated to find the correlation of data distribution. The covariance of the original dataset to the average simulated dataset is 2.49, demonstrating that both the original and simulated datasets are positively dependent. Furthermore, the ratios of job-size distribution are also presented in to highlight the job distribution trends in original and simulated datasets.
Figure 3. Ratios of jobs distribution in the GoCJ dataset.
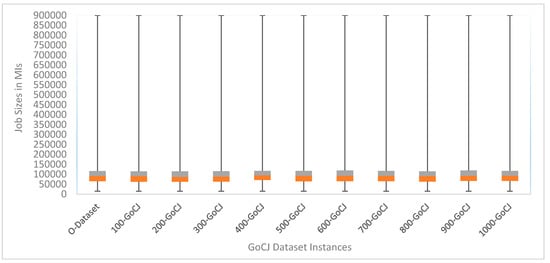
Another statistical measure that displays the data distribution based on five-number summary (i.e., minimum, first quartile, median, third quartile and maximum) is boxplot visualization. The five-number summary for original datasets and ten sample datasets produced using GoCJ generated is determined. To reflect the job-size trends in the original and simulated dataset, a boxplot visualization is shown in . The boxplot presents the median of job sizes in the original, and ten simulated GoCJ datasets which are 92,000, 91,000, 87,000, 89,000, 95,000, 93,000, 93,000, 93,000, 91,000, 93,000, and 93,000 MIs, respectively. These job sizes belong to the medium job sizes as shown in and . However, the minimum and maximum job sizes in both original and simulated GoCJ datasets are same as 15,000 and 900,000 MIs, respectively. Similarly, the first quartile and third quartile of original and simulated GoCJ datasets belongs to a category of medium- and large-size jobs as presented in . Thus, the boxplot visualization proves that the data distribution in the simulated GoCJ datasets complies with the data distribution in the original dataset in the same manner.
Figure 4. Boxplot visualization of jobs distribution in original and simulated GoCJ datasets.
4. User Notes
It is very hard to acquire real cloud datasets due to user data confidentiality and policies maintained by CSPs. This restricts the performance analysis to the scale of the real dataset and making diversified empirical examination impossible as per varying requirements of the researchers. Thus, realizing the need for a varying size realistic dataset, the GoCJ dataset is generated based on the real jobs trend in Google cluster traces. A very comprehensive analysis of the Google cluster traces [
21,
22,
23,
24] is conducted and presented in the form of GoCJ dataset. An original dataset based on this analysis is derived depicting the jobs behavior in real Google cluster. Then, MC bootstrapping is used to generate the GoCJ dataset based on this original dataset (i.e., dataset comprised of 50 different fix-sized jobs) as a seed to the GoCJ workload generator. Two GoCJ dataset generators (i.e., Excel worksheet and Java tool generators) are presented so that a researcher can easily create a GoCJ dataset comprised of any desired number of jobs. The job sizes in GoCJ are presented in terms of MIs, where the same is presented in the HCSP, TETM, and GWA-T instances as ETC. However, the conversion of the GoCJ to an ETC-based dataset is also presented and explained. The proposed GoCJ dataset can be used by the cloud research community for cloud scheduling, resource-allocation policies, and benchmark-based performance analysis. GoCJ dataset is also used in the performance analysis of a resource-aware load-balancing technique as a benchmark in cloud infrastructure [
20].
However, the GoCJ dataset is based on the jobs trend observed in one specific real cloud infrastructure (i.e., Google cluster traces). As a future direction of this data descriptor, the GoCJ dataset can be enhanced with a generalized original dataset (to be input into the MC simulation) based on a diversified analysis of different multiple real cloud infrastructure (i.e., Google cluster traces, Facebook Hadoop workload, Yahoo cluster traces, etc.). In addition, the GoCJ can be equipped with SLA- and deadline-based jobs parameters based on a comprehensive literature review that would be useful in the performance analysis of SLA-aware and constraints-oriented resource-allocation and scheduling policies in cloud.