Deep Reinforcement Learning (DRL) combines Reinforcement Learning and Deep Learning. It is more capable of learning from raw sensors or images as input, enabling end-to-end learning, which opens up more applications in robotics, video games, NLP, computer vision, healthcare, and more. A milestone in value-based DRL is employing Deep Q-Networks (DQN) to play Atari games by Google DeepMindin 2013.
1. Introduction
Where V(st) is the estimated state value, initialized using a certain strategy; α is a rate that influences the convergence; Gt is the return from the time that the actor first visited the state-action pair (or sum of returns from each time it visited the pair), can be calculated as below:(12)Gt=rt+1+γrt+2+…+γT−1rT
Q-learning:(14)Q(s,a)←Q(s,a)+α[r+γmaxαQ(s′,a′)−Q(s,a)](s←s′)
SARSA:(15)Q(s,a)←Q(s,a)+α[r+γQ(s′,a′)−Q(s,a)](s←s′,a←a′)
A table of representative DRL techniques is shown inTable 1.
Table 1. Representative DRL Techniques.
| |
DRL Algorithms |
Main Techniques |
| Value-based |
DQN [1] |
Experience Replay, Target Network, Clipping Rewards, Clipping Rewards, and Skipping Frames |
| |
Double DQN [2] |
Double Q-learning |
| |
Dueling DQN [3] |
Dueling Neural Network architecture |
| |
Prioritized DQN [4] |
Prioritized experience replay |
| |
Bootstrapped DQN [5] |
Deep exploration with DNNs |
| |
Distributional DQN [6] |
Distributional Bellman equation |
| |
Noisy DQN [7] |
Parametric noise added to weights |
| |
Rainbow DQN [8] |
Combine 6 extensions to the DQN |
| |
Hierarchical DQN [9] |
Hierarchical value functions |
| |
Gorila [10] |
Asynchronous training for multi agents |
| Policy-based |
TRPO [11] |
KL divergence constraint |
| |
PPO [12] |
Specialized clipping in the objective function |
| Actor-Critic |
Deep DPG [13] |
DNN and DPG |
| |
TD3 [14] |
Twin Delayed DDPG |
| |
PGQ [15] |
Policy gradient and Q-learning |
| |
Soft Actor Critic (SAC) [16] |
Maximum entropy RL framework |
| |
A3C [17] |
Asynchronous Gradient Descent |
2. Applications
Deep Reinforcement Learning has been widely utilized in many domains, as shown in
Table 2, which is summarized from
[18]. This chapter will discuss the recent advances in applications in games, robotics, Natural Language Processing (NLP), transportation, industrial applications, communication and networking, and more topics. Usually, different techniques may be employed in an application besides DRL, e.g., AlphaGo is trained using supervised learning and reinforcement learning. In this report, POMDP problems are taken into more consideration, but in reality, it is hard to define an application as a firm POMDP problem or not. We focus applications generally based on Deep Reinforcement Learning, not only on POMDP problems.
Table 2. Various DRL Applications, summarized from
[18].
| Domains |
Applications |
| Healthcare |
DTRs, HER/EMR, diagnosis |
| Education |
Educational games, recommendation, proficiency estimation |
| Transportation |
Traffic control |
| Energy |
Decision control |
| Finance |
Trading, risk management |
| Science, Engineering, Art |
Math, Physics, music, animation |
| Business management |
Recommendation, customer management |
| Computer systems |
Resources management, security |
| Games |
Board games, card games, video games |
| Robotics |
Sim-to-real, control |
| Computer vision |
Recognition, detection, perception |
| NLP |
Sequence generation, translation, dialogue |
2.1. Games
Researchers have continuously been studying RL algorithms with games as testbeds since long ago. This section discusses this research in board games, card games, and video games. This section refers to Li’s overview
[18].
2.1.1. Board Games
In the board games like Go, chess, checkers, and Backgammon, players have perfect information about each other, and the environment is deterministic (not MDPs). The AI research in two-person games can trace back to the 1950s, Claude Shannon and Alan Turing proposed computer programs that could challenge humans.
RL in Board Games
There have been significant steps in AI playing games towards the DRL direction. In 1994, TD-Gammon
[19] was a Neural Network to estimate evaluation function with TD learning for Backgammon. Buro
[20] also wrote papers proposing methods of playing Othello programs in the 1990s, for further references, see:
https://skatgame.net/mburo/publications.html, accessed on 11 January 2021. Schaeffer et al.
[21] developed Chinook, playing checkers, between 1989 and 2007. Ginsberg
[22] is the inventor of GIB for playing the computer bridge. For the Hex games, Huang employed MCTS in MoHex
[23], and Gao et al.
[24] trained the neural networks by canonical maximum likelihood to enhance MoHex 2.0.
Mannen’s thesis
[25] implemented experiments in the training of neural networks as evaluation functions for a chess program. Block et al.
[26] used reinforcement learning in chess engines, extending KinghtCap’s
[27] learning algorithm with a larger database. Later, Lai
[28] presented Giraffe, using Deep Reinforcement Learning with automatic feature extraction in chess, outperformed other chess engines during the time.
AlphaGo
In 2016, AlphaGo
[29] became the first computer Go program that won the professional Go player Lee Sedol. This is the historical moment that AI proves to be able to surpass human learning in board games. AlphaGo was trained by a combination of supervised learning and reinforcement learning of self-play. The networks also combined Monte Carlo simulation with value and policy networks. Later, Silver et al.
[30] introduced ALphaGo Zero, based solely on RL without human data or guidance beyond game rules. A neural network is trained to predict AlphaGo or other winner’s action selections. This resulted in higher quality and more robust self-play features. Later, Silver et al.
[31] also came up with a general algorithm called AlphaZero. It realized superhuman performance in many other games and defeated champion programs in chess, shogi, and Go. Furthermore, Kimura et al.
[32] applied AlphaZero to POMDP maze problems, and it turned out effective.
AlphaGo is a turning point in the application of Deep Reinforcement Learning. It has made tremendous progress in recent years.
2.1.2. Card Games
Card games, like many variants of Poker, UNO, and mahjong, have incomplete information. The agents and the environment are stochastic and uncertain. These games are usually POMDP problems.
Texas Hold’em Poker
One of the classic poker games is Texas Hold’em Poker. Davidson
[33], Davidson et al.
[34], Felixa and Reis
[35], and Bayes’ Bluff presented by Southey et al.
[36] used Neural Networks to model opponents in Texas Hold’em Poker, thus the network was able to predict the next actions of players correctly.
Zinkevich et al.
[37] presented Counterfactual Regret Minimization(CFR). CFR is to compute an approximate Nash equilibrium for the abstract game by iteratively traversing the game tree. Based on the CFR technique, Bowling et al.
[38] weakly solved Heads-up Limit Hold’em Poker. Furthermore, Deep CFR was discussed by Brown et al.
[39].
DeepStack computer program presented by Moravčík et al.
[40], uses deep neural networks as the value function for its depth-limited look-ahead, defeated professional poker players for the first time, in heads-up no-limit Texas Hold’em. More information about DeepStack can be found at
https://www.deepstack.ai/, accessed on 11 January 2021.
Prior breakthroughs have been limited to settings with two players. Brown and Sandholm
[41] proposed Pluribus, a superhuman AI capable of defeating elite human professionals in six-player no-limit Texas hold’em poker, with self-play through improved Monte Carlo CFR.
Hearts and Wizard
Hearts is a multi-player non-cooperative finite-state zero-sum imperfect-information game that can formulate a POMDP
[42]. Fujita and Ishii
[43] developed model-based RL for large-scale multi-player games with partial observability and applied it to Hearts, using Markov Chain Monte Carlo (MCMC) technique. Sturtevant and White
[44] developed a player for the game of hearts of 4 players, based on stochastic linear regression and TD learning.
In 2017, Wagenaar’s thesis
[45] used a multi-layer perceptron (MLP) and Monte Carlo learning to play Game Hearts and realized DRL. However, more work is required to realize mature performance in the Hearts game.
Similar to Hearts, Wizard is also a multi-player imperfect-information poker game. RL has turned out effective for these POMDP games. Backhus et al.
[46] applied RL in the Wizard game, separately dealing with forecasting and trick playing.
RLCard
In recent years, the full-width extensive-form fictitious play (XFP) was introduced by Heinrich and Heinrich and Lanctot
[47], Neural Fictitious Self-Play (NFSP) was presented by Heinrich and Heinrich and Silver
[48], and Unified Game-Theoretic Approach was proposed by Lanctot et al.
[49]. We can see that RL strategies can perform well in betting games. These results give the inspiration for researchers to explore DRL in more card games.
Zha et al.
[50] presented RLCard, an open-source toolkit for reinforcement learning research in card games. It provides various card game environments, including Blackjack, Leduc Hold’em, Texas Hold’em, UNO, Dou Dizhu, and Mahjong, with easy-to-use interfaces (see
Figure 1).
Figure 1. RLCard: It supports various styles of card games and board games
[50].
2.1.3. Video Games
Video games are valuable resources with video frames as inputs to RL/AI agents, in which computer games are the most popular testbeds for DRL algorithms. Similar to the MDP process as shown in
Figure 1, DRL for video games employ CNNs to extract features from the video frames (environment) to be recognized by the agents. Recently, DRL has been applied in Sega, Nintendo, Xbox, etc. Shao et al.
[51] made a comprehensive survey of DRL in video games. Based on this,
Figure 2 presents popular video-game platforms for RL research. In this section, we particularly dig into details about games with POMDP characteristics.
Figure 2. Popular video-game platforms for Reinforcement Learning research, summarized from
[51].
Atari
A traditional platform, the Arcade Learning Environment (ALE)
[52], provides an interface to lots of games in Atari 2600 and is a pioneer evaluation platform in RL research. As described in Chapter One, many value-based methods are tested in Atari 2600 and the un-mentioned techniques, such as DRQN
[53] and ADRQN
[54]. Aytar et al.
[55] presented an exciting method of playing Atari exploration games by watching Youtube. They map unaligned videos from several sources to a common representation, then embed a single YouTube video in this representation to construct a reward function. Hence, the agent learns to imitate human gameplay. This method exceeds human-level performance on MONTEZUMA’S REVENGE, PITFALL! and PRIVATE EYE, with no environment rewards in games.
ViZDoom
Doom is a classical first-person shooter (FPS) game with a 3D environment, where agents observe perspective 2D projections from their positions as pixel matrices. The partial observability of game states is the main challenge. ViZDoom
[56] is a Doom-based platform that offers API.
Lample and Chaplot
[57] used a divide and conquered method in Doom to divide the action space. They trained an action agent and a navigation agent. Different agents will act
[58] based on the detection of an enemy. Akimov and Makarov
[59] proposed Categorical 51 with Multi-step (C51M) architecture, outperformed baseline methods in ViZDoom environment.
In the survey
[51], they mentioned the following important techniques that evaluated in ViZDoom: Wu and Tian
[60] proposed a framework combining A3C with curriculum learning
[61]; Parisotto and Salakhutdinov
[62] developed Neural Map, a memory system with an adaptable write operator, using a spatially structured 2D memory image to store arbitrary environment information; Shao et al.
[63] also introduced ACKTR, which teaches agents to battle in the ViZDoom environment.
TORCS
The Open Racing Car Simulator (TORCS) is a racing game with acceleration, braking, and steering as actions. It has been used as testbeds for visual-input games. It is also an essential platform for testing autonomous driving methods with its realistic feature.
In 2014, Koutník et al.
[64][65] had Max-Pooling Convolutional Neural Network (MPCNN) compressor and recurrent neural network (RNN) controllers evolved successfully to control a car in TORCS based on visual input; DDPG
[13], as mentioned, was assessed in TORCS; Wang et al.
[66] adopted DDPG and selected sensor information from TORCS as inputs, evaluated on different modes in TORCS; Sallab et al.
[67] formulated two categories of algorithms for lane-keeping assist: DQN for discrete actions and Deep Deterministic Actor-Critic Algorithm (DDAC) for continuous actions; Furthermore, Liu et al.
[68] proposed DDPG method with expert demonstrations and supervised loss, simulated in TORCS, which improves efficiency and stability significantly; Verma et al.
[69] presented Programmatically Interpretable Reinforcement Learning (PIRL), to generate interpretable agent policies and a new method called Neurally Directed Program Search (NDPS), to find a programmatic policy with maximal reward;
In addition to the works shown above, some techniques discussed by Shao et al.
[51]: Sharma et al.
[70] proposed Fine-Grained Action Repetition (FiGAR) to improve DDPG; Gao et al.
[71] used TORCS to evaluate Normalized Actor-Critic (NAC); Mazumder et al.
[72] developed a property called state-action permissibility (SAP), with which the agent learns to solve the lane-keeping problem in TORCS, with faster training process; Li et al.
[73] break the vision-based lateral control system down into a perception module and a control module; Zhu and Zhao
[74] uses DRL to train a CNN to perceive data.
Minecraft
Minecraft is a well-known sandbox video game where players can explore a blocky, procedurally-generated 3D world and build structures and earthworks with freedom in different game modes. It supports scenarios from navigation and survival to collaboration and problem-solving tasks, making it a rich environment to carry out RL.
Project Malmo
[75] is an AI experimentation platform on top of Minecraft, created by Microsoft. Marlo, based on Malmo, provides a higher-level API and a more standardized RL-friendly environment for RL study. In 2019, Guss et al.
[76] presented a comprehensive, large-scale, simulator-paired dataset of human demonstrations: MineRL, which provides an RL environment and competitions.
Some RL tasks created in Minecraft were effectively achieved. Liu et al.
[77] constructed tasks with shared characteristics in Minecraft for multi-task DQN (MDQN), which turned out effective. Oh et al.
[78] also designed tasks to evaluate DRL architectures: Memory Q-Network (MQN), Recurrent Memory Q-Network (RMQN), and Feedback Recurrent Memory Q-Network (FRMQN). Frazier
[79] conducted experiments with two RL algorithms: Feedback Arbitration and Newtonian Action Advice, enabling human teachers to give action advice. Furthermore, HogRider
[80] is the champion agent of MCAC in 2017, using a Q-learning approach with state-action abstraction and warm start; Tessler et al.
[81] proposed a lifelong learning system that is able to transfer knowledge from one task to another, incorporated with Hierarchical-DRLN with a deep skill array and skill distillation; Jin et al.
[82] utilized counterfactual regret minimization to update an approximation to an advantage-like function iteratively.
DeepMind Lab
DeepMind Lab
[83] is a 3D customizable first-person game platform for agent-based AI research, a modified version of Quake III Arena. It is usually used to study how RL agents deal with complex tasks in large, partially observed, and visually diverse worlds.
Many researchers have created RL tasks in DeepMind Lab and tested algorithms. Johnston
[84] introduced an unsupervised auxiliary task—“surprise pursuit”. It quantifies the surprise” the agent encounters when exploring the environment and trains a policy to maximize this “surprise”.
There also are researchers who used DM-Lab to propose new architectures. As mentioned by
[51], Mankowitz et al.
[85] proposed Unicorn, which demonstrates robust continual learning; Schmitt et al.
[86] had a teacher agent to kickstart the training of a new student agent. The method mentioned by Jaderberg et al.
[87] trains plenty of agents concurrently from lots of parallel matches, where agents play cooperatively in teams, competing in randomly generated environments.
Later on, DeepMind also invented Psychlab
[88], a psychophysics testing room embedded inside the world of DM-Lab. This framework allows DRL agents to be directly compared with humans, lifted from cognitive psychology and visual psychophysics.
Real-Time Strategy Games
Real-time strategy games (RTS) allow players to play the game in “real-time” simultaneously rather than to take turns to play. RTS like StarCraft, Dota, and LOL are popular platforms in AI research. The real-time games usually consist of thousands of time steps and hundreds of actions selected in real-time through the gameplay. StarCraft is a game in which players balance high-level economic decisions in the control of tons of units. In each time step, the agent receives imperfect information from observations. In 2019, DeepMind proposed AlphaStar
[89], which defeats professional players for the first time.
Table 3 presents the techniques carried out in StarCraft.
MOBA (Multiplayer Online Battle Arena) games have two teams, and each team consists of five players. OpenAI Five
[90] used Dota2 as the research platform and achieved expert-level performance, and is the first AI system that could defeat the world champions in an esports game.
Table 3. Techniques used in StarCraft, summarized based on
[51].
| StarCraft Algorithms |
Main Techniques |
| GMEZO [91] |
Micromanagement; greedy MDP; episodic zero-order exploration |
| BiCNet [92] |
Multiagent bidirectionally coordinated network |
| Stabilising Experience Replay [93] |
Importance sampling; fingerprints |
| PS-MAGDS [94] |
Parameter sharing multi-agent gradient descent SARSA(λ |
| ) |
| MS-MARL [95] |
Master-slave architecture; multi-agent |
| QMIX [96] |
Decentralised policies in a centralised end-to-end training |
| NNFQ CNNFQ [97] |
Neural network fitted Q-Learning |
| SC2LE [98] |
FullyConv-A2C; baseline results |
| Relational DRL [99] |
Self-attention to iteratively reason about the relations |
| TStarBots [100] |
Flat action structure; hierarchical action structure |
| Modular architecture [101] |
Splits responsibilities between multiple modules |
| Two-level hierarchical RL [102] |
Macro-actions; a two-layer hierarchical architecture |
2.2. Robotics
Robotics is widely used in science, industries, healthcare, education, entertainment, and many more domains. Robotics has many challenging problems involved, including perceptron, control system, operation system, etc. The development of Deep Reinforcement Learning paves the way in robotics. Many applications mentioned in the gaming section, including AlphaGo, are also involved in Robotics. While in this section, we focus on manipulation and locomotion.
For more surveys in Robotics, see
[103] in 2009, a study of robot learning from demonstration (LfD), with which a policy is learned from demonstrations, provided by a teacher; Deisenroth
[104] made a survey on policy search for robotics in 2013; In 2014, Kober and Peters
[105] provided a general survey on RL in robotics; Tai et al.
[106] presented a comprehensive survey for learning control in robotics from reinforce to imitation in 2018.
A 3D physics simulator MuJoCo physics engine
[107], which stands for Multi-Joint dynamics with Contact, was developed by OpenAI for continuous control. Mainly based on which series algorithms are evaluated.
2.2.1. Manipulation
Dexterous manipulation is one of the most challenging control problems in robotics due to the barriers of high dimensionality, intermittent contact dynamics, and under-actuation in dynamic object manipulation; Dexterous manipulation can be widely used in different domains. These make it a hot topic in Robotics. Nguyen and La
[108] provided a review of DRL for Robot Manipulation with the challenges, the existing problems, and future research directions.
For reinforcement learning, researchers made significant progress, making DRL in manipulation tasks accessible in recent years. For example, in 2008, Peters and Schaal
[109] evaluated policy gradient methods on parameterized motor primitives, and Episodic Natural Actor-Critic
[110] outperforms the others; In 2010, Theodorou et al.
[111] presented Policy Improvement with Path Integrals (PI2); In 2010, Peters et al.
[112] suggested Relative Entropy Policy Search (REPS) method; In 2011, Kalakrishnan et al.
[113] used PI2 with force control policies. Nair et al.
[114] demonstrated overcoming the exploration problem and solved the block stacking task using RL.
Multi-Fingered Hands
Dexterous multi-fingered hands can perform a wide range of manipulation skills. They are essential in research while it requires high dimensional observation and ample action space. Kumar et al.
[115] demonstrated online planning based on an ADROIT platform, and Kumar et al.
[116] described a model-based method combining optimizing Linear–Gaussian controllers models with KL-constrained optimization. It was applied on a pneumatically-actuated tendon-driven 24-DoF hand, which learned hand manipulation involving clockwise rotation of the object.
Rajeswaran et al.
[117] then demonstrated that model-free DRL could scale up to complex manipulation tasks. It does not require a model of the dynamics and can optimize the policy directly. They used a combination of RL and imitation learning Demo Augmented Policy Gradient (DAPG), achieved in object relocation, in-hand manipulation, door opening, and tool use tasks.
However, in the real world, the interaction time with the environment is limited, the model-free methods perform poorly in such cases. Haarnoja et al.
[118] studied how maximum entropy policies were trained using soft Q-learning. Policies learned using soft Q-learning can be composed to create new policies, the optimality of which can be enclosed knowing the divergence between the composing policies. By composing existing skills can efficiently improve the training process. This method is sample efficient than prior model-free DRL methods and can be performed for simulated and real-world tasks.
Zhu et al.
[119] surveyed multi-fingered manipulation and used model-free DRL algorithms with low-cost hardware, succeeded in learning complex contact-rich behaviors.
Considering interacting with fragile objects, Huang et al.
[120] realized gentle object manipulation, minimizing impact forces, with dynamics-based surprise and penalty-based surprise.
Grasping
Levine et al.
[121] trained using guided policy search (GPS), which can perform policy search by supervised learning, where supervision is granted by a simple trajectory-centric RL method. It was evaluated in various tasks, like learning to insert, screw, fit, and place the objects. DRL has also been applied to learn grasping objects
[122][123], Popov et al.
[124] introduced two extensions to the Deep Deterministic Policy Gradient (DDPG) algorithm to improve data efficiency with linear speedup for 16 parallel workers. The method succeeded in grasping objects and precisely stacking them on another in simulation. Kalashnikov et al.
[125] introduced QT-Opt, a scalable self-supervised RL framework, enables closed-loop vision-based control. They achieved real-world grasping tasks with a high success rate based only on RGB vision perceptron.
Opening a Door
Gu et al.
[126] presented Asynchronous NAF with practical extensions. The experiment shows success in several 3D manipulation skills in simulation and a door opening skill on real robots.
Cloth Manipulation
Regarding cloth manipulation, the state of the cloth can vary, unlike rigid objects. Tsurumine et al.
[127] proposed Deep P-Network (DPN) and Dueling Deep P-Network (DDPN) to combine smooth policy update with feature extraction, evaluated in flipping a handkerchief and folding a t-shirt by a dual-arm robot. Jangir et al.
[128] investigated the effectiveness of different textile state representations and the importance of speed and trajectory, solved dynamic cloth manipulation tasks by restricting the manipulator workspace.
Magnetic Manipulation
Magnets can be utilized in magnetic resonance imaging (MRI) applications, lifting machinery, levitation devices, jewelry, bearings, audio equipment, and hard disc drives. de Bruin et al.
[129] deployed two experience replay databases in the method, one filled with experiences in the First In First Out (FIFO) manner. The experiences are overwritten with new experiences in the other. This method limits the detrimental effects of exploration, tested on a simulated horizontal magnetic manipulation task.
2.2.2. Locomotion
Over the recent years, many RL methods have been proposed to control locomotion, locomotion examples are shown in
Figure 3. On humanoid platforms such as Nao, Pepper, Asimo, and Robotis-op2 include the cameras
[130], many algorithms were evaluated. The main goal for robot locomotion is to imitate human motions dynamically. Several main techniques such as DeepDPG
[13], A3C
[17], TRPO
[11], etc., that were previously covered, were tested in robotics locomotion and turned out effective. They are the key to the vast development of DRL algorithms in locomotion
[131][132].
Figure 3. Locomotion examples.
In Robotics, many tasks are complex and poorly specified. Christiano et al.
[133] had humans compare possible trajectories, used the data to learn a reward function, and optimized the learned reward function with RL and scaled up this method to DRL. In particular, the robotics tasks including walker, hopper, swimmer, etc., were implemented in MujoCo and OpenAI Gym
[134].
DeepLoco
[135] adopted a two-level hierarchical control framework. First, low-level controllers (LLC) learn to operate at a timescale and achieve robust walking gaits. Second, high-level controllers (HLC) learn the policy at the timescale of steps by invoking desired step targets for the low-level controller. Both levels of the hierarchy use an identical style of the actor-critic algorithm.
To develop sound strategies for integrating or merging policies for multiple skills, Berseth et al.
[136] proposed Progressive Learning and Integration via Distillation (PLAiD). Distillation refers to the combination of the policies of one or more experts, thus creating one controller to perform the tasks of a set of experts. The main blocks are policy transfer and multi-task policy distillation, evaluated on five different terrains with a 2D PD-biped. Compared with MultiTasker, PLAiD scales better.
Generally, model-free methods can learn a wide range of robotic skills but require a large number of samples to achieve good performance. Model-based algorithms can provide more efficient learning but are challenging to scale up to high-capacity models. Md-Mf
[137] uses deep neural network dynamics models to initialize a model-free learner, then uses the policy trained by a model-based controller as the initial policy for a TRPO (model-free) algorithm. Testing locomotion skills on a simulated quadrupedal robot, this method surpasses the individual model-free and model-based approach.
Duan et al.
[138] studied Truncated Natural Policy Gradient (TNPG) and compared it with TRPO and DDPG. They also provided a benchmark of continuous control problems for RL.
Following are some examples of different locomotion skills.
Walking/Running
Xie et al.
[139] demonstrated DRL on a bipedal robot Cassie, developed by Agility Robotics. The framework used PPO and PD control on a simulated model of Cassie in the MuJoCo
[107] simulation and is robust to disturbances.
Designing agile locomotion for robots usually requires human expertise and manual tuning. Tan et al.
[140] presented a system to learn quadruped locomotion from scratch or allow users to guide the learning process. In addition, it narrows the gap between simulation and the real world, successfully developed two gaits, trotting, and galloping.
Haarnoja et al.
[132] proposed an extension of the soft actor-critic (SAC) algorithm with dynamic temperature, based on maximum entropy RL. It was applied to a real-world Minitaur robot without any model or simulation. This sample-efficient and stable algorithm outperforms standard SAC, DDPG, TD3, and PPO.
Özalp et al.
[130] evaluated Double Dueling Q Networks (D3QN)
[141] and DQN
[142] for locomotion using a Robotis-op2 humanoid robot.
Hopping
Peng et al.
[143] introduced a mixture of actor-critic experts (MACE), constructed of multiple actor-critic pairs where each specializes in particular aspects of the motion. It can work with high-dimensional state descriptions for terrain-adaptive dynamic locomotion skills. With leaps or steps as output actions, the method was tested on seven classes of terrain and gives excellent results.
Swimming
Heess et al.
[144] surveyed a hierarchical motor control architecture that encourages the low-level controller to focus on reactive motor control. The high-level controller directs behavior towards the task goal by transmitting a modulatory signal. Evaluated on a swimming snake, a quadruped, and a humanoid, this method failed in end-to-end learning but turned out effective in transferring tasks with sparse reward.
To learn stochastic energy-based policies for continuous states and actions, not only in tabular domains, Haarnoja et al.
[145] introduced Soft Q-learning, which expresses the optimal policy via a Boltzmann distribution. The simulated swimming snake and quadrupedal robot results show that the method can effectively capture complex multi-modal behaviors and learn general-purpose stochastic policies.
To narrow the gap between simulation and the real world and generalize from training to testing, Pinto et al.
[146] introduced robust adversarial reinforcement learning (RARL). The adversary learns to apply destabilizing forces on specific points on the system, encouraging the protagonist to retain a strong control policy. This method improves training stability, and is robust to training/testing conditions, and outperforms the baselines even without an adversary.
Verma et al.
[147] studied that DRL can learn efficient collective swimming in unsteady and vortical flow fields.
Tensegrity
Tensegrity robots are composed of rigid rods connected by elastic cables, which display high tolerance to physical damage. With their unique properties, tensegrity robots are appealing for planetary exploration rovers. The primary locomotion of tensegrity robots is rolling.
Zhang et al.
[148] applied an extension of mirror descent guided policy search (MDGPS) to periodic locomotion movements on a SUPERball tensegrity robot. The learned locomotion policies performed well, are more effective, and can generalize better than open-loop policies. Luo et al.
[149] showed that MDGPS could efficiently learn even with limited sensory inputs.
2.2.3. Robotics Simulators
Robotics simulators are used to simulate and model the structures or actions of a physical robot without depending on the real-world machine. The use of simulators to develop robots allows for programs to be written and debugged offline, and the final versions can then be transferred to the real robot, thus saving cost and time. Table 4 presents the popular robotics simulators nowadays.
Table 4. Robotics simulators, adapted from Wikipedia (2021)
[150].
2.3. Natural Language Processing
Natural language processing (NLP) focuses on the communication between computers and humans—how to program computers to understand, analyze, and process natural language, including generation, language grounding, information extraction, dialogue, etc. Due to the unique features of NLP, DRL has been playing an important role. For more surveys, see
[18][151][152][153][154][155].
2.3.1. Neural Machine Translation
Neural Machine Translation (NMT) refers to using machine learning software to translate content into another language. RL has been shown as an effective technique for NMT systems recently. Examples of machine translation providers are Google Translate, Yandex Translate, Watson Language Translator, etc. Wu et al.
[156] provided a literature review on RL for NMT, in which they compared several vital factors, including baseline reward and reward shaping, and studied how to train better NMT systems. They also proposed training with source-side and (or) target-side monolingual data and succeeded in the Chinese-English translation task.
He et al.
[157] proposed dual-NMT for English-French dual translation. The English-to-French translation (primal) agent and French-to-English translation (dual) agent can form a closed loop and generate feedback signals to train the models by teaching each other through the RL process. This system works well on bilingual translation, especially by learning from monolingual data.
In the traditional NMT setting, the translator has to wait until the user completes the sentence, then translates. Satija and Pineau
[158] presented an approach to interpret in real-time.
The open-source toolkit OpenNMT was described by Klein et al.
[159], which prioritizes efficiency and modularity; Zhang et al.
[160] introduced THUMT that supports minimum risk training and semi-supervised training.
For generative adversarial net (GAN) in NMT, BR-CSGAN
[161] leverages the BLEU reinforced GAN to improve the NMT, and Wu et al.
[162] introduced Adversarial-NMT with a CNN based adversary.
2.3.2. Dialogue
Dialogue systems generally have two categories—task-oriented dialog agents and chatbots. Task-oriented dialog agents usually have short Q-and-A conversations to help complete specific tasks or provide information, while chatbots are usually designed human-likely and used for entertainment
[163].
Cuayáhuitl has done significant research on dialogue systems with RL
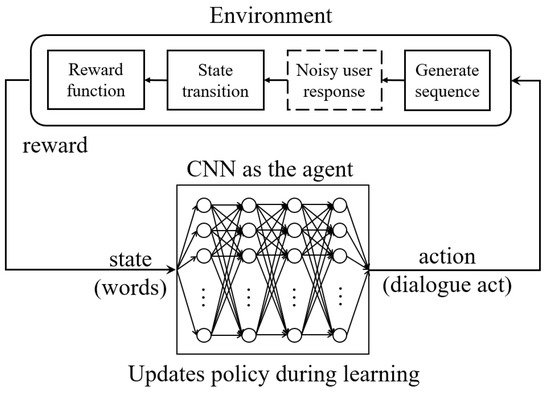
[164][165][166][167]. In 2017, he presented SimpleDS
[168], as shown in
Figure 4. It’s a publicly available dialogue system trained with DQN, which extends the traditional methods
[167] and avoids manual feature engineering by directly selecting actions from raw text and user responses.
Figure 4. SimpleDS architecture
[168].
Cuayáhuitl et al.
[169] proposed a two-stage method—the first stage reduces the times of weight updates, and the second uses limited mini-batches sampled from experience replay for accelerating the induction of single or multi-domain dialogue policies. The training turns out five times faster than a baseline. Furthermore, Cuayáhuitl et al.
[170] described an ensemble-based approach applied to value-based DRL chatbots. Actions are derived from sentence clustering, the training datasets are derived from dialogue clustering, and the reward function is derived from human–human dialogues without manual annotations. The ensemble of DRL agents turns out more promising than a single DRL agent or SEQ2SEQ model.
Most DRL systems perform poorly in exploring online in the environment or learn effectively from off-policy data. Jaques et al.
[171] leveraged models pre-trained on data with KL-control to penalize divergence. They used uncertainty estimates with dropout to lower bound the target Q-values. Tested in the real world with humans, the Way Off-policy algorithm can effectively learn from different reward functions from human interaction data and outperforms prior methods in off-policy batch RL.
Text Generation
Text generation is the basis of dialogue systems. Ranzato et al.
[172] proposed mixed incremental cross-entropy reinforce (MIXER) with a loss function combining REINFORCE
[173] and cross-entropy. For sequence prediction, Bahdanau et al.
[174] proposed an actor-critic algorithm, inspired by Ranzato et al.
[172]. Yu et al.
[175] introduced sequence generative adversarial nets with policy gradient (SeqGAN). Li et al.
[176] from Huawei Technologies proposed a new DL framework for paraphrase generation, consisting of a generator and an evaluator. The generator is modeled as the SEQ2SEQ learning model for paraphrase generation. As a deep matching model, the evaluator is trained via supervised learning or inverse RL in different settings for paraphrase identification.
Sentence Simplification
Sentence simplification is also crucial in dialogue systems, which aims to make sentences easier to read and understand for the agents. Zhang and Lapata
[177] addressed this simplification issue with an encoder-decoder model with a DRL framework, known as Deep Reinforcement Sentence Simplification (DRESS). Their work succeeded in simplicity, grammaticality, and semantic fidelity to the input.
Coherent Dialogues
Some neural models of dialogue generation tend to be short-sighted, and modeling the future direction of dialogue is crucial to generating coherent and exciting conversations. Li et al.
[178] applied DRL with policy search and curriculum learning on the SEQ2SEQ model
[179], which can generate utterances that optimize future reward.
Goal-Oriented Dialogues
Dhingra et al.
[180] proposed KB-InfoBot, an end-to-end dialogue agent to help people search Knowledge Bases (KBs). They offered a differentiable probabilistic framework to compute the posterior distribution (a Soft-KB lookup) to avoid symbolic queries used in previous works.
To evaluate persuasion strategies and negotiation dialogue, Keizer et al.
[181] presented a comparative evaluation of various negotiation strategies on the game “Settlers of Catan” online. It outperforms the original rule-based strategy and human players.
Ilievski et al.
[182] presented goal-oriented chatbot dialog management bootstrapping with transfer learning, which helps users achieve a predefined goal. Due to the domain specificity, the available data is limited to obtain. The transfer learning method is to boost the performances and mitigate the limitation. They describe that transfer learning improves performance significantly with a low number of goals or whole target domain data.
For social robot navigation, Ciou et al.
[183] presented composite reinforcement learning (CRL) framework, with which agents learn social navigation with sensor input and reward update based on human feedback.
2.3.3. Visual Dialogue
Das et al.
[184] introduced a goal-driven training for visual question answering (VQA) and dialogue agents. The experiment contains two cooperative robots, with one giving descriptions and the other giving answers. The results show that it outperforms supervised learning agents.
Thanks to the encoder-decoder architectures, End-to-end dialogue systems have developed rapidly. However, there are some drawbacks in encoder-decoder models when engaging in task-oriented dialogue. Strub et al.
[185] introduced the DRL method to optimize vision-based task-oriented dialogues with REINFORCE algorithm. It resulted in significant improvement over a supervised baseline model, which was capable of generating coherent dialogue.
Visual Captioning
Evaluation metrics are created to evaluate image captioning. Standard syntactic evaluation metrics, such as BLEU, METEOR, and ROUGE, are usually not well correlated. SPICE and CIDEr are better correlated but are hard to optimize. Liu et al.
[186] used a policy gradient method to optimize a linear combination of SPICE and CIDEr (SPIDEr).
In reference to visual problems, image captioning is challenging due to the complexity of understanding the image content and describing it in natural language. Xu et al.
[187] introduced an attention-based model for image caption generation. Adaptive encoder-decoder attention model
[188] with an LSTM extension as a visual sentinel decides whether to attend to the image and where to generate information. Ren et al.
[189] introduced a decision-making framework for image captioning, which has a policy network and a value network. Both networks are learned using an actor-critic approach with a visual-semantic embedding reward.
Wang et al.
[190] proposed an Adversarial Reward Learning (AREL) framework for visual storytelling. The model learns a reward function from human demonstrations, then optimizes policy search with the learned reward function.
Video captioning is to generate a description of the actions in the video automatically. Wang et al.
[191] proposed a hierarchical RL framework for video captioning. A high-level module learns to create sub-goals, and a low-level module recognizes the actions to fulfill the sub-goal. The HRL model turns out a good performance on MSR-VTT and Charades Captions datasets. For video captioning, Pasunuru and Bansal
[192] presented a mixed-loss policy gradient approach that allows for metric-based optimization, then improved with an entailment-corrected CIDEnt reward, successfully achieved on MSR-VTT.
Visual Relationship and Attribute Detection
Apart from generating labels and captioning, understanding relationships among objects and their attributes in the scene is challenging for computers. Liang et al.
[193] proposed a deep Variation-structured Reinforcement Learning (VRL) framework for visual relationship and attribute detection. A directed action graph is built to represent semantic correlations between object categories, predicates, and attributes. Then based on the state information, a variation-structured traversal over the chart is used to generate an action set for each step. Predictions are made using DRL and the extracted phrases in the state vector. This method can significantly achieve better detection results on datasets involving relationships and attributes.
3. Conclusions
In this paper, we have presented the fundamental concepts of Markov Decision Processes(MDP), Partially Observable Markov Decision Processes (POMDPs), Reinforcement Learning (RL), and Deep Reinforcement Learning (DRL). Generally, we have discussed the representative DRL techniques and algorithms. The core elements of an RL algorithm are value function, policy, reward, model and planning, exploration, and knowledge. In DRL applications that were discussed, most of the algorithms applied are extensions of the representative algorithms, for example, DQN, DPG, A3C, etc., with some optimizations, respectively. We then discussed the applications of DRL in some popular domains. As DRL provides optimal policies and strategies, it has been widely utilized in gaming, including almost all kinds of games. As the leading entertainment among people, a better gaming experience is always desired. Another popular application of DRL is in Robotics. We discussed manipulation, locomotion, and other aspects of robotics where DRL can be applied. Robotics simulators are also discussed, where DRL is used to select the appropriate simulator when needed. Finally, the application of DRL in natural language processing (NLP) is presented.
As we witnessed, DRL has been developing fast and on enormous scales. Some groups pushed forward the development of DRL, like OpenAI, DeepMind, AI research office in Alberta, and research center led by Rich Sutton, and more. From the research, we have acknowledged the algorithms; variations, and the development of all the optimizations. Based on the review, we are more familiar with the usability of each method. For example, model-free methods work better in scaled-up tasks. The value function is key to RL, in DQN and its many extensions; policy gradient approaches have also been utilized in lots of applications, such as robotics, dialogue systems, machine translation, etc. New learning techniques have also been applied, such as transfer, curriculum learning, adversarial networks, etc. When we select a method or combinations of methods to apply in our models, the characteristics we need to consider are stability, convergence, generalizing power, accuracy, efficiency, scalability, robustness, safety, cost, speed, simplicity, etc. For example, in healthcare, we focus more on stability and security rather than simplicity or cost. This topic, along with applications in transportation, communications and networking, and industries, will be discussed in a Part 2 follow-up paper.
 +1 point
+1 point