This work introduces an innovative Markov Chain Monte Carlo (MCMC) classifier that combines Bayesian machine learning with Apache Spark. The primary focus of this study is on the analysis of a large dataset of air pollutant concentrations in Madrid from 2001 to 2018, using Bayesian Logistic Regression to classify the Air Quality Index (AQI) as safe or hazardous.
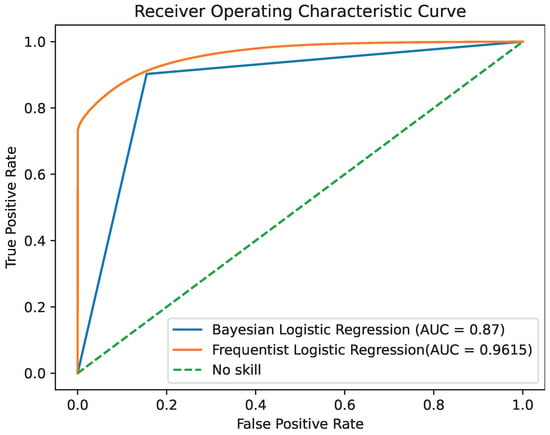
The research demonstrates the model's capability to manage overfitting and enhance predictive accuracy in big data environments. It achieved a maximum accuracy of 87.91% and a remarkable recall value of 99.58% at a specific decision threshold. However, it slightly underperformed in comparison to the traditional Frequentist Logistic Regression in terms of accuracy and the AUC score.
This work highlights the effectiveness of Bayesian machine learning for managing large datasets and its applicability in environmental analysis. It underscores the importance of the MCMC Classifier and Apache Spark in handling high-dimensional data and their broader implications not only in statistics, mathematics, and physics but also in practical real-world applications.
The key points of the study are:
-
Objective: The study introduces the EVCA Classifier, a Markov Chain Monte Carlo (MCMC) based classifier, designed for analyzing high-dimensional big data. This classifier is integrated with Bayesian machine learning and Apache Spark.
-
Data Source: The classifier was applied to a large dataset of air pollutant concentrations in Madrid, collected from 2001 to 2018.
-
Methodology: Bayesian Logistic Regression was used to classify the Air Quality Index (AQI) as safe or hazardous. The research used MCMC techniques for posterior distribution sampling.
-
Results: The EVCA Classifier achieved a maximum accuracy of 87.91% and an impressive recall of 99.58% at a specific decision threshold, indicating high effectiveness in classifying AQI.
-
Comparison with Frequentist Approach: When compared with traditional Frequentist Logistic Regression, the Bayesian approach had slightly lower accuracy and AUC score.
-
Importance of Model Complexity: The study found that models with fewer features tended to perform better than those with more features, indicating that an equilibrium between the number of features and model complexity is crucial.
-
Impact of Decision Thresholds: The selection of appropriate decision thresholds was critical for balancing false positives and negatives, particularly important for classifying AQI correctly.
-
Performance in Apache Spark: The use of Apache Spark was instrumental in handling large datasets and demonstrated the scalability of the classifier.
-
Future Work: The study suggests potential future directions, including developing a multiclass Bayesian classification model, refining prior distributions, and expanding applications to other environmental datasets.
This study underscores the effectiveness of Bayesian machine learning in handling large datasets and its applicability in environmental analysis, emphasizing the role of MCMC classifiers and Apache Spark in managing high-dimensional data.
- stochastic data engineering
- Markov Chain Monte Carlo
- big data management
- large-scale data
1. Introduction
| Pollutant | Good | Fair | Moderate | Poor | Very Poor | Extremely Poor |
|---|---|---|---|---|---|---|
| PM2.52.5 | 0–10 | 10–20 | 20–25 | 25–50 | 50–75 | 75–800 |
| PM1010 | 0–20 | 20–40 | 40–50 | 50–100 | 100–150 | 150–1200 |
| NO22 | 0–40 | 40–90 | 90–120 | 120–230 | 230–340 | 340–1000 |
| O33 | 0–50 | 50–100 | 100–130 | 130–240 | 240–380 | 380–800 |
| SO22 | 0–100 | 100–200 | 200–350 | 350–500 | 500–750 | 750–1250 |
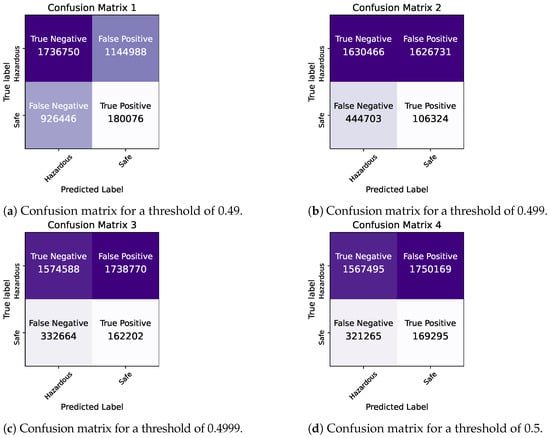
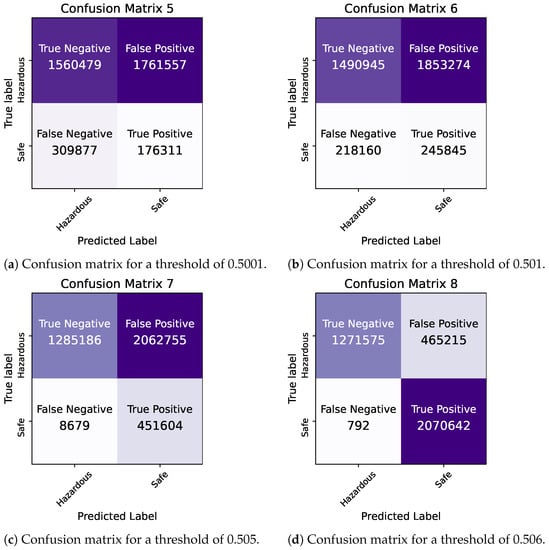
2. Predictions in Apache Spark for Different Decision Thresholds
3. Bayesian vs. Frequentist Logistic Regression in Apache Spark
| Metrics | Bayesian Logistic Regression | Frequentist Logistic Regression |
|---|---|---|
| Accuracy | 0.8791 | 0.8923 |
| Precision | 0.9932 | 0.9270 |
| Recall/Specificity | 0.9958 | 0.9452 |
| ROC AUC | 0.8678 | 0.9614 |
| Time | 35.3 s | 35.3 s |
| Confusion Matrix | [1285186,451604] [8679, 2062755] |
[1440301, 296489] [113412, 1958022] |

This entry is adapted from the peer-reviewed paper 10.3390/info14080451